![[GCP] Google Cloud Certified:Professional Cloud Architect](https://www.cloudsmog.net/wp-content/uploads/google-cloud-certified_professional-cloud-architect-1200x675.jpg)
※ 他の問題集は「タグ:Professional Cloud Architect の模擬問題集」から一覧いただけます。
この模擬問題集は「Professional Cloud Architect Practice Exam (2021.02.10)」の回答・参考リンクを改定した日本語版の模擬問題集です。
Google Cloud 認定資格 – Professional Cloud Architect – 模擬問題集(全 57問)
Question 1
会社のテストスイートは Linux 仮想マシン上で毎日テストを実行するカスタム C++ アプリケーションです。
テスト用に予約された限られた数のオンプレミスのサーバ上で実行されているため、完全なテストスイートを完成させるのに数時間かかります。会社ではシステムの変更を完全にテストするのにかかる時間を短縮し、テストの変更を可能な限り少なくするためにテスト インフラストラクチャをクラウドに移行したいと考えています。
どのクラウド インフラストラクチャをお勧めしますか?
- A. 非マネージド インスタンス グループと ネットワーク ロードバランサ の Google Compute Engine。
- B. マネージド インスタンス グループでの自動スケーリングの Google Compute Engine。
- C. ApacheHadoop ジョブを実行して各テストを処理する Google Cloud Dataproc。
- D. Google StackDriver Logging を利用した Google App Engine。
Correct Answer: B
Google Compute Engine はユーザーがオンデマンドで仮想マシン(VM)を起動できるようにします。VM は標準イメージまたはユーザーが作成したカスタムイメージから起動することができます。
マネージド インスタンス グループは負荷の増減に応じて自動的にインスタンスを追加または削除できる自動スケーリング機能を提供します。自動スケーリングはアプリケーションがトラフィックの増加に優雅に対応し、リソースの必要性が低い場合にコストを削減するのに役立ちます。
B: カスタム C++アプリケーションのための着信IPデータトラフィックについては言及されていません。
C: Apache HadoopはC++アプリケーションのテストには適していません。Apache Hadoop はMapReduceプログラミングモデルを使用したビッグデータのデータセットの分散ストレージと処理に使用されるオープンソースのソフトウェア フレームワークです。
D: Google App Engine はWebアプリケーションでの使用を目的としています。
Google App Engine は Google が管理するデータセンターでWebアプリケーションを開発し、ホスティングするためのWebフレームワークおよびクラウドコンピューティングプラットフォームです。
Reference contents:
– インスタンスのグループの自動スケーリング | Compute Engine ドキュメント
Question 2
リードソフトウェア エンジニアの新しいアプリケーションの設計ではWeb サーバに分散されていないWebSocket とHTTP セッションを使用していると話しています。
アプリケーションが Google Cloud Platform で正常に動作することを確認するためにサポートしたいと考えています。
何をすべきでしょうか?
- A. エンジニアがHTTP ストリーミングを使用するためにWebSocket コードを変換するのに役立ちます。
- B. セキュリティチームとのWebSocket 接続の暗号化要件を確認します。
- C. クラウド運用チームとエンジニアでロードバランサーのオプションについて話し合います。
- D. エンジニアがWebSocket と HTTP セッションに依存しない分散型ユーザーセッションサービスを使用するようにアプリケーションを再設計するようにします。
Correct Answer: C
Google Cloud Platform のHTTP(S) 負荷分散はインスタンス向けの HTTP(S) リクエストに対してグローバル 負荷分散を提供します。
HTTP(S) 負荷分散はWebSocket プロトコルをネイティブにサポートしています。
A: HTTP サーバープッシュはHTTP ストリーミングとも呼ばれ、クライアントからのリクエストなしにHTTP サーバーからクライアントに情報を非同期的に送信するクライアント-サーバー通信パターンです。サーバープッシュ アーキテクチャーは 1つ以上のクライアントがサーバーから継続的に情報を受け取る必要がある高度にインタラクティブなWeb やモバイルアプリケーションに特に効果的です。
Reference contents:
– 外部 HTTP(S) 負荷分散の概要
Question 3
会社のアプリケーション信頼性エンジニアリング チームはバックエンド サービスにデバッグ機能を追加し、最終的な分析のためにすべてのサーバーイベントをGoogle Cloud Storage に送信しました。
イベントレコードは少なくとも 50 KB、最大 15 MBで、毎秒 3,000 件のイベントでピークに達すると予想されます。また、データの損失を最小限に抑えたいと考えています。
どのプロセスを実装するあるでしょうか?
- A. ファイル本体にメタデータを追加します。個々のファイルを圧縮します。serverName Timestamp でファイルに名前を付けます。バケットが 1時間よりも古い場合は新しいバケットを作成し、個々のファイルを新しいバケットに保存します。それ以外の場合は既存のバケットにファイルを保存します。
- B. 10,000 イベントごとにメタデータ用の単一のマニフェストファイルでバッチ処理を行います。イベントファイルとマニフェストファイルを単一のアーカイブファイルに圧縮します。serverName EventSequenceを使用してファイルに名前を付けます。バケットが 1日よりも古い場合は新しいバケットを作成し、単一のアーカイブ ファイルを新しいバケットに保存します。それ以外の場合は単一のアーカイブファイルを既存のバケットに保存します。
- C. 個々のファイルを圧縮します。serverName EventSequence でファイルに名前を付けます。ファイルを 1つのバケットに保存します。保存後、各オブジェクトにカスタムメタデータヘッダを設定します。
- D. ファイル本体にメタデータを追加します。個々のファイルを圧縮します。ランダムな接頭辞パターンでファイルに名前を付けます。ファイルを 1つのバケットに保存します。
Correct Answer: D
Question 4
最近の監査でGCPプロジェクトに新しいネットワークが作成されたことが明らかになりました。
このネットワークでは Google Compute Engine(GCE)インスタンスが SSH ポートが世界中に公開されており、このネットワークの出所を発見したいと考えています。
何をすべきでしょうか?
- A. Stackdriverアラートコンソールで [VMエントリの作成] を検索します。
- B. [ホーム] セクションの [アクティビティ] ページに移動します。カテゴリを [Data Access] に設定し、[VM エントリの作成] を検索します。
- C. コンソールの [Logging] セクションで、[Logging] セクションに GCE Network を指定し、[VM エントリの作成] を検索します。
- D. プロジェクトの SSH キーを使用して GCE インスタンスに接続します。システム ログで以前のログインを識別し、プロジェクト所有者リストと照合します。
Correct Answer: C
A: Stackdriver アラートコンソールを使用するにはまずアラートポリシーを設定する必要があります。
B: データ アクセス ログには読み取り専用の操作しか含まれていません。
監査ログは誰が、どこで、いつ、何をしたのかを特定するのに役立ちます。
クラウド監査ログは 2 種類のログを返します。
– 管理者の活動ログ
– データ アクセス ログ:取得、リスト、集約されたリストメソッドなどデータを変更しない読み取り専用の操作を行う操作のログエントリが含まれています。
Question 5
本番用の Linux 仮想マシンのコピーを us-central リージョンに作成します。
本番用仮想マシンに変更があった場合にコピーを簡単に管理して置き換える必要があり、us-east リージョンの別のプロジェクトに新しいインスタンスとしてコピーをデプロイします。
どのような手順を踏む必要がありますか?
- A. Linux の dd コマンドと netcat コマンドを使用してルート ディスクの内容をコピーして us-east リージョンの新しい仮想マシン インスタンスにストリームします。
- B. ルート ディスクのスナップショットを作成して us-east リージョンで新しい仮想マシン インスタンスを作成する際にそのスナップショットをルートディスクとして選択します。
- C. Linux の dd コマンドを使用してルートディスクからイメージファイルを作成して us-east リージョンで新しい仮想マシンインスタンスを作成します。
- D. ルートディスクのスナップショットを作成し、そのスナップショットから Google Cloud Storage にイメージファイルを作成し、ルートディスクのイメージファイルを使用して us-east リージョンに新しい仮想マシンインスタンスを作成します。
Correct Answer: D
Question 6
会社は単一のMySQL インスタンスで複数のデータベースを実行しています。
特定のデータベースのバックアップを定期的に作成する必要があり、 バックアップ アクティビティはできるだけ早く完了しなければなりません。しかし、ディスクのパフォーマンスに影響を与えないようにしなければなりません。
ストレージをどのように構成すべきでしょうか?
