
Google Cloud 認定資格 – Professional Data Engineer – 模擬問題集(全 205問)
Question 01
会社は多数のニューロンと層を持つ TensorFlow ニューラル ネットワーク モデルを構築しました。
モデルはトレーニング データによく適合しますが、新しいデータに対してテストするとパフォーマンスが低下します。
これに対処するにはどのような方法を採用できますか?
- A. スレッディング (Threading)
- B. シリアル化 (Serialization)
- C.ドロップアウト方法 (Dropout Methods)
- D. 次元削減 (Dimensionality Reduction)
Answer: C
Question 02
衣類のレコメンデーションを行うためのモデルを構築しています。
ユーザーのファッションの好みは時間の経過とともに変化する可能性が高いことがわかっているため、データ パイプラインを構築して新しいデータが利用可能になったときにモデルにストリーミングします。
このデータをどのように使用してモデルをトレーニングするべきでしょうか?
- A. 新しいデータだけでモデルを継続的に再トレーニングします。
- B. 既存のデータと新しいデータの組み合わせでモデルを継続的に再トレーニングします。
- C. 新しいデータをテスト セットとして使用しながら、既存のデータでトレーニングします。
- D. 既存のデータをテスト セットとして使用しながら、新しいデータでトレーニングします。
Answer: B
Question 03
3つのクリニックの数百人の患者をカバーするパイロット プロジェクトとして患者記録のデータベースを設計しました。
設計では、すべての患者とその訪問を表すために単一のデータベーステーブルを使用し、レポートを作成するために自己結合を使用しました。サーバーリソースの使用率は 50 %でした。その後、このプロジェクトの範囲は拡大しました。データベースには、100 倍の患者記録を保存する必要があります。レポートは、時間がかかりすぎるか、計算資源が不足してエラーが発生するため、実行できません。
データベースの設計をどのように調整すべきでしょうか?
- A. 容量 (メモリとディスク容量) をデータベース サーバーに 200 のオーダーで追加します。
- B. 日付範囲に基づいてテーブルを小さなテーブルに分割し、事前に指定された日付範囲のレポートのみを生成します。
- C. マスター患者記録テーブルを患者テーブルと来院テーブルに正規化し、自己結合を避けるために他の必要なテーブルを作成します。
- D. テーブルをクリニックごとに 1 つずつ小さなテーブルに分割します。小さいテーブル ペアに対してクエリを実行し、統合レポートにユニオンを使用します。
Answer: C
Question 04
Google データスタジオ 360 で大規模なチームの重要なレポートを作成します。
このレポートでは BigQuery をデータ ソースとして使用しています。ビジュアライゼーションに 1 時間未満のデータが表示されていないことに気付きました。
何をするべきでしょうか?
- A. レポート設定を編集してキャッシュを無効にします。
- B. テーブルの詳細を編集して BigQuery でのキャッシュを無効にします。
- C. ビジュアライゼーションを表示するブラウザ タブを更新します。
- D. 過去 1 時間のブラウザ履歴をクリアしてから、仮想化を表示するタブをリロードします。
Answer: A
Reference:
データの更新頻度を管理する – Looker Studio Help
Question 05
外部の顧客は、データベースからのデータの毎日のダンプを提供します。
データは、カンマ区切り値 (CSV) ファイルとして Cloud Storage に流れます。このデータを BigQuery で分析したいのですが、データの行が正しくフォーマットされていないか破損している可能性があります。
このパイプラインをどのように構築するべきでしょうか?
- A. 連携データ ソースを使用し、SQL クエリでデータを確認します。
- B. Google Stackdriver で BigQuery モニタリングを有効にし、アラートを作成します。
- C. gcloud CLI を使用してデータを BigQuery にインポートし、max_bad_records を 0 に設定します。
- D. Dataflow バッチ パイプラインを実行してデータを BigQuery にインポートし、エラーを別のデッドレター テーブルに push して分析します。
Answer: D
Question 06
天気アプリは 15 分ごとにデータベースにクエリを実行して、現在の気温を取得します。
フロントエンドは Google App Engine を利用しており、何百万ものユーザーにサービスを提供しています。
データベースの障害に対応するには、フロントエンドをどのように設計するべきでしょうか?
- A. データベース サーバーを再起動するコマンドを発行します。
- B. 最大 15 分の指数バックオフでクエリを再試行します。
- C. データの古さを最小限に抑えるために、オンラインに戻るまで毎秒クエリを再試行します。
- D. データベースがオンラインに戻るまで、クエリの頻度を 1 時間に 1 回に減らします。
Answer: B
Question 07
住宅価格を予測するモデルを作成しています。
予算の制約により、リソースに制約のある単一の仮想マシンで実行する必要があります。
どの学習アルゴリズムを使用するべきでしょうか?
- A. 線形回帰
- B. 物流分類
- C. 再帰型ニューラル ネットワーク (RNN)
- D. フィードフォワード ニューラル ネットワーク (FF)
Answer: A
Question 08
会社のために新しいリアルタイム データ ウェアハウスを構築しており、BigQuery ストリーミング挿入を使用します。
データが 1 回だけ送信されるという保証はありませんが、データの各行に一意の ID とイベントのタイムスタンプがあります。データを対話的にクエリする際に、重複が含まれないようにする必要があります。
どのクエリ タイプを使用するべきでしょうか?
- A. タイムスタンプ列に ORDER BY DESK を含め、LIMIT を 1 にします。
- B. 一意の ID 列とタイムスタンプ列で GROUP BY を使用し、値で SUM を使用します。
- C. WHERE LAG IS NOT NULL とともに一意の ID による PARTITION で LAG ウィンドウ関数を使用します。
- D. ROW_NUMBER ウィンドウ関数を、一意の ID による PARTITION とともに、WHERE 行が 1 に等しい場合に使用します。
Answer: D
Question 09
会社では WILDCARD テーブルを使用して、類似した名前を持つ複数のテーブルのデータをクエリしています。
SQL ステートメントは現在、次のエラーで失敗しています。
# Syntax error : Expected end of statement but got "-" at [4:11]
SELECT age -
FROM -
bigquery-public-data.noaa_gsod.gsod
WHERE -
age != 99
AND_TABLE_SUFFIX = "˜1929'
ORDER BY -
age DESCSQL ステートメントを正しく機能させるテーブル名はどれですか?
- A. ‘bigquery-public-data.noaa_gsod.gsod’
- B. bigquery-public-data.noaa_gsod.gsod*
- C. ‘bigquery-public-data.noaa_gsod.gsod’*
- D. ‘bigquery-public-data.noaa_gsod.gsod*`
Answer: D
Reference:
ワイルドカード テーブルを使用した複数テーブルに対するクエリ | BigQuery | Google Cloud
Question 10
会社は、規制の厳しい業界にあります。
要件の 1 つは、個々のユーザーが業務を遂行するために必要な最小限の情報にのみアクセスできるようにすることです。この要件を BigQuery で適用したいと考えています。
どのアプローチを取ることができますか? (回答を 3つ選択してください)
- A. 特定のテーブルへの書き込みを無効にします。
- B. ロールごとにテーブルへのアクセスを制限します。
- C. データが常に暗号化されていることを確認します。
- D. BigQuery API アクセスを承認済みユーザーに制限します。
- E. 複数のテーブルまたはデータベース間でデータを分離します。
- F. Google Stackdriver Audit Logging を使用してポリシー違反を特定します。
Answer: B、D F
Question 11
会社は e コマース会社のバスケット放棄システムを設計しています。
システムは、次のルールに基づいてユーザーにメッセージを送信します。
・サイト上でのユーザーの操作が 1 時間ない
・$ 30 以上の商品をカートに追加した
・取引を完了していない
Dataflow を使用してデータを処理し、メッセージを送信するかどうかを決定します。
パイプラインをどのように設計するべきでしょうか?
- A. 60 分間の固定時間ウィンドウを使用します。
- B. 60 分間のスライディング タイム ウィンドウを使用します。
- C. ギャップ タイムが 60 分のセッション ウィンドウを使用します。
- D. 60 分の遅延がある時間ベースのトリガーでグローバル ウィンドウを使用します。
Answer: C
Question 12
会社は、さまざまなクライアントのデータ処理を処理しています。
各クライアントは独自の分析ツール スイートを使用することを好み、BigQuery を介して直接クエリ アクセスできるものもあります。クライアントが互いのデータを見ることができないように、データを保護する必要があります。データへの適切なアクセスを確保します。
どの手順を実行するべきでしょうか? (回答を 3つ選択してください)
- A. データを異なるパーティションに読み込みます。
- B. クライアントごとに異なるデータセットにデータを読み込みます。
- C. 各クライアントの BigQuery データセットを別のテーブルに挿入します。
- D. クライアントのデータセットを承認されたユーザーに制限します。
- E. サービス アカウントにのみデータセットへのアクセスを許可します。
- F. 各クライアントのユーザーに適切な ID およびアクセス管理 (IAM) ロールを使用します。
Answer: B、D、F
Question 13
Google Cloud Platform で実行される POS アプリケーションで支払いトランザクションを処理したいと考えています。
ユーザーベースは指数関数的に増加する可能性がありますが、インフラストラクチャのスケーリングを管理したくありません。
どの Google データベース サービスを使用するべきでしょうか?
- A. Cloud SQL
- B. BigQuery
- C. Cloud Bigtable
- D. Datastore
Answer: D
Reference:
トランザクション | Datastore Documentation
Question 14
組織サンプルに関する情報のデータベースを使用して、将来の組織サンプルを正常または変異のいずれかに分類したいと考えています。
組織サンプルを分類するための教師なし異常検出方法を評価しています。
この方法をサポートする特徴はどれでしょうか? (回答は 2つ選択してください)
- A. 通常のサンプルと比較して、変異の発生は非常に少ないです。
- B. データベースには、正常なサンプルと変異したサンプルの両方がほぼ同数存在します。
- C. 将来の変異には、データベース内の変異サンプルとは異なる特徴があると予想されます。
- D. 将来の変異には、データベース内の変異サンプルと同様の特徴があると予想されます。
- E. 変異したサンプルとデータベース内の正常なサンプルのラベルが既にあります。
Answer: A、D
Question 15
ほぼリアルタイムで毎分 10,000 メッセージの速度で、ソーシャル メディアの投稿を BigQuery に保存して分析する必要があります。
最初に、個々の投稿にストリーミング挿入を使用するようにアプリケーションを設計します。アプリケーションは、ストリーミング挿入の直後にデータ集計も実行します。挿入をストリーミングした後のクエリが強い一貫性を示さず、クエリからのレポートで実行中のデータが欠落している可能性があることがわかりました。
アプリケーションの設計をどのように調整できるでしょうか?
- A. 蓄積されたデータを 2 分ごとにロードするようにアプリケーションを書き直します。
- B. 個々のメッセージのストリーミング挿入コードをバッチ ロードに変換します。
- C. 元のメッセージを Google Cloud SQL に読み込み、ストリーミング挿入を介して 1 時間ごとにテーブルを BigQuery にエクスポートします。
- D. ストリーミング挿入後のデータ可用性の平均レイテンシーを見積もり、常に 2 倍の待機時間後にクエリを実行します。
Answer: D
Question 16
スタートアップ企業は、正式なセキュリティ ポリシーを実装したことがありません。
現在、社内の全員が BigQuery に保存されているデータセットにアクセスできます。チームは、適切と思われるサービスを自由に使用できますが、ユース ケースは文書化されていません。データ ウェアハウスの保護を依頼され、誰が何をしているのかを発見する必要があります。
最初に何をすべきですか?
- A. Google Stackdriver 監査ログを使用してデータ アクセスを確認します。
- B. 各テーブルの ID およびアクセス管理 (IAM) ポリシーを取得します。
- C. Stackdriver Monitoring を使用して BigQuery クエリ スロットの使用状況を確認します。
- D. Google Cloud Billing API を使用して倉庫がどのアカウントに請求されているかを確認します。
Answer: A
Question 17
会社は 30 ノードの Apache Hadoop クラスタをクラウドに移行しています。
すでに作成した Hadoop ジョブを再利用し、クラスタの管理を可能な限り最小限に抑え、クラスタの存続期間を超えてデータを永続化できるようにしたいと考えています。
何をするべきでしょうか?
- A. データを処理する Dataflow ジョブを作成します。
- B. HDFS 用の永続ディスクを使用する Dataproc クラスタを作成します。
- C. 永続ディスクを使用する Compute Engine 上に Hadoop クラスタを作成します。
- D. Cloud Storage コネクタを使用する Dataproc クラスタを作成します。
- E. ローカル SSD ディスクを使用する Compute Engine 上に Hadoop クラスタを作成します。
Answer: D
Question 18
会社の事業主は、銀行取引のデータベースを会社に渡しました。
各行には、ユーザー ID、トランザクションの種類、トランザクションの場所、およびトランザクションの金額が含まれています。会社はデータに適用できる機械学習の種類を調査するように求めています。
どの機械学習アプリケーションを使用できますか? (回答を 3つ選択してください)
- A. どのトランザクションが不正である可能性が最も高いかを判断するための教師あり学習。
- B. どのトランザクションが不正である可能性が最も高いかを判断するための教師なし学習。
- C. 特徴の類似性に基づいてトランザクションを N 個のカテゴリに分割するためのクラスタリング。
- D. トランザクションの場所を予測する教師あり学習。
- E. トランザクションの場所を予測するための強化学習。
- F. トランザクションの場所を予測するための教師なし学習。
Answer: B、C、E
Question 19
会社のオンプレミス Apache Hadoop サーバーは寿命が近づいており、IT 部門はクラスタを Dataproc に移行することを決定しました。
クラスタを同様に移行するには、ノードごとに 50 TB の Google Persistent Disk が必要です。CIO は、それだけ多くのブロック ストレージを使用するコストを懸念しており、移行のストレージ コストを最小限に抑えたいと考えています。
何をするべきでしょうか?
- A. データを Cloud Storage にインポートします。
- B. Dataproc クラスタにプリエンプティブル仮想マシン (VM) を使用します。
- C. Dataproc クラスタを調整してすべてのデータに十分なディスクが確保されるようにします。
- D. コールド データの一部を Cloud Storage に移行し、ホット データのみを永続ディスクに保持します。
Answer: A
Question 20
自動車メーカーで働いており、異常なセンサー イベントをキャプチャするために Pub/Sub を使用してデータ パイプラインを設定しました。
Pub/Sub で push サブスクリプションを使用しています。このサブスクリプションは、これらの異常なイベントが発生したときにアクションを実行するために作成したカスタム HTTPS エンドポイントを呼び出します。カスタム HTTPS エンドポイントが、膨大な量の重複メッセージを取得し続けています。
これらの重複したメッセージの最も可能性の高い原因は何でしょうか?
- A. センサー イベントのメッセージ本文が大きすぎます。
- B. カスタム エンドポイントの SSL 証明書が古い。
- C. Pub/Sub トピックに発行されたメッセージが多すぎる。
- D. カスタム エンドポイントが確認期限内にメッセージを確認していません。
Answer: D
Reference:
トラブルシューティング | Pub/Sub ドキュメント
Question 21
会社では、独自のシステムを使用して、在庫データを 6 時間ごとにクラウドのデータ取り込みサービスに送信しています。
送信されるデータには、いくつかのフィールドのペイロードと送信のタイムスタンプが含まれます。送信に問題がある場合、システムはデータを再送信します。
データを最も効率的に重複排除するにはどうすればいいでしょうか?
- A. 各データ エントリにグローバル一意識別子 (GUID) を割り当てます。
- B. 各データ エントリのハッシュ値を計算し、それをすべての履歴データと比較します。
- C. 各データ エントリを主キーとして別のデータベースに保存し、インデックスを適用します。
- D. 各データ エントリのハッシュ値とその他のメタデータを格納するデータベース テーブルを維持します。
Answer: A
Question 22
会社は Cloud Storage と Compute Engine の Cassandra クラスタに格納された非常に大規模なデータセット全体で複雑な分析を実行したいと考えている新しいデータ サイエンティストを雇いました。
データ サイエンティストは主に、いくつかの視覚化タスクと共に、機械学習プロジェクト用のラベル付きデータセットを作成したいと考えています。データ サイエンティストはラップトップが自分のタスクを実行するのに十分なほど強力ではなく、速度が低下していると報告しています。あなたはデータ サイエンティストが仕事をするのを手伝いたいと思っています。
何をするべきでしょうか?
- A. ラップトップで Jupiter のローカル バージョンを実行します。
- B. ユーザーに Cloud Shell へのアクセスを許可します。
- C. Compute Engine の VM で可視化ツールをホストします。
- D. Cloud Datalab を Compute Engine 上の仮想マシン (VM) にデプロイします。
Answer: D
Reference:
Cloud Datalab インスタンスのライフサイクルの管理
Cloud Datalab ドキュメント
Question 23
世界中の倉庫の温度データを収集するために 10,000 台の新しいモノのインターネット デバイスを展開しています。
これらの非常に大きなデータセットをリアルタイムで処理、保存、分析する必要があります。
何をするべきでしょうか?
- A. データを Datastore に送信し、BigQuery にエクスポートします。
- B. データを Pub/Sub に送信し、Pub/Sub を Dataflow にストリーミングしてデータを BigQuery に保存します。
- C. データを Cloud Storage に送信し、分析が必要なときに Dataproc で必要に応じて Apache Hadoop クラスタを起動します。
- D. ログをバッチで Cloud Storage にエクスポートしてから Google Cloud SQL インスタンスを起動し、Cloud Storage からデータをインポートして必要に応じて分析を実行します。
Answer: B
Question 24
カンマ区切り値 (CSV) ファイルから BigQuery テーブル CLICK_STREAM にデータを読み込むのに数日かかりました。
列 DT には、クリック イベントのエポック タイムが格納されます。便宜上、すべてのフィールドが STRING 型として扱われる単純なスキーマを選択しました。サイトにアクセスしたユーザーの Web セッション期間を計算し、そのデータ型を TIMESTAMP に変更したいと考えています。また、将来のクエリの計算コストを高くすることなく、移行作業を最小限に抑えたいと考えています。
何をするべきでしょうか?
- A. テーブル CLICK_STREAM を削除し、列 DT が TIMESTAMP タイプになるように再作成します。データをリロードします。
- B. TIMESTAMP タイプの列 TS をテーブル CLICK_STREAM に追加し、各行の列 TS から数値を入力します。今後は DT 列ではなく TS 列を参照します。
- C. ビュー CLICK_STREAM_V を作成します。このビューでは、列 DT の文字列が TIMESTAMP 値にキャストされます。今後は、テーブル CLICK_STREAM の代わりにビュー CLICK_STREAM_V を参照します。
- D. テーブル CLICK STREAM に 2 つの列を追加します。TIMESTAMP タイプの TS と BOOLEAN タイプの IS_NEW。すべてのデータを追加モードで再読み込みします。追加された行ごとに、IS_NEW の値を true に設定します。今後のクエリでは、IS_NEW の値が true であることを保証する WHERE 句を使用して、DT 列ではなく TS 列を参照します。
- E. テーブル CLICK_STREAM のすべての行を返すクエリを作成し、組み込み関数を使用して列 DT の文字列を TIMESTAMP 値にキャストします。列 TS が TIMESTAMP タイプである宛先テーブル NEW_CLICK_STREAM に対してクエリを実行します。今後は、テーブル CLICK_STREAM の代わりにテーブル NEW_CLICK_STREAM を参照します。今後、新しいデータはテーブル NEW_CLICK_STREAM にロードされます。
Answer: E
Reference:
テーブル スキーマの変更 |ビッグクエリ | Google Cloud
Question 25
Google Stackdriver Logging を使用して BigQuery の使用状況を監視したいと考えています。
挿入ジョブを使用して特定のテーブルに新しいデータが追加されたときに、監視ツールに即時通知を送信する必要がありますが、他のテーブルについては通知を受け取りたくありません。
何をするべきでしょうか?
