![[GCP] Google Cloud Certified:Professional Cloud Architect](https://www.cloudsmog.net/wp-content/uploads/google-cloud-certified_professional-cloud-architect-1200x675.jpg)
※ 他の問題集は「タグ:Professional Cloud Architect の模擬問題集」から一覧いただけます。
英語版は「Professional Cloud Architect 模擬問題集 (Version 2018-08-09) (English)」をご覧ください。
この模擬問題集のバージョンが「2018年8月9日 版」になります。2018年のため、GCP プロダクト名称や仕様が現在と異なっていますが、当時はどんな問題だったのか?を感じていただければと思います。
パブリッククラウド や Gooogle テクノロジー の発達は早いです。
Google Cloud 認定資格 – Professional Cloud Architect 模擬問題集(42問)
Version 2018-08-09
QUESTION 1
この質問については、JencoMart のケーススタディを参照してください。
JencoMart は、ユーザ プロファイル ストレージを Google Cloud Datastore に、アプリケーションサーバを Google Compute Engine(GCE)に移行することを決定しました。移行中は既存のインフラストラクチャはアップロードするために Google Cloud Datastore にアクセスする必要があります。
どのようなサービス アカウント キー管理戦略をお勧めしますか?
- A. オンプレミス インフラストラクチャおよびGCE 仮想マシン(VM)のサービス アカウント キーをプロビジョニングします。
- B. ユーザー アカウントを使用してオンプレミス インフラストラクチャを認証し、VMのサービス アカウントキーをプロビジョニングします。
- C. オンプレミス インフラストラクチャにサービス アカウント キーをプロビジョニングし、VMに Google Cloud Platform 管理キー(Google Cloud Key Management Service)を使用します。
- D. オンプレミス インフラストラクチャ用のカスタム認証サービスをGCE / Google Container Engine (Google Kubernetes Engine)に導入し、VMに GCP 管理キーを使用します。
Correct Answer: C
Google Cloud Platformへのデータの移行:別のクラウド プロバイダーで発生するデータ処理があり、処理したデータを Google Cloud Platform に転送するとします。 外部クラウド上の仮想マシンのサービス アカウントを使用して、データを Google Cloud Platform にプッシュできます。これを行うにはサービス アカウントを作成するときにサービス アカウント キーを作成してダウンロードし、外部プロセスからそのキーを使用し、Google Cloud Platform API を呼び出す必要があります。
References:
・サービス アカウントについて
QUESTION 2
この質問については、JencoMart のケーススタディを参照してください。
JencoMar tは、アジアへのトラフィックを提供する Google Cloud Platform 上に彼らのアプリケーションのバージョンを構築しました。ビジネスおよび技術的な目標に対する成功を測定する必要があります。
どの指標を追跡する必要がありますか。
- A. アジアからのリクエストのエラー率。
- B. 米国とアジアの待ち時間の違い。
- C. アジアからの総訪問数、エラー率、および待ち時間。
- D. アジアのユーザーの合計訪問数と平均待ち時間。
- E. データベースに存在する文字セットの数。
Correct Answer: D
シナリオから:ビジネス要件は「サービスをアジアに拡大します。」、技術要件は「アジアの遅延を短縮します。」が含まれます。
QUESTION 3
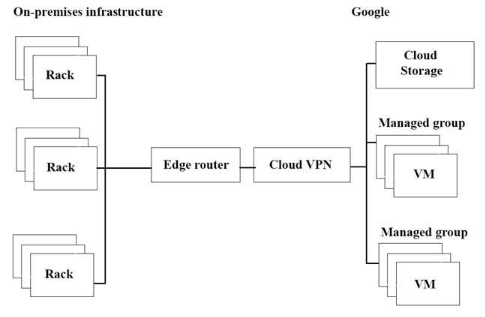
この質問については、JencoMart のケーススタディを参照してください。
JencoMart のアプリケーションの Google Cloud Platform(GCP)への移行が遅延しています。上図にインフラストラクチャがあり、スループットを最大化したいと考えています。。
潜在的なボトルネックを 3つ選びなさい。(回答を3つ)
- A. スループットを制限する単一のVPN トンネル。
- B. このタスクには適さない Google Cloud Storage のレイヤー。
- C. 長距離の操作には適していないコピー コマンド。
- D. オンプレミスマシンよりもGCP 仮想マシン(VM)が少ない。
- E. このタスクには適してないVMの外部にある独立したストレージ レイヤー。
- F. オンプレミス インフラストラクチャとGCP 間の複雑なインターネット接続。
Correct Answer: A、C、E
QUESTION 4
この質問については、JencoMart のケーススタディを参照してください。
JencoMart は、ユーザー プロファイル データベースを Google Cloud Platform に移動したいと考えています。
どのGoogle データベースを使用する必要がありますか?
- A. Google Cloud Spanner.
- B. Google BigQuery.
- C. Google Cloud SQL.
- D. Google Cloud Datastore.
Correct Answer: D
Google Cloud Datastore の一般的なワークロード:
– User profiles
– Product catalogs
– Game state
References:
– クラウド ストレージ プロダクト
– Cloud Datastore の概要
QUESTION 5
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Games は、新しいバックエンドを Google Cloud Platform(GCP)にデプロイしました。 バックエンドの新しいバージョンが公開される前に、それらのバックエンドの完全なテストプロセスを作成します。 テスト環境を経済的な方法で拡張する必要があります
どのようにプロセスを設計するべきでしょうか?
- A. 本番環境の負荷をシミュレートするために、GCP でスケーラブルな環境を作成します。
- B. 既存のインフラストラクチャを使用して、GCP ベースのバックエンドを大規模にテストします。
- C. GCP 内部のリソースを使用して負荷をシミュレートし、アプリケーションの各コンポーネントにストレステストを組み込みます。
- D. GCP で一連の静的環境を作成して、さまざまなレベルの負荷(高、中、低 など)をテストします。
Correct Answer: A
シナリオから:ゲームバック エンド プラットフォームの要件
– ゲーム アクティビティに基づいて動的に拡大または縮小します。
– マネージド NoSQL データベース サービスに接続します。
– Linux ディストリビューションのカスタマイズを実行します。
QUESTION 6
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Games は、継続的パイプラインのセットアップを望んでいます。そのアーキテクチャには、迅速に更新およびロールバックできるようにしたい多数の小さなサービスが含まれています。
Mountkirk Games には次の要件があります。
- サービスは、米国とヨーロッパの複数の地域に冗長的に展開されます。
- フロント エンド サービスのみがパブリック インターネットに公開されます。
- サービス群に単一のフロント エンド IP を提供できます。
- デプロイメント アーティファクトは不変です。
どのGoogle Cloud Platform プロダクトを使用するべきでしょうか?