- A. gcloud ツールを使用して永続ディスクのスナップショットを使用して定期的なバックアップを作成するようにcron ジョブを設定します。
- B. バックアップ場所としてローカル SSD パーティションをマウントします。バックアップが完了し、gsutil を使用してバックアップを Google Cloud Storage に移動します。
- C. gcsfuse を使用して Google Cloud Storage バケットをボリュームとしてインスタンスに直接マウントし、mysqldump を使用してマウントされた場所にバックアップを書き込みます。
- D. 追加の永続ディスク ボリュームをRAID10 アレイの各仮想マシン(VM)インスタンスにマウントし、LVM を使用してスナップショットを作成して Google CloudStorage に送信します。
Correct Answer: C
Reference contents:
– mvarrieur/MySQL-backup-to-Google-Cloud-Storage: Backup daily/weekly/monhtly all your MySQL databases to Google Cloud Storage via SH and gsutil
– Google Cloud Storage FUSE
Question 7
QAチームが新しい負荷テストツールを展開して Google Cloud Bigtable を使用した Google Compute Engine で実行されるプライマリ クラウドサービスのスケーラビリティをテストするのをサポートしています。
それらに含まれるべき要件はどれでしょうか?(回答を 3つ選択してください)
- A. 負荷テストで Google Cloud Bigtable のパフォーマンスが検証されていることを確認します。
- B. 負荷テスト環境で使用する別の Google Cloud プロジェクトを作成します。
- C. 本番環境に対して定期的に負荷テストツールを実行するようにスケジュールを作成します。
- D. サービスで使用するすべてのサードパーティ システムが高負荷に対応できることを確認します。
- E. 本番サービスに負荷テストツールで再生するためのすべてのトランザクションを記録するように機器を設置します。
- F. 詳細なログ記録とメトリック収集を使用して負荷テスト ツールとターゲット サービスを計測します。
Correct Answer: B、E、F
Question 8
顧客は企業のアプリケーションを Google Cloud Platform に移行しています。
セキュリティチームは組織内のすべてのプロジェクトの詳細な可視性を求めており、Google Cloud Resource Manager をプロビジョニングして自分が組織の管理者として設定します。
セキュリティチームにどのような Google Cloud Identity and Access Management(Cloud IAM)に与えるべきでしょうか?
- A. 組織管理者、プロジェクト オーナー
- B. 組織閲覧者、プロジェクト オーナー
- C. 組織管理者、プロジェクト参照者
- D. プロジェクト オーナー、ネットワーク管理者
Correct Answer: B
Question 9
会社は迅速に対応し、顧客のニーズに応えることに重視しています。
会社の主要なビジネス目標はリリースのスピードと俊敏性です。セキュリティエラーが誤って導入される可能性を減らしたいと考えています。
どのようなアクションを取ることができますか?(回答を 2つ選択してください)
- A. すべてのコードチェックインがセキュリティ SME によるピアレビューを受けていることを確認します。
- B. CI/CD パイプラインの一部としてソースコードセキュリティアナライザーを使用します。
- C. コンポーネント間のすべてのインタフェースを単体テストするためのスタブがあることを確認します。
- D. CI/CD パイプラインに統合されたコード署名と信頼できるバイナリリポジトリを有効にします。
- E. 継続的インテグレーション/継続的デリバリー(CI/CD)パイプラインの一部として脆弱性セキュリティ スキャナーを実行します。
Correct Answer: B、E
Question 10
実行中の Google Kubernetes Engine クラスタをアプリケーションの需要の変化に合わせてスケーリングできるようにしたいと考えています。
どうすればいいのでしょうか?
- A. 次のコマンドを使用して Google Kubernetes Engine クラスタにノードを追加します。
- gcloud container clusters resize CLUSTER_Name -size 10
- B. gcloud compute instances add-tags INSTANCE – -tags enable- autoscaling max-nodes-10 次のコマンドを使用してクラスター内のインスタンスにタグを追加します。
- C. 次のコマンドを使用して既存の Google Kubernetes Engine クラスタを更新します。
- gcloud alpha container clusters update mycluster – -enable- autoscaling – -min-nodes=1 – -max-nodes=10
- D. 次のコマンドを使用して新しい Google Kubernetes Engine クラスタを作成し、アプリケーションを再デプロイします。
- gcloud alpha container clusters create mycluster – -enable- autoscaling – -min-node=1 – -max-node=10
Correct Answer: C
Question 11
マーケティング部門はプロモーション用のメールキャンペーンを配信したいと考えています。
開発チームは直接の運用管理を最小限に抑えたいと考えており、1日あたり 100 ~ 50 万回のクリックスルーを想定しています。リンクはプロモーションを説明し、ユーザー情報と設定を収集する簡単なWeb サイトにつながります。
どのインフラストラクチャをお勧めしますか?(回答を 2つ選択してください)
- A. Google App Engine を使用してウェブサイトを提供して Google Cloud Datastore を使用してユーザーデータを保存します。
- B. Google Container Engine クラスタを使用してWeb サイトにサービスを提供し、データを永続的なディスクに保存します。
- C. マネージド インスタンス グループを使用してWeb サイトにサービスを提供し、Google Cloud Bigtable を使用してユーザー データを保存します。
- D. 単一の Google Compute Engine 仮想マシンを使用して Google Cloud SQL をバックエンドとしたWeb サーバーをホストします。
Correct Answer: A、C
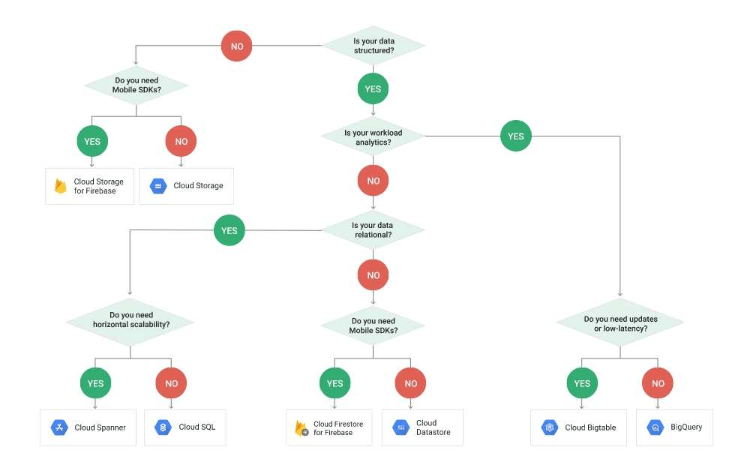
Reference contents:
– クラウド ストレージ オプション
Question 12
会社はコンピュータのニーズに合わせて Google Compute Engine へ移行完了しました。
よりクラウドネイティブなソリューションを設計および展開するにはさらに 9か月かかります。具体的にはオペレーションなしで自動スケーリングが可能なシステムを必要にしています。
どのコンピュータ プロダクトを選択すえうべきでしょうか?(回答を 2つ選択してください)
- A. Google Compute Engine とコンテナー
- B. Google Kubernetes Engine とコンテナー
- C. Google App Engine スタンダード環境
- D. Google Compute Engine とカスタム インスタンス タイプ
- E. Google Compute Engine とマネージド インスタンス グループ
Correct Answer: B、C
B:Google Container Engineを使用すると Google が自動的にクラスタをデプロイし、ノードを更新、パッチ適用、保護を行います。
Google Kubernetes Engine のクラスタ オートスケーラーは実行するワークロードの要求に基づいてクラスターのサイズを自動的に変更します。
C:Google Cloud Datastore、Google BigQuery、Google App Engine などのソリューションはまさににNoOps です。
Google App Engine はデフォルトで負荷に合わせて実行中のインスタンスの数をスケーリングします。これにより、アイドル状態のインスタンスを最小限に抑えながらアプリに常に一貫したパフォーマンスを提供し、コストを削減します。
NoOps はプラットフォームの使用中に構築および管理するインフラストラクチャがないことを意味します。一般的にNoOps で行う妥協点は基盤となるインフラストラクチャの制御を失うことです。
Reference contents:
– How well does Google Container Engine support Google Cloud Platform’s NoOps claim?