- A. Stackdriver API を呼び出してすべてのログを一覧表示し、高度なフィルタを適用します。
- B. Stackdriver Logging 管理インターフェースで、BigQuery へのログシンク エクスポートを有効にします。
- C. Stackdriver Logging 管理インターフェースで、Pub/Sub へのログ シンク エクスポートを有効にし、モニタリング ツールからトピックにサブスクライブします。
- D. Stackdriver API を使用して、Pub/Sub にエクスポートするための高度なログ フィルタを備えたプロジェクト シンクを作成し、モニタリング ツールからトピックをサブスクライブします。
Answer: D
Reference:
ログ エクスプローラでクエリを作成する | Google Cloud
Question 26
あなたは、プライベート ユーザー データを含む機密プロジェクトに取り組んでいます。
Google Cloud Platform でプロジェクトをセットアップして、作業を内部に格納しました。外部のコンサルタントが、プロジェクトの Dataflow パイプラインでの複雑な変換のコーディングを支援します。
ユーザーのプライバシーをどのように維持するべきでしょうか?
- A. コンサルタントにプロジェクトの閲覧者の役割を付与します。
- B. プロジェクトに対する Dataflow 開発者の役割をコンサルタントに付与します。
- C. サービス アカウントを作成し、コンサルタントがそれを使用してログオンできるようにします。
- D. コンサルタントが別のプロジェクトで使用できるように、匿名化されたデータのサンプルを作成します。
Answer: D
Reference:
IAM によるアクセス制御 | Cloud Dataflow | Google Cloud
Question 27
特定の日に雨が降るかどうかを予測するモデルを構築しています。
何千もの入力特徴があり、モデルの精度への影響を最小限に抑えながら、いくつかの特徴を削除することでトレーニング速度を改善できるかどうかを確認したいと考えています。
何ができるでしょうか?
- A. 出力ラベルとの相関性が高い特徴を除外します。
- B. 相互依存性の高い機能を 1 つの代表的な機能に結合します。
- C. 各特徴を個別に入力する代わりに 3 つのバッチでそれらの値を平均します。
- D. トレーニング レコードの 50% を超える null 値を持つ機能を削除します。
Answer: B
Question 28
あなたの会社は Dataflow で学習アルゴリズムのデータ前処理を行っています。
このステップでは多数のデータ ログが生成されており、チームはそれらを分析したいと考えています。キャンペーンの動的な性質により、データは 1 時間ごとに指数関数的に増加しています。データ サイエンティストは、ログ内の新しい主要な機能のデータを読み取るために次のコードを作成しました。
Google BigQueryIO.Read -
.named("ReadLogData")
.from("clouddataflow-readonly:samples.log_data")このデータ読み取りのパフォーマンスを改善したいと考えています。
何をするべきでしょうか?
- A. コードで TableReference オブジェクトを指定します。
- B. .fromQuery 操作を使用してテーブルから特定のフィールドを読み取ります。
- C. BigQuery の TableSchema クラスと TableFieldSchema クラスの両方を使用します。
- D. PCollection の各要素がテーブルの 1 つの行を表す TableRow オブジェクトを返す変換を呼び出します。
Answer: B
Reference:
BigQuery でコストを管理 | Google Cloud
Question 29
あなたの会社は、リアルタイムのセンサー データを工場フロアから Cloud Bigtable にストリーミングしていますが、パフォーマンスが非常に悪いことに気付きました。
リアルタイム ダッシュボードに入力するクエリで Cloud Bigtable のパフォーマンスを向上させるには、行キーをどのように再設計するべきでしょうか?
- A. <timestamp> の形式の行キーを使用します。
- B. <sensorid> の形式の行キーを使用します。
- C. <timestamp>#<sensorid> の形式の行キーを使用します。
- D. >#<sensorid>#<timestamp> の形式の行キーを使用します。
Answer: D
Question 30
あなたの会社の顧客データベースと注文データベースは、多くの場合、大きな負荷がかかっています。
これにより、運用に影響を与えずにそれらに対して分析を実行することが困難になります。データベースは MySQL クラスタ内にあり、mysqldump を使用して毎晩バックアップが作成されます。運用への影響を最小限に抑えて分析を実行したい。
何をするべきでしょうか?
- A. MySQL クラスタにノードを追加し、そこに OLAP キューブを構築します。
- B. ETL ツールを使用して MySQL から BigQuery にデータをロードします。
- C. オンプレミスの Apache Hadoop クラスタを MySQL に接続し、ETL を実行します。
- D. バックアップを Google Cloud SQL にマウントし、Dataproc を使用してデータを処理します。
Answer: B
Question 31
Pub/Sub サブスクリプションをソースとして実行している Dataflow ストリーミング パイプラインがあります。
新しい Dataflow パイプラインが現在のバージョンと互換性がなくなるように、コードを更新する必要があります。この更新を行う際にデータを失いたくありません。
何をするべきでしょうか?
- A. 現在のパイプラインを更新し、ドレイン フラグを使用します。
- B. 現在のパイプラインを更新し、変換マッピング JSON オブジェクトを提供します。
- C. 同じ Pub/Sub サブスクリプションを持つ新しいパイプラインを作成し、古いパイプラインをキャンセルします。
- D. 新しい Pub/Sub サブスクリプションを持つ新しいパイプラインを作成し、古いパイプラインをキャンセルします。
Answer: A
Reference:
既存のパイプラインを更新する | Cloud Dataflow | Google Cloud
Question 32
あなたの会社は、最初のダイナミック キャンペーンを実施しており、ホリデー シーズン中にリアルタイム データを分析してさまざまなオファーを提供しています。
データ サイエンティストは 30 日間のキャンペーン中に 1 時間ごとに急増する数テラバイトのデータを収集しています。Dataflow を使用してデータを前処理し、Google Cloud Bigtable の機械学習モデルに必要な特徴 (シグナル) データを収集しています。チームは 10 TB のデータの初期ロードの読み取りと書き込みで、最適ではないパフォーマンスを観察しています。コストを最小限に抑えながら、このパフォーマンスを向上させたいと考えています。
チームは何をすべきでしょうか?
- A. テーブルの行スペース全体に読み取りと書き込みを均等に分散することにより、スキーマを再定義します。
- B. BigDate クラスタのサイトが増えるにつれて、パフォーマンスの問題は時間の経過とともに解決されるはずです。
- C. クラスタ内で頻繁に更新する必要がある値を識別するために単一の行キーを使用するようにスキーマを再設計します。
- D. スキーマを再設計して、オファーを表示するユーザーごとに順次増加する数値 ID に基づく行キーを使用します。
Answer: A
Question 33
ソフトウェアは、すべてのメッセージに単純な JSON 形式を使用します。
これらのメッセージは Pub/Sub に公開され、Dataflow で処理されて CFO 用のリアルタイム ダッシュボードが作成されます。テスト中に、ダッシュボードにいくつかのメッセージが表示されないことに気付きました。ログを確認すると、すべてのメッセージが Pub/Sub に正常に公開されています。
次に何をすべきでしょうか?
- A. ダッシュボード アプリケーションが正しく表示されていないか確認してください。
- B. Dataflow パイプラインを介して固定データセットを実行し、出力を分析します。
- C. Pub/Sub で Google Stackdriver Monitoring を使用して、不足しているメッセージを見つけます。
- D. Pub/Sub がメッセージを Dataflow に push するのではなく、Pub/Sub からメッセージを pull するように Dataflow を切り替えます。
Answer: B
Question 34
Flowlogistic のケーススタディをご確認ください。
Flowlogistic は BigQuery を主要な分析システムとして使用したいと考えていますが、BigQuery に移行できない Apache Hadoop と Spark のワークロードがまだ残っています。
Flowlogistic は、両方のワークロードに共通するデータを保存する方法を知りません。
Flowlogistic は何をすべきですか?
- A. 共通データを分割テーブルとして BigQuery に保存する。
- B. 共通データを BigQuery に保存し、承認されたビューを公開する。
- C. Avro としてエンコードされた共通データを Cloud Storage に保存します。
- D. Dataproc クラスタの HDFS ストレージに共通データを保存します。
Answer: C
Question 35
Flowlogistic のケーススタディをご確認ください。
Flowlogistic の経営陣は、現在の Apache Kafka サーバーではリアルタイムの在庫追跡システムのデータ量を処理できないと判断しました。
独自の追跡ソフトウェアにフィードする新しいシステムを Google Cloud Platform (GCP) 上に構築する必要があります。システムは、さまざまなグローバル ソースからデータを取り込み、リアルタイムで処理およびクエリを実行し、データを確実に保存できる必要があります。
GCP プロダクトのどの組み合わせを選択するべきでしょうか?
- A. Pub/Sub、Dataflow、Cloud Storage
- B. Pub/Sub、Dataflow、ローカル SSD
- C. Pub/Sub、Cloud SQL、Cloud Storage
- D. Cloud Load Balancing、Dataflow、Cloud Storage
Answer: A
Question 36
Flowlogistic のケーススタディをご確認ください。
Flowlogistic の CEO は、営業チームが現場でより多くの情報を得られるように顧客ベースを迅速に把握したいと考えています。
このチームはあまり技術的ではないため、BigQuery レポートの作成を簡素化するための可視化ツールを購入しました。しかし、チームはテーブル内のすべてのデータに圧倒されており、必要なデータを見つけようとするクエリに多額の費用を費やしています。最も費用対効果の高い方法で問題を解決したいと考えています。
何をするべきでしょうか?
- A. 仮想化のためにデータを Google スプレッドシートにエクスポートします。
- B. 必要な列のみを含む追加のテーブルを作成します。
- C. テーブルにビューを作成して、仮想化ツールに提示します。
- D. 適切な列に ID およびアクセス管理 (IAM) ロールを作成して、それらのみがクエリに表示されるようにします。
Answer: C
Question 37
Flowlogistic のケーススタディをご確認ください。
Flowlogistic は、リアルタイムの在庫追跡システムを展開しています。
追跡デバイスはすべて、パッケージ追跡メッセージを送信します。このメッセージは、Apache Kafka クラスタではなく、単一の Pub/Sub トピックに送信されます。次に、サブスクライバー アプリケーションがメッセージを処理してリアルタイム レポートを作成し、履歴分析のために BigQuery に保存します。パッケージ データを長期的に分析できるようにする必要があります。
どのアプローチを取るべきですか?
- A. 受信した Pub/Sub サブスクライバー アプリケーションの各メッセージにタイムスタンプを添付します。
- B. Pub/Sub に送信される各パブリッシャー デバイスからのアウトバウンド メッセージに、タイムスタンプとパッケージ ID を添付します。
- C. BigQuery で NOW () 関数を使用して、イベントの時間を記録する。
- D. Pub/Sub から自動生成されたタイムスタンプを使用してデータを並べ替える。
Answer: B
Question 38
MJTelco のケーススタディをご確認ください。
MJTelco の Dataflow パイプラインは 50,000 のインストールからデータを受信する準備が整いました。
Dataflow が必要に応じてコンピューティング能力をスケールアップできるようにしたいと考えています。
どの Dataflow パイプライン構成設定を更新するべきでしょうか?
- A. ゾーン
- B. 労働者の数
- C. ワーカーあたりのディスク サイズ
- D. ワーカーの最大数
Answer: D
Reference:
Pipeline options #Resource utilization | Dataflow
Question 39
MJTelco のケーススタディをご確認ください。
次の要件を満たす運用チーム向けのビジュアライゼーションを作成する必要があります。
・レポートには、直近 6 週間の 50,000 のインストールすべてからのテレメトリ データが含まれている必要があります (1 分ごとにサンプリング)。
・レポートはライブ データから 3 時間以上遅れてはなりません。
・実用的なレポートには、次善のリンクのみを表示する必要があります。
・最適ではないリンクのほとんどは、一番上にソートする必要があります。
・最適でないリンクは、地域の地理によってグループ化およびフィルタリングできます。
・レポートをロードするユーザーの応答時間は 5 秒未満である必要があります。
要件を満たすアプローチはどれですか?
- A. データを Google スプレッドシートに読み込み、数式を使用して指標を計算し、フィルタ/並べ替えを使用して、最適でないリンクのみをテーブルに表示します。
- B. データを BigQuery テーブルにロードし、データのクエリを実行する Google Apps スクリプトを作成し、メトリックを計算して Google スプレッドシートのテーブルに最適でない行のみを表示します。
- C. データを Datastore テーブルにロードし、すべての行をクエリする Google App Engine アプリケーションを作成し、関数を適用して指標を導出し、Google チャートと視覚化 API を使用して結果をテーブルにレンダリングします。
- D. データを BigQuery テーブルにロードし、データに接続する Google データスタジオ 360 レポートを作成し、メトリクスを計算してからフィルタ式を使用してテーブル内の次善の行のみを表示します。
Answer: D
Question 40
MJTelco のケーススタディをご確認ください。
Google Data Studio 360 で大規模なチーム用の新しいレポートを作成します。
レポートはデータ ソースとして BigQuery を使用します。従業員が自分の地域に関連付けられたデータのみを表示できるようにすることが会社のポリシーであるため、地域ごとにテーブルを作成して入力します。データに地域アクセス ポリシーを適用する必要があります。
どのアクションを実行するべきでしょうか? (回答を 2つ選択してください)
- A. すべてのテーブルがグローバル データセットに含まれていることを確認します。
- B. 各テーブルが地域のデータセットに含まれていることを確認します。
- C. 各テーブルの設定を調整して関連する地域ベースのセキュリティ グループ ビュー アクセスを許可します。
- D. 各ビューの設定を調整して関連する地域ベースのセキュリティ グループ ビュー アクセスを許可します。
- E. 各データセットの設定を調整して関連する地域ベースのセキュリティ グループ ビュー アクセスを許可します。
Answer: B、E
Question 41
MJTelco のケーススタディをご確認ください。
MJTelco は、過去 2 年間のレコードの履歴分析を可能にするスキーマを Cloud Bigtable で作成する必要があります。
着信する各レコードは 15 分ごとに送信され、デバイスの一意の識別子とデータ レコードが含まれます。最も一般的なクエリは、特定の日の特定のデバイスのすべてのデータに対するものです。
どのスキーマを使用するべきでしょうか?
- A. Rowkey: date#device_id Column data: data_point
- B. Rowkey: date Column data: device_id, data_point
- C. Rowkey: device_id Column data: date, data_point
- D. Rowkey: data_point Column data: device_id, date
- E. Rowkey: date#data_point Column data: device_id
Answer: A
Question 42
あなたの会社は最近急速に成長し、以前よりもはるかに高い速度でデータを取り込むようになりました。
Apache Hadoop で毎日のバッチ MapReduce 分析ジョブを管理します。ただし、最近のデータの増加は、バッチ ジョブが遅れをとっていることを意味しています。あなたは、開発チームがコストを増やさずに分析の応答性を向上させる方法を推奨するよう求められました。
開発チームに何をすすめるべきですか?
- A. Pig でジョブを書き直します。
- B. Apache Spark でジョブを書き直す。
- C. Hadoop クラスタのサイズを増やします。
- D. Hadoop クラスタのサイズを小さくするだけでなく、Hive でジョブを書き直す。
Answer: B
Question 43
あなたは 400,000 人以上の従業員を抱える大規模なファーストフード レストラン チェーンで働いています。
FirstName フィールドと LastName フィールドで構成される Users テーブルに、BigQuery の従業員情報を保存します。IT のメンバーがアプリケーションを構築しており、BigQuery のスキーマとデータを変更して、スペースで連結された FirstName フィールドの値とそれに続く LastName フィールドの値で構成される FullName フィールドをアプリケーションがクエリできるようにするよう依頼されました。従業員。
コストを最小限に抑えながら、そのデータを利用できるようにするにはどうすればよいでしょうか?
- A. FirstName フィールドと LastName フィールドの値を連結して FullName を生成するビューを BigQuery で作成します。
- B. FullName という新しい列を Users テーブルに追加します。FirstName 値と LastName 値を連結して各ユーザーの FullName 列を更新する UPDATE ステートメントを実行します。
- C. ユーザー テーブル全体に対して BigQuery にクエリを実行し、各ユーザーの FirstName 値と LastName 値を連結し、FirstName、LastName、および FullName の適切な値を BigQuery の新しいテーブルに読み込む Dataflow ジョブを作成します。
- D. BigQuery を使用して、テーブルのデータを CSV ファイルにエクスポートします。Dataproc ジョブを作成して CSV ファイルを処理し、FirstName、LastName、FullName の適切な値を含む新しい CSV ファイルを出力します。BigQuery 読み込みジョブを実行して、新しい CSV ファイルを BigQuery に読み込みます。
Answer: B
Question 44
メディア ストリーミング サービスであるモバイル アプリケーション用の新しいストレージ システムを展開しています。
最適なのは Datastore であると判断します。複数のプロパティを持つエンティティがあり、その一部は複数の値を取ることができます。たとえば、エンティティ Movie では、プロパティ アクターとプロパティ タグに複数の値がありますが、リリースされたプロパティの日付にはありません。一般的なクエリでは actor=<actorname> のすべての映画を date_released で並べ替えるか、tag=Comedy のすべての映画を date_released で並べ替えるかを尋ねます。
インデックス数の組み合わせによる爆発をどのように回避するべきでしょうか?
- A. 次のように、インデックス構成でインデックスを手動で構成します。
Indexes:
-kind: Movie
Properties:
-name: actors
name date_released
-kind: Movie
Properties:
-name: tags
name: date_released- B. 次のように、インデックス構成でインデックスを手動で構成します。
Indexes:
-kind: Movie
Properties:
-name: actors
-name: date_published- C. エンティティ オプションで次のように設定します。
exclude_from_indexes = actors, tags - D. エンティティ オプションで次のように設定します。
exclude_from_indexes = date_published
Answer: A
Question 45
あなたは 1 日 1 回午前 2 時にアプリケーション ログ ファイルを 1 つのログ ファイルにまとめる製造工場で働いています。
そのログ ファイルを処理する Dataflow ジョブを作成しました。ログ ファイルが 1 日 1 回、できるだけ安価に処理されるようにする必要があります。
何をするべきでしょうか?
- A. 代わりに Dataproc を使用するように処理ジョブを変更します。
- B. 毎朝、出社時に Dataflow ジョブを手動で開始します。
- C. Dataflow ジョブを実行するために Google App Engine Cron Service で cron ジョブを作成します。
- D. Dataflow ジョブをストリーミング ジョブとして構成し、ログ データをすぐに処理する。
Answer: C
Question 46
あなたは経済コンサルティング会社で働いており、企業が経済動向を把握するのを支援しています。
分析の一環として BigQuery を使用して、パン、ガソリン、牛乳など、最も一般的に販売されている 100 の商品の平均価格と顧客データを関連付けます。これらの商品の平均価格は 30 分ごとに更新されます。このデータを最新の状態に保ち、できるだけ安価に BigQuery の他のデータと組み合わせることができるようにしたいと考えています。
何をするべきでしょうか?