- A. Google Cloud Storage、Google Cloud Dataflow、Google Compute Engine.
- B. Google Cloud Storage、Google App Engine、Google Network Load Balancer.
- C. Google Container Registry、Google Container Engine、Google HTTP(S) Load Balancer.
- D. Google Cloud Functions、Google Cloud Pub/Sub、Google Cloud Deployment Manager.
Correct Answer: D
Google Cloud Functions は、クラウドサービスを構築して接続するためのサーバーレス環境です。
Google Cloud Pub / Sub は、エンタープライズメッセージ指向ミドルウェアのスケーラビリティ、柔軟性、信頼性をクラウドにもたらします。 送信者と受信者を分離する多対多の非同期メッセージングを提供することにより、独立して記述されたアプリケーション間の安全で可用性の高い通信が可能になります。Google Cloud Pub / Sub は、開発者が Google Cloud Platform 上および外部でホストされるシステムを迅速に統合するのに役立つ、低遅延で耐久性のあるメッセージングを提供します。
– A:Google Cloud Dataflow は、ストリーム(リアルタイム)モードとバッチ(履歴)モードでデータを変換および強化するための完全に管理されたサービスです。
– C:プライベート Docker コンテナ イメージをGoogle Cloud Platformに保存して、高速でスケーラブルな取得と展開を実現します。Google Container Registry は、一般的な継続的配信システムで動作するプライベート Docker リポジトリです。Google Cloud Platform 上で実行され、Google のセキュリティで保護されたインフラ ストラクチャで一貫した稼働時間を提供します。使用するストレージと下りネットワークに対してのみお支払いいただきます。画像ごとの料金はかかりません。
QUESTION 7
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Games のゲームサーバーは、自動的に適切にスケーリングされません。先月、新機能を発表し、それが突然大人気となりました。記録的な数のユーザーがサービスを利用しようとしていますが、それらの多くは503 エラーの表示と応答時間が非常に遅いです。
まずは何を調査するべきでしょうか?
- A. データベースがオンラインであることを確認します。
- B. プロジェクトの割り当てを超えていないことを確認します。
- C. 新しい機能コードによってパフォーマンスのバグが発生していないことを確認します。
- D. 負荷 テストチームが運用環境に対してツールを実行していないことを確認します。
Correct Answer: B
503 はサービス 使用不可 エラーです。データベースがオンラインの場合は、すべてのユーザーに503 エラーが表示されます。
QUESTION 8
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Games は、分離されたアプリケーション環境を展開するための、再現可能で構成可能なメカニズムを作成する必要があります。
開発者とテスト 担当者は互いの環境とリソースにアクセスできますが、ステージング リソースや本番リソースにはアクセスできません。ステージング環境は、本番環境から一部のサービスにアクセスする必要があります。
開発環境をステージング環境と本番環境から分離するには、どうすればよいですか?
- A. 開発とテスト用のプロジェクトと、ステージングとプロダクション用のプロジェクトを作成します。
- B. 開発とテスト用のネットワークと、ステージングと実稼働用のネットワークを作成します。
- C. 開発用に1つのサブネットワークを作成し、ステージングと実動用に別のサブネットワークを作成する
- D. 開発用に1つ、ステージング用に2つ目、プロダクション用に3つ目のプロジェクトを作成します。
Correct Answer: A
References:
– Google App Engine Go 1.12+ Standard Environment documentation
QUESTION 9
最近の監査により、GCP プロジェクトで新しいネットワークが作成されたことがわかりました。 このネットワークでは GCE インスタンスには世界中に開かれたSSH ポートがあります。このネットワークの発信元を検出する必要があります。
何をするべきでしょうか?
- A. Stackdriver Alerting Console でCreate VM エントリを検索します。
- B. [ホーム] セクションの[アクティビティ] ページに移動します。 カテゴリを[データアクセス] に設定し、[VMエントリの作成] を検索します。
- C.コンソールの 「Logging」 セクションで、Logging セクションとして 「GCE Network」 を指定します。[Create Insert] エントリを検索します。
- D.プロジェクト SSHキーを使用して GCE インスタンスに接続します。 システムログで以前のログインを特定し、プロジェクト 所有者リストと一致させます。
Correct Answer: C
A:Stackdriver Alerting Console を使用するには、最初にアラートポリシーを設定する必要があります。
B:データアクセス ログには読み取り専用操作のみが含まれます。
-監査ログは、誰が何を、どこで、いつ行ったかを判断するのに役立ちます。
-Cloud Audit Loggingは、2種類のログを返します。
管理アクティビティログ
データアクセスログ:読み取り専用操作を実行する操作のログ エントリが含まれます。get、list、aggregated list メソッドなどのデータは変更されません。
QUESTION 10
US-Central リージョンの実稼働しているLinux 仮想マシンのコピーを作成します。本番の仮想マシンに変更があった場合は、コピーの管理と交換を簡単にしたいと考えています。 そして、コピーを新しいインスタンスとしてUS-East リージョンの別のプロジェクトに展開します。
どの手順を行うべきでしょうか?
- A. Linuxのdd コマンドとnetcat コマンドを使用して、ルートディスクの内容をUS-East リージョン内の新しい仮想マシン インスタンスにコピーしてストリーミングします。
- B. US-East リージョンで新しい仮想マシン インスタンスを作成する場合は、ルートディスクのスナップショットを作成し、そのスナップショットをルートディスクとして選択します。
- C. Linuxのdd コマンドを使用してルートディスクからイメージファイルを作成し、US-East リージョンに新しい仮想マシン インスタンスを作成します。
- D. ルートディスクのスナップショットを作成し、そのスナップショットからGoogle Cloud Storage にイメージファイルを作成し、ルートディスクのイメージファイルを使用してUS-East リージョンに新しい仮想マシン インスタンスを作成します。
Correct Answer: D
QUESTION 11
会社は、単一のMySQL インスタンスで複数のデータベースを実行しています。定期的に特定のデータベースのバックアップを取る必要があります。バックアップ アクティビティはできるだけ早く完了する必要があり、ディスクのパフォーマンスに影響を与えることはできません。
ストレージをどのように構成する必要がありますか?