Question 13
主なビジネス目的の 1つはアプリケーションに保存されているデータを信頼できることです。
アプリケーション データへのすべての変更をログに記録したいと考えています。
ログの信頼性を検証するためにどのようにログシステムを設計することができますか?
- A. ログをクラウドとオンプレミスで同時に書き込みます。
- B. SQL データベースを使用してログ テーブルを変更できるユーザーを制限します。
- C. 各タイムスタンプとログエントリにデジタル署名して署名を保存します。
- D. 各ログエントリのJSON ダンプを作成して Google Cloud Storage に保存します。
Correct Answer: D
ログエントリを書き込みます。ログが存在しない場合はログを作成します。ログエントリに深刻度を指定することができ、 — payload-type=json を指定してメッセージを JSON 文字列として書き込むことで構造化されたログエントリを書くことができます。
gcloud logging write LOG STRING gcloud logging write LOG JSON-STRING –payload-type=json
Reference contents:
– Command-line interface | Cloud Logging
Question 14
会社は開発者により良い体験を提供するためにAPI の大規模な改訂を行うことを決定しました。
新しい顧客やテスターが新しいAPI を試すことができるようにしながら、古いバージョンのAPI を利用可能でデプロイ可能な状態にしておく必要があります。両方のAPI を提供するために、同じSSL とDNS レコードを維持したいと考えています。
どうすればいいのでしょうか?
- A. 新しいバージョンのロードバランサー API を構成します。
- B. 新しいAPI に新しいエンドポイントを使用するように古いクライアントを再構成します。
- C. パスに基づいて古いAPI がトラフィックを新しいAPI に転送するようにします。
- D. ロードバランサーの背後にあるAPI パスごとに個別のバックエンド プールを使用します。
Correct Answer: D
Question 15
会社は数ペタバイトのデータセットをクラウドに移行することを計画しています。
データセットは 24 時間利用可能である必要があります。ビジネスアナリストはSQL インターフェイスの使用経験しかありません。
分析を容易にするためにデータを最適化するにはどのようにデータを保存すべきでしょうか?
- A. Google BigQuery にデータを読み込みます。
- B. Google Cloud SQL にデータを挿入します。
- C. Google Cloud Storage にフラットファイルを配置します。
- D. Google Cloud Datastore にデータをストリームします。
Correct Answer: A
Google BigQuery はすべてのデータアナリストの生産性を高めるように設計されたサーバーレスで拡張性の高い低コストのエンタープライズ データ ウェアハウスです。管理するインフラストラクチャがないため、使い慣れたSQL を使用してデータの分析に集中し、意味のある洞察を見つけることができます。データベース管理者は必要ありません。
Google BigQuery を使用すると管理されたカラム型ストレージやオブジェクトストレージ、スプレッドシートからのデータだけでなく、論理的なデータウェアハウスを作成することで、すべてのデータを分析することができます。
Reference contents:
– BigQuery: クラウド データ ウェアハウス | Google Cloud
Question 16
運用管理者はJ2EE アプリケーションをクラウドに移行するときに考慮すべきベスト プラクティスのリストを要求します。
どのプラクティスをお勧めしますか? (回答を3つ選択してください)
- A. Google App Engine で動作するようにアプリケーション コードを移植します。
- B. Google Cloud Dataflow をアプリケーションに統合してリアルタイムの指標を取得します。
- C. Stackdriver Debugger などの監視ツールでアプリケーションを計測します。
- D. クラウド インフラストラクチャを確実にプロビジョニングするための自動化フレームワークを選択します。
- E. ステージング環境に自動テストを備えた継続的インテグレーションツールを導入します。
- F. MySQL から Google Cloud Datastore や Google Cloud Bigtable などの管理されたマネージド NoSQL データベースに移行します。
Correct Answer: A、D、E
Reference contents:
– Java アプリをデプロイする | Java 8 の App Engine スタンダード環境 | Google Cloud
– 入門: Cloud SQL | Java 8 の App Engine スタンダード環境 | Google Cloud
Question 17
ニュースフィード Web サービス はGoogle App Engine で下記のコードを実行しています。
負荷のピーク時にユーザーから「すでに閲覧したニュース記事が表示される」との報告があります。
この問題の最も可能性の高い原因は何でしょうか?
import news
from flask import Flask, redirect, request
from flask.ext.api import status
from google.appengine.api import users
app = Flask (_name_)
sessions = { }
@app.route ("/")
def homepage():
user = users.get_current_user()
if not user:
return "Invalid login",
status.HTTP_401_UNAUTHORIZED
if user not in sessions :
sessions (user] = { "viewed": []}
news_articles = news.get_new_news (user, sessions [user] ["viewed"])
sessions [user] ["viewed"] + [n["id"] for n in news_articles]
return news.render (news_articles)
if _name_ == "_main_":
app.run()- A. セッション変数は単一のインスタンスに対してローカルです。
- B. セッション変数が Google Cloud Datastore で上書きされています。
- C. API URL はキャッシュを防ぐために変更する必要があります。
- D. HTTP Expires ヘッダーを -1 に設定してキャッシュを停止する必要があります。
Correct Answer: A
Reference contents:
– Google App Engine Cache List in Session Variable
Question 18
アプリケーション開発チームは現在 使用しているロギング ツールでは新しいクラウドベースの製品に対してニーズを満たせないと考えています。
エラーをキャプチャし、過去のログデータを分析するのに役立つ より優れたツールを求めており、解決策を見つけるのを手伝いたいと思っています。
何をすべきでしょうか?
- A. Google StackDriver Logging エージェントをダウンロードしてインストールするように指示します。
- B. ロギングのベスト プラクティスに関するオンライン リソースのリストを送信します。
- C. 要件を定義し、実行可能なロギング ツールを評価するのを支援します。
- D. 現在のツールをアップグレードして新しい機能を利用できるようにします。
Correct Answer: C
Stackdriver Logging エージェントはVM インスタンスや特定のサードパーティ ソフトウェア パッケージのログを Stackdriver Logging にストリームします。エージェントの使用はオプションですが推奨されています。このエージェントはLinux とMicrosoft Windows の両方で動作します。
Stackdriver Loggingでは Google CloudPlatform および Amazon Web Services からのログ データとイベントを保存、検索、分析、監視、アラートすることができます。API を使用すると任意のソースから任意のカスタム ログ データを取り込むこともできます。Stackdriver Logging は大規模に実行され、何千ものVM からアプリケーションとシステムのログ データを取り込むことができるフルマネージドサービスですべてのログデータをリアルタイムで分析できます。
Reference contents:
– 単一の VM に Cloud Logging エージェントをインストールする | Google Cloud
– The hidden superpowers of Stackdriver Logging | by Alex Van Boxel | Google Cloud – Community
Question 19
会社のWeb ホスティング プラットフォームでの誤った本番展開の計画外のロールバックの数を減らす必要があります。
QA /テストプロセスの改善により、80%の削減が達成されました。
ロールバックをさらに減らすためにどのアプローチができるでしょうか?(回答を 2つ選択してください)
- A. Blue/Green デプロイ パターンを導入します。
- B. QA 環境をカナリア テストに置き換えます。
- C. モノリシック プラットフォームをマイクロサービスに断片化します。
- D. プラットフォームのリレーショナル データベース システムへの依存を減らします。
- E. プラットフォームのリレーショナル データベース システムをNoSQL データベースに置き換えます。
Correct Answer: A、C
Reference contents:
– GKE でのデプロイとテストの戦略の実装 | ソリューション
– アプリケーションのデプロイとテストの戦略 | ソリューション
Question 20
コストを削減するためにエンジニアリング ディレクターはすべての開発者に開発インフラのリソースをオンプレミスの仮想マシン(VM)から Google Cloud Platform に移動するようにリクエストがありました。
これらのリソースは 1 日の間に複数の起動/停止 イベントを通過し、状態を持続させる必要があります。財務部門にコストの可視性を提供しながら Google Cloud で開発環境を実行するプロセスを設計するように依頼がありました。
どのステップを行うべきでしょうか?(回答は 2つ選択してください)
- A. すべての永続ディスクで -no-auto-delete フラグを使用してVM を停止します。
- B. すべての永続ディスクで -auto-delete フラグを使用してVM を終了します。
- C. VM の CPU 使用率ラベルを適用して Google BigQuery の課金エクスポートに含めます。
- D. Google BigQuery 課金エクスポートとラベルを使用してコストをグループに関連付けます。
- E. すべての状態をローカル SSDに格納し、永続ディスクをスナップショットしてVM を終了します。
- F. すべての状態を Google Cloud Storage に保存し、永続ディスクをスナップショットしてVM を終了します。
Correct Answer:A、D
A はインスタンスが停止しても永続ディスクは削除されません。
B はインスタンスが削除されない限り、–auto-deleteフラグは効果がありません。インスタンスを停止してもインスタンスや添付の永続ディスクは削除されません。
Cはラベルはインスタンスを整理するために使用され、指標を監視するために使用されません。
D は毎日の使用量とコストの見積もりを Google BigQuery データセットに 1日を通して自動的にエクスポートすると財務部門に可視性を提供する良い方法です。その後、ラベルを使用してチームまたはコスト センターに基づいてコストをグループ化することができます。
E はインスタンスを停止するとローカル SSD に保存されている状態が失われます。
F は Google Cloud Storage に保存する場合は永続ディスクやスナップショットは必要ありません。
Reference contents:
– Cloud Billing データを BigQuery にエクスポートする | Google Cloud
– インスタンスの停止と起動 | Compute Engine ドキュメント | Google Cloud
Question 21
会社は予定された会議のために予約された会議室に誰かが出席しているかどうかを追跡したいと考えています。
3 大陸にある 5 つのオフィスには 1,000 の会議室があります。各部屋には毎秒その状態を報告するモーションセンサーが設置されています。モーションセンサーからのデータにはセンサー ID といくつかの異なる情報が含まれています。分析にはこのデータをアカウント所有者や会議室の場所に関する情報と合わせて使用します。
どのデータベースタイプを使用すればよいですか?