- A. BigQuery の新しい分割テーブルに 30 分ごとにデータを読み込みます。
- B. 地域の Cloud Storage バケットにデータを保存して更新し、BigQuery でフェデレーション データ ソースを作成します。
- C. Datastore にデータを保存します。Dataflow を使用して BigQuery にクエリを実行し、そのデータをプログラムで Datastore に保存されているデータと組み合わせます。
- D. 地域の Cloud Storage バケット内のファイルにデータを保存します。Dataflow を使用して BigQuery にクエリを実行し、そのデータをプログラムで Cloud Storage に保存されているデータと結合します。
Answer: B
Question 47
ユーザーが何を食べたいかを予測する機械学習ベースの食品注文サービスのデータベース スキーマを設計しています。
保存する必要がある情報の一部を次に示します。
・ユーザープロフィール:好きなもの、嫌いなもの
・ユーザーアカウント情報:氏名、住所、希望食事時間
・注文情報:いつ、どこから、誰に注文したか
データベースは、製品のすべてのトランザクション データを保存するために使用されます。データ スキーマを最適化したい。
どの Google Cloud Platform プロダクトを使用するべきでしょうか?
- A. BigQuery
- B. Cloud SQL
- C. Cloud Bigtable
- D. Datastore
Answer: A
Question 48
あなたの会社は、コンマ区切り値 (CSV) ファイルを BigQuery に読み込んでいます。
データは正常に完全にインポートされました。ただし、インポートされたデータはバイト単位でソース ファイルと一致しません。
この問題の最も可能性の高い原因は何でしょうか?
- A. BigQuery に読み込まれた CSV データは CSV としてフラグ付けされていません。
- B. CSV データにはインポート時にスキップされた無効な行があります。
- C. BigQuery に読み込まれた CSV データは BigQuery のデフォルトのエンコードを使用していません。
- D. CSV データは BigQuery にロードする前に ETL フェーズを経ていません。
Answer: C
Question 49
あなたの会社では、毎時 20,000 個のファイルが生成されます。
各データ ファイルは 4 KB 未満のカンマ区切り値 (CSV) ファイルとしてフォーマットされます。すべてのファイルは、処理する前に Google Cloud Platform に取り込む必要があります。あなたの会社のサイトでは、Google Cloud に対して 200 ミリ秒のレイテンシがあり、インターネット接続の帯域幅は 50 Mbps に制限されています。あなたは現在、セキュア FTP (SFTP) サーバーをデータ取り込みポイントとして Compute Engine の仮想マシンにデプロイしています。ローカルの SFTP クライアントは、専用のマシンで実行され、CSV ファイルをそのまま送信します。目標は、毎日午前 10 時までに前日のデータを含むレポートを幹部が利用できるようにすることです。この設計は、帯域幅の使用率がかなり低いにもかかわらず、現在のボリュームにほとんど追いつくことができません。
あなたの会社は、季節的な理由から、今後 3 か月でファイル数が 2 倍になると予想しているとのことです。
どのアクションを実行するべきでしょうか? (回答を 2つ選択してください)
- A. 各ファイルにデータ圧縮を導入して、ファイル転送速度を上げます。
- B. インターネット サービス プロバイダー (ISP) に連絡して、最大帯域幅を少なくとも 100 Mbps に増やしてください。
- C. データ取り込みプロセスを再設計して、gsutil ツールを使用して CSV ファイルをストレージ バケットに並行して送信します。
- D. 1,000 個のファイルをテープ アーカイブ (TAR) ファイルにまとめます。代わりに TAR ファイルを送信し CSV ファイルを受信したらクラウドで分解します。
- E. ネットワークに S3 互換のストレージ エンドポイントを作成し、Cloud Storage Transfer Service を使用してオンプレミス データを指定のストレージ バケットに転送します。
Answer: C、D
Question 50
何百万ものモノのインターネット (IoT) デバイスから送信されたテレメトリ データを処理する NoSQL データベースを選択しています。
データ量は年間 100 TB で増加しており、各データ エントリには約 100 の属性があります。データ処理パイプラインには、原子性、一貫性、分離、耐久性 (ACID) は必要ありません。ただし、高可用性と低遅延が必要です。個々のフィールドに対してクエリを実行してデータを分析する必要があります。
要件を満たすデータベースはどれでしょうか? (回答を 3つ選択してください)
- A. Redis
- B. HBase
- C. MySQL
- D. MongoDB
- E. Cassandra
- F. HDFS with Hive
Answer: B、D、E
Question 51
スパム分類子をトレーニングしています。
トレーニング データがオーバーフィットしていることに気付きました。
この問題を解決するために実行できるアクションを選択してください。(回答を 3つ選択してください)
- A. より多くのトレーニング例を取得する。
- B. トレーニング例の数を減らす。
- C. 少数の機能セットを使用する。
- D. より多くの機能セットを使用する。
- E.正則化パラメータを増やす。
- F. 正則化パラメーターを減らす。
Answer: A、C、E
Question 52
データ パイプラインにセキュリティのベスト プラクティスを実装しています。
現在、あなたはプロジェクト オーナーとして手動でジョブを実行しています。Cloud Storage から非公開情報を含む夜間のバッチ ファイルを取得し、Dataproc クラスタで Spark Scala ジョブを使用してそれらを処理し、結果を BigQuery にデポジットすることで、これらのジョブを自動化したいと考えています。
このワークロードをどのように安全に実行するべきでしょうか?
- A. Cloud Storage バケットを制限して自分だけがファイルを表示できるようにします。
- B. プロジェクト オーナーの役割をサービス アカウントに付与し、それを使用してジョブを実行します。
- C. バッチ ファイルの読み取りと BigQuery への書き込みができるサービス アカウントを使用します。
- D. Dataproc クラスタでプロジェクト閲覧者の役割を持つユーザー アカウントを使用して、バッチ ファイルを読み取り、BigQuery に書き込みます。
Answer: C
Question 53
BigQuery をデータ ウェアハウスとして使用しています。
次の単純なクエリは、いつクエリを実行しても非常に遅いとユーザーから報告されています。
[myproject:mydataset.mytable] GROUP BY country から国、州、都市を選択します。
クエリのクエリ プランを確認すると、Stage:1 の Read セクションに次の出力が表示されます。

このクエリの遅延の最も可能性の高い原因は何ですか?
- A. ユーザーがシステムで実行している同時クエリが多すぎます。
- B. [myproject:mydataset.mytable] テーブルにパーティションが多すぎます。
- C. [myproject:mydataset.mytable] テーブルの州列または都市列に NULL 値が多すぎます。
- D. [myproject:mydataset.mytable] テーブルのほとんどの行で、country 列に同じ値が含まれているため、データの偏りが生じる。
Answer: D
Question 54
グローバルに分散されたオークション アプリケーションにより、ユーザーはアイテムに入札できます。
場合によっては、ユーザーがほぼ同じ時間に同じ入札を行い、異なるアプリケーション サーバーがそれらの入札を処理することがあります。各入札イベントには、アイテム、金額、ユーザー、およびタイムスタンプが含まれています。これらの入札イベントをリアルタイムで 1 つの場所に照合して、どのユーザーが最初に入札したかを判断したいと考えています。
何をするべきでしょうか?
- A. 共有ファイルにファイルを作成し、アプリケーション サーバーがすべての入札イベントをそのファイルに書き込むようにします。ファイルを Apache Hadoop で処理して最初に入札したユーザーを特定します。
- B. 各アプリケーション サーバーで入札イベントが発生したときに Pub/Sub に書き込みます。Pub/Sub から入札イベント情報を Cloud SQL に書き込むカスタム エンドポイントにイベントを push します。
- C. アプリケーション サーバーごとに MySQL データベースをセットアップして入札イベントを書き込みます。これらの分散型 MySQL データベースのそれぞれに定期的にクエリを実行し、マスター MySQL データベースを入札イベント情報で更新します。
- D. 各アプリケーション サーバーで、入札イベントが発生したときに Pub/Sub に書き込みます。pull サブスクリプションを使用して Dataflow を使用して入札イベントを pull します。最初に処理される入札イベントで各アイテムの入札をユーザーに与えます。
Answer: B
Question 55
あなたの組織は 6 か月間 BigQuery でデータを収集して分析しています。
分析されたデータの大部分は events_partitioned という名前の時間分割テーブルに配置されます。クエリのコストを削減するために組織はイベントと呼ばれるビューを作成しました。このビューは、過去 14 日間のデータのみをクエリします。ビューはレガシー SQL で記述されます。来月、既存のアプリケーションが BigQuery に接続され、ODBC 接続を介してイベント データが読み取られるようになります。アプリケーションが接続できることを確認する必要があります。
どのアクションを実行するべきでしょうか? (回答を 2つ選択してください)
- A. 標準 SQL を使用してイベントの新しいビューを作成します。
- B. 標準の SQL クエリを使用して、新しい分割テーブルを作成します。
- C. 標準 SQL を使用して events_partitioned に新しいビューを作成します。
- D. 認証に使用する ODBC 接続用のサービス アカウントを作成します。
- E. ODBC 接続と共有イベント用の Google Cloud Identity and Access Management (Cloud IAM) ロールを作成します。
Answer: C、D
Question 56
Firebase Analytics と BigQuery 間の無料の統合が有効になりました。
Firebase は app_events_YYYYMMDD の形式で BigQuery に新しいテーブルを毎日自動的に作成するようになりました。過去 30 日間のすべてのテーブルをレガシー SQL でクエリしたいと考えています。
何をするべきでしょうか?
- A. TABLE_DATE_RANGE 関数を使用します。
- B. WHERE_PARTITIONTIME 疑似列を使用します。
- C. YYYY-MM-DD と YYYY-MM-DD の間の WHERE 日付を使用します。
- D. SELECT IF.(date >= YYYY-MM-DD AND date <= YYYY-MM-DD を使用します。
Answer: A
Reference:
Google Developers Japan: BigQuery と Firebase Analytics でモバイルアプリを理解する
Question 57
あなたの会社は現在、キャンペーン用のデータ パイプラインを設定しています。
すべての Pub/Sub ストリーミング データについて、重要なビジネス要件の 1 つは、キャンペーン中の入力とそのタイミングを定期的に特定できることです。エンジニアは、この目的のために Dataflow でウィンドウ処理と変換を使用することにしました。ただし、この機能をテストすると、すべてのストリーミング挿入で Dataflow ジョブが失敗することがわかりました。
この問題の最も可能性の高い原因は何でしょうか?
- A. タイムスタンプが割り当てられていないため、ジョブが失敗します。
- B. 遅れて入ってくるデータに対応するトリガーを設定していないため、ジョブが失敗します。
- C. グローバル ウィンドウ関数が適用されていないため、パイプラインの作成時にジョブが失敗します。
- D. 非グローバル ウィンドウ機能を適用していないため、パイプラインの作成時にジョブが失敗します。
Answer: D
Question 58
地震データを分析するシステムを設計します。
抽出、変換、読み込み (ETL) プロセスは、Apache Hadoop クラスタで一連の MapReduce ジョブとして実行されます。一部のステップは計算コストがかかるため、ETL プロセスではデータ セットの処理に数日かかります。次に、センサーのキャリブレーション手順が省略されていることに気付きます。
将来的にセンサーのキャリブレーションを体系的に実行するには、ETL プロセスをどのように変更するべきでしょうか?
- A. transformMapReduce ジョブを変更して他の処理を行う前にセンサー キャリブレーションを適用します。
- B. 新しい MapReduce ジョブを導入してセンサー キャリブレーションを生データに適用し、この後に他のすべての MapReduce ジョブが確実に連鎖されるようにします。
- C. ETL プロセスの出力にセンサー キャリブレーション データを追加し、すべてのユーザーがセンサー キャリブレーションを自分で適用する必要があることを文書化します。
- D. キャリブレーション係数に基づいて最後の MapReduce ジョブから出力されたデータの分散を予測するシミュレーションを通じてアルゴリズムを開発し、すべてのデータに補正を適用します。
Answer: B
Question 59
オンライン小売業者は、現在のアプリケーションを Google App Engine 上に構築しました。
同社の新しいイニシアチブでは、顧客がアプリケーションを介して直接取引できるようにアプリケーションを拡張することが義務付けられています。ビジネス インテリジェンス (BI) ツールを使用して、ショッピング トランザクションを管理し、複数のデータセットから結合されたデータを分析する必要があります。この目的のために単一のデータベースのみを使用したいと考えています。
どの Google Cloud データベースを選択するべきでしょうか?
- A. BigQuery
- B. Cloud SQL
- C. Cloud Bigtable
- D. Datastore
Answer: B
Question 60
あなたはほぼ 3 年前に新しいゲーム アプリを立ち上げました。
前日のログ ファイルを別の BigQuery テーブルに、テーブル名形式 LOGS_yyyymmdd でアップロードしています。テーブル ワイルドカード関数を使用して、すべての時間範囲の日次および月次レポートを生成してきました。最近、長い日付範囲をカバーする一部のクエリが 1,000 テーブルの制限を超えて失敗していることを発見しました。
この問題をどのように解決できますか?
- A. すべての日次ログ テーブルを日付分割テーブルに変換します。
- B. シャード テーブルを単一のパーティション テーブルに変換します。
- C. クエリのキャッシュを有効にして前の月のデータをキャッシュできるようにします。
- D. 各月をカバーする個別のビューを作成し、これらのビューからクエリを実行します。
Answer: B
Question 61
あなたの分析チームは、いくつかの異なる指標に基づいて、どの顧客があなたの会社と再び仕事をする可能性が最も高いかを判断するための単純な統計モデルを構築したいと考えています。
分析チームは Cloud Storage に格納されたデータを使用して Apache Spark でモデルを実行したいと考えており、あなたは Dataproc を使用してこのジョブを実行することを推奨しています。テストの結果、このワークロードは 15 ノードのクラスタで約 30 分で実行でき、結果を BigQuery に出力できることが示されています。このワークロードを毎週実行する計画です。
クラスタのコストをどのように最適化するべきでしょうか?
- A. ワークロードを Dataflow に移行します。
- B. クラスタにプリエンプティブル仮想マシン (VM) を使用します。
- C. ジョブがより高速に実行されるようにメモリの大きいノードを使用します。
- D. ワーカーノードで SSD を使用してジョブをより高速に実行できるようにします。
Answer: B
Question 62
あなたの会社は、バッチ ベースとストリーム ベースの両方のイベント データを受け取ります。
予測可能な期間にわたって Dataflow を使用してデータを処理したいと考えています。ただし、場合によっては、データが遅れて到着したり、順不同で到着したりする可能性があることに気付きます。
遅れているデータや順不同のデータを処理するには Dataflow パイプラインをどのように設計するべきでしょうか?
- A. 単一のグローバル ウィンドウを設定してすべてのデータをキャプチャします。
- B. スライディング ウィンドウを設定して遅延データをすべてキャプチャします。
- C. 透かしとタイムスタンプを使用して遅延データをキャプチャします。
- D. すべてのデータソース タイプ (ストリームまたはバッチ) にタイムスタンプがあることを確認し、タイムスタンプを使用して遅延データのロジックを定義します。
Answer: C
Question 63
下の図に示すデータがあります。
2 つの次元は X と Y であり、各ドットの陰影はそれがどのクラスであるかを表します。線形アルゴリズムを使用して、このデータを正確に分類したいと考えています。これを行うには、合成機能を追加する必要があります。
その機能の価値はどうあるべきか?
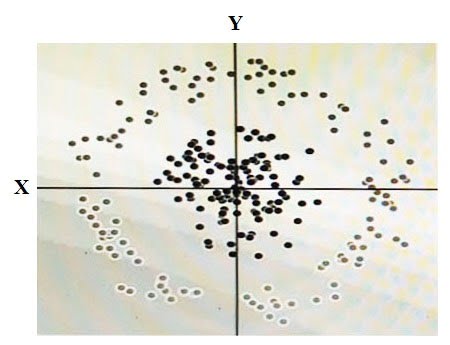
- A.X2+Y2
- B.X2
- C.Y2
- D.cos(X)
Answer: A
Question 64
内部 IT アプリケーションの 1 つと BigQuery を統合しているため、ユーザーはアプリケーションのインターフェースから BigQuery にクエリを実行できます。
個々のユーザーが BigQuery に対して認証されないようにし、データセットへのアクセス権を付与したくない。IT アプリケーションから BigQuery に安全にアクセスする必要があります。
何をするべきでしょうか?
- A. ユーザーのグループを作成し、それらのグループにデータセットへのアクセスを許可します。
- B. シングル サインオン (SSO) プラットフォームと統合し、各ユーザーの資格情報をクエリ要求と共に渡す。
- C. サービス アカウントを作成し、そのアカウントにデータセットへのアクセスを許可します。サービス アカウントの秘密鍵を使用してデータセットにアクセスします。
- D.ダミーユーザーを作成し、そのユーザーにデータセットへのアクセスを許可します。そのユーザーのユーザー名とパスワードをファイル システム上のファイルに保存し、それらの認証情報を使用して BigQuery データセットにアクセスします。
Answer: C
Question 65
あなたは Google Cloud でデータ パイプラインを構築しています。
機械学習プロセスの因果的方法を使用してデータを準備する必要があります。ロジスティック回帰モデルをサポートしたい。また、null 値を監視して調整する必要があります。null 値は実数値のままにしておく必要があり、削除できません。
何をするべきでしょうか?
- A. Cloud Dataprep を使用して、サンプル ソース データの null 値を見つけます。Dataproc ジョブを使用して、すべての null を「none」に変換します。
- B. Cloud Dataprep を使用して、サンプル ソース データの null 値を見つける。Cloud Dataprep ジョブを使用して、すべての null を 0 に変換します。
- C. Dataflow を使用して、サンプル ソース データの null 値を見つける。Cloud Dataprep ジョブを使用して、すべての null を「none」に変換します。
- D. Dataflow を使用して、サンプル ソース データの null 値を見つける。カスタム スクリプトを使用して、すべてのヌルを 0 に変換します。
Answer: B
Question 66
Kafka クラスタを介して Redis クラスタへのストリーミング データ挿入をセットアップします。
両方のクラスタが Compute Engine インスタンスで実行されています。必要に応じて作成、ローテーション、および破棄できる暗号化キーを使用して保管中のデータを暗号化する必要があります。
何をするべきでしょうか?
- A. 専用のサービス アカウントを作成し、保存時の暗号化を使用して API サービス呼び出しの一部として Compute Engine クラスタ インスタンスに保存されているデータを参照します。
- B. Cloud Key Management Service で暗号鍵を作成します。これらの鍵を使用して、すべての Compute Engine クラスタ インスタンスでデータを暗号化します。
- C. 暗号化キーをローカルで作成します。暗号鍵を Cloud Key Management Service にアップロードします。これらの鍵を使用して、すべての Compute Engine クラスタ インスタンスでデータを暗号化します。
- D. Cloud Key Management Service で暗号化キーを作成します。Compute Engine クラスタ インスタンスのデータにアクセスするときに API サービス呼び出しでこれらのキーを参照します。
Answer: B
Question 67
Google Cloud でレコメンデーション エンジンを使用するアプリケーションを開発しています。
ソリューションでは、過去の視聴に基づいて顧客に新しい動画を表示する必要があります。ソリューションでは、顧客が視聴した動画内のエンティティのラベルを生成する必要があります。設計では、数 TB のデータに関する他の顧客の好みからのデータに基づいて、非常に高速なフィルタリングの提案を提供できる必要があります。
何をするべきでしょうか?