- A. gcloud ツールを使用して永続ディスク スナップショットを使用して定期的なバックアップを作成するようにcron ジョブを構成します。
- B. バックアップの場所としてローカル SSD ボリュームをマウントします。バックアップが完了したら、gsutil を使ってバックアップをGoogle Cloud Storage に移動します。
- C. gcsfise を使用してGoogle Cloud Storage バケットをボリュームとしてインスタンスに直接マウントし、mysqldump を使用してマウントした場所にバックアップを書き込みます。
- D. 追加の永続ディスク ボリュームをRAID10 arrayの各仮想マシン(VM)インスタンスにマウントし、LVM を使ってスナップショットを作成してGoogle Cloud Storageに送信します。
Correct Answer: C
References:
− Backup daily/weekly/monhtly all your MySQL databases to Google Cloud Storage via SH and gsutil
– Cloud Storage FUSE
QUESTION 12
QAチームは、Google Compute Engine とGoogle Cloud Bigtable を使って主なクラウド サービスのスケーラビリティーをテストするための、新しい負荷テスト ツールをロールアウトしています。
どの要件を含める必要がありますか? (回答は3つ)
- A.負荷テストがGoogle Cloud Bigtable のパフォーマンスを検証されていることを確認します。
- B.負荷テスト環境で使用する別のGoogle Cloud プロジェクトを作成します。
- C. 本番環境に対して定期的に負荷テストツールを実行するようにスケジュールします。
- D.サービスで使用するすべてのサードパーティ製システムが高負荷を処理できることを確認します。
- E. 本番サービスを計測して、負荷テスト ツールによる再生のためにすべてのトランザクションを記録します。
- F. 詳細なログとメトリック収集を使用して、負荷テストツールとターゲットサービスを計測します。
Correct Answer: B、E、F
QUESTION 13
顧客は企業アプリケーションをGoogle Cloud Platform に移行しています。
セキュリティチームは、組織内のすべてのプロジェクトのを詳細に表示する必要があります。Google Cloud Resource Manager をプロビジョニングし、組織管理者として自分で設定します。
Google Cloud Identity and Access Management (Cloud IAM) でセキュリティチームに与えるべき役割はどれでしょうか?
- A. 組織管理者、プロジェクト オーナー。
- B. 組織閲覧者、プロジェクト 閲覧者。
- C. 組織管理者、プロジェクト参照者。
- D. プロジェクト オーナー、ネットワーク管理者。
Correct Answer: B
QUESTION 14
顧客は、迅速な対応とお客様のニーズへの迅速な対応を重視しています。主なビジネス目標はリリースのスピードとアジリティです。セキュリティ エラーが偶発的に発生する可能性を減らしたいと考えています。
何をするべきでしょうか?(回答は2つ)
- A.すべてのコード チェックインがセキュリティ SMEによってピアレビューされていることを確認します。
- B. CI / CD パイプラインの一部としてソースコード セキュリティ アナライザーを使用します。
- C.コンポーネント間のすべてのインターフェイスを単体テストするためのスタブがあることを確認します。
- D.コード署名とCI / CD パイプラインと統合された信頼できるバイナリリポジトリを有効にします。
- E.継続的統合/継続的配信(CI / CD)パイプラインの一部として脆弱性 セキュリティ スキャナーを実行します。
Correct Answer: B、E
QUESTION 15
実行中のGoogle Container Engine クラスタを、アプリケーションの変更に応じてスケールできるようにしたいと考えています。
何をするべきでしょうか?
- A. 次のコマンドを使用して、Google Container Engine クラスタにノードを追加します。
gcloud container clusters resize
CLUSTER_Name – -size 10 - B. 次のコマンドを使用して、クラスタ内のインスタンスにタグを追加します。
gcloud compute instances add-tags
INSTANCE – -tags enableautoscaling max-nodes-10 - C. 次のコマンドを使用して、既存のGoogle Container Engine クラスタを更新します。
gcloud alpha container clusters
update mycluster – -enableautoscaling – -min-nodes=1 – -max-nodes=10 - D. 次のコマンドを使用して、新しいGoogle Container Engine クラスタを作成します。
gcloud alpha container clusters
create mycluster – -enableautoscaling – -min-nodes=1 – -max-nodes=10
そして、アプリケーションを再配置します。
Correct Answer: B
クラスタの自動スケール
–enable-autoscaling
ノードプールの自動スケールを有効にします。
–node-pool で指定されたノードプール、または–node-pool が指定されていない場合はデフォルトのノードプールでの自動スケールを有効にします。
Where:
–max-nodes=MAX_NODES
ノードプール内のノードの最大数。
–node-pool で指定されたノードプール(または指定されていない場合はデフォルトのノードプール)がスケーリングできるノードの最大数。
C、D は不正解:実稼働ワークロードにアルファクラスターまたはアルファ機能を使用しないでください。
アルファ クラスタを作成して、Kubernetes アルファ機能を試すことができます。 アルファ クラスタは、すべてのKubernetes API と機能を有効にして安定したKubernetes リリースを実行する短命のクラスタです。 アルファ クラスターは、上級ユーザーや早期導入者が、新機能を運用準備する前に新機能を活用するワークロードを試すように設計されています。通常のKubernetes Engine クラスターと同様に、アルファ クラスタを使用できます。
References:
– gcloud container clusters create
QUESTION 16
マーケティング部門は、プロモーションメール キャンペーンを送信したいと考えています。開発チームは、直接的な運用管理を最小限に抑えたいと考えています。1日あたり100〜500,000のクリック スルーから、幅広い可能な顧客の反応を予測しています。 このリンクをクリックするとプロモーションを説明、ユーザー情報と設定を収集する簡単なWebサイトにつながります。
どのインフラストラクチャを選択するべきでしょうか?(回答は2つ)
- A. Google App Engine を使用してWebサイトを提供し、Google Cloud Datastore を使用してユーザーデータを保存します。
- B. Google Container Engine クラスタを使用して、Webサイトを提供し、永続ディスクにデータを保存します。
- C. マネージド インスタンス グループ(MIG)を使用してWebサイトを提供し、Google Cloud Bigtableを使用してユーザーデータを保存します。
- D. 単一のGoogle Compute Engine 仮想マシン(VM)を使用して、Google Cloud SQL によるバックエンドのWebサーバーをホストします。
Correct Answer: A、C
Explanation:
References:
– クラウド ストレージ プロダクト
QUESTION 17
会社は、コンピューティングのニーズに応えるため、Google Compute Engine への移行を急ピッチで完了しました。よりクラウド ネイティブなソリューションの設計と導入には、さらに9ヶ月かかります。具体的にはNo-Opsで、自動スケーリングが可能なシステムが必要です。
どのGCP プロダクトを使用するべきでしょうか?(回答は2つ)
- A. Google Compute Engine とコンテナ。
- B. Google Cloud Container Engine (Google Kubernetes Engine) とコンテナ。
- C. Google App Engine スタンダード環境t。
- D. Google Compute Engine とカスタム マシンタイプ。
- E. Google Compute Engine とマネージド インスタンス グループ(MIG)。
Correct Answer: B、C
B: Google Cloud Container Engine (Google Kubernetes Engine) を使用すると、Google が自動的にクラスタを展開し、ノードを更新、修正、保護します。Kubernetes Engine のクラスタ オートスケーラーは、実行するワークロードの要求に基づいてクラスタのサイズを自動的に変更します。
C: Google Cloud Datastore、Google BigQuery、Google App Engineなどのソリューションは真のNoOpsです。 Google App Engine はデフォルトで、負荷に合わせて実行するインスタンスの数を増減するため、アイドルインスタンスを最小限に抑えながらコストを削減しながら、常に一定のパフォーマンスをアプリに提供します。
Note: 高レベルでは、NoOpsは、プラットフォームの使用中に構築および管理するインフラストラクチャがないことを意味します。 通常、NoOpsで妥協することは、基盤となるインフラストラクチャの制御を失うことです。
References:
– How well does Google Container Engine support Google Cloud Platform’s NoOps claim?