- A. Flat file
- B. NoSQL
- C. Relational
- D. Blobstore
Correct Answer: B
リレーショナル データベースは現代のアプリケーションが直面するスケールや俊敏性の課題に対処するために設計されておらず、現在 利用可能な汎用ストレージや処理能力を活用するために設計されていません。
NoSQL は次のような場合に適しています。
– 開発者は構造化、半構造化、非構造化、および多態なデータの急速に変化する新しいデータ型を大量に作成するアプリケーションを使用しています。
D: Blobstore API を使用するとアプリケーションは Google Cloud Datastore サービスのオブジェクトに許可されているサイズよりもはるかに大きい、ブロブと呼ばれるデータ オブジェクトを提供できます。
Blob は動画ファイルや画像ファイルなどの大容量のファイルを提供したり、ユーザーが大容量のデータファイルをアップロードできるようにする場合に便利です。
Reference contents:
– What is NoSQL? NoSQL Databases Explained
Question 22
自動スケーリングのインスタンス グループを設定して今後のリリースに向けてWebトラフィックを提供します。
インスタンス グループをHTTP(S) ロードバランサのバックエンドサービスとして構成後、VM インスタンスが毎分ごとに毎分再起動されていることに気付きました。インスタンスはパブリック IP アドレスを持っていません。curl コマンドを使用して各インスタンスから適切なWeb レスポンスが送られてくることを確認しましたがバックエンドが正しく設定されていることを確認します。
どうすればよいでしょうか?
- A. HTTP/HTTPS のソーストラフィックがロードバランサに到達するためのファイアウォール ルールが存在することを確認します。
- B. 各インスタンスにパブリック IP を割り当て、ロードバランサがインスタンスのパブリックIPに到達できるようにファイアウォール ルールを設定します。
- C. インスタンス グループ内のインスタンスにロードバランサのヘルスチェックが届くようにファイアウォール ルールが存在することを確認します。
- D. ロードバランサの名前で各インスタンスにタグを作成します ロードバランサの名前をソースとしてインスタンス タグを宛先としてファイアウォール ルールを構成します。
Correct Answer: C
ヘルスチェックを設定する際のベスト プラクティスはヘルスチェックとトラフィックのサーブを同じポートで行うことです。しかし、1つのポートでヘルスチェックを実行し、別のポートでトラフィックを提供することは可能です。2つの異なるポートを使用する場合はインスタンス上で実行されているファイアウォール ルールとサービスが適切に設定されていることを確認してください。ヘルスチェックを実行して同じポートでトラフィックを提供しているがある時点でポートを切り替えることにした場合は、バックエンドサービスとヘルスチェックの両方を更新してください。
参照する有効なグローバル転送ルールがないバックエンドサービスはヘルスチェックされず、ヘルスステータスもありません。
Reference contents:
– バックエンド サービスの概要 | 負荷分散 | Google Cloud
– ヘルスチェックの概要 | 負荷分散 | Google Cloud
– 外部 HTTP(S) 負荷分散の概要 | Google Cloud
Question 23
Google Compute Engine 仮想マシンから Google BigQuery に接続するPython スクリプトを記述します。
スクリプトは「Google BigQuery に接続できない」というエラーを表示されています。
スクリプトを修正するにはどうすればいいでしょうか?
- A. Python 用の最新の Google BigQuery API クライアントライブラリをインストールします。
- B. Google BigQuery アクセス スコープを有効にして新しい仮想マシン上でスクリプトを実行します。
- C. Google BigQuery アクセスを持つ新しいサービス アカウントを作成してそのユーザーでスクリプトを実行します。
- D. gcloud components install bq コマンドを使用して gcloud 用の bq コンポーネントをインストールします。
Correct Answer: B
Google BigQuery を使用するアプリケーションは Google BigQuery API を有効にし、Google Cloud Console のプロジェクトに関連付ける必要があります。
Reference contents:
– クイックスタート: クライアント ライブラリの使用 | BigQuery | Google Cloud
Question 24
顧客は既存の企業アプリケーションをオンプレミスのデータセンターから Google Cloud Platform に移行しています。
ビジネスオーナーはユーザーの混乱を最小限に抑え、パスワードを保存するためのセキュリティチームの厳格な要件があります。
どのような認証戦略を使用するべきでしょうか?
- A. G Suite Password Sync を使用してパスワードを Google に複製します。
- B. SAML 2.0 を介して既存の ID プロバイダに認証を渡します。
- C. Google Cloud Directory Sync ツールを使用して Google でユーザーをプロビジョニングします。
- D. ユーザーに企業のパスワードと一致するように Google のパスワードを設定するように依頼します。
Correct Answer: C
Googleのディレクトリにユーザーをプロビジョニング
グローバル ディレクトリは Google Cloud Platform と G Suite リソースの両方で利用でき、さまざまな方法でプロビジョニングすることができます。プロビジョニングされたユーザーはシングル サインオン(SSO)、OAuth、2段階認証などの豊富な認証機能を利用できます。
次のツールやサービスのいずれかを使用してユーザーを自動的にプロビジョニングすることができます。
– Google Cloud Directory Sync(GCDS)
– Google Admin SDK
– サードパーティコネクタ
GCDSは Google Cloud Platform と G Suite の両方でユーザーやグループのプロビジョニングを代行できるコネクタです。GCDS を使用することでユーザー、グループ、従業員以外の連絡先の追加、変更、削除を自動化することができます。LDAP クエリを使用して、LDAP ディレクトリ サーバーから Google Cloud Platform ドメインにデータを同期させることができます。この同期は一方通行でLDAP ディレクトリ サーバー内のデータが変更されることはありません。
Reference contents:
– エンタープライズ企業のベスト プラクティス | ドキュメント | Google Cloud
Question 25
会社はクラウドへの移行に成功し、データストリームを分析して運用の最適化を考えています。
この分析のための既存のコードを持っていないため、あらゆるオプションを検討しています。オプションにはバッチ処理とストリーム処理を組み合わせたものが含まれます。
どの技術を使用するべきでしょうか?
- A. Google Cloud Dataproc
- B. Google Cloud Dataflow
- C. Google Container Engine と Google Cloud Bigtable
- D. Google Compute Engine と Google BigQuery
Correct Answer: B
Google Cloud Dataflow はストリーム(リアルタイム)モードとバッチ(ヒストリカル)モードのデータを同等の信頼性と表現力で変換し、豊かにするための完全に管理されたサービスで複雑な回避策や妥協は必要ありません。
Reference contents:
– Dataflow | Google Cloud
Question 26
顧客は最近更新された Google App Engine アプリケーションの一部のユーザーが読み込みに約 30 秒かかるという報告を受けています。
この動作はアップデート前には報告されていませんでした。
どのような戦略を取るべきでしょうか?