- A. Spark MLlib を使用して複雑な分類モデルを構築およびトレーニングし、ラベルを生成して結果をフィルタリングします。Dataproc を使用してモデルをデプロイします。アプリケーションからモデルを呼び出します。
- B. Spark MLlib を使用して分類モデルを構築およびトレーニングし、ラベルを生成します。Spark MLlib を使用して 2 番目の分類モデルを構築およびトレーニングし、顧客の好みに合わせて結果をフィルタリングします。Dataproc を使用してモデルをデプロイします。アプリケーションからモデルを呼び出します。
- C. Cloud Video Intelligence API を呼び出してラベルを生成するアプリケーションを構築する。データを Cloud Bigtable に保存し、予測されたラベルをフィルタリングしてユーザーの閲覧履歴に一致させ、設定を生成します。
- D. Cloud Video Intelligence API を呼び出してラベルを生成するアプリケーションを構築する。データを Cloud SQL に保存し、予測されたラベルを結合してフィルタリングし、ユーザーの閲覧履歴と一致させて設定を生成します。
Answer: C
Question 68
Google Cloud 上のデータ パイプライン用に Pub/Sub から BigQuery に JSON メッセージを書き込んで変換するサービスを選択しています。
サービス コストを最小限に抑えたい。また、手動による介入を最小限に抑えて、サイズが変化する入力データ ボリュームを監視し、対応する必要もあります。
何をするべきでしょうか?
- A. Dataproc を使用して変換を実行します。クラスタの CPU 使用率を監視します。コマンド ラインを使用して、クラスタ内のワーカー ノードの数を変更します。
- B. Dataproc を使用して変換を実行します。操作出力アーカイブを生成するには diagnostic コマンドを使用します。ボトルネックを特定し、クラスタ リソースを調整します。
- C. Dataflow を使用して変換を実行します。Stackdriver でジョブ システムの遅延をモニタリングします。ワーカー インスタンスのデフォルトの Auto Scaling 設定を使用します。
- D. Dataflow を使用して変換を実行します。ジョブのサンプリングの合計実行時間を監視します。必要に応じて、デフォルト以外の Compute Engine マシンタイプを使用するようにジョブを構成します。
Answer: C
Question 69
インフラストラクチャには、一連の YouTube チャンネルが含まれています。
あなたは、分析のために YouTube チャンネル データを Google Cloud に送信するプロセスを作成する任務を負っています。あなたは、世界中のマーケティング チームが最新の YouTube チャンネル ログ データに対して ANSI SQL やその他の種類の分析を実行できるようにするソリューションを設計したいと考えています。
Google Cloud へのログ データ転送をどのように設定する必要がありますか。
- A. Storage Transfer Service を使用して、オフサイト バックアップ ファイルを Cloud Storage Multi-Regional ストレージ バケットに最終的な宛先として転送します。
- B. Storage Transfer Service を使用して、オフサイト バックアップ ファイルを Cloud Storage Regional バケットに最終的な転送先として転送します。
- C. BigQuery Data Transfer Service を使用して、オフサイト バックアップ ファイルを Cloud Storage Multi-Regional ストレージ バケットに最終転送先として転送します。
- D. BigQuery Data Transfer Service を使用して、オフサイト バックアップ ファイルを Cloud Storage Regional Storage バケットに最終的な転送先として転送します。
Answer: A
Question 70
あなたは Google Cloud のデータ パイプライン用に非常に大きなテキスト ファイル用のストレージを設計しています。
ANSI SQL クエリをサポートしたい。また、Google の推奨プラクティスを使用して、入力場所からの圧縮と並列読み込みをサポートする必要があります。
何をするべきでしょうか?
- A. Dataflow を使用してテキスト ファイルを圧縮 Avro に変換します。ストレージとクエリには BigQuery を使用します。
- B. Dataflow を使用してテキスト ファイルを圧縮 Avro に変換します。クエリには Cloud Storage と BigQuery の永続的なリンク テーブルを使用します。
- C. Grid Computing Tools を使用してテキスト ファイルを gzip に圧縮します。ストレージとクエリには BigQuery を使用します。
- D. Grid Computing Tools を使用してテキスト ファイルを gzip に圧縮します。Cloud Storage を使用してからクエリのために Cloud Bigtable にインポートします。
Answer: B
Question 71
あなたは、ユーザーのブログ投稿の件名ラベルを自動的に生成するアプリケーションを Google Cloud で開発しています。
この機能をすぐに追加しなければならないという競争圧力にさらされており、追加の開発者リソースがありません。チームの誰も機械学習の経験がありません。
何をするべきでしょうか?
- A. アプリケーションから Cloud Natural Language API を呼び出します。生成されたエンティティ分析をラベルとして処理します。
- B. アプリケーションから Cloud Natural Language API を呼び出します。生成された感情分析をラベルとして処理します。
- C. TensorFlow を使用してテキスト分類モデルを構築し、トレーニングします。Cloud Machine Learning Engine を使用してモデルをデプロイします。アプリケーションからモデルを呼び出し、結果をラベルとして処理します。
- D. TensorFlow を使用してテキスト分類モデルを構築し、トレーニングします。Kubernetes Engine クラスタを使用してモデルをデプロイします。アプリケーションからモデルを呼び出し、結果をラベルとして処理します。
Answer: A
Question 72
Google Cloud にデータ パイプラインをデプロイする一環として、20 TB のテキスト ファイル用のストレージを設計しています。
入力データは CSV 形式です。複数のエンジンで Cloud Storage のデータをクエリする複数のユーザーの集計値をクエリするコストを最小限に抑えたいと考えています。
どのストレージ サービスとスキーマ設計を使用するべきでしょうか?
- A. ストレージに Cloud Bigtable を使用します。HBase シェルを Compute Engine インスタンスにインストールして、Cloud Bigtable データにクエリを実行します。
- B. ストレージに Cloud Bigtable を使用します。クエリ用に BigQuery の永続テーブルとしてリンクします。
- C. ストレージに Cloud Storage を使用します。クエリ用に BigQuery の永続テーブルとしてリンクします。
- D. ストレージに Cloud Storage を使用します。クエリ用に BigQuery の一時テーブルとしてリンクします。
Answer: C
Question 73
あなたは Google Cloud 上の 10 TB データベースの一部である 2 つのリレーショナル テーブル用のストレージを設計しています。
水平方向にスケーリングするトランザクションをサポートしたい。また、非キー列に対する範囲クエリのデータを最適化する必要があります。
何をするべきでしょうか?
- A. ストレージに Cloud SQL を使用します。クエリ パターンをサポートするためにセカンダリ インデックスを追加します。
- B. ストレージに Cloud SQL を使用します。Dataflow を使用してデータを変換し、クエリ パターンをサポートします。
- C. ストレージに Cloud Spanner を使用します。クエリ パターンをサポートするためにセカンダリ インデックスを追加します。
- D. ストレージに Cloud Spanner を使用します。Dataflow を使用してデータを変換し、クエリ パターンをサポートします。
Answer: C
Question 74
あなたの金融サービス会社はクラウド テクノロジーに移行しており、50 TB の金融時系列データをクラウドに保存したいと考えています。
このデータは頻繁に更新され、新しいデータが常にストリーミングされます。あなたの会社はまた、既存の Apache Hadoop ジョブをクラウドに移行してこのデータに関する洞察を得たいと考えています。
データの保存にはどの製品を使用するべきでしょうか?
- A. Cloud Bigtable
- B. BigQuery
- C. Cloud Storage
- D. Datastore
Answer: A
Reference:
時系列データ用のスキーマ設計 | Cloud Bigtable ドキュメント | Google Cloud
Question 75
組織は、ユーザーレベルのデータを含むテーブルを含む BigQuery データセットを維持しています。
ユーザーレベルのデータへのアクセスを制御しながら、このデータの集計を他の Google Cloud プロジェクトに公開したいと考えています。さらに、全体的なストレージ コストを最小限に抑え、他のプロジェクトの分析コストがそれらのプロジェクトに割り当てられるようにする必要があります。
彼らは何をすべきですか?
- A. 集計結果を提供する承認済みビューを作成して共有します。
- B. 集計結果を提供する新しいデータセットとビューを作成して共有します。
- C. 集計結果を含む新しいデータセットとテーブルを作成して共有します。
- D. データセットに dataViewer Identity and Access Management (IAM) ロールを作成して、共有を有効にします。
Answer: B
Reference:
承認済みビューを作成する | BigQuery | Google Cloud
Question 76
業界の政府規制では、特定の種類のデータへのアクセスの監査可能な記録を維持する必要があります。
期限切れのすべてのログが正しくアーカイブされると仮定すると、その義務の対象となるデータをどこに保存するべきでしょうか?
- A. ユーザー指定の暗号鍵を使用して Cloud Storage で暗号化されます。承認された各ユーザーには個別の復号化キーが提供されます。
- B. 承認された担当者のみが表示できる BigQuery データセットで、監査可能性を提供するために使用されるデータアクセス ログ。
- C. Cloud SQL で各ユーザーに個別のデータベース ユーザー名を使用します。Cloud SQL 管理者アクティビティ ログは監査可能性を提供するために使用されます。
- D. ユーザー情報を収集し、バケットへのリンクを提供する前にアクセスをログに記録する AppEngine サービスによってのみアクセス可能な Cloud Storage 上のバケット内。
Answer: B
Question 77
ニューラル ネットワーク モデルのトレーニングに数日かかっています。
トレーニング速度を上げたいと思っています。
あなたは何ができますか?
- A. テスト データセットをサブサンプリングします。
- B. トレーニング データセットをサブサンプリングします。
- C. モデルへの入力フィーチャの数を増やします。
- D. ニューラル ネットワークのレイヤー数を増やす。
Answer: B
Reference:
Improving the Performance of a Neural Network | by Rohith Gandhi | Towards Data Science
Question 78
あなたは、会社の ETL パイプラインを記述して Apache Hadoop クラスタで実行する責任があります。
パイプラインには、いくつかのチェックポイントおよび分割パイプラインが必要です。
パイプラインを作成するには、どの方法を使用するべきでしょうか?
- A. Pig を使用した PigLatin
- B. Hive を使用した HiveQL
- C. MapReduce を使用する Java
- D. MapReduce を使用する Python
Answer: A
Question 79
あなたの会社は、匿名化された顧客データに対して分析が実行される GCP とのハイブリッド デプロイを維持しています。
データは GCP で実行されているデータ転送サーバーへの並列アップロードを通じて、データ センターから Cloud Storage にインポートされます。管理者は毎日の転送に時間がかかりすぎると通知し、問題を解決するように依頼しました.転送速度を最大化したい。
どのアクションを実行するべきでしょうか?
- A. サーバーの CPU サイズを増やします。
- B. サーバー上の Google Persistent Disk のサイズを増やします。
- C. データセンターから GCP へのネットワーク帯域幅を増やす。
- D. Compute Engine から Cloud Storage へのネットワーク帯域幅を増やす。
Answer: C
Question 80
MJTelco のケーススタディをご確認ください。
MJTelco は、データを共有するためのカスタムインターフェースを構築しています。次の要件があります。
1. ペタバイト規模のデータセットを集計する必要がある。
2. 非常に速い応答時間 (ミリ秒) で特定の時間範囲の行をスキャンする必要がある。
推奨する Google Cloud Platform プロダクトの組み合わせはどれですか。
- A. Datastore と Cloud Bigtable
- B. Cloud Bigtable と Cloud SQL
- C. BigQuery と Cloud Bigtable
- D. BigQuery と Cloud Storage
Answer: C
Question 81
MJTelco のケーススタディをご確認ください。
次の要件を備えた運用チーム向けの視覚化を構成する必要があります。
・テレメトリには、直近 6 週間の全 50,000 件のインストールからのデータが含まれている必要があります (1 分ごとにサンプリング)
・レポートはライブ データから 3 時間以上遅れてはなりません。
・実用的なレポートには、次善のリンクのみを表示する必要があります。
・最適ではないリンクのほとんどは、一番上にソートする必要があります。
最適ではないリンクは、地域ごとにグループ化およびフィルタリングできます。
・レポートをロードするユーザーの応答時間は 5 秒未満である必要があります。
過去 6 週間のデータを保存するためのデータ ソースを作成し、視聴者が複数の日付範囲、異なる地理的地域、および固有のインストール タイプを確認できる視覚化を作成します。ビジュアライゼーションを変更することなく、常に最新のデータを表示します。毎月新しいビジュアライゼーションを作成および更新することは避けたいと考えています。
何をするべきでしょうか?
- A. 現在のデータに目を通し、考えられる条件の組み合わせごとに 1 つずつ、一連のグラフと表を作成します。
- B. 現在のデータに目を通し、値の選択を可能にする条件フィルターにバインドされた一般化されたチャートとテーブルの小さなセットを作成します。
- C. データをスプレッドシートにエクスポートし、考えられる条件の組み合わせごとに 1 つずつ、一連のグラフと表を作成し、それらを複数のタブに広げます。
- D. データをリレーショナル データベース テーブルに読み込み、すべての行をクエリする Google App Engine アプリケーションを作成し、各条件でデータを要約してから Google Charts と視覚化 API を使用して結果をレンダリングします。
Answer: D
Question 82
MJTelco のケーススタディをご確認ください。
MJTelco は、1 日あたりの取り込みに関心があるレコード ストリームを考えると、BigQuery のコストが増加することを懸念しています。
MJTelco は、設計ソリューションの提供をお願いしています。tracking_table と呼ばれる単一の大きなデータ テーブルが必要です。さらに、毎日のイベントをきめ細かく分析しながら、毎日のクエリのコストを最小限に抑えたいと考えています。また、ストリーミング インジェストも使用したいと考えています。
何をするべきでしょうか?
- A. tracking_table という名前のテーブルを作成し、DATE 列を含めます。
- B. tracking_table という分割テーブルを作成し、TIMESTAMP 列を含めます。
- C. パターン tracking_table_YYYYMMDD に従って、日ごとにシャード テーブルを作成します。
- D. 日を表す TIMESTAMP カラムを含む tracking_table というテーブルを作成します。
Answer: B
Question 83
Flowlogistic のケーススタディをご確認ください。
Flowlogistic の経営陣は、現在の Apache Kafka サーバーではリアルタイムの在庫追跡システムのデータ量を処理できないと判断しました。
独自の追跡ソフトウェアにフィードする新しいシステムを Google Cloud Platform (GCP) 上に構築する必要があります。システムはさまざまなグローバル ソースからデータを取り込み、リアルタイムで処理およびクエリを実行し、データを確実に保存できる必要があります。
GCP プロダクトのどの組み合わせを選択するべきでしょうか?
- A. Pub/Sub、Dataflow、Cloud Storage
- B. Pub/Sub、Dataflow、ローカル SSD
- C. Pub/Sub、Cloud SQL、Cloud Storage
- D. Cloud Load Balancing、Dataflow、Cloud Storage
- E. Dataflow、Cloud SQL、Cloud Storage
Answer: A
Question 84
ETL ジョブを移行して BigQuery で実行した後、移行したジョブの出力が元のジョブの出力と同じであることを確認する必要があります。
元のジョブの出力を含むテーブルを読み込んでおり、その内容を移行されたジョブの出力と比較して、それらが同一であることを示したいと考えています。テーブルには、比較のために結合できる主キー列が含まれていません。
何をするべきでしょうか?
- A. RAND() 関数を使用してテーブルから無作為にサンプルを選択し、サンプルを比較します。
- B. HASH() 関数を使用してテーブルからランダムにサンプルを選択し、サンプルを比較します。
- C. Dataproc クラスタと BigQuery Hadoop コネクタを使用して各テーブルからデータを読み取り、並べ替え後にテーブルのタイムスタンプ以外の列からハッシュを計算する。各テーブルのハッシュを比較します。
- D. OVER() 関数を使用して層別ランダム サンプルを作成し、各テーブルの同等のサンプルを比較します。
Answer: C
Question 85
あなたは、それぞれが異なる優先順位と予算を持つ複数のビジネス ユニットを持つ大企業の BI 責任者です。
プロジェクトごとに 2,000 の同時オンデマンド スロットのクォータで、BigQuery のオンデマンド料金を使用します。組織のユーザーがクエリを実行するためのスロットを取得できない場合があり、これを修正する必要があります。アカウントに新しいプロジェクトを導入することは避けたいと考えています。
何をするべきでしょうか?
- A. バッチ BQ クエリをインタラクティブな BQ クエリに変換します。
- B. 追加のプロジェクトを作成して、プロジェクトごとの 2K オンデマンド クォータを克服します。
- C. 定額料金に切り替えて、プロジェクトの階層的な優先モデルを確立する。
- D. Cloud Console の割り当てページで、プロジェクトごとの同時スロット数を増やします。
Answer: C
Question 86
Web アプリケーション ログを含むトピックを含むオンプレミスの Apache Kafka クラスタがあります。
BigQuery と Cloud Storage で分析するには、データを Google Cloud に複製する必要があります。Kafka Connect プラグインのデプロイを回避するために推奨される複製方法はミラーリングです。
何をするべきでしょうか?
- A. GCE VM インスタンスに Kafka クラスタをデプロイします。GCE で実行されているクラスタにトピックをミラーリングするようにオンプレミス クラスタを構成します。Dataproc クラスタまたは Dataflow ジョブを使用して、Kafka から読み取り、Cloud Storage に書き込みます。
- B. シンク コネクタとして構成された Pub/Sub Kafka コネクタを使用して GCE VM インスタンスに Kafka クラスタをデプロイします。Dataproc クラスタまたは Dataflow ジョブを使用して、Kafka から読み取り、Cloud Storage に書き込みます。
- C. Pub/Sub Kafka コネクタをオンプレミスの Kafka クラスタにデプロイし、Pub/Sub をソース コネクタとして構成します。Dataflow ジョブを使用して Pub/Sub から読み取り、Cloud Storage に書き込みます。
- D. Pub/Sub Kafka コネクタをオンプレミスの Kafka クラスタにデプロイし、Pub/Sub をシンク コネクタとして構成します。Dataflow ジョブを使用して、Pub/Sub から読み取り、Cloud Storage に書き込みます。
Answer: A
Question 87
Hadoop ジョブをオンプレミス クラスタから Dataproc と Cloud Storage に移行しました。
Spark ジョブは、多くのシャッフル操作で構成される複雑な分析ワークロードであり、初期データは寄木細工のファイル (それぞれ平均 200 ~ 400 MB のサイズ) です。Dataproc への移行後にパフォーマンスの低下が見られるため、最適化したいと考えています。あなたの組織はコストに非常に敏感であるため、このワークロードには引き続き Dataproc をプリエンプティブルで使用したいと考えています。(2 つの非プリエンプティブル ワーカーのみ)
何をするべきでしょうか?
- A. parquet ファイルのサイズを増やして、少なくとも 1 GB になるようにします。
- B.寄木細工のファイルの代わりに TFRecords 形式 (ファイルあたり約 200 MB) に切り替えます。
- C. HDD から SSD に切り替え、初期データを Cloud Storage から HDFS にコピーし、Spark ジョブを実行して、結果を Cloud Storage にコピーして戻します。
- D. HDD から SSD に切り替え、プリエンプティブル VM 構成をオーバーライドしてブートディスクのサイズを増やします。
Answer: D
Question 88
あなたのチームは、社内で ETL を開発および維持する責任があります。
入力データのエラーが原因で Dataflow ジョブの 1 つが失敗しており、パイプラインの信頼性を向上させる必要があります。(失敗したすべてのデータを再処理できるようにするなど)
何をするべきでしょうか?
- A. 今後、これらのタイプのエラーをスキップするフィルタリング手順を追加し、ログからエラーのある行を抽出します。
- B. データを変換する DoFn に try catch ブロックを追加し、ログからエラーのある行を抽出します。
- C. データを変換する DoFn に try catch ブロックを追加し、誤った行を DoFn から直接 Pub/Sub PubSub に書き込みます。
- D. データを変換する DoFn に try catch ブロックを追加し、sideOutput を使用して、後で Pub/Sub に保存できる PCollection を作成します。
Answer: C
Question 89
不動産を含む利用可能なデータセットに基づいて住宅価格を予測するモデルをトレーニングしています。
あなたの計画は、完全に接続されたニューラル ネットワークをトレーニングすることであり、データセットにプロパティの緯度と経度が含まれていることを発見しました。不動産の専門家は、不動産の場所が価格に大きな影響を与えるとあなたに言ったので、この物理的な依存関係を組み込む機能を設計したいと考えています。
何をするべきでしょうか?