QUESTION 18
主なビジネス目標の1つは、アプリケーションに保存されているデータを信頼できるようにすることです。アプリケーションデータへのすべての変更を記録する必要があります。
ログの信頼性を検証するために、ログ システムをどのように設計しますか?
- A. クラウドとオンプレミスで同時にログを書き込みます。
- B. SQL データベースを使用し、ログ テーブルを変更できるユーザーを制限します。
- C. 各タイムスタンプとログ エントリにデジタル署名を付け、署名を保存します。
- D. 各ログ エントリのJSON ダンプを作成し、Google Cloud Storage に保存する。
Correct Answer: D
ログエントリを書きます。ログが存在しない場合は作成されます。ログ エントリの重大度を指定できます。また、–payloadtype = json を指定してメッセージをJSON 文字列として書き込むことにより、構造化されたログ エントリを書き込むことができます。
gcloud logging write LOG STRING
gcloud logging write LOG JSON-STRING –payload-type=json
References:
– Command-line interface
QUESTION 19
会社は、開発者により良いエクスペリエンスを提供するために、API を大幅に改訂することを決定しました。新しい顧客やテスターが新しいAPI を試用できるようにしながら、API の古いバージョンを使用可能かつデプロイ可能に保つ必要があります。両方のAPI を提供するために、同じSSL およびDNS レコードを保持したいと考えています。
何をするべきでしょうか?
- A. API の新しいバージョン用に新しいロード バランサを構成します。
- B. 新しいAPI の新しいエンドポイントを使用するように、古いクライアントを再構成します。
- C. パスに基づいて、古いAPI から新しいAPI にトラフィックを転送するようにします。
- D. ロード バランサの背後にあるAPI パスごとに別々のバックエンド プールを使用します。
Correct Answer: D
QUESTION 20
会社は、数ペタバイトのデータセットをクラウドに移行することを計画しています。データセットは24時間利用可能でなければなりません。ビジネスアナリストは、SQL インターフェイスを使用した経験しかありません。
分析を容易にするためにデータを最適化するには、どのようにデータを保存する必要がありますか?
- A. データをGoogle BigQuery に読み込ませます。
- B. Google Cloud SQL にデータを挿入します。
- C. Google Cloud Storage にフラットファイルを配置します。
- D. データをGoogle Cloud Datastore にストリームします。
Correct Answer: A
Google BigQuery は、すべてのデータアナリストの生産性を高めるために設計された、Google のサーバーレスで拡張性の高い低コストのエンタープライズデータウェアハウスです。管理するインフラストラクチャがないため、使い慣れたSQL を使用してデータの分析に集中して有意義な洞察を見つけることができ、データベース管理者は必要ありません。
Google BigQuery を使用すると、オブジェクトストレージやスプレッドシートからのデータだけでなく、管理された円柱状のストレージ上に論理データウェアハウスを作成することにより、すべてのデータを分析できます。
References:
– BigQuery
QUESTION 21
運用マネージャーは、Google のベストプラクティスに従ってJ2EE アプリケーションをクラウドに移行したいと考えています。
どのベスト プラクティスに従うべきですか?(回答は3つ)
- A.アプリケーションコードを移植して、Google App Engine で実行します。
- B. Google Cloud Dataflow をアプリケーションに統合して、リアルタイムのメトリックを捕捉します。
- C. Stackdriver Debugger などの監視ツールを使用してアプリケーションを計測します。
- D. 自動化フレームワークを選択して、クラウド インフラストラクチャを確実にプロビジョニングします。
- E. ステージング環境で自動テストを使用して継続的統合ツールを展開します。
- F. MySQL からGoogle Cloud Datastore やGoogle Cloud Bigtable などの管理されたNoSQL データベースに移行します
Correct Answer: A、D、E
References:
– Java アプリをデプロイする
– 入門: Cloud SQL
QUESTION 22
ニュースフィード Webサービスには、Google App Engine で実行される次のコードがあります。負荷がピークのとき、ユーザーは既に閲覧したニュース記事を見ることができると報告があります。
この問題で最も可能性の高い原因は何でしょうか?
import news
from flask import Flask, redirect request
from flask,ext.api import status
from google appengine.api import users
app = Flask (<em>name</em>)
sessions = {}
@app.royte ("/")
def homepage ():
user = users.get_current_user()
if not user:
return "Invalid login",
status.HTTP_401_UNAUTHORIZED
<code>if user not in sessions:</code>
<code> sessions [user] = {"viewed"; [] }</code>
<code> news_aricles = news.get_new_news (user, sessions [user] ["viewed'])</code>
<code> sessions [user] ["viewed"] +- [n["id"] for n in news_articles]</code>
<code> return news.render(news_articles)</code>
if_name_ ++ "main_":
app.run()- A.セッション変数は、単一のインスタンスに対してのみローカルです。
- B.セッション変数はGoogle Cloud Datastore で上書きされている。
- C.キャッシュを防ぐために、API のURLを変更する必要があります。
- D.HTTP Expires ヘッダーを-1stop caching に設定する必要があります。
Correct Answer: B
Reference:
– Google App Engine Cache List in Session Variable
QUESTION 23
アプリケーション開発チームは、現在のロギング ツールは新しいクラウド ベース プロダクトのニーズを満たしていないと考えています。エラーを捕捉し、履歴ログ データの分析に役立つ、より優れたツールを求めています。顧客のニーズに合ったソリューションを見つけるための支援が必要です。
何をするべきでしょうか?