- A. ISPと協力して問題を診断します。
- B. サポートチケットを開いて、問題を診断するためにネットワークキャプチャとフローデータを要求し、アプリケーションをロールバックします。
- C. 最初は以前の既知の良いリリースにロールバックし、その後 Stackdriver Trace と Logging を使用して開発/テスト/ステージング環境で問題を診断します。
- D. 以前の既知の良好なリリースにロールバックし、静かな時期に再度リリースをプッシュして調査します。その後、Stackdriver Trace と Logging を使って問題を診断します。
Correct Answer: C
Stackdriver Loggingは Google Cloud Platform や Amazon Web Services からのログ データやイベントの保存、検索、分析、監視、アラートを行うことができます。API は任意のソースから任意のカスタム ログ データを取り込み可能です。Stackdriver Logging はフル マネージド サービスで規模に応じて実行され、何千ものVM からアプリケーションやシステムのログ データを取り込みすることができます。さらに優れているのはすべてのログ データをリアルタイムで分析することができることです。
Reference contents:
– Cloud Logging | Google Cloud
Question 27
Google Compute Engine の本番用データベース仮想マシンにはデータファイル用にext4 形式の永続ディスクがあります。
データベースのストレージ容量が不足しようとしています。
最小限のダウンタイムで問題を修正するにはどうすればよいでしょうか?
- A. Google Cloud Console で永続ディスクのサイズを増やし、Linux でresize2fs コマンドを使用します。
- B. 仮想マシンをシャットダウンし、Google Cloud Console を使用して永続ディスクのサイズを増やした後、仮想マシンを再起動します。
- C. Google Cloud Console で永続ディスクのサイズを増やし、Linux の fdisk コマンドを使用して新しいスペースが使用できる状態になっていることを確認します。
- D. Google Cloud Console で仮想マシンに接続された新しい永続ディスクを作成し、フォーマットしてマウントし、新しいディスクにファイルを移動するようにデータベース サービスを構築します。
- E. Google Cloud Console で永続ディスクのスナップショットを作成し、スナップショットを新しい大きなディスクに復元し、古いディスクのマウントを解除し、新しいディスクをマウントして、データベース サービスを再起動します。
Correct Answer: A
Linux インスタンスではインスタンスに接続し、パーティションとファイル システムのサイズを手動で変更して、追加のディスク領域を使用します。
追加した領域を使用するためにディスクまたはパーティション上のファイル システムを拡張します。ディスク上にパーティションを拡張した場合はパーティションを指定します。ディスクにパーティションテーブルがない場合はディスク ID だけを指定します。
sudo resize2fs /dev/[DISK_ID][PARTITION_NUMBER]
ここで [DISK_ID] はデバイス名、[PARTITION_NUMBER] はファイル システムを変更するデバイスのパーティション番号です。
Reference contents:
– ゾーン永続ディスクの追加またはサイズ変更 | Compute Engine ドキュメント | Google Cloud
Question 28
顧客のアプリケーションはクレジットカード取引を処理する必要があります。
取引データや使用されている決済方法に関連する傾向を分析する機能を損なうことなく、PCI(Payment Card Industry)コンプライアンスの範囲を最小限する必要があります。
どのようにアーキテクチャを設計すべきでしょか?
- A. トークン化サービスを作成し、トークン化されたデータのみを保存します。
- B. クレジットカード データのみを処理する個別のプロジェクトを作成します。
- C. 個別のサブネットワークを作成し、クレジットカード データを処理するコンポーネントを分離します。
- D. PCI データを処理するすべてのVM にラベルを付けることで監査検出フェーズを合理化します。
- E. Google BigQuery へのログ エクスポートを有効にし、ACLとビューを使用して監査人と共有されるデータのスコープを設定します。
Correct Answer: A
Reference contents:
– Six Ways to Reduce PCI DSS Audit Scope by Tokenizing Cardholder data
Question 29
会社の大規模なWeb サイトのポートフォリオのクリック データ用のストレージ システムを選択する依頼がありました。
このデータはカスタム Web サイト分析パッケージから 1分間に 6,000 クリックの速度でストリーミングされます。1秒間に最大 8,500 クリックが発生します。データサイエンス チームとユーザーエクスペリエンス チームの将来の分析のために保存されている必要があります。
どのストレージ インフラストラクチャを選択すべきでしょうか?
- A. Google Cloud SQL
- B. Google Cloud Bigtable
- C. Google Cloud Storage
- D. Google Cloud Datastore
Correct Answer: B
Google Cloud Bigtable はリアルタイム アクセスとアナリティクスのワークロードの両方に適した、スケーラブルでフルマネージド ワイドカラム NoSQL データベースです。
次のような場合に適しています。
– 低遅延の読み取り/書き込みアクセス
– ハイスループット分析
– ネイティブ時系列サポート
一般的なワークロード:
– IoT、金融、アドテク
– パーソナライズ、推奨事項
– モニタリング
– 地理空間データセット
– グラフ
C: Google Cloud Storage は拡張性があり、フルマネージで信頼性が高く、コスト効率の高い Object/Blobstoreです。
次のような用途に適しています。
– 画像、写真、ビデオ
– オブジェクトとブロブ
– 非構造化データ
D: Google Cloud Datastore はWeb およびモバイルアプリケーション用のフルマネージドでスケーラブルの NoSQL ドキュメントデータベースです。
次のような用途に適しています。
– 半構造化されたアプリケーションデータ
– 階層データ
– 耐久性のあるキーバリューデータ
共通の作業負荷:
– ユーザープロファイル
– 製品カタログ
– ゲーム状態
Reference contents:
– クラウド ストレージ オプション | Google Cloud
Question 30
90 日以上前のバックアップ ファイルを Google Cloud Storage バケットから削除するソリューションを作成しています。
進行中の Google Cloud Storage の支払いを最適化したいと考えています。
どうすればよいでしょうか?
- A. ライフサイクル管理の構成をXML で記述して gsutil でバケットにプッシュします。
- B. ライフサイクル管理の構成をJSON で記述して gsutil でバケットにプッシュします。
- C. gsutil ls gs://backups/** を使用してcron スクリプトをスケジュールし、90 日以上より古いアイテムを検索して削除します。
- D. gsutil ls gs://backups/** を使用してcron スクリプトをスケジュールし、90 日以上より古いアイテムを見つけて削除してcron でスケジュールします。
Correct Answer: B
Question 31
会社ではローカルのデータセンターで実行されるApache Spark やHadoop ジョブの数と規模が急増すると予測しています。
クラウドを利用して 最小限の運用作業とコード変更でこの今後の需要を拡大できるようにしたいと考えています。
どのGCP プロダクトを使うべきでしょうか?
- A. Google Cloud Dataflow
- B. Google Cloud Dataproc
- C. Google Compute Engine
- D. Google Kubernetes Engine
Correct Answer: B
Google Cloud Dataproc は Google Cloud Platform でApache Spark とApache Hadoop のエコシステムを実行する高速で使いやすく、低コストでフルマネージド サービスです。Google Cloud Dataproc は小〜大規模のクラスタを迅速にプロビジョニングし、多くの一般的なジョブタイプをサポートし、Google Cloud Storage や Stackdriver Logging などの他の Google Cloud Platform サービスと統合されているため、TCO を削減できます。
Reference contents:
– Dataproc に関するよくある質問 | Dataproc ドキュメント | Google Cloud
Question 32
データベース管理チームから Google Compute Engine で動作する新しいデータベースサーバのパフォーマンスを改善するためにサポートを依頼されました。
このデータベースはパフォーマンス統計をインポートして正規化するためのもので、Debian Linux で動作するMySQL で構築されています。仮想マシン n1-standard-8 と 80 GBのSSD 永続ディスクを使用しています。
このシステムのパフォーマンスを向上させるには何を変更すべきでしょうか?
- A. 仮想マシンのメモリを 64 GBに増やします。
- B. PostgreSQL を実行する新しい仮想マシンを作成します。
- C. SSD 永続ディスクのサイズを動的に変更して 500 GB にします。
- D. パフォーマンス メトリクスウェア ハウスを Google BigQuery に移行する。
- E. データベースへの一括挿入を使用するようにすべてのバッチジョブを変更します。
Correct Answer: C
Question 33
正確でリアルタイムな天気図アプリケーションのパフォーマンスを最適化したいと考えています。
データはタイムスタンプとセンサーの読み取り値の形式で毎秒 10 回の読み取り値を送信する 50,000 個のセンサーから取得されます。
データはどこに保存するべきでしょうか?