- A. 入力ベクトルとして緯度と経度をニューラル ネットワークに提供します。
- B. 緯度と経度のフィーチャ クロスから数値列を作成します。
- C. 緯度と経度のフィーチャ クロスを作成し、それを分レベルでバケット化し、最適化中に L1 正則化を使用します。
- D. 緯度と経度のフィーチャ クロスを作成し、それを分レベルでバケット化し、最適化中に L2 正則化を使用します。
Answer: C
Reference:
地理空間データの操作 | BigQuery | Google Cloud
Question 90
GCE VM インスタンスに MariaDB SQL データベースをデプロイしており、モニタリングとアラートを構成する必要があります。
最小限の開発作業で MariaDB からネットワーク接続、ディスク IO、レプリケーション ステータスなどの指標を収集し、ダッシュボードとアラートに StackDriver を使用したいと考えています。
何をするべきでしょうか?
- A. OpenCensus Agent をインストールし、StackDriver エクスポーターを使用してカスタム指標収集アプリケーションを作成します。
- B. MariaDB インスタンスをヘルスチェックのあるインスタンス グループに配置します。
- C. StackDriver Logging Agent をインストールし、fluentd in_tail プラグインを構成して MariaDB ログを読み取ります。
- D. StackDriver Agent をインストールし、MySQL プラグインを構成します。
Answer: D
Question 91
あなたは銀行で働いています。
既に許可されたローン申請に関する情報と、これらの申請が債務不履行になっているかどうかに関する情報を含む、ラベル付きのデータセットがあります。モデルをトレーニングして、クレジット申請者のデフォルト率を予測するように依頼されました。
何をするべきでしょうか?
- A. 追加のデータを収集して、データセットのサイズを増やします。
- B. 線形回帰をトレーニングして、クレジット デフォルト リスク スコアを予測します。
- C. データから偏りを取り除き、融資を拒否された申請書を収集します。
- D. 融資申請者とそのソーシャル プロファイルを照合して、機能エンジニアリングを有効にする。
Answer: B
Question 92
2 TB のリレーショナル データベースを Google Cloud Platform に移行する必要があります。
このデータベースを使用するアプリケーションを大幅にリファクタリングするためのリソースがなく、運用コストが主な懸念事項です。
データの保存と提供にどのサービスを選択しますか?
- A. Cloud Spanner
- B. Cloud Bigtable
- C. Cloud Firestore
- D. Cloud SQL
Answer: D
Question 93
リアルタイム アプリケーションに Cloud Bigtable を使用していて、読み取りと書き込みが混在する重い負荷があります。
あなたは最近、追加のユース ケースを特定し、データベース全体にわたって特定の統計を計算するために、1 時間ごとの分析ジョブを実行する必要があります。本番アプリケーションの信頼性と分析ワークロードの両方を確保する必要があります。
何をするべきでしょうか?
- A. Cloud Bigtable ダンプを Cloud Storage にエクスポートし、エクスポートしたファイルに対して分析ジョブを実行します。
- B. マルチ クラスタ ルーティングを使用して既存のインスタンスに 2 つ目のクラスタを追加し、通常のワークロードにはライブ トラフィック アプリ プロファイルを使用し、分析ワークロードにはバッチ分析プロファイルを使用します。
- C. 単一クラスタ ルーティングを使用して既存のインスタンスに 2 つ目のクラスタを追加し、通常のワークロードにはライブ トラフィック アプリ プロファイルを使用し、分析ワークロードにはバッチ分析プロファイルを使用します。
- D. 既存のクラスタのサイズを 2 倍に増やし、サイズを変更した新しいクラスタで分析ワークロードを実行します。
Answer: C
Question 94
Pub/Sub のデータを BigQuery の静的参照データで強化する Apache Beam パイプラインを設計しています。
参照データは 1 つのワーカーのメモリに収まるほど小さいです。パイプラインは、分析のために強化された結果を BigQuery に書き込む必要があります。
このパイプラインで使用するジョブの種類と変換はどれですか?
- A. バッチジョブ、PubSubIO、副入力
- B. ストリーミング ジョブ、PubSubIO、JdbcIO、副出力
- C. ストリーミング ジョブ、PubSubIO、BigQueryIO、副入力
- D. ストリーミング ジョブ、PubSubIO、BigQueryIO、副出力
Answer: C
Question 95
適切に設計された行キーを使用して Cloud Bigtable にデータを書き込むデータ パイプラインがあります。
パイプラインをモニタリングして、Cloud Bigtable クラスタのサイズをいつ増やすかを判断したいと考えています。
これを達成するために実行できるアクションを選択してください。 (回答を 2つ選択してください)
- A. Key Visualizer メトリクスを確認します。Read pressure index が 100 を超える場合は Cloud Bigtable クラスタのサイズを増やします。
- B. Key Visualizer メトリクスを確認します。Write pressure index が 100 を超える場合は Cloud Bigtable クラスタのサイズを増やします。
- C. 書き込み操作の待ち時間を監視します。書き込みレイテンシが持続的に増加する場合は、Cloud Bigtable クラスタのサイズを増やします。
- D. ストレージの使用率を監視します。使用率が最大容量の 70% を超えたら Cloud Bigtable クラスタのサイズを増やします。
- E. 読み取り操作の待ち時間を監視します。読み取りオペレーションの Cloud Bigtable クラスタのサイズを大きくすると 100 ミリ秒以上かかります。
Answer: C、D
Question 96
毎日何十万件ものソーシャル メディアの投稿を、最小のコストと最小の手順で分析したいと考えています。
次の要件があります。
・投稿を1日1回バッチロードし、Cloud Natural Language APIで実行します。
・投稿から話題や感想を抽出します。
・アーカイブと再処理のために未加工の投稿を保存する必要があります。
・ダッシュボードを作成し、社内外で共有していただきます。
分析を実行するために API から抽出されたデータと、履歴をアーカイブするための生のソーシャル メディア投稿の両方を保存する必要があります。
何をするべきでしょうか?
- A. ソーシャル メディアの投稿と API から抽出されたデータを BigQuery に保存します。
- B. ソーシャル メディアの投稿と API から抽出されたデータを Cloud SQL に保存します。
- C. 生のソーシャル メディア投稿を Cloud Storage に保存し、API から抽出したデータを BigQuery に書き込みます。
- D. ソーシャル メディアの投稿をソースから直接 API にフィードし、抽出したデータを API から BigQuery に書き込みます。
Answer: C
Question 97
履歴データを Cloud Storage に保存します。
履歴データに対して分析を実行する必要があります。ソリューションを使用して、無効なデータ エントリを検出し、プログラミングや SQL の知識を必要としないデータ変換を実行したいと考えています。
何をするべきでしょうか?
- A. Dataflow と Beam を使用してエラーを検出し、変換を実行します。
- B. レシピで Cloud Dataprep を使用してエラーを検出し、変換を実行します。
- C. Hadoop ジョブで Dataproc を使用してエラーを検出し、変換を実行します。
- D. エラーを検出して変換を実行するクエリで BigQuery の連合テーブルを使用します。
Answer: B
Question 98
あなたの会社は、履歴データを Cloud Storage にアップロードする必要があります。
セキュリティ ルールは、外部 IP からオンプレミス リソースへのアクセスを許可しません。最初のアップロードの後、既存のオンプレミス アプリケーションから新しいデータを毎日追加します。
彼らは何をすべきですか?
- A. オンプレミス サーバーから gsutil rsync を実行します。
- B. Dataflow を使用してデータを Cloud Storage に書き込みます。
- C. Dataproc にジョブ テンプレートを記述して、データ転送を実行します。
- D. Compute Engine VM に FTP サーバーをインストールしてファイルを受信し、Cloud Storage に移動します。
Answer: A
Question 99
タイムスタンプ列と ID 列で WHERE 句を使用して BigQuery テーブルをフィルタリングするクエリがあります。
bq query `”-dry_run を使用すると、タイムスタンプと ID のフィルタがデータ全体のごく一部を選択する場合でも、クエリがテーブルのフル スキャンをトリガーすることがわかります。既存の SQL クエリへの最小限の変更をします。
何をするべきでしょうか?
- A. ID ごとに個別のテーブルを作成します。
- B. LIMIT キーワードを使用して返される行数を減らします。
- C. パーティショニング列とクラスタリング列を使用してテーブルを再作成します。
- D. bq query –maximum_bytes_billed フラグを使用して請求されるバイト数を制限します。
Answer: C
Question 100
50,000 個のセンサーからの分単位の解像度のデータを BigQuery テーブルに挿入する必要があります。
データ ボリュームの大幅な増加が予想され、集約された傾向をリアルタイムで分析するために、取り込みから 1 分以内にデータを利用できるようにする必要があります。
何をするべきでしょうか?
- A. bq load を使用してセンサー データのバッチを 60 秒ごとに読み込みます。
- B. Dataflow パイプラインを使用してデータを BigQuery テーブルにストリーミングします。
- C. INSERT ステートメントを使用して 60 秒ごとにデータのバッチを挿入します。
- D. MERGE ステートメントを使用して 60 秒ごとにバッチで更新を適用します。
Answer: B
Question 101
何百万もの患者の機密記録をリレーショナル データベースから BigQuery にコピーする必要があります。
データベースの合計サイズは 10 TB です。安全で時間効率の良いソリューションを設計する必要があります。
何をするべきでしょうか?
- A. データベースからレコードを Avro ファイルとしてエクスポートします。gsutil を使用してファイルを Cloud Storage にアップロードし、GCP Console の BigQuery ウェブ UI を使用して Avro ファイルを BigQuery に読み込みます。
- B. データベースからレコードを Avro ファイルとしてエクスポートします。ファイルを Transfer Appliance にコピーして Google に送信し、GCP Console の BigQuery ウェブ UI を使用して Avro ファイルを BigQuery に読み込みます。
- C. データベースからレコードを CSV ファイルにエクスポートします。CSV ファイルのパブリック URL を作成し、Storage Transfer Service を使用してファイルを Cloud Storage に移動します。GCP Console の BigQuery ウェブ UI を使用して CSV ファイルを BigQuery に読み込みます。
- D. データベースからレコードを Avro ファイルとしてエクスポートします。Avro ファイルのパブリック URL を作成し、Storage Transfer Service を使用してファイルを Cloud Storage に移動します。GCP Console の BigQuery ウェブ UI を使用して Avro ファイルを BigQuery に読み込みます。
Answer: B
Question 102
BigQuery データ ウェアハウスのメイン インベントリ テーブルを読み取るほぼリアルタイムのインベントリ ダッシュボードを作成する必要があります。
過去の在庫データは、品目別および場所別の在庫残高として保存されます。1 時間ごとにインベントリに数千の更新があります。ダッシュボードのパフォーマンスを最大化し、データが正確であることを確認したいと考えています。
何をするべきでしょうか?
- A. BigQuery の UPDATE ステートメントを利用して在庫残高の変化に合わせて更新します。
- B. 各在庫更新でスキャンされるデータの量を減らすために在庫残高テーブルをアイテムごとに分割します。
- C. BigQuery ストリーミングを使用してストリームの変化を毎日の在庫移動テーブルにストリーミングします。履歴在庫残高テーブルに結合するビューで残高を計算します。毎晩、在庫バランス テーブルを更新します。
- D. BigQuery バルクローダーを使用して在庫の変更を日次在庫移動テーブルに一括読み込みします。履歴在庫残高テーブルに結合するビューで残高を計算します。毎晩、在庫バランス テーブルを更新します。
Answer: A
Question 103
BigQuery にデータが保存されています。
BigQuery データセット内のデータは高可用性である必要があります。コストを最小限に抑える、このデータのストレージ、バックアップ、およびリカバリ戦略を定義する必要があります。
目標復旧時点 (RPO) が 30 日の BigQuery テーブルをどのように構成するべきでしょうか?
- A. BigQuery データセットをリージョンに設定します。緊急時には特定時点のスナップショットを使用してデータを回復します。
- B. BigQuery データセットをリージョンに設定します。スケジュールされたクエリを作成して、バックアップの時刻のサフィックスが付いたテーブルにデータのコピーを作成します。緊急時にはテーブルのバックアップ コピーを使用します。
- C. BigQuery データセットをマルチリージョンに設定する。緊急時には特定時点のスナップショットを使用してデータを回復します。
- D. BigQuery データセットをマルチリージョンに設定する。スケジュールされたクエリを作成して、バックアップの時刻のサフィックスが付いたテーブルにデータのコピーを作成します。緊急時にはテーブルのバックアップ コピーを使用します。
Answer: C
Question 104
Dataprep を使用して BigQuery テーブル内のサンプル データのレシピを作成しました。
可変実行時間の読み込みジョブが完了した後、同じスキーマを使用してデータを毎日アップロードする際に、このレシピを再利用したいと考えています。
何をするべきでしょうか?
- A. Dataprep で cron スケジュールを作成します。
- B. App Engine cron ジョブを作成して、Dataprep ジョブの実行をスケジュールします。
- C. レシピを Dataprep テンプレートとしてエクスポートし、Cloud Scheduler でジョブを作成します。
- D. Dataprep ジョブを Dataflow テンプレートとしてエクスポートし、Composer ジョブに組み込む。
Answer: D
Question 105
Google Cloud で実行されているマルチステップ データ パイプラインの実行を自動化したいと考えています。
パイプラインには相互に複数の依存関係を持つ Dataproc ジョブと Dataflow ジョブが含まれます。可能な場合はマネージド サービスを使用する必要があり、パイプラインは毎日実行されます。
どのツールを使用するべきでしょうか?
- A. cron
- B. Cloud Composer
- C. Cloud Scheduler
- D. Dataproc のワークフロー テンプレート
Answer: B
Question 106
Dataproc クラスタを管理しています。
クラスタで進行中の作業を失うことなく、コストを最小限に抑えながらジョブをより高速に実行する必要があります。
何をするべきでしょうか?
- A. プリエンプティブルでないワーカーを増やしてクラスタ サイズを増やします。
- B. プリエンプティブル ワーカー ノードを使用してクラスタ サイズを増やし、それらを強制的に廃止するように構成します。
- C. プリエンプティブル ワーカー ノードでクラスタ サイズを増やし、Cloud Stackdriver を使用してスクリプトをトリガーして作業を保持する。
- D. プリエンプティブル ワーカー ノードでクラスタ サイズを増やし、グレースフルなデコミッションを使用するように構成します。
Answer: D
Reference:
Dataproc の高度な柔軟性モード | Dataproc ドキュメント | Google Cloud
Question 107
あなたは、ハンドヘルド スキャナーを使用して配送ラベルを読み取る運送会社で働いています。
あなたの会社には、イベントが Kafka トピックに送信されたときにのみ追跡番号を送信することをスキャナーに要求する厳格なデータ プライバシー基準があります。最近のソフトウェア更新により、スキャナーが誤って受信者の個人を特定できる情報 (PII) を分析システムに送信し、ユーザーのプライバシー規則に違反しました。クラウドネイティブのマネージド サービスを使用してスケーラブルなソリューションを迅速に構築し、分析システムへの PII の公開を防ぎたいと考えています。
何をするべきでしょうか?
- A. BigQuery で承認済みビューを作成して機密データを含むテーブルへのアクセスを制限します。
- B. Compute Engine 仮想マシンにサードパーティのデータ検証ツールをインストールして受信データに機密情報がないかどうかを確認します。
- C. Cloud Logging を使用してパイプライン全体を通過したデータを分析し、機密情報が含まれている可能性のあるトランザクションを特定します。
- D. トピックを読み取り、Cloud Data Loss Prevention (Cloud DLP) API を呼び出す Cloud Functions を構築します。タグ付けと信頼レベルを使用してレビューのためにバケット内のデータを渡すか隔離します。
Answer: D
Question 108
3 つのデータ処理ジョブを作成しました。
1 つ目は Cloud Storage にアップロードされたデータを変換し、結果を BigQuery に書き込む Dataflow パイプラインを実行します。2 つ目は、オンプレミス サーバーからデータを取り込み、Cloud Storage にアップロードします。3 つ目は、サードパーティのデータ プロバイダから情報を取得し、その情報を Cloud Storage にアップロードする Dataflow パイプラインです。これら 3 つのワークフローの実行をスケジュールおよび監視し、必要に応じて手動で実行できる必要があります。
何をするべきでしょうか?
- A. Cloud Composer で直接非巡回グラフを作成して、ジョブをスケジュールおよび監視します。
- B. Stackdriver Monitoring を使用し、Webhook 通知でアラートを設定してジョブをトリガーする。
- C. GCP API 呼び出しを使用してジョブのステータスをスケジュールおよびリクエストする App Engine アプリケーションを開発します。
- D. Compute Engine インスタンスで cron ジョブを設定し、GCP API 呼び出しを使用してパイプラインをスケジュールおよび監視します。
Answer: A
Question 109
Pub/Sub からメッセージをプルして BigQuery にデータを送信する Node.js で記述された Cloud Functions があります。
Pub/Sub トピックのメッセージ処理速度が予想よりも桁違いに高いことがわかりますが、Cloud Logging にはエラーが記録されていません。
この問題の最も可能性の高い原因は何でしょうか? (回答を 2つ選択してください)
- A. パブリッシャーのスループット クォータが小さすぎます。
- B. 未処理のメッセージの合計が最大の 10 MB を超えています。
- C. サブスクライバ コードのエラー処理が実行時エラーを適切に処理していません。
- D. 加入者コードがメッセージについていけない。
- E. サブスクライバー コードは pull したメッセージを確認しません。
Answer: C、E
Question 110
Pub/Sub から Dataflow を介して BigQuery に IoT データをストリーミングするために Google Cloud で新しいパイプラインを作成しています。
データのプレビュー中に、データの約 2% が破損しているように見えることに気付きました。この破損データを除外するには Dataflow パイプラインを変更する必要があります。
何をするべきでしょうか?
- A. 要素が破損している場合にブール値を返す SideInput を追加します。
- B. Dataflow に ParDo 変換を追加して破損した要素を破棄します。
- C. Dataflow にパーティション変換を追加して有効なデータを破損したデータから分離します。
- D. Dataflow に GroupByKey 変換を追加して有効なデータをすべてグループ化し、残りを破棄します。
Answer: B
Question 111
過去 3 年間の BigQuery をカバーする履歴データと、毎日新しいデータを BigQuery に配信するデータ パイプラインがあります。
データ サイエンス チームが、日付列でフィルター処理され、30 ~ 90 日間のデータに制限されたクエリを実行すると、クエリがテーブル全体をスキャンすることに気付きました。また、請求額が予想よりも早く増加していることにも気付きました。SQL クエリを実行する機能を維持しながら、可能な限り費用対効果の高い方法で問題を解決したいと考えています。
何をするべきでしょうか?
- A. DDL を使用してテーブルを再作成します。TIMESTAMP または DATE タイプを含む列でテーブルを分割します。
- B. データ サイエンス チームがテーブルを Cloud Storage の CSV ファイルにエクスポートし、Cloud Datalab を使用してファイルを直接読み取ることでデータを探索することを推奨します。
- C. パイプラインを変更して、過去 3090 日間のデータを 1 つのテーブルに保持し、それよりも長い履歴を別のテーブルに保持して、履歴全体のフル テーブル スキャンを最小限に抑えます。
- D. 1 日ごとに BigQuery テーブルを作成する Apache Beam パイプラインを作成する。データ サイエンス チームは、必要なデータを選択するために、テーブル名のサフィックスにワイルドカードを使用することをお勧めします。
Answer: A
Question 112
あなたは物流会社を経営しており、車両ベースのセンサーのイベント配信の信頼性を向上させたいと考えています。
これらのイベントをキャプチャするために世界中の小さなデータ センターを運用していますが、イベント収集インフラストラクチャからイベント処理インフラストラクチャへの接続を提供する専用線は信頼性が低く、予測できない待機時間があります。この問題には、最も費用対効果の高い方法で対処したいと考えています。
何をするべきでしょうか?