- A. Google StackDriver ログエージェント をダウンロードしてインストールするように指示します。
- B. ロギングのベストプラクティスに関するオンラインリソースのリストを送信します。
- C. 要件の定義し、実行可能なログ ツールの評価を支援します。
- D. 現在使用しているツールをアップグレードして、新しい機能を利用できるようにします。
Correct Answer: A
Stackdriver Logging エージェントは、VM インスタンスおよび選択したサードパーティ ソフトウェアパッケージからStackdriver Logging にログをストリーミングします。エージェントの使用はオプションですが、推奨します。エージェントは、Linux とMicrosoft Windows の両方で動作します。
Note:Stackdriver Logging を使用すると、Google Cloud Platform およびAmazon Web Services (AWS) からのログデータとイベントを保存、検索、分析、監視、およびアラートが行なえます。
また、API を使用すると、任意のソースからカスタム ログ データを取り込むことができます。 Stackdriver Logging は、規模に応じて実行される完全に管理されたサービスで、数千のVMからアプリケーションおよびシステムのログ データを取り込むことができます。さらに、すべてのログ データをリアルタイムで分析できます。
References:
– Stackdriver Logging エージェントのインストール
QUESTION 24
会社のWebホスティングプラットフォームでの誤った運用環境の予期しないロールバックの回数を減らす必要があります。QA / テスト プロセスの改善により、80%の削減が達成されました。
ロールバックをさらに削減するために、どのアプローチを行うべきでしょうか?(回答は2つ)
- A. green-blue モデルを紹介します。
- B. QA環境をカナリアリリースに置き換えます。
- C. モノリシック プラットフォームをマイクロサービスに断片化します。
- D. プラットフォームのリレーショナル データベースシステムへの依存度を減らします。
- E. プラットフォームのリレーショナル データベースシステムをNoSQL データベースに置き換えます。
Correct Answer: A、C
QUESTION 25
コストを削減するため、エンジニアリング ディレクターは、すべての開発者に開発に対して、インフラ ストラクチャリソースをオンプレミスの仮想マシン(VM)からGoogle Cloud Platform に移動することを求めています。これらのリソースは、日中に複数の開始 / 停止イベントを通過し、状態を維持する必要があります。財務部門にコストの可視性を提供しながら、Google Cloud で開発環境を実行するプロセスを設計するよう求められています。
どの手段を行うべきでしょうか?(回答は2つ)
- A. すべての永続ディスクで–no-auto-delete フラグを使用し、VMを停止します。
- B. すべての永続ディスクで–auto-delete フラグを使用し、VMを終了します。
- C. VM CPU 使用率ラベルを適用し、Google BigQuery 請求エクスポートに含めます。
- D. Google BigQuery 請求エクスポートとラベルを使用して、コストをグループに関連付けます。
- E. すべての状態をローカル SSDに保存し、永続ディスクのスナップショットを作成して、VMを終了します。
- F. すべての状態をGoogle Cloud Storage に保存し、永続ディスクのスナップショットを作成して、VMを終了します。
Correct Answer: C、E
C:Google BigQuery への請求エクスポートにより、1日の使用量とコストの見積もりを1日を通して自動的に指定したGoogle BigQuery データセットにエクスポートできます。
使用状況メトリックを生成するリソースに適用されたラベルは請求システムに転送されるため、ラベル条件に基づいて請求料金を分類できます。 たとえば、Google Compute Engine サービスはVM インスタンスのメトリックをレポートします。 それぞれが明確にラベル付けされた2,000個のVMを含むプロジェクトを展開する場合、1時間以内に表示される最初の1,000個のラベルマップのみが保持されます。
E:ローカル SSDが接続されているインスタンスを停止することはできません。 代わりに、インスタンスを完全に削除する前に、重要なデータをローカル SSDから永続ディスクまたは別のインスタンスに移行する必要があります。
後でインスタンスに戻ることができるように、インスタンスを一時的に停止できます。 停止したインスタンスには課金されませんが、インスタンスに接続されているリソースはすべて課金されます。 または、インスタンスの使用が完了したら、インスタンスとそのリソースを削除して、課金の発生を停止します。
References:
– 課金データの BigQuery へのエクスポート
– インスタンスの停止と起動
QUESTION 26
顧客は、最近更新されたGoogle App Engine アプリケーションが一部のユーザーの読み込みに約30秒かかっているという報告を受けています。この動作は、更新前には報告されていませんでした。
どのような戦略を取るべきですか?
- A. ISPと協力して問題を診断してください。
- B. 問題を診断するためにネットワーク キャプチャとフローデータを要求するサポートチケットを開き、アプリケーションをロールバックします。
- C. 最初に既知の正常なリリースにロールバックし、次にStackdriver Trace とLogging を使用して、開発 / テスト / ステージング環境で問題を診断します。
- D. 以前の既知の正常なリリースにロールバックし、静かな期間に再度リリースをプッシュして調査します。 次に、Stackdriver Trace とLogging を使用して問題を診断します。
Correct Answer: C
Stackdriver Logging を使用すると、Google Cloud Platform およびAmazon Web Services (AWS) からのログデータとイベントを保存、検索、分析、監視、およびアラートできます。
また、API を利用することで、任意のソースからカスタム ログデータを取り込むことができます。 Stackdriver Logging は、大規模に実行され、数千のVMからアプリケーションおよびシステム ログデータを取り込むことができる完全に管理されたサービスです。 さらに良いことに、すべてのログデータをリアルタイムで分析できます。
References:
– Stackdriver Logging
QUESTION 27
Google Compute Engine の本番データベース仮想マシンには、データファイル用のext4 フォーマットの永続ディスクがあります。データベースのストレージ容量が不足しています。
最小のダウンタイムでどのように問題を修正しますか?