- A. Google BigQuery
- B. Google Cloud SQL
- C. Google Cloud Bigtable
- D. Google Cloud Storage
Correct Answer: C
Google Cloud Bigtable はリアルタイム アクセスとアナリティクスのワークロードの両方に適した、スケーラブルでフルマネージド ワイドカラム NoSQL データベースです。
次のような場合に適しています。
– 低遅延の読み取り/書き込みアクセス
– ハイスループット分析
– ネイティブ時系列サポート
一般的なワークロード:
– IoT、金融、アドテク
– パーソナライズ、推奨事項
– モニタリング
– 地理空間データセット
– グラフ
Reference contents:
– クラウド ストレージ オプション | Google Cloud
Question 34
会社のユーザーフィードバック ポータルは 2つのゾーンに複製された標準のLAMP スタックで構成されています。
これは us-central1 リージョンにデプロイされ、データベースを除くすべてのレイヤーでオートスケールのマネージド インスタンス グループを使用しています。現在 ポータルにアクセスできるのはごく一部の顧客のみです。これらの条件ではポータルは 99.99% の可用性 SLA を満たしています。しかし、次の四半期には認証されていないユーザーを含むすべてのユーザーがポータルにアクセスできるようにする予定です。システムがSLA を維持していることを確認するために回復力テスト戦略を策定する必要があります。
どうすればよいでしょうか?
- A. 既存のユーザー入力をキャプチャし、すべてのレイヤーでオートスケールがトリガーされるまでキャプチャしたユーザー負荷を再生します。同時にいずれかのゾーンのすべてのリソースを終了させます。
- B. 合成のランダム ユーザー入力を作成して少なくとも1つのレイヤーでオートスケール ロジックがトリガされるまで合成負荷を再生し、両方のゾーンのランダムリソースを終了させることでシステムに「chaos」を導入します。
- C. 新しいシステムをより大きなユーザーグループに公開し、すべてのレイヤーでオートスケール ロジックがトリガされるまで、グループのサイズを毎日増加させます。同時に両方のゾーンのランダムリソースを終了させます。
- D. 既存のユーザー入力をキャプチャし、リソース利用率が 80 %を超えるまでキャプチャしたユーザー負荷を再生します。また、既存ユーザーのアプリ利用状況に基づいて推定ユーザー数を導き出し、予想される負荷の 200 %を処理するのに十分なリソースをデプロイします。
Correct Answer: D
Question 35
チームの開発者の 1人が次のDockerfile を使って Google Container Engine にアプリケーションをデプロイしました。
アプリケーションのデプロイに時間がかかりすぎると報告しています。
FROM ubuntu;16.04
COPY . /src
RUN apt-get update && apt-get install - y python python-pip
RUN pip install -r requirements.txtアプリの機能に悪影響を及ぼすことなく、このDockerfile を最適化してデプロイ時間を短縮したいと思います。
どのようなアクションを行うべきでしょうか?(回答を 2つ選択してください)
- A. pip を実行した後にPython を削除します。
- B. requirements.txt から依存関係を削除する。
- C. Alpine Linux のようなスリム化されたベースイメージを使用する。
- D. Google Container Engine ノードプールにはより大きなマシンタイプを使用します。
- E. パッケージの依存関係(Pythonとpip)がインストールされた後にソースをコピーします。
Correct Answer: C、E
アップロードされたアプリのサイズを制限したり、Dockerfileが存在する場合は必要なビルドの複雑さを制限したり、高速で信頼性の高いインターネット接続を確保したりすることでデプロイの速度を変えることができます。
Alpine Linux はmusl libc とbusybox を中心に構築されています。これにより、従来のGNU/Linux ディストリビューションよりも小さく、リソース効率が高くなっています。コンテナに必要な容量は 8 MB以下でディスクへの最小限のインストールで約 130 MBのストレージが必要です。本格的な Linux 環境を手に入れるだけでなく、リポジトリから多くのパッケージを選択することができます。
Reference contents:
– Google App Engine is slow to deploy, hangs on “Updating service [someproject]…”
– about
– Best practices for writing Dockerfiles
Question 36
ソリューションではステージング環境やテスト環境では確認できなかったパフォーマンス バグが本番環境で発生しています。
将来的にこの問題が発生しないようにテストとデプロイの手順を調整したいと考えています。
どうすればよいでしょうか?
- A. 本番環境にデプロイする回数を小さくします。
- B. 変更を小さくして本番環境にデプロイします。
- C. テスト環境とステージング環境の負荷を増やします。
- D. 本番環境にデプロイする前に小さなサブセットのユーザーに変更をデプロイします。
Correct Answer: D
Question 37
マイクロサービス ベースのアプリケーションへの少数のAPI リクエストには非常に長い時間がかかります。
API への各リクエストは多くのサービスを経由していることを知っています。そのような場合、どのサービスに最も時間がかかるかを知りたいと考えています。
どうすればよいでしょうか?
- A. アプリケーションにタイムアウトを設定してリクエストをより早く失敗できるようにします。
- B. 各リクエストのカスタム指標を Stackdriver Monitoring に送信します。
- C. Stackdriver Monitoring を使用してAPI のレイテンシが高いときインサイトを探します。
- D. Stackdriver Trace を使用してアプリケーションを計測し、各マイクロサービスでのリクエストのインストゥルメント化をします。
Correct Answer: D
Reference contents:
– クイックスタート | Cloud Trace | Google Cloud
Question 38
1日のトラフィックが多い時間帯にリレーショナル データベースの1つがクラッシュし、レプリカがマスターにプロモートされていません。
将来的にこのような事態を回避したいと考えています。
どうすればよいでしょうか?
- A. 別のデータベースを使用します。
- B. データベースに大きなインスタンスを選択します。
- C. データベースのスナップショットをより定期的に作成します。
- D. データベースの定期的にスケジュールされたフェイルオーバーを実装します。
Correct Answer: D
Question 39
組織では訴訟手続きで将来分析するためにすべてのアプリケーションからの計測を 5 年間保持する必要があります。
どのアプローチを使用すべきでしょうか?
- A. セキュリティチームに各プロジェクトのログへのアクセスを許可します。
- B. すべてのプロジェクトに対して Stackdriver Monitoring を構成して Google BigQuery にエクスポートします。
- C. デフォルトの保持ポリシーを使用してすべてのプロジェクトに対して Stackdriver Monitoring を構成します。
- D. すべてのプロジェクトに対してスタックドライバー監視を構成し、Google Cloud Storage にエクスポートします。
Correct Answer: D
Stackdriver Logging はクラウドやオープンソース アプリケーションサービスからのログをフィルタリング、検索、表示する機能を提供します。ダッシュボードとアラートに組み込まれているログの内容に基づいてメトリックを定義できます。ログを GoogleBigQuery、Google Cloud Storage、Google Cloud Pub/Sub にエクスポートできます。
Reference contents:
– 運用: Cloud Monitoring と Logging | Google Cloud
Question 40
会社はオンプレミスのユーザー認証 PostgreSQL データベースのバックアップ レプリカを Google Cloud Platform に構築することを決定しました。
データベースは 4 TBで大規模な更新が頻繁に行われます。レプリケーションにはプライベート アドレス空間通信が必要です。
どのネットワーキングアプローチを使用するべきでしょか?