- A. データセンターに小さな Kafka クラスタを展開してイベントをバッファリングします。
- B. データ取得デバイスにデータを Pub/Sub に公開します。
- C. すべてのリモート データセンターと Google の間に Cloud Interconnect を確立します。
- D. セッション ウィンドウ内のすべてのデータを集約する Dataflow パイプラインを作成します。
Answer: B
Question 113
あなたは、オンライン販売機能を Google Home などのさまざまな家庭用アシスタントと統合したいと考えている小売業者です。
顧客の音声コマンドを解釈し、バックエンド システムに命令を出す必要があります。
どのソリューションを選択するべきでしょうか?
- A. Speech-to-Text API
- B. Cloud Natural Language API
- C. Dialogflow Enterprise Edition
- D. AutoML Natural Language
Answer: C
Question 114
あなたの会社には、ハイブリッド クラウド イニシアチブがあります。
クラウド プロバイダ サービス間でデータを移動し、各クラウド プロバイダのサービスを活用する複雑なデータ パイプラインがあります。
パイプライン全体を調整するには、どのクラウド ネイティブ サービスを使用するべきでしょうか?
- A. Dataflow
- B. Cloud Composer
- C. Cloud Dataprep
- D. Dataproc
Answer: B
Question 115
分析には BigQuery のデータセットを使用します。
サードパーティ企業に同じデータセットへのアクセスを提供したいと考えています。データ共有のコストを低く抑え、データが最新であることを確認する必要があります。
どのソリューションを選択するべきでしょうか?
- A. Analytics Hub を使用してデータ アクセスを制御し、サードパーティ企業にデータセットへのアクセスを提供します。
- B. Cloud Scheduler を使用して定期的にデータを Cloud Storage にエクスポートし、サードパーティ企業にバケットへのアクセスを提供します。
- C. 共有する関連データを含む別のデータセットを BigQuery で作成し、サードパーティ企業に新しいデータセットへのアクセスを提供します。
- D. データを頻繁に読み取る Dataflow ジョブを作成し、サードパーティ企業が使用できるように関連する BigQuery データセットまたは Cloud Storage バケットに書き込みます。
Answer: A
Question 116
あなたの会社は、オンプレミスのデータ ウェアハウス ソリューションを BigQuery に移行中です。
既存のデータ ウェアハウスは、トリガーベースの変更データ キャプチャ (CDC) を使用して、複数のトランザクション データベース ソースからの更新を毎日適用しています。BigQuery を使用して CDC の処理を改善し、ログベースの CDC ストリームを使用して BigQuery でソース システムへの変更をほぼリアルタイムでクエリできるようにすると同時に、変更をデータ ウェアハウスに適用するパフォーマンスを最適化したいと考えています。.
コンピューティング オーバーヘッドを削減しながら、レイテンシを最小限に抑えて BigQuery レポート テーブルで変更を利用できるようにするには、どの手順を実行するべきでしょうか? (回答を 2つ選択してください)
- A. DML INSERT、UPDATE、または DELETE を実行して、個々の CDC レコードをリアルタイムでレポート テーブルに直接複製します。
- B. 新しい各 CDC レコードと対応する操作タイプをステージング テーブルにリアルタイムで挿入します。
- C. レポート テーブルから定期的に古いレコードを削除します。
- D. DML MERGE を定期的に使用して、レポート テーブルに対して複数の DML INSERT、UPDATE、および DELETE 操作を同時に実行します。
- E. 新しい各 CDC レコードと対応する操作タイプをリアルタイムでレポート テーブルに挿入し、マテリアライズド ビューを使用して、各一意のレコードの最新バージョンのみを公開します。
Answer: B、D
Question 117
あなたはデータ処理パイプラインを設計しています。
パイプラインは、負荷の増加に応じて自動的にスケーリングできる必要があります。メッセージは少なくとも 1 回処理する必要があり、1 時間以内に注文する必要があります。
ソリューションをどのように設計するべきでしょうか?
- A. メッセージの取り込みには Apache Kafka を使用し、ストリーミング分析には Dataproc を使用します。
- B. メッセージの取り込みには Apache Kafka を使用し、ストリーミング分析には Dataflow を使用します。
- C. メッセージの取り込みには Pub/Sub を使用し、ストリーミング分析には Dataproc を使用します。
- D. メッセージの取り込みには Pub/Sub を使用し、ストリーミング分析には Dataflow を使用します。
Answer: D
Question 118
社内のさまざまな部門に対して BigQuery へのアクセスを設定する必要があります。
ソリューションは、次の要件に準拠する必要があります。
・各部門は、自分のデータにのみアクセスできる必要があります。
・各部門には、テーブルを作成および更新し、チームに提供できる必要があるリードが 1 人以上います。
・各部門には、データのクエリはできるがデータの変更はできない必要があるデータ アナリストがいます。
BigQuery のデータへのアクセスをどのように設定するべきでしょうか?
- A. 部門ごとにデータセットを作成します。部署のリーダーに OWNER の役割を割り当て、データ アナリストにデータセットの WRITER の役割を割り当てます。
- B. 各部門のデータセットを作成します。部門のリーダーにライターの役割を割り当て、データ アナリストにデータセットのリーダーの役割を割り当てます。
- C. 部門ごとにテーブルを作成します。部門のリーダーに所有者の役割を割り当て、データ アナリストに、テーブルが含まれるプロジェクトの編集者の役割を割り当てます。
- D. 部門ごとにテーブルを作成します。テーブルが含まれるプロジェクトで、部門のリーダーに編集者の役割を割り当て、データ アナリストに閲覧者の役割を割り当てます。
Answer: B
Question 119
株式取引を格納するデータベースと、調整可能な時間枠で特定の会社の平均株価を取得するアプリケーションを操作します。
データは Cloud Bigtable に保存され、株式取引の日時が行キーの先頭になります。アプリケーションには何千もの同時ユーザーがいて、株式が追加されるにつれてパフォーマンスが低下し始めていることに気付きました。
アプリケーションのパフォーマンスを向上させるために何をすべきですか?
- A. Cloud Bigtable テーブルの行キー構文を変更して銘柄記号で開始します。
- B. Cloud Bigtable テーブルの行キー構文を 1 秒あたりの乱数で始まるように変更します。
- C. 株式取引の保存に BigQuery を使用するようにデータ パイプラインを変更し、アプリケーションを更新します。
- D. Dataflow を使用して毎日の株式取引の概要を Cloud Storage の Avro ファイルに書き込みます。Cloud Storage と Cloud Bigtable から読み取って応答を計算するようにアプリケーションを更新します。
Answer: A
Question 120
Dataflow ストリーミング パイプラインを運用しています。
パイプラインは、ウィンドウ内で Pub/Sub サブスクリプション ソースからイベントを集約し、結果の集約を Cloud Storage バケットにシンクします。ソースには一貫したスループットがあります。Cloud Stackdriver でパイプラインの動作に関するアラートをモニタリングして、データが処理されていることを確認したいと考えています。
どの Stackdriver アラートを作成するべきでしょうか?
- A. ソースのサブスクリプション/num_undelivered_messages の減少と、宛先のインスタンス/ストレージ/ used_bytes の変化率の増加に基づくアラート。
- B. ソースのサブスクリプション/num_undelivered_messages の増加と、宛先のインスタンス/ストレージ/ used_bytes の変化率の減少に基づくアラート。
- C. ソースの instance/storage/used_bytes の減少と、宛先の subscription/num_undelivered_messages の変化率の増加に基づくアラート。
- D. ソースの instance/storage/used_bytes の増加と、宛先の subscription/num_undelivered_messages の変化率の減少に基づくアラート。
Answer: B
Question 121
現在、米国東部リージョンのデータ センターに単一のオンプレミス Kafka クラスタがあり、IoT デバイスからグローバルにメッセージを取り込む役割を担っています。
地球の大部分ではインターネット接続が不十分であるため、メッセージがエッジでバッチ処理され、一度にすべて受信され、Kafka クラスタの負荷が急増することがあります。これは管理が難しくなり、法外な費用がかかります。
このシナリオで Google が推奨するクラウド ネイティブ アーキテクチャはどれですか。
- A. メッセージを保存および送信するためのセンサー デバイスとしての Edge TPU。
- B. 着信メッセージの処理をスケーリングするために Kafka クラスタに接続された Dataflow。
- C. Pub/Sub に接続された IoT ゲートウェイ。Dataflow を使用して Pub/Sub からのメッセージを読み取って処理します。
- D. 米国東部の Compute Engine で仮想化された Kafka クラスタと Cloud Load Balancing を使用して世界中のデバイスに接続する。
Answer: C
Question 122
Datastore を使用して車両のテレメトリー データをリアルタイムで取り込むことにしました。
コストを低く抑えながら、長期的なデータの増加に対応できるストレージ システムを構築したいと考えています。また、データのスナップショットを定期的に作成して、ポイント イン タイム (PIT) リカバリを作成したり、別の環境で Datastore のデータのコピーをクローンしたりできます。これらのスナップショットを長期間アーカイブしたいと考えています。
これを達成できる方法はどれでしょうか? (回答を 2つ選択してください)
- A. マネージド エクスポートを使用し、Nearline または Coldline クラスを使用して Cloud Storage バケットにデータを保存します。
- B. マネージド エクスポートを使用してから、そのエクスポート用に予約された一意の名前空間の下にある別のプロジェクトの Datastore にインポートします。
- C. マネージド エクスポートを使用してから、そのエクスポート専用に作成された BigQuery テーブルにデータをインポートし、一時的にエクスポート ファイルを削除します。
- D. Datastore クライアント ライブラリを使用してすべてのエンティティを読み取るアプリケーションを作成します。BigQuery ストリーミング挿入を介して、各エンティティを BigQuery テーブルの行として扱います。エクスポートごとにエクスポート タイムスタンプを割り当て、それを各行の追加の列として添付します。エクスポート タイムスタンプ列を使用して BigQuery テーブルが分割されていることを確認します。
- E. Datastore クライアント ライブラリを使用してすべてのエンティティを読み取るアプリケーションを作成します。エクスポートされたデータを JSON ファイルにフォーマットします。Cloud Source Repositories にデータを保存する前に圧縮を適用します。
Answer: A、B
Question 123
時系列のトランザクション データをコピーするデータ パイプラインを作成して、データ サイエンス チームが分析のために BigQuery 内からクエリできるようにする必要があります。
1 時間ごとに、何千ものトランザクションが新しいステータスで更新されます。初期データセットのサイズは 1.5 PB で、1 日あたり 3 TB ずつ増加します。データは高度に構造化されており、データ サイエンス チームはこのデータに基づいて機械学習モデルを構築します。データ サイエンス チームのパフォーマンスと使いやすさを最大化する必要があります。
どの 2 つの戦略を採用するべきでしょうか? (回答を 2つ選択してください)
- A. データを可能な限り非正規化します。
- B. データの構造を可能な限り維持します。
- C. BigQuery UPDATE を使用してデータセットのサイズをさらに縮小します。
- D. ステータスの更新が更新ではなく BigQuery に追加されるデータ パイプラインを開発する。
- E. トランザクション データの日次スナップショットを Cloud Storage にコピーし、Avro ファイルとして保存します。外部データ ソースに対する BigQuery のサポートを使用してクエリを実行します。
Answer: A、D
Question 124
あなたは、次の条件を満たすクラウド ネイティブの履歴データ処理システムを設計しています。
・分析されるデータは CSV、Avro、PDF 形式であり、Dataproc、BigQuery、Compute Engine などの複数の分析ツールからアクセスされます。
・日次データはバッチパイプラインで移動。
・パフォーマンスはソリューションの要因ではありません。
・ソリューションの設計は、可用性を最大化する必要があります。
このソリューションのデータ ストレージをどのように設計するべきでしょうか?
- A. 高可用性を備えた Dataproc クラスタを作成します。データを HDFS に保存し、必要に応じて分析を実行します。
- B. データを BigQuery に保存します。Dataproc と Compute Engine で BigQuery コネクタを使用してデータにアクセスします。
- C. データを地域の Cloud Storage バケットに保存します。Dataproc、BigQuery、Compute Engine を使用してバケットに直接アクセスします。
- D. マルチリージョンの Cloud Storage バケットにデータを保存します。Dataproc、BigQuery、Compute Engine を使用してデータに直接アクセスします。
Answer: D
Question 125
ペタバイトの分析データがあり、そのストレージと処理プラットフォームを設計する必要があります。
Google Cloud のデータに対してデータ ウェアハウス スタイルの分析を実行し、データセットを他のクラウド プロバイダのバッチ分析ツール用のファイルとして公開できる必要があります。
何をするべきでしょうか?
- A. データセット全体を BigQuery に保存して処理します。
- B. データセット全体を Cloud Bigtable に保存して処理します。
- C. データセット全体を BigQuery に保存し、データの圧縮コピーを Cloud Storage バケットに保存します。
- D. ウォーム データをファイルとして Cloud Storage に保存し、アクティブ データを BigQuery に保存します。この比率を 80% ウォーム、20% アクティブに保ちます。
Answer: C
Question 126
あなたは、それぞれ異なるサプライヤーから最大 750 の異なるコンポーネントを調達する製造会社で働いています。
固有のコンポーネントごとに平均 1000 の例があるラベル付きデータセットを収集しました。あなたのチームは、部品の写真に基づいて倉庫の作業員が入荷部品を認識できるようにするアプリを実装したいと考えています。このアプリの最初の動作バージョンを (概念実証として) 数営業日以内に実装したいと考えています。
何をするべきでしょうか?
- A. Cloud Vision AutoML を既存のデータセットで使用します。
- B. Cloud Vision AutoML を使用しますがデータセットを 2 回削減します。
- C. 認識のヒントとしてカスタム ラベルを提供して Cloud Vision API を使用します。
- D. 転送学習を活用して独自の画像認識モデルをトレーニングします。
Answer: A
Question 127
あなたは画像認識分野のニッチな製品に取り組んでいます。
あなたのチームは、チームが実装したカスタム C++ TensorFlow ops によって支配されるモデルを開発しました。これらの演算は、メインのトレーニング ループ内で使用され、かさばる行列の乗算を実行しています。現在、モデルのトレーニングには最大で数日かかります。Google Cloud のアクセラレータを使用して、この時間を大幅に短縮し、コストを低く抑えたいと考えています。
何をするべきでしょうか?
- A. コードを追加調整せずに Cloud TPU を使用します。
- B. カスタム オペレーションに GPU カーネル サポートを実装した後、Cloud TPU を使用します。
- C. カスタム オペレーションに GPU カーネル サポートを実装した後、Cloud GPU を使用します。
- D. CPU にとどまり、モデルをトレーニングしているクラスタのサイズを増やします。
Answer: D
Question 128
自然言語処理ドメインで回帰問題に取り組んでおり、データセットに 1 億個のラベル付きの例があります。
データをランダムにシャッフルし、データセットをトレーニング サンプルとテスト サンプルに (90/10 の比率で) 分割しました。ニューラル ネットワークをトレーニングし、テスト セットでモデルを評価した後、モデルの二乗平均平方根誤差 (RMSE) が、トレーニング セットではテスト セットの 2 倍であることがわかりました。
モデルのパフォーマンスをどのように改善するべきでしょうか?
- A. トレーニングとテストの分割でテスト サンプルのシェアを増やします。
- B. より多くのデータを収集し、データセットのサイズを大きくしてください。
- C. オーバーフィッティングを避けるために、正則化手法 (バッチ正規化のドロップアウトなど) を試してください。
- D. たとえば、追加のレイヤーを導入したり、使用する語彙や n-gram のサイズを大きくしたりして、モデルの複雑さを増やします。
Answer: D
Question 129
一元化された分析プラットフォームとして BigQuery を使用します。
毎日新しいデータがロードされ、ETL パイプラインが元のデータを変更して最終ユーザー向けに準備します。この ETL パイプラインは定期的に変更され、エラーが発生する可能性がありますが、エラーが検出されるのは 2 週間後です。これらのエラーから回復する方法を提供する必要があり、バックアップはストレージ コストに合わせて最適化する必要があります。
BigQuery でデータをどのように整理し、バックアップを保存するべきでしょうか?
- A. データを 1 つのテーブルに整理し、BigQuery データをエクスポートして圧縮し、Cloud Storage に保存します。
- B. データを月ごとに別々のテーブルに整理し、データをエクスポート、圧縮して、Cloud Storage に保存します。
- C. 月ごとに個別のテーブルにデータを整理し、BigQuery の個別のデータセットにデータを複製する。
- D. 月ごとに別々のテーブルにデータを整理し、スナップショット デコレータを使用してテーブルを破損前の時点に復元します。
Answer: B
Question 130
組織のマーケティング チームは、顧客データセットのセグメントの定期的な更新を提供します。
マーケティング チームから、BigQuery で更新する必要がある 100 万件のレコードを含む CSV が提供されました。BigQuery で UPDATE ステートメントを使用すると、quotaExceeded エラーが発生します。
何をするべきでしょうか?
- A. BigQuery UPDATE DML ステートメントの制限内に収まるように毎日更新されるレコードの数を減らします。
- B. Google Cloud Platform Console の割り当て管理セクションで BigQuery UPDATE DML ステートメントの制限を増やします。
- C. Cloud Storage でソース CSV ファイルを小さな CSV ファイルに分割して BigQuery ジョブごとの BigQuery UPDATE DML ステートメントの数を減らす。
- D. CSV ファイルから新しいレコードを新しい BigQuery テーブルにインポートします。新しいレコードを既存のレコードとマージし、結果を新しい BigQuery テーブルに書き込む BigQuery ジョブを作成します。
Answer: D
Question 131
組織が GCP の使用を拡大するにつれて、多くのチームが独自のプロジェクトを作成し始めています。
プロジェクトは、展開のさまざまな段階と対象ユーザーに対応するためにさらに拡張されます。各プロジェクトには、固有のアクセス制御構成が必要です。中央の IT チームは、すべてのプロジェクトにアクセスできる必要があります。さらに、Cloud Storage バケットと BigQuery データセットからのデータは、アドホックな方法で他のプロジェクトで使用するために共有する必要があります。ポリシーの数を最小限に抑えて、アクセス制御の管理を簡素化したい。
どの手順を実行するべきでしょうか? (回答を 2つ選択してください)
- A. Cloud Deployment Manager を使用して、アクセス プロビジョニングを自動化します。
- B. リソース階層を導入して、アクセス制御ポリシーの継承を活用します。
- C. さまざまなチームに個別のグループを作成し、Cloud IAM ポリシーでグループを指定します。
- D. Cloud Storage バケットと BigQuery データセットのデータを共有する場合にのみサービス アカウントを使用します。
- E. Cloud Storage バケットまたは BigQuery データセットごとに、アクセスが必要なプロジェクトを決定します。これらのプロジェクトへのアクセス権を持つすべてのアクティブなメンバーを見つけ、これらすべてのユーザーにアクセス権を付与する Cloud IAM ポリシーを作成します。
Answer: B、C
Question 132
米国に拠点を置くあなたの会社は、ユーザーのアクションを評価して応答するためのアプリケーションを作成しました。
プライマリ テーブルのデータ ボリュームは 1 秒あたり 250,000 レコードずつ増加します。多くのサード パーティは、アプリケーションの API を使用して、独自のフロントエンド アプリケーションに機能を組み込みます。アプリケーションの API は、次の要件に準拠する必要があります。
・シングルグローバルエンドポイント
・ANSI SQL対応
・最新データへの一貫したアクセス
何をするべきでしょうか?