- A. Google Cloud Platform Console で、永続ディスクのサイズを増やし、Linux でresize2fs コマンドを使用します。
- B.仮想マシンをシャットダウンし、Google Cloud Platform Console を使用して永続ディスクサイズを増やしてから、仮想マシンを再起動します。
- C. Google Cloud Platform Console で、永続ディスクのサイズを増やし、Linux のfdisk コマンドで新しいスペースが使用できる状態になっていることを確認します。
- D. Google Cloud Platform Console で、仮想マシンに接続された新しい永続ディスクを作成し、フォーマットしてマウントし、データベースサービスを構成して、ファイルを新しいディスクに移動します。
- E. Google Cloud Platform Console で、永続ディスクのスナップショットを作成し、スナップショットを新しい大きなディスクに復元し、古いディスクをアンマウントし、新しいディスクをマウントして、データベースサービスを再起動します。
Correct Answer: A
Linux インスタンスで、インスタンスに接続し、追加した追加のディスク領域を使用するようにパーティションとファイルシステムのサイズを手動で変更します。
追加したスペースを使用するには、ディスクまたはパーティション上のファイルシステムを拡張します。 ディスクのパーティションを拡大した場合、パーティションを指定します。 ディスクにパーティションテーブルがない場合は、ディスクIDのみを指定します。
sudo resize2fs /dev/[DISK_ID][PARTITION_NUMBER]
ここでの、[DISK_ID] はデバイス名、[PARTITION_NUMBER] はファイルシステムのサイズを変更するデバイスのパーティション番号です。
References:
– ゾーン永続ディスクの追加またはサイズ変更
QUESTION 28
アプリケーションはクレジットカード 取引を処理する必要があります。取引データおよび使用される支払い方法に関連する傾向を分析する機能を損なうことなく、Payment Card Industry (PCI) コンプライアンスの最小スコープが必要です。
アーキテクチャをどのように設計する必要がありますか?
- A. トークン化サービスを作成し、トークン化されたデータのみを保存します。
- B. クレジットカード データのみを処理する個別のプロジェクトを作成します。
- C. 個別のサブネットワークを作成し、クレジットカード データを処理するコンポーネントを分離します。
- D. PCI データを処理するすべての仮想マシン(VM)にラベルを付けることにより、監査発見フェーズを合理化します。
- E. Google BigQuery へのログのエクスポートを有効にし、ACLとビューを使用して、監査者と共有するデータの範囲を絞り込みます。
Correct Answer: A
Reference:
– Six Ways to Reduce PCI DSS Audit Scope by Tokenizing Cardholder data (PDF)
QUESTION 29
会社のWebサイトの大規模なポートフォリオのクリックデータ用のストレージシステムを選択するように求められました。このデータはカスタムWebサイト分析パッケージから毎分 6,000 クリックの割合で送られてきます。最大 毎秒 8,500 クリックのバースト速度をが起きています。データ サイエンスチームとユーザー エクスペリエンスチームが将来分析するために保管しておく必要があります。
どのストレージ インフラストラクチャを選択するべきでしょうか?
- A. Google Cloud SQL
- B. Google Cloud Bigtable
- C. Google Cloud Storage
- D. Google Cloud Datastore
Correct Answer: B
Google Cloud Bigtable は、リアルタイムアクセスと分析ワークロードの両方に適した、スケーラブルで完全に管理されたNoSQL ワイドカラムデータベースです。
Good for:
・低遅延の読み取り/書き込みアクセス。
・ハイスループット分析。
・ネイティブ時系列サポート。
Common workloads:
・IoT、金融、アドテック
・カスタマイズ、推奨事項
・モニタリング
・地理空間データセット
・グラフ
C:Google Cloud Storage は、スケーラブルで、完全に管理され、信頼性が高く、費用効率の高いオブジェクト/ブロブ ストアです。
Is good for:
・画像、写真、ビデオ
・オブジェクトとブロブ
・非構造化データ
D: Google Cloud Datastore は、Webおよびモバイルアプリケーション向けの、スケーラブルで完全に管理されたNoSQLドキュメントデータベースです。
Is good for:
・半構造化アプリケーションデータ
・階層データ
・耐久性のあるキーバリューデータ
・一般的なワークロード:
・ユーザープロファイル
・製品カタログ
・ゲームの状態
References:
– https://cloud.google.com/storage-options/
QUESTION 30
バックアップのGoogle Cloud Storage バケットから90日を経過したバックアップファイルを削除するソリューションを作成しています。継続的なクラウドストレージの費用を最適化したいと考えています。
どうするべきでしょうか?
- A. ラライフサイクル管理の構成をXML で記述し、gsutil を使用してバケットにプッシュします。
- B. ライフサイクル管理の構成をJSON で記述し、gsutil を使用してバケットにプッシュします。
- C. –lr gs://backups/** を使用してcron スクリプトをスケジュールし、90日以上経過したアイテムを見つけて削除します。
- D. –l gs://backups/** を使用してcron スクリプトをスケジュールし、90日より古いアイテムを見つけて削除し、cron でスケジュールします。
Correct Answer: B
QUESTION 31
会社では、ローカル データセンターで実行されるApache Spark およびHadoop ジョブの数とサイズが急激に増加すると予測しています。クラウドを利用して、今後の需要を最小限の運用作業とコード変更でスケーリングできるようにします。
どのGCP プロダクトを使用するべきでしょうか?
- A. Google Cloud Dataflow
- B. Google Cloud Dataproc
- C. Google Compute Engine
- D. Google Container Engine
Correct Answer: B
Google Cloud Dataproc は、Google Cloud Platform 上でApache Spark およびApache Hadoop エコシステムを実行できる、高速で使いやすく、低コストで完全に管理されたサービスです。Google Cloud Dataproc は大規模または小規模のクラスターを迅速にプロビジョニングし、多くの一般的なジョブタイプをサポートし、Google Cloud Storage やStackdriver Logging などの他のGoogle Cloud Platform サービスと統合されているため、TCOの削減に役立ちます。
References:
– Dataproc FAQ
QUESTION 32
データベース管理チームから、Google Compute Engine で実行されている新しいデータベースサーバーのパフォーマンスを改善するための支援を依頼されました。データベースは、パフォーマンス統計をインポートおよび正規化するためのもので、Debian Linux 上で動作するMySQL で構築されています。n1-standard-8 仮想マシンと80 GBのSSD 永続ディスクを搭載しています。
このシステムのパフォーマンスを向上させるには、何を行うべきでしょうか?