- A. Dedicated Interconnect
- B. データセンターのネットワークに接続した Cloud VPN。
- C. オンプレミスに設置されたNAT とTLS 変換ゲートウェイ。
- D. データセンターのネットワークに接続されたVPN サーバーをインストールされた Google Compute Engine インスタンス。
Correct Answer: A
Dedicated Interconnect はオンプレミスのネットワークと Google のネットワークに物理的に接続と RFC 1918 通信を提供します。専用インターコネクトを使用するとネットワーク間で大量のデータを転送することができるため、公共のインターネット上で帯域幅を追加購入したり、VPN トンネルを使用したりするよりも費用対効果が高くなります。
メリット
-オンプレミスネットワークとVPC ネットワーク間のトラフィックはパブリック インターネットを経由しません。トラフィックは少ないホップ数で専用の接続を通過するため、トラフィックが落ちたり中断される可能性のある障害ポイントが少なくなります。
– VPCネットワークの内部(RFC 1918)IPアドレスは、オンプレミスネットワークから直接アクセスできます。内部 IP アドレスに到達するために NAT デバイスや VPN トンネルを使用する必要はありません。現在、内部 IP アドレスにアクセスできるのは専用の接続を介してのみです。Google の外部 IP アドレスにアクセスするには別の接続を使用する必要があります。
– Google への接続はニーズに応じて拡張することができます。接続容量は 1 つ以上の 10 Gbps イーサネット接続を介して提供され、最大8つの接続(相互接続ごとに合計80 Gbps)があります。
– VPC ネットワークからオンプレミス ネットワークへの出力トラフィックのコストが削減されます。Google のネットワークとの間で大量のトラフィックが発生する場合は専用の接続が最も安価な方法です。
Reference contents:
– Dedicated Interconnect の概要 | Google Cloud
Question 41
監査人は 12 か月ごとにチームを訪問し、過去 12 か月の Google Cloud Identity and Access Management(Cloud IAM)ポリシーの変更点をすべて確認するよう求められます。
分析と監査のプロセスを合理化と迅速化したいと考えています。
どうすればよいでしょうか?
- A. Google Stackdriver のカスタムアラートを作成して監査人に送信します。
- B. Google BigQuery へのログエクスポートを有効にし、ACLとビューを使用して監査人と共有するデータをスコープを設定します。
- C. Google Cloud Functions を使用してログエントリを Google Cloud SQL に転送し、ACLとビューを使用して監査人のビューを制限します。
- D. Google Cloud Storage のログ エクスポートを有効にして監査ログを Google Cloud Storage バケットにエクスポートし、バケットへのアクセスを委任します。
Correct Answer: D
Question 42
30 個のマイクロサービスを持つ大規模な分散アプリケーションを設計しています。
分散マイクロサービスはデータベースのバックエンドに接続して資格情報を安全に保存したいと考えています。
資格情報はどこに保存するべきでしょうか?
- A. ソースコード
- B. 環境変数.
- C. シークレット管理
- D. ACL によるアクセスを制限した設定ファイル
Correct Answer: C
Reference contents:
– Secret Manager のコンセプトの概要 | Secret Manager のドキュメント | Google Cloud
Question 43
リードエンジニアがレガシーデータセンターに仮想マシンをデプロイするカスタムツールを作成しました。
カスタムツールを新しいクラウド環境に移行し、 Google Cloud Deployment Manager の採用を提案したいと考えています。
Google Cloud Deployment Manager に移行することで伴うビジネスリスクは何でしょうか?(回答を 2つ選択してください)
- A. Google Cloud Deployment Manager はPython を使用しています。
- B. Google Cloud Deployment Manager API は将来的に非推奨になる可能性があります。
- C. Google Cloud Deployment Manager は会社のエンジニアに知見がありません。
- D. Google Cloud Deployment Manager を実行するには Google API サービスのアカウントが必要です。
- E. Google Cloud Deployment Manager を使用するとクラウド リソースを永久的に削除することができます。
- F. Google Cloud Deployment Manager は Google Cloud リソースの自動化のみをサポートしています。
Correct Answer: C、F
Question 44
開発マネージャが新しいアプリケーションを構築しています。
要件を確認し、それを満たすためにどのようなクラウド テクノロジーを使用できるかを特定するように依頼しています。
このアプリケーションの要件は以下になります。
– クラウド ポータビリティのためのオープンソース技術をベースにしていること
– 需要に応じて計算容量を動的にスケーリング
– 継続的なソフトウェア配信をサポート
– 同じアプリケーション スタックの複数の分離されたコピーの実行
– 動的テンプレートを使用したアプリケーション バンドルの展開
– URL に基づいてネットワーク トラフィックを特定のサービスにルーティング
どの技術の組み合わせがこの要件をすべて満たせることができるしょうか?
- A. Google Kubernetes Engine、Jenkins、Helm
- B. Google Kubernetes Engine、Google Cloud Load Balancing
- C. Google Kubernetes Engine、Google Cloud Deployment Manager
- D. Google Kubernetes Engine、Jenkins、Google Cloud Load Balancing
Correct Answer: D
Jenkins はビルド、テスト、デプロイメントのパイプラインを柔軟に調整できるオープンソースの自動化サーバーです。Google Kubernetes Engine はコンテナ用の強力なクラスタ マネージャとオーケストレーションシステムであるKubernetes のホスト版です。
継続的デリバリー(CD)パイプラインを設定する必要がある場合、Google Kubernetes Engine にJenkins をデプロイすることで標準的なVM ベースのデプロイよりも重要なメリットが得られます。
A:Helm はKubernetes のチャートを管理するためのツールです。チャートはあらかじめ設定されたKubernetes リソースのパッケージです。
Helm を使用して次のことを行います。
– Kubernetes チャートとしてパッケージ化された人気のソフトウェアを検索して使用
– アプリケーションをKubernetes のチャートとして共有
– Kubernetes アプリケーションの再現性のあるビルドを作成
– Kubernetes のマニフェストファイルをインテリジェントに管理
– Helm パッケージのリリース管理
Reference contents:
– Kubernetes Engine での Jenkins | ソリューション | Google Cloud
Question 45
Google Compute Engineを使用してプリエンプティブル Linux 仮想マシン インスタンスをいくつか作成しました。
仮想マシンが先取りされる前にアプリケーションを適切にシャットダウンしたいと思っています。
何をすべきでしょうか?
- A. etc/rc.6.d/ ディレクトリに k99.shutdown という名前のシャットダウン スクリプトを作成します。
- B. Linux でxinetd サービスとして登録されているシャットダウン スクリプトを作成し、Stackdriver のエンドポイント チェックでサービスを呼び出すように構築します。
- C. シャットダウン スクリプトを作成して新しい仮想マシン インスタンスを作成する際に Google Cloud Console で shutdown-script というキーを持つ新しいメタデータ エントリの値として使用します。
- D. Linux でxinetd サービスとして登録されたシャットダウン スクリプトを作成し、gcloud compute instances add-metadataコマンドを使用してサービスのURL をshutdown-script-url キーで新しいメタデータ エントリの値として指定します。
Correct Answer: C
起動スクリプトまたはシャットダウン スクリプトは起動スクリプトのメタデータ キーを使用して、メタデータ サーバーから指定されます。
Reference contents:
– 起動スクリプトの実行 | Compute Engine ドキュメント | Google Cloud
Question 46
組織には Google CloudPlatform の同じネットワークにデプロイされた3層のWeb アプリケーションがあります。
各層(Web、API、データベース)は他の層とは独立して拡張できます。ネットワーク トラフィックはWeb 層を通ってAPI 層に流れ、その後にデータベース層に流れます。トラフィックはWeb とデータベース層の間を流れてはなりません。
ネットワークはどのように構成するべきでしょうか?
- A. 各層を別のサブネットワークに追加します。
- B. 個々のVMにソフトウェアベースのファイアウォールを設定します。
- C. 各層にタグを追加し、目的のトラフィック フローを許可するようにルートを設定します。
- D. 各階層にタグを追加し、目的のトラフィック フローを許可するようにファイアウォール ルールを設定します。
Correct Answer: D
GCP はルールとタグを通じてファイアウォール ルールを適用します。GCP のルールとタグは 一度定義すればすべてのリージョンで使用できます。
Reference contents:
– OpenStack ユーザーのための Google Cloud
– Building three-tier architectures with security groups | AWS News Blog
Question 47
開発チームは新しいLinux カーネルモジュールを Google Compute Engine(GCE)仮想マシンのバッチサーバーにインストールしたことで夜間のバッチ処理を高速化しました。
インストールから 2日後、バッチサーバーの 50 %が夜間のバッチ実行に失敗しました。失敗の詳細を収集して開発チームに伝えたいと考えています。
どのようなアクションは行うべきでしょうか?(回答を 3つ選択してください)
- A. Stackdriver Logging を使用してモジュールのログエントリを検索します。
- B. API または Google Cloud Console を使用してデバッグ GCE アクティビティのログを読み込みます。
- C. gcloud または Google Cloud Console を使用してシリアルコンソールに接続してログを観察します。
- D. アクティビティ ログを使用して障害が発生したサーバーのライブマイグレーション イベントが発生したかどうかを確認します。
- E. Google Stackdriver のタイムラインを障害時間に合わせて調整してバッチサーバーの指標を観察します。
- F. デバッグ VM をイメージにエクスポートし、ローカルサーバー上でイメージを実行します。
Correct Answer: A、C、E
Question 48
会社は低リスクでクラウドを試用したいと考えています。
約 100 TBのログデータをクラウドにアーカイブし、クラウドで利用できるアナリティクス機能をテストしたいと考えている。
どのステップを行うべきでしょうか?(回答を2つ選択してください)
- A. ログを Google BigQuery に読み込みます。
- B. ログを Google Cloud SQL に読み込みます。
- C. ログを Google Stackdriver にインポートします。
- D. ログを Google Cloud Bigtable に挿入します。
- E. ログファイルを Google Cloud Storage にアップロードします。
Correct Answer: A、E
Question 49
自己回復のためにソースコードの変更をインスタンス グループのインフラストラクチャにデプロイできるパイプラインを作成しました。
その変更の1つが主要業績評価指標に悪影響を与えています。修正方法がわからず、調査には最大 1 週間かかる可能性があります。
どうすればよいでしょうか?