- A. ストレージまたは処理用にリージョンを選択せずに BigQuery を実装します。
- B. 北米のリーダーとアジアとヨーロッパの読み取り専用レプリカで Cloud Spanner を実装します。
- C. 北米のマスターとアジアとヨーロッパのリードレプリカを使用して Cloud SQL for PostgreSQL を実装します。
- D. 北米のプライマリ クラスタとアジアとヨーロッパのセカンダリ クラスタで Cloud Bigtable を実装します。
Answer: B
Question 133
データ サイエンティストが BigQuery ML モデルを作成し、予測を提供する ML パイプラインを作成するように依頼しました。
100 ミリ秒未満の待機時間で個々のユーザー ID の予測を提供する必要がある REST API アプリケーションがあります。次のクエリを使用して予測を生成します: SELECT predicted_label, user_id FROM ML.PREDICT (MODEL ‘dataset.model’, table user_features)。
ML パイプラインをどのように作成するべきでしょうか?
- A. クエリに WHERE 句を追加し、BigQuery データ閲覧者の役割をアプリケーション サービス アカウントに付与します。
- B. 提供されたクエリを使用して承認済みビューを作成します。ビューを含むデータセットをアプリケーション サービス アカウントと共有します。
- C. BigQueryIO を使用して Dataflow パイプラインを作成し、クエリから結果を読み取ります。Dataflow Worker ロールをアプリケーション サービス アカウントに付与します。
- D. BigQueryIO を使用して Dataflow パイプラインを作成し、クエリからすべてのユーザーの予測を読み取ります。Cloud BigtableIO を使用して結果を Cloud Bigtable に書き込みます。アプリケーションが個々のユーザーの予測を Cloud Bigtable から読み取ることができるように、アプリケーション サービス アカウントに Cloud Bigtable の Reader 役割を付与します。
Answer: D
Question 134
あなたは、データ フィードを受け取る消費者と金融市場データを共有するアプリケーションを構築しています。
データは市場からリアルタイムで収集されます。コンシューマーは次の方法でデータを受け取ります。
・リアルタイムイベント配信
・リアルタイムストリームと履歴データへの ANSI SQLアクセス
・バッチヒストリエクスポート
どのソリューションを使用するべきでしょうか?
- A. Dataflow、Cloud SQL、Cloud Spanner
- B. Pub/Sub、Cloud Storage、BigQuery
- C. Dataproc、Dataflow、BigQuery
- D. Pub/Sub、Dataproc、Cloud SQL
Answer: B
Question 135
スケーラブルな方法でデータを収集する必要がある新しいアプリケーションを構築しています。
データは 1 日を通してアプリケーションから継続的に到着し、年末までに 1 日あたり約 150 GB の JSON データが生成されると予想されます。要件は次のとおりです。
・生産者と消費者のデカップリング
・無期限に保存される、取り込まれた生データのスペース効率とコスト効率の高いストレージ
・ほぼリアルタイムのSQLクエリ
・SQLでクエリされる、少なくとも2年間の履歴データを維持する
これらの要件を満たすには、どのパイプラインを使用するべきでしょうか?
- A. API を提供するアプリケーションを作成します。API をポーリングし、データを gzip 圧縮された JSON ファイルとして Cloud Storage に書き込むツールを作成します。
- B. Cloud SQL データベースに書き込みを行ってデータを保存するアプリケーションを作成します。データベースの定期的なエクスポートを設定して Cloud Storage に書き込み、BigQuery に読み込みます。
- C. Pub/Sub にイベントを発行するアプリケーションを作成し、Dataproc で Spark ジョブを作成して JSON データを Avro 形式に変換し、永続ディスクの HDFS に保存します。
- D. イベントを Pub/Sub に発行するアプリケーションを作成し、JSON イベント ペイロードを Avro に変換して Cloud Storage と BigQuery にデータを書き込む Dataflow パイプラインを作成します。
Answer: D
Question 136
Pub/Sub トピックからメッセージを受信し、結果を EU の BigQuery データセットに書き込むパイプラインを Dataflow で実行しています。
現在、パイプラインは europe-west4 にあり、最大 3 つのワーカー、インスタンス タイプ n1-standard-1 があります。ピーク時に、3 つのワーカーすべてが最大の CPU 使用率に達しているときに、パイプラインがタイムリーにレコードを処理するのに苦労していることに気付きました。
パイプラインのパフォーマンスを向上させるために実行できるアクションはどれでしょうか? (回答を 2つ選択してください)
- A. 最大ワーカー数を増やします。
- B. Dataflow ワーカーにより大きなインスタンス タイプを使用します。
- C. Dataflow パイプラインのゾーンを us-central1 で実行するように変更します。
- D. 新しいデータのバッファとして機能する一時テーブルを Cloud Bigtable に作成します。最初にこのテーブルに書き込む新しいステップをパイプラインに作成してから Cloud Bigtable から BigQuery に書き込む新しいパイプラインを作成します。
- E. Cloud Spanner で、新しいデータのバッファとして機能する一時テーブルを作成します。最初にこのテーブルに書き込むための新しいステップをパイプラインに作成してから Cloud Spanner から BigQuery に書き込むための新しいパイプラインを作成します。
Answer: A、B
Question 137
時系列指標を集計して Cloud Bigtable に書き込む Dataflow ジョブを含むデータ パイプラインがあります。
Cloud Bigtable でのデータの更新が遅いことに気付きました。このデータは、組織全体の何千人ものユーザーが使用するダッシュボードにフィードされます。追加の同時ユーザーをサポートし、データの書き込みに必要な時間を短縮する必要があります。
どのアクションを実行するべきでしょうか? (回答を 2つ選択してください)
- A. ローカル実行を使用するように Dataflow パイプラインを構成します。
- B. PipelineOptions で maxNumWorkers を設定して Dataflow ワーカーの最大数を増やします。
- C. Cloud Bigtable クラスタ内のノード数を増やします。
- D. Cloud Bigtable に書き込む前に、Flatten 変換を使用するように Dataflow パイプラインを変更します。
- E. Cloud Bigtable に書き込む前に CoGroupByKey 変換を使用するように Dataflow パイプラインを変更します。
Answer: B、C
Reference:
パフォーマンスについて | Cloud Bigtable ドキュメント | Google Cloud
Question 138
スケジュールに従って Dataproc クラスタで実行される Spark ジョブがいくつかあります。順番に実行されるジョブもあれば、同時に実行されるジョブもあります。
このプロセスを自動化する必要があります。
何をするべきでしょうか?
- A. Dataproc ワークフロー テンプレートを作成します。
- B. ジョブを実行するための初期化アクションを作成します。
- C. Cloud Composer で有向非巡回グラフを作成します。
- D. Cloud SDK を使用してクラスタを作成し、ジョブを実行してからクラスタを破棄する Bash スクリプトを作成します。
Answer: C
Reference:
ワークフローの使用 | Dataproc ドキュメント | Google Cloud
Question 139
2 つの異なるタイプのアプリケーション (ジョブ ジェネレーターとジョブ ランナー) 間でデータを共有するための新しいデータ パイプラインを構築しています。
ソリューションは、使用量の増加に対応できるように拡張する必要があり、既存のアプリケーションのパフォーマンスに悪影響を与えることなく、新しいアプリケーションの追加に対応する必要があります。
何をするべきでしょうか?
- A. App Engine を使用して API を作成し、アプリケーションとの間でメッセージを送受信します。
- B. Pub/Sub トピックを使用してジョブを公開し、サブスクリプションを使用してジョブを実行します。
- C. Cloud SQL でテーブルを作成し、ジョブ情報を含む行を挿入および削除します。
- D. Cloud Spanner でテーブルを作成し、ジョブ情報を含む行を挿入および削除します。
Answer: B
Reference:
Mail API を使用したメールの送受信 | App Engine スタンダード環境での Go 1.11 に関するドキュメント | Google Cloud
Question 140
製品の販売データを格納する新しいトランザクション テーブルを Cloud Spanner に作成する必要があります。
主キーとして何を使用するかを決定しています。
パフォーマンスの観点から、どの戦略を選択するべきでしょうか?
- A. 現在のエポック時間。
- B. 製品名と現在のエポック時間の連結。
- C. ランダムな普遍的に一意の識別子番号 (バージョン 4 UUID)。
- D. 単調に増加する整数である販売システムからの元の注文識別番号。
Answer: C
Question 141
社内のデータ アナリストには、プロジェクトで Cloud IAM オーナーの役割が割り当てられており、プロジェクトで複数の GCP プロダクトを操作できるようになっています。
あなたの組織では、すべての BigQuery データ アクセス ログを 6 か月間保持する必要があります。社内の監査担当者のみがすべてのプロジェクトのデータ アクセス ログにアクセスできるようにする必要があります。
何をするべきでしょうか?
- A. 各データ アナリストのプロジェクトでデータ アクセス ログを有効にします。Cloud IAM の役割を介して Stackdriver Logging へのアクセスを制限します。
- B. プロジェクト レベルのエクスポート シンクを介して、データ アナリストのプロジェクトの Cloud Storage バケットにデータ アクセス ログをエクスポートします。Cloud Storage バケットへのアクセスを制限します。
- C. プロジェクト レベルのエクスポート シンクを介して監査ログ用に新しく作成されたプロジェクトの Cloud Storage バケットにデータ アクセス ログをエクスポートします。エクスポートされたログでプロジェクトへのアクセスを制限します。
- D. 集約されたエクスポート シンクを介して監査ログ用に新しく作成されたプロジェクトの Cloud Storage バケットにデータ アクセス ログをエクスポートします。エクスポートされたログを含むプロジェクトへのアクセスを制限します。
Answer: D
Question 142
組織内の各分析チームは、独自のプロジェクトで BigQuery ジョブを実行しています。
各チームがプロジェクト内のスロットの使用状況を監視できるようにしたいと考えています。
何をするべきでしょうか?
- A. BigQuery メトリクス query/scanned_bytes に基づいて Cloud Monitoring ダッシュボードを作成します。
- B. BigQuery メトリクスの slot/allocated_for_project に基づいて Cloud Monitoring ダッシュボードを作成します。
- C. プロジェクトごとにログ エクスポートを作成し、BigQuery ジョブ実行ログを取得し、totalSlotMs に基づいてカスタム指標を作成し、カスタム指標に基づいて Cloud Monitoring ダッシュボードを作成します。
- D. 組織レベルで集約ログ エクスポートを作成し、BigQuery ジョブ実行ログをキャプチャし、totalSlotMs に基づいてカスタム指標を作成し、カスタム指標に基づいて Cloud Monitoring ダッシュボードを作成します。
Answer: B
Question 143
ストリーミング Dataflow パイプラインを運用しています。
エンジニアは、ウィンドウ アルゴリズムとトリガー戦略が異なる新しいバージョンのパイプラインを使用しています。実行中のパイプラインを新しいバージョンで更新したいと考えています。更新中にデータが失われないようにする必要があります。
何をするべきでしょうか?
- A. –jobName を既存のジョブ名に設定して –update オプションを渡すことにより、インフライトの Dataflow パイプラインを更新します。
- B. –jobName を新しい一意のジョブ名に設定して –update オプションを渡すことにより、インフライトの Dataflow パイプラインを更新します。
- C. [キャンセル] オプションを使用して Dataflow パイプラインを停止します。更新されたコードで新しい Dataflow ジョブを作成します。
- D. Drain オプションを使用して Dataflow パイプラインを停止します。更新されたコードで新しい Dataflow ジョブを作成します。
Answer: D
Reference:
既存のパイプラインを更新する | Dataflow | Google Cloud
Question 144
2 PB の履歴データをオンプレミス ストレージ アプライアンスから Cloud Storage に 6 か月以内に移動する必要があり、送信ネットワーク容量は 20 Mb/秒に制限されています。
このデータを Cloud Storage にどのように移行するべきでしょうか?
- A. Transfer Appliance を使用してデータを Cloud Storage にコピーします。
- B. gsutil cp J を使用して Cloud Storage にアップロードするコンテンツを圧縮します。
- C. 履歴データのプライベート URL を作成し、Storage Transfer Service を使用してデータを Cloud Storage にコピーします。
- D. トリクルまたはイオニスを gsutil cp と一緒に使用して gsutil が使用する帯域幅の量を 20 Mb/秒未満に制限し、本番トラフィックに干渉しないようにします。
Answer: A
Question 145
サードパーティから毎月 CSV 形式のデータ ファイルを受け取ります。
このデータをクレンジングする必要がありますが、ファイルのスキーマは 3 か月ごとに変更されます。これらの変換を実装するための要件は次のとおりです。
・スケジュール通りに変換を実行する
・開発者以外のアナリストが変換を変更できるようにする
・変換を設計するためのグラフィカルツールの提供
何をするべきでしょうか?
- A. Dataprep by Trifacta を使用して変換レシピを構築および維持し、スケジュールに基づいて実行します。
- B. 毎月の CSV データを BigQuery に読み込み、SQL クエリを記述してデータを標準スキーマに変換します。変換されたテーブルを SQL クエリと一緒にマージします。
- C. アナリストが Python で Dataflow パイプラインを記述して変換を実行できるように支援します。Python コードはリビジョン管理システムに保存し、受信データのスキーマが変更されたときに変更する必要があります。
- D. Dataframe を作成する前に Dataproc で Apache Spark を使用して CSV ファイルのスキーマを推測します。次に、データを Cloud Storage に書き込んで BigQuery に読み込む前に Spark SQL で変換を実装します。
Answer: A
Question 146
オンプレミスの Hadoop システムを Dataproc に移行したいと考えています。
主に使用されるツールは Hive で、データ形式は Optimized Row Columnar (ORC) です。すべての ORC ファイルが Cloud Storage バケットに正常にコピーされました。パフォーマンスを最大化するには、一部のデータをクラスタのローカル Hadoop 分散ファイル システム (HDFS) に複製する必要があります。
Dataproc で Hive の使用を開始する方法はどれでしょうか? (回答を 2つ選択してください)
- A. gsutil ユーティリティを実行して、すべての ORC ファイルを Cloud Storage バケットから HDFS に転送します。Hive テーブルをローカルにマウントします。
- B. gsutil ユーティリティを実行して、すべての ORC ファイルを Cloud Storage バケットから Dataproc クラスタの任意のノードに転送します。Hive テーブルをローカルにマウントします。
- C. gsutil ユーティリティを実行して、すべての ORC ファイルを Cloud Storage バケットから Dataproc クラスタのマスターノードに転送します。次に Hadoop ユーティリティを実行して、それらを HDFS にコピーします。HDFS から Hive テーブルをマウントします。
- D. Hadoop 用の Cloud Storage コネクタを利用して ORC ファイルを外部 Hive テーブルとしてマウントします。外部 Hive テーブルをネイティブ テーブルにレプリケートします。
- E. ORC ファイルを BigQuery にロードします。Hadoop 用の BigQuery コネクタを利用して、BigQuery テーブルを外部 Hive テーブルとしてマウントします。外部 Hive テーブルをネイティブ テーブルにレプリケートします。
Answer: C、D
Question 147
スケジュールに従って実行する必要がある複数のバッチ ジョブを実装しています。
これらのジョブには、特定の順序で実行する必要がある、相互に依存する多くのステップがあります。ジョブの一部には、シェル スクリプトの実行、Hadoop ジョブの実行、BigQuery でのクエリの実行が含まれます。ジョブは数分から数時間実行されることが予想されます。ステップが失敗した場合は、一定の回数だけ再試行する必要があります。
これらのジョブの実行を管理するには、どのサービスを使用するべきでしょうか?
- A. Cloud Scheduler
- B. Dataflow
- C. Cloud Functions
- D. Cloud Composer
Answer: D
Question 148
あなたは、荷物が配送ライン上を移動して適切にルーティングされる配送センターを持つ運送会社で働いています。
同社は、配送ラインにカメラを追加して、輸送中の荷物の目に見える損傷を検出および追跡したいと考えています。破損したパッケージの検出を自動化し、パッケージの輸送中に人間がリアルタイムでレビューできるようにフラグを付ける方法を作成する必要があります。
どのソリューションを選択するべきでしょうか?
- A. BigQuery 機械学習を使用してモデルを大規模にトレーニングできるため、パッケージをバッチで分析できます。
- B. 画像のコーパスで AutoML モデルをトレーニングし、そのモデルを中心に API を構築して、荷物追跡アプリケーションと統合します。
- C. Cloud Vision API を使用して損傷を検出し、Cloud Functions を介してアラートを生成する。荷物追跡アプリケーションをこの機能と統合します。
- D. TensorFlow を使用して、画像のコーパスでトレーニングされたモデルを作成します。このモデルを使用する Cloud Datalab で Python ノートブックを作成して、破損したパッケージを分析できるようにします。
Answer: B
Question 149
データ ウェアハウスを BigQuery に移行しています。
すべてのデータをデータセット内のテーブルに移行しました。組織の複数のユーザーがデータを使用します。チーム メンバーシップに基づいて特定のテーブルのみを表示する必要があります。
ユーザー権限をどのように設定するべきでしょうか?
- A. 各テーブルのテーブル レベルで、ユーザー/グループのデータ閲覧者アクセス権を割り当てます。
- B. データが存在する同じデータセットで各チームの SQL ビューを作成し、SQL ビューへのユーザー/グループのデータ閲覧者アクセス権を割り当てます。
- C. データが存在する同じデータセットで各チームの承認済みビューを作成し、ユーザー/グループのデータ閲覧者アクセスを承認済みビューに割り当てます。
- D. 各チーム用に作成されたデータセットで、各チームの承認済みビューを作成します。データが存在するデータセットへの承認されたビュー データ ビューアー アクセスを割り当てます。許可されたビューが存在するデータセットへのユーザー/グループ データ ビューアー アクセス権を割り当てます。
Answer: A
Question 150
マネージド Hadoop システムをデータ レイクとして構築したいと考えています。
データ変換プロセスは、順番に実行される一連の Hadoop ジョブで構成されます。ストレージをコンピューティングから分離する設計を実現するために、Cloud Storage コネクタを使用してすべての入力データ、出力データ、中間データを保存することにしました。ただし、オンプレミスのベアメタル Hadoop 環境 (100 GB RAM の 8 コア ノード) と比較すると Dataproc では 1 つの Hadoop ジョブの実行が非常に遅いことに気付きました。分析によると、この特定の Hadoop ジョブはディスク I/O 集中型であることがわかります。問題を解決したい。
何をするべきでしょうか?
- A. 特定の Hadoop ジョブの中間データをメモリに保持できるように Hadoop クラスタに十分なメモリを割り当てます。
- B. Hadoop クラスタに十分な永続ディスク領域を割り当て、その特定の Hadoop ジョブの中間データをネイティブ HDFS に保存します。
- C. 各インスタンスのネットワーク帯域幅をスケールアップできるように Hadoop クラスタの仮想マシン インスタンスの CPU コアをさらに割り当てます。
- D. 追加のネットワーク インターフェイス カード (NIC) を割り当て、オペレーティング システムでリンク アグリゲーションを構成して Cloud Storage を操作するときに結合されたスループットを使用します。
Answer: B
Question 151
あなたは広告会社で働いており、広告ブロックでのクリック率を予測する Spark ML モデルを開発しました。
オンプレミスのデータセンターですべてを開発してきましたが、現在、会社は Google Cloud に移行しています。データセンターが間もなく閉鎖されるため、迅速なリフト&シフト移行が必要ですが、これまで使用していたデータは BigQuery に移行されます。Spark ML モデルを定期的に再トレーニングするため、既存のトレーニング パイプラインを Google Cloud に移行する必要があります。
何をするべきでしょうか?
- A. Vertex AI を使用して、既存の Spark ML モデルをトレーニングします。
- B. TensorFlow でモデルを書き直し、Vertex AI の使用を開始する。
- C. 既存の Spark ML モデルのトレーニングには Dataproc を使用しますが BigQuery から直接データの読み取りを開始します。
- D. Compute Engine で Spark クラスタを起動し、BigQuery からエクスポートされたデータで Spark ML モデルをトレーニングします。
Answer: C
Question 152
あなたは世界的な海運会社で働いています。
40 TB のデータでモデルをトレーニングして、各地域のどの船が特定の日に配送遅延を引き起こす可能性があるかを予測したいと考えています。モデルは、複数のソースから収集された複数の属性に基づいています。GeoJSON 形式の場所を含むテレメトリ データは、各船から 1 時間ごとに取得され、読み込まれます。地域内で遅延を引き起こす可能性のある船の数と、どの船が遅れているかを示すダッシュボードが必要です。予測と地理空間処理のためのネイティブ機能を備えたストレージ ソリューションを使用したいと考えています。
どのストレージ ソリューションを使用するべきでしょうか?
- A. BigQuery
- B. Cloud Bigtable
- C. Datastore
- D. PostgreSQL 用 Cloud SQL
Answer: A
Question 153
あなたは Apache Kafka を中心に構築された IoT パイプラインを運用しています。このパイプラインは通常、毎秒約 5000 のメッセージを受信します。
Google Cloud Platform を使用して 1 時間の移動平均が 1 秒あたり 4000 メッセージを下回ったらすぐにアラートを作成したいと考えています。
何をするべきでしょうか?
- A. Kafka IO を使用して Dataflow でデータ ストリームを使用します。5 分ごとに 1 時間のスライディング タイム ウィンドウを設定します。ウィンドウが閉じたときに平均を計算し、平均が 4000 メッセージ未満の場合はアラートを送信します。
- B. Kafka IO を使用して Dataflow でデータ ストリームを使用します。1 時間の固定時間枠を設定します。ウィンドウが閉じたときに平均を計算し、平均が 4000 メッセージ未満の場合はアラートを送信します。
- C. Kafka Connect を使用して Kafka メッセージ キューを Pub/Sub にリンクします。Dataflow テンプレートを使用して Pub/Sub から Cloud Bigtable にメッセージを書き込みます。Cloud Scheduler を使用して過去 1 時間に Cloud Bigtable で作成された行数をカウントするスクリプトを 1 時間ごとに実行します。その数が 4000 を下回った場合はアラートを送信します。
- D. Kafka Connect を使用して Kafka メッセージ キューを Pub/Sub にリンクします。Dataflow テンプレートを使用して Pub/Sub から BigQuery にメッセージを書き込みます。Cloud Scheduler を使用して過去 1 時間に BigQuery で作成された行数をカウントするスクリプトを 5 分ごとに実行します。その数が 4000 を下回った場合はアラートを送信します。
Answer: A
Question 154
MySQL を使用して Cloud SQL をデプロイする予定です。
ゾーンに障害が発生した場合の高可用性を確保する必要があります。
何をするべきでしょうか?
- A. 1 つのゾーンに Cloud SQL インスタンスを作成し、同じリージョン内の別のゾーンにフェイルオーバー レプリカを作成します。
- B. 1 つのゾーンに Cloud SQL インスタンスを作成し、同じリージョン内の別のゾーンにリードレプリカを作成します。
- C. 1 つのゾーンに Cloud SQL インスタンスを作成し、別のリージョンのゾーンに外部リードレプリカを構成します。
- D. リージョンに Cloud SQL インスタンスを作成し、同じリージョンの Cloud Storage バケットへの自動バックアップを構成します。
Answer: A
Question 155
あなたの会社は、データの取り込みと配信を一元化するシステムを選択しています。
要件に対応するために、メッセージングおよびデータ統合システムを検討しています。主な要件は次のとおりです。
・トピック内の特定のオフセットをシークする機能。これまでにキャプチャされたすべてのデータの先頭に戻る可能性があります
・数百のトピックでのパブリッシュ/サブスクライブ セマンティクスのサポート
・キーごとの順序を保持
どのシステムを選択するべきでしょうか?
- A. Apache Kafka
- B. Cloud Storage
- C. Dataflow
- D. Firebase Cloud Messaging
Answer: A
Question 156
現在のオンプレミスの Apache Hadoop デプロイメントをクラウドに移行することを計画しています。
実行時間の長いバッチ ジョブに対して、可能な限りフォールト トレラントで費用対効果の高い展開を確保する必要があります。マネージド サービスを利用したい。
何をするべきでしょうか?
- A. Dataproc クラスタをデプロイします。標準の永続ディスクと 50% のプリエンプティブル ワーカーを使用します。Cloud Storage にデータを保存し、スクリプト内の参照を hdfs:// から gs:// に変更します
- B. Dataproc クラスタをデプロイします。SSD 永続ディスクと 50% のプリエンプティブル ワーカーを使用します。Cloud Storage にデータを保存し、スクリプト内の参照を hdfs:// から gs:// に変更します
- C. 標準インスタンスを含む 10 ノードの Compute Engine インスタンス グループに Hadoop と Spark をインストールします。Cloud Storage コネクタをインストールし、データを Cloud Storage に保存します。スクリプト内の参照を hdfs:// から gs:// に変更します
- D. プリエンプティブル インスタンスを含む 10 ノードの Compute Engine インスタンス グループに Hadoop と Spark をインストールします。HDFS にデータを保存します。スクリプト内の参照を hdfs:// から gs:// に変更します。
Answer: A
Question 157
あなたのチームは二値分類問題に取り組んでいます。
サポート ベクター マシン (SVM) 分類子を既定のパラメーターでトレーニングし、検証セットで 0.87 の曲線下面積 (AUC) を受け取りました。モデルの AUC を増やしたいと考えています。
何をするべきでしょうか?
- A. ハイパーパラメータ調整を実行します。
- B. ニューラル ネットワークは常に SVM を打ち負かすため、ディープ ニューラル ネットワークを使用して分類器をトレーニングします。
- C. モデルを展開し、実際の AUC を測定します。一般化のため、常に高くなります。
- D. 最高の AUC を得るためにモデルから取得した予測をスケーリングします (スケーリング係数をハイパーパラメーターとして調整します)。
Answer: A
Question 158
既存の初期化アクションを使用して、起動時に Dataproc クラスタのすべてのノードに追加の依存関係をデプロイする必要があります。
会社のセキュリティ ポリシーでは Dataproc ノードがインターネットにアクセスできないようにする必要があるため、パブリックの初期化アクションはリソースをフェッチできません。
何をするべきでしょうか?
- A. Dataproc マスターに Cloud SQL Proxy をデプロイします。
- B. SSH トンネルを使用して Dataproc クラスタがインターネットにアクセスできるようにする。
- C. VPC セキュリティ境界内の Cloud Storage バケットにすべての依存関係をコピーします。
- D. Resource Manager を使用して Dataproc クラスタで使用されるサービス アカウントをネットワーク ユーザー ロールに追加します。
Answer: C
Question 159
次の要件を持つ新しいプロジェクト用のデータベースを選択する必要があります。
・フルマネージド
・自動スケールアップ可能
・トランザクション一貫性
・6TBまでスケールアップ可能
・SQLでクエリ可能
どのデータベースを選択しますか?
- A. Cloud SQL
- B. Cloud Bigtable
- C. Cloud Spanner
- D. Datastore
Answer: A
Question 160
あなたは、運用システムのトランザクション データをオンプレミス データベースから GCP に移行する必要がある中規模企業で働いています。
データベースのサイズは約 20 TB です。
どのデータベースを選択するべきでしょうか?
- A. Cloud SQL
- B. Cloud Bigtable
- C. Cloud Spanner
- D. Datastore
Answer: A
Question 161
何百万ものコンピューターの CPU とメモリの使用状況を時系列で保存するデータベースを選択する必要があります。
このデータを 1 秒間隔のサンプルに格納する必要があります。アナリストは、データベースに対してリアルタイムのアドホック分析を実行します。クエリを実行するたびに料金が発生することを避け、スキーマ設計がデータセットの将来の成長に対応できるようにする必要があります。
どのデータベースとデータ モデルを選択するべきでしょうか?
- A. BigQuery でテーブルを作成し、CPU とメモリの新しいサンプルをテーブルに追加します。
- B. BigQuery で幅の広いテーブルを作成し、1 秒ごとにサンプル値の列を作成し、1 秒ごとの間隔で行を更新します。
- C. コンピュータ エンジンのコンピュータ ID と毎秒のサンプル時間を組み合わせた行キーを使用して、Cloud Bigtable に狭いテーブルを作成します。
- D. Cloud Bigtable に幅の広いテーブルを作成し、コンピューター識別子と毎分のサンプル時間を組み合わせた行キーを使用し、各秒の値を列データとして組み合わせます。
Answer: C
Question 162
Cloud Storage にデータをアーカイブしたいと考えています。
一部のデータは非常に機密であるため、「Trust No One」(TNO) アプローチを使用してデータを暗号化し、クラウド プロバイダーのスタッフがデータを解読できないようにする必要があります。
何をするべきでしょうか?
- A. gcloud kms keys を使用して対称鍵を作成します。次に gcloud kms encrypt を使用して、キーと一意の追加認証データ (AAD) を使用して各アーカイブ ファイルを暗号化します。gsutil cp を使用して、暗号化された各ファイルを Cloud Storage バケットにアップロードし、AAD を Google Cloud の外部に保持します。
- B. gcloud kms keys を使用して対称鍵を作成します。次に gcloud kms encrypt を使用して、各アーカイブ ファイルをキーで暗号化します。gsutil cp を使用して、暗号化された各ファイルを Cloud Storage バケットにアップロードします。以前に暗号化に使用したキーを手動で破棄し、キーを 1 回ローテーションします。
- C. .boto 構成ファイルで顧客提供の暗号化キー (CSEK) を指定します。gsutil cp を使用して、各アーカイブ ファイルを Cloud Storage バケットにアップロードします。CSEK をシークレットの永続的なストレージとして Cloud Memorystore に保存します。
- D. .boto 構成ファイルで顧客提供の暗号化キー (CSEK) を指定します。gsutil cp を使用して、各アーカイブ ファイルを Cloud Storage バケットにアップロードします。セキュリティ チームのみがアクセスできる別のプロジェクトに CSEK を保存します。
Answer: A
Question 163
BigQuery、Dataflow、Dataproc で実行されているデータ パイプラインがあります。
ヘルス チェックを実行してその動作を監視し、失敗した場合はパイプラインを管理するチームに通知する必要があります。また、複数のプロジェクトにまたがって作業できる必要があります。あなたの好みは、プラットフォームのマネージド製品または機能を使用することです.
何をするべきでしょうか?
- A. Cloud Monitoring に情報をエクスポートし、アラート ポリシーを設定します。
- B. Airflow を使用して Compute Engine で仮想マシンを実行し、情報を Cloud Monitoring にエクスポートします。
- C. ログを BigQuery にエクスポートし、その情報を読み取ってログに障害が見つかった場合にメールを送信するように App Engine を設定します。
- D. GCP API 呼び出しを使用してログを消費する App Engine アプリケーションを開発し、ログに障害が見つかった場合はメールを送信します。
Answer: A
Question 164
あなたは BigQuery ML で線形回帰モデルに取り組んでおり、顧客が自社の製品を購入する可能性を予測しています。
このモデルでは、主要な予測コンポーネントとして都市名の変数を使用しています。モデルをトレーニングして提供するには、データを列に編成する必要があります。予測可能な変数を維持しながら、最小限のコーディングを使用してデータを準備したいと考えています。
何をするべきでしょうか?
- A. BigQuery を使用して、都市情報の列を含まない新しいビューを作成します。
- B. BigQuery で SQL を使用して、ワンホット エンコーディング メソッドを使用して州列を変換し、各都市をバイナリ値の列にします。
- C. TensorFlow を使用して、語彙リストを含むカテゴリ変数を作成します。ボキャブラリ ファイルを作成し、モデルの一部として BigQuery ML にアップロードします。
- D. Cloud Data Fusion を使用して、各都市を 1、2、3、4、または 5 のラベルが付いた地域に割り当て、その番号を使用してモデル内の都市を表現します。
Answer: B
Question 165
あなたは、北米各地で営業している大手銀行で働いています。
銀行口座取引を処理するデータ ストレージ システムを設定しています。ACID への準拠と、SQL を使用してデータにアクセスする機能が必要です。
適切なソリューションはどれですか?
- A. トランザクション データを Cloud Spanner に保存します。古い読み取りを有効にして待ち時間を短縮します。
- B. Cloud Spanner にトランザクションを保存します。ロック読み取り/書き込みトランザクションを使用します。
- C. トランザクション データを BigQuery に保存します。一貫性を確保するためにクエリ キャッシュを無効にします。
- D. トランザクション データを Cloud SQL に保存します。分析には連携クエリ BigQuery を使用します。
Answer: B
Question 166
運送会社には、リアルタイムで Apache Kafka ストリームに送信されるライブ パッケージ追跡データがあります。
これが BigQuery に読み込まれます。あなたの会社のアナリストは、パッケージのライフサイクルにおける地理空間の傾向を分析するために BigQuery で追跡データをクエリしたいと考えています。このテーブルは、もともと ingest-date パーティショニングを使用して作成されました。時間の経過とともに、クエリの処理時間が増加しました。BigQuery でのクエリ パフォーマンスを向上させる変更を実装する必要があります。
何をするべきでしょうか?
- A. 取り込み日付列で BigQuery にクラスタリングを実装します。
- B. BigQuery でパッケージ追跡 ID 列にクラスタリングを実装します。
- C. 古いデータを Cloud Storage ファイルに階層化し、Cloud Storage を外部データソースとして使用して BigQuery テーブルを作成する。
- D. パッケージ配達日にデータ分割を使用してテーブルを再作成します。
Answer: B
Question 167
あなたの会社は現在、コロケーション施設で Spark、Hive、および HDFS を使用して大規模なオンプレミス クラスタを実行しています。
クラスタは、システムのピーク使用に対応できるように設計されています。ただし、多くのジョブは本質的にバッチであり、クラスタの使用量は非常に劇的に変動します。あなたの会社は、オンプレミスのインフラストラクチャとメンテナンスに関連するオーバーヘッドを削減し、コスト削減の恩恵を受けるために、クラウドへの移行を切望しています。また、クラウドを活用するために、既存のインフラストラクチャをモダナイズして、より多くのサーバーレス サービスを使用することも望んでいます。コロケーション施設との契約更新のタイミングのため、最初の移行期間は 2 か月しかありません。
今後の移行戦略にどのように取り組むことをお勧めしますか?
- A. ワークロードを Dataproc と HDFS に移行します。後でモダナイズします。
- B. ワークロードを Dataproc と Cloud Storage に移行します。後でモダナイズします。
- C. Spark ワークロードを Dataproc と HDFS に移行し、BigQuery の Hive ワークロードをモダナイズします。
- D. Dataflow の Spark ワークロードと BigQuery の Hive ワークロードをモダナイズします。
Answer: B
Question 168
あなたは、顧客がオンラインで登録できる金融機関で働いています。
新規顧客が登録すると、そのユーザー データは BigQuery に取り込まれる前に Pub/Sub に送信されます。セキュリティ上の理由から、顧客サービス担当者が必要に応じて元の値を表示できるようにしながら、顧客の政府発行の識別番号を編集することにしました。
何をするべきでしょうか?
- A. BigQuery の組み込みの AEAD 暗号化を使用して SSN 列を暗号化します。許可されたユーザーのみが表示できる新しいテーブルにキーを保存します。
- B. BigQuery の列レベル セキュリティを使用します。Customer Service ユーザー グループのメンバーのみが SSN 列を表示できるようにテーブルのアクセス許可を設定します。
- C. データを BigQuery にロードする前に Cloud Data Loss Prevention (DLP) を使用して入力値を暗号化ハッシュに置き換えます。
- D. データを BigQuery にロードする前に Cloud Data Loss Prevention (DLP) を使用して入力値を暗号形式を保持する暗号化トークンに置き換えます。
Answer: B
Question 169
テーブルを BigQuery に移行しており、データ モデルを決定しています。
テーブルには、複数の店舗で行われた購入に関連する情報が格納され、トランザクションの時間、購入されたアイテム、店舗 ID、店舗がある市と州などの情報が含まれています。このテーブルを頻繁にクエリして、過去 30 日間に販売された各アイテムの数を確認し、州、都市、および個々の店舗ごとの購入傾向を調べます。
最高のクエリ パフォーマンスを得るには、このテーブルをどのようにモデル化しますか?
- A. トランザクション時間で分割します。最初に州、次に都市、次に店舗 ID ごとにクラスタ化します。
- B. トランザクション時間による分割。最初に店舗 ID、次に市、州の順にクラスタ化します。
- C. 最初に州、次に都市、次に店舗 ID による最上位クラスタ化します。
- D. 最初に店舗 ID、次に都市、次に州による最上位クラスタ化します。
Answer: A
Question 170
サブスクライバーのコードを Pub/Sub フィードに更新しています。
展開時に、サブスクライバーが誤ってメッセージを確認し、メッセージの損失につながる可能性があることを懸念しています。サブスクライバーは、確認済みメッセージを保持するように設定されていません。
展開後にエラーから確実に回復できるようにするにはどうすればよいですか?
- A. ローカル マシンに Pub/Sub エミュレータをセットアップします。運用環境にデプロイする前に、新しいサブスクライバー ロジックの動作を検証します。
- B. 新しいサブスクライバー コードをデプロイする前に Pub/Sub スナップショットを作成します。シーク操作を使用してスナップショットの作成後に利用可能になったメッセージを再配信します。
- C. デプロイに Cloud Build を使用します。デプロイ後にエラーが発生した場合はシーク オペレーションを使用して、デプロイの開始時に Cloud Build によって記録されたタイムスタンプを見つけます。
- D. Pub/Sub トピックで配信不能を有効にして正常に確認されなかったメッセージをキャプチャします。展開後にエラーが発生した場合は配信不能キューによってキャプチャされたすべてのメッセージを再配信します。
Answer: B
Reference:
メッセージの再生と消去 | Cloud Pub/Sub ドキュメント | Google Cloud
Question 171
あなたは大規模な不動産会社に勤務しており、機械学習に使用する 6 TB の住宅販売データを準備しています。
SQL を使用してデータを変換し、BigQuery ML を使用して機械学習モデルを作成します。変換されていない生のデータセットに対する予測にモデルを使用する予定です。
予測時のスキューを防ぐために、ワークフローをどのように設定するべきでしょうか?
- A. モデルを作成するときは BigQuery の TRANSFORM 句を使用して前処理ステップを定義します。予測時に、未加工の入力データに対する変換を指定せずに BigQuery の ML.EVALUATE 句を使用します。
- B. モデルを作成するときは BigQuery の TRANSFORM 句を使用して前処理ステップを定義します。予測をリクエストする前に、保存されたクエリを使用して生の入力データを変換してから ML.EVALUATE を使用します。
- C. BigQuery ビューを使用して前処理ロジックを定義します。モデルを作成するときは