- A. 仮想マシンのメモリを64 GBに増やします。
- B. PostgreSQL を実行する新しい仮想マシンを作成します。
- C. SSD 永続ディスクを動的に500 GBにサイズ変更します。
- D. パフォーマンス メトリック ウェアハウスをGoogle BigQuery に移行します。
- E. すべてのバッチジョブを変更して、データベースへの一括挿入を使用します。
Correct Answer: C
QUESTION 33
正確なリアルタイムの天気図作成 アプリケーションのパフォーマンスを最適化する必要があります。データは、タイムスタンプとセンサー読み取り値の形式で、毎秒 10 回の読み取り値を送信する50,000 個のセンサーから取得されます。
データをどのGCP プロダクトに保存するべきでしょうか?
- A. Google BigQuery
- B. Google Cloud SQL
- C. Google Cloud Bigtable
- D. Google Cloud Storage
Correct Answer: C
Google Cloud Bigtable は、リアルタイムアクセスと分析ワークロードの両方に適した、スケーラブルで完全に管理されたNoSQLワイドカラムデータベースです。
Good for:
・低遅延の読み取り/書き込みアクセス
・ハイスループット分析
・ネイティブ時系列サポート
Common workloads:
・IoT、金融、アドテック
・カスタマイズ、推奨事項
・モニタリング
・地理空間データセット
・グラフ
References:
− クラウド ストレージ プロダクト
QUESTION 34
会社のユーザーフィード バックポータルは、2つのゾーンに複製された標準LAMP スタックで構成されています。us-central1 リージョンにデプロイされ、データベースを除くすべてのレイヤーで自動スケーリングされたマネージド インスタンス グループ(MIG)を使用します。 現在、ポータルにアクセスできるのは一部の選ばれた顧客のみです。ポータルはこれらの条件下で99.99 %の可用性SLAを満たしています。ただし、次の四半期には、認証されていないユーザーを含むすべてのユーザーがポータルを利用できるようになります。耐障害性テスト戦略を開発して、追加のユーザー負荷が発生したときにシステムがSLAを維持するようにする必要があります。
何をするべきでしょうか?
- A. 既存のユーザ入力を捕捉し、すべてのレイヤで自動スケールがトリガされるまで捕捉ししたユーザー負荷を再生します。同時に、いずれかのゾーン内のすべてのリソースを終了します。
- B. 合成ランダム ユーザー入力を作成し、自動スケール ロジックが少なくとも1つのレイヤーでトリガーされるまで合成負荷を再生し、両方のゾーンのランダム リソースを終了することによってシステムに「chaos」を導入します。
- C. 新しいシステムをより多くのユーザグループに公開し、すべてのレイヤで自動スケール ロジックがトリガされるまで毎日グループサイズを増やします。同時に、両方のゾーンでランダム リソースを終了します。
- D. 既存のユーザー入力を捕捉し、捕捉されたユーザー負荷をリソース使用率が80 %を超えるまで再生します。 また、既存のユーザーのアプリの使用に基づいて推定ユーザー数を導き出し、予想される負荷の200 %を処理するのに十分なリソースを展開します。
Correct Answer: D
QUESTION 35
チームの開発者の1人が、以下のDockerfile を使用してGoogle Container Engine にアプリケーションをデプロイしました。アプリケーションの展開に時間がかかりすぎると報告しています。
FROM ubuntu;16.04
COPY . /src
RUN apt-get update && apt-get install - y python python-pip
RUN pip install -r requirements.txtこのDockerfile を最適化して、アプリの機能に悪影響を与えずに展開時間を短縮します。
何をすべきでしょうか?(回答は2つ)
- A. pip の実行後にPython を削除します。
- B. requirements.txt から依存関係を削除します。
- C. Alpine Linux のようなスリム化されたベースイメージを使用します。
- D. Google Container Engine ノードプールには、より大きなマシンタイプを使用します。
- E. パッケージの依存関係(Python およびpip)をインストールした後、ソースをコピーします。
Correct Answer: C、E
アップロード速度を変更するには、アップロードされたアプリのサイズを制限し、Dockerfileに必要なビルドの複雑さ(存在する場合)を制限し、高速で信頼性の高いインターネット接続を確保します。
Note: Alpine Linux は、musl libc とbusybox を中心に構築されています。これにより、従来のGNU / Linux ディストリビューションよりも小さくなり、リソース効率が向上します。 コンテナには8 MB以下しか必要なく、ディスクへの最小インストールには約 130 MBのストレージが必要です。本格的なLinux 環境だけでなく、リポジトリから多数のパッケージを入手できます。
References:
– Google group: Google App Engine is slow to deploy, hangs on “Updating service [someproject]…”
– Alpine Linux is a security-oriented, lightweight Linux distribution based on musl libc and busybox.
QUESTION 35
このソリューションでは、本番環境ではステージング環境やテスト環境では見られなかったパフォーマンスのバグが発生しています。今後、この問題を回避するために、テスト手順と展開手順を調整する必要があります。
何をすすべきでしょうか?
- A. 本番環境への変更を少なくします。
- B. 小規模な変更を本番環境に展開します。
- C. テストおよびステージング環境の負荷を増やします。
- D. 本番環境にロールアウトする前に、一部のユーザーに変更を展開します。
Correct Answer: D
QUESTION 36
マイクロサービスベースのアプリケーションに対する少数のAPI リクエストには、非常に長い時間がかかります。API への各リクエストは多くのサービスを通過できることがわかっています。その場合、どのサービスが最も時間がかかるかを知りたいです。
何をするべきでしょうか?
- A. アプリケーションにタイムアウトを設定して、要求をより速く失敗できるようにします。
- B. 各リクエストのカスタム メトリックをStackdriver Monitoring に送信します。
- C. Stackdriver Monitoring を使用して、API のレイテンシが高い時を示す洞察を探します。
- D. Stackdriver Trace を使ってアプリケーションを計測し、マイクロサービスごとにリクエストの遅延を分析します。
Correct Answer: D
References:
– クイックスタート:トレースの検索
QUESTION 37
日によってトラフィックの多い部分で、リレーショナル データベースの1つがクラッシュしますが、レプリカがマスターに昇格することはありません。今後これを避けたいと考えています。
何をするべきでしょうか?