- A. サーバーにログインしてローカルでfox を繰り返し処理します。
- B. ソースコードの変更を元に戻し、デプロイメント パイプラインを再実行します。
- C. 悪いコードの変更があったサーバーにログインして前のコードをスワップします。
- D. インスタンス グループ テンプレートを前のテンプレートに変更してすべてのインスタンスを削除します。
Correct Answer: B
Question 50
組織は異なる部門のIAM ポリシーを個別にしますが一元的に制御したいと考えています。
どのアプローチ行うべきでしょうか?
- A. 複数のフォルダを持つ複数の組織。
- B. 各部門に1つずつ、複数の組織。
- C. 部門ごとにフォルダを持つ単一の組織。
- D. 複数のプロジェクトを持ち、それぞれが中央の所有者を持つ単一の組織。
Correct Answer: C
フォルダは Google Cloud Platform Resource Hierarchy のノードです。
フォルダにはプロジェクト、他のフォルダ、または両方の組み合わせを含めることができます。フォルダを使用して階層内の組織の下でプロジェクトをグループ化することができます。例えば、それぞれに独自の GCP リソースのセットがある場合があります。フォルダを使用するとこれらのリソースを部門ごとにグループ化できます。フォルダは共通のIAM ポリシーを共有するリソースをグループ化するために使用されます。1つのフォルダには複数のフォルダやリソースを含めることができますが 1つのフォルダやリソースの親は 1つだけです。
Reference contents:
– フォルダの作成と管理 | Resource Manager のドキュメント | Google Cloud
Question 51
カスタム Java アプリケーションを Google App Engine にデプロイしました。
デプロイに失敗し、次のようなスタックトレースが表示されます。
どうすればよいでしょうか?
java.lang.SecurityException: SHA1 diest digest error for com/Altostart/CloakeServlet.class
at com.google.appengine.runtime.Request.prosess-d36f818a24b8cf1d (Request.java)
at sun.security.util.ManifestEntryVerifier.verify (ManifestEntryVerifier.java:210)
at.java.util.har.JarVerifier.prosessEntry (JarVerifier.java:218)
at java.util.jar.JarVerifier.update (JarVerifier.java:205)
at java.util.jar.JarVerifiersVerifierStream.read (JarVerifier.java:428)
at sun.misc.Resource.getBytes (Resource.java:124)
at java.net.URL.ClassLoader.defineClass (URCClassLoader.java:273)
at sun.reflect.GenerateMethodAccessor5.invoke (Unknown Source)
at sun.reflect.DelegatingMethodAccessorImp1.invoke (DelegatingMethodAccessorImp1.java:43)
at java.lang.reflect.Method.invoke (Method.java:616)
at java.lang.ClassLoader.loadClass (ClassLoader.java:266)- A. 不足しているJAR ファイルをアップロードしアプリケーションを再デプロイします。
- B. すべての JAR ファイルにデジタル署名をしてアプリケーションを再デプロイします。
- C. SHA1 の代わりに MD5 ハッシュを使用して CLoakedServlet クラスをリコンパイルします。
Correct Answer: B
Question 52
モバイルチャット アプリケーションを設計しています。
特定のユーザーによって送信されたメッセージを提供することでチャットメッセージをなりすましできないようにしたいと考えています。
どうすればよいでしょうか?
- A. メッセージのクライアント側に発信元のユーザ識別子と送信先のユーザをタグ付けします。
- B. メッセージのクライアント側を共有鍵を用いたブロックベースの暗号化で暗号化します。
- C. 公開鍵基盤(PKI)を用いて発信元ユーザの秘密鍵を用いてメッセージのクライアント側を暗号化します。
- D. 信頼できる証明書局を使用してクライアント アプリケーションとサーバ間のSSL 接続を有効にします。
Correct Answer: C
Question 53
災害復旧計画の実施の一環として、会社では Cloud VPN 接続を使用してプライベート データセンターから GCP プロジェクトに本番用のMySQL データベースを複製しようとしています。
遅延の問題と少量のパケットロスが発生し、レプリケーションが中断しています。
どうすればよいでしょうか?
- A. UDP を使用するように複製を構成します。
- B. Dedicated Interconnect を構成します。
- C. Google Cloud SQL を使用してデータベースを毎日復元します。
- D. VPN 接続を追加し、負荷分散を行います。
- E. 複製されたトランザクションを Google Cloud Pub/Sub に送信します。
Correct Answer: B
Question 54
顧客のカスタマーサポート ツールではメールやチャットでの会話をすべて Google Cloud Bigtable に記録し、保持と分析のために利用しています。
個人を特定できる情報や支払いカード情報のデータを初期保存する前にを削除するための推奨されるアプローチは何でしょうか?
- A. SHA256 を使用してすべてのデータをハッシュ化します。
- B. 楕円曲線暗号を用いてすべてのデータを暗号化します。
- C. Google Cloud Data Loss Prevention API を使用してデータの匿名化します。
- D. 正規表現を使用して、電話番号、電子メールアドレス、クレジットカード番号を検索して再編集します。
Correct Answer: C
Reference contents:
– PCI データ セキュリティ基準の遵守 | アーキテクチャ | Google Cloud
Question 55
Google Cloud Shell を使用しており、数週間後に使用するカスタム ユーティリティをインストールする必要があります。
ファイルをデフォルトの実行パスに保存し、セッション間で保持できるようにするにはどこに保存できるでしょうか?
- A. ~/bin
- B. Google Cloud Storage
- C. /google/scripts
- D. /usr/local/bin
Correct Answer: A
Question 56
Google Compute Engine インスタンスとオンプレミスのデータセンターとの間にプライベート接続を作成したいと考えています。
20 Gbps 以上の接続が必要で Google の ベスト プラクティスに従います。
どのように接続を設定すればよいでしょうか?
- A. VPC を作成し、Dedicated Interconnect を使用してオンプレミスのデータセンターに接続します。
- B. VPC を作成し、単一の Cloud VPN を使用してオンプレミス データ センターに接続します。
- C. クラウド コンテンツ配信ネットワーク(Cloud CDN)を作成し、専用のインターコネクトを使用してオンプレミスのデータセンターに接続します。
- D. クラウド コンテンツ配信ネットワーク(Cloud CDN)を作成し、単一の Cloud VPN を使用してあなたのオンプレミスのデータセンターに接続します。
Correct Answer: A
Question 57
スタートアップの GCP の試用をサポートするためのビジネスプロセスを分析と定義していますが、プロダクトに対する消費者の需要がどのようなものになるかはまだわかりません。
上司は GCP サービスのコストを最小限に抑え、Google のベスト プラクティスに従うことを求めています。
何をすべきでしょうか?
- A. 無料枠と継続利用割引を利用します。サービスコスト管理のためのスタッフ ポジションをプロビジョニングします。
- B. 無料枠と継続利用割引を利用します。サービスコスト管理についてチームにトレーニングを提供します。
- C. 無料枠と確約利用割引を利用します。サービスコスト管理のためのスタッフ ポジションをプロビジョニングします。
- D. 無料枠と確約利用割引を利用します。サービスコスト管理についてチームにトレーニングを提供します。
Correct Answer: B
Comments are closed