- A.別のデータベースを使用してください。
- B.データベースのより大きなインスタンスを選択します。
- C.データベースのスナップショットをより定期的に作成します。
- D.データベースの定期的にスケジュールされたフェイルオーバーを実装します。
Correct Answer: C
データベースシステムの定期的なスナップショットを作成します。
データベースシステムがGoogle Compute Engine 永続ディスク上にある場合、アップグレードするたびにシステムのスナップショットを作成できます。 データベースシステムがダウンした場合、または以前のバージョンにロールバックする必要がある場合、目的のスナップショットから新しい永続ディスクを作成し、そのディスクを新しいGoogle Compute Engine インスタンスのブートディスクにすることができます。 このアプローチでは、データの破損を防ぐために、スナップショットの作成中にデータベースシステムのディスクをフリーズする必要があることに注意してください。
Reference:
– 障害復旧計画ガイド
QUESTION 38
組織では今後の法的手続きでの分析のために、すべてのアプリケーションのメトリックを5年間 保持する必要があります。
どのアプローチを使用する必要がありますか?
- A. セキュリティチームに各プロジェクトのログへのアクセスを許可します。
- B. すべてのプロジェクトのStackdriver Monitoring を設定し、Google BigQueryにエクスポートします。
- C. デフォルトの保持ポリシーを使用して、すべてのプロジェクトのStackdriver Monitoring を設定します。
- D. すべてのプロジェクトのStackdriver Monitoring を設定し、Google Cloud Storage にエクスポートします。
Correct Answer: B
Stackdriver Logging を使用すると、クラウドおよびオープンソースアプリケーションサービスからログをフィルタリング、検索、表示できます。 ダッシュボードとアラートに組み込まれているログの内容に基づいてメトリックを定義できます。 ログをGoogle BigQuery、Google Cloud Storage、および Google Cloud Pub / Sub にエクスポートできます。
References:
– Stackdriver
QUESTION 39
会社は、オンプレミスのユーザ認証データベース PostgreSQL のバックアップレプリカをGoogle Cloud Platform 上に構築することにしました。データベースは4 TBであり、大規模な更新が頻繁に行われます。レプリケーションにはプライベートアドレス空間通信が必要です。
どのネットワークア プローチを使用する必要がありますか?
- A. Google Cloud Dedicated Interconnect。
- B. データセンターネットワークに接続されたGoogle Cloud VPN。
- C. オンプレミスにインストールされたNATおよびTLS変換ゲートウェイ。
- D. データセンター ネットワークに接続されたVPNサーバーがインストールされたGoogle Compute Engine インスタンス。
Correct Answer: A
Google Cloud Dedicated Interconnect は、ユーザのオンプレミスネットワークとGoogle のネットワーク間に直接的な物理的接続とRFC 1918 通信を提供する。Google Cloud Dedicated Interconnect を使用すると、ネットワーク間で大量のデータを転送できるため、パブリックインターネット経由で帯域幅を追加購入したり、VPN トンネルを使用したりするよりもコスト効率が高くなります。
Benefits:
オンプレミスネットワークとVPC ネットワーク間のトラフィックは、パブリックインターネットを通過しません。トラフィックは、より少ないホップで専用接続を通過します。つまり、トラフィックがドロップまたは中断される可能性のある障害ポイントが少なくなります。
VPCネットワークの内部(RFC 1918)IP アドレスは、オンプレミス ネットワークから直接アクセスできます。内部 IPアドレスに到達するためにNAT デバイスまたはVPNトンネルを使用する必要はありません。現在、専用 IP アドレスを介してのみ内部IPアドレスにアクセスできます。Google の外部 IP アドレスにアクセスするには、別の接続を使用する必要があります。
ニーズに基づいて、Google への接続を拡大できます。接続容量は、1つまたは複数の10 Gbpsイーサネット接続で提供され、最大 8つの接続(相互接続ごとに合計80 Gbps)が提供されます。
VPC ネットワークからオンプレミスネットワークへの出力トラフィックのコストが削減されます。Google のネットワークとの間で大量のトラフィックがある場合、通常、専用接続は最も安価な方法です。
References:
– Dedicated Interconnect の概要
QUESTION 40
監査人は12か月ごとにチームを訪問し、過去 12か月のすべてのGoogle Cloud Identity and Access Management (Cloud IAM) ポリシーの変更を確認するよう依頼します。分析および監査プロセスを合理化および迅速化する必要があります。
何をするべきでしょうか?
- A. カスタム Google Stackdriver アラートを作成し、監査人に送信します。
- B. Google BigQuery へのログ エクスポートを有効にし、ACL とビューを使用して監査人と共有するデータのスコープを設定します。
- C. Google Cloud Functions を使ってログ エントリをGoogle Cloud SQL に転送し、ACL とビューを使って監査人のビューを制限します。
- D.Google Cloud Storage(GCS)ログのエクスポートを有効にして、ログをGCSバケットに監査し、バケットへのアクセスを委任します。
Correct Answer: D
QUESTION 41
30 個のマイクロサービスを持つ大規模な分散アプリケーションを設計しています。分散マイクロサービスのそれぞれは、データベース バックエンドに接続する必要があります。資格情報を安全に保存したいと考えています。
資格情報はどこに保存するべきでしょうか?
- A. ソースコード内。
- B. 環境変数内。
- C. シークレット管理。
- D. ACLを介したアクセスが制限されている設定ファイル。
Correct Answer: C
References:
– Cloud KMS によるシークレット管理
QUESTION 42
リードエンジニアが、レガシー データセンターに仮想マシンを展開するカスタムツールを作成しました。カスタムツールを新しいクラウド環境に移行したいと考えています。Google Cloud Deployment Manager の採用を推奨します。
Google Cloud Deployment Manager に移行する際のビジネスリスクは何でしょうか?(回答は2つ)
- A. Google Cloud Deployment Manager はPython を使用しています。
- B. Google Cloud Deployment Manager API は将来廃止される可能性があります。
- C. Google Cloud Deployment Manager は、会社のエンジニアには馴染みがありません。
- D. Google Cloud Deployment Manager を実行するには、Google APIサービス アカウントが必要です。
- E. Google Cloud Deployment Manager を使用して、クラウドリソースを完全に削除できます。
- F. Google Cloud Deployment Manager は、Google Cloud リソースの自動化のみをサポートしています。
Correct Answer: B、F
Google Cloud Deployment Manager に移行する2つのビジネスリスクは何ですか?
・リスク1:Google Cloud Deployment Manager API は、将来廃止される可能性があります。
・リスク2:Google Cloud Deployment Manager は、Google Cloudリソースの自動化のみをサポートしています。
Comments are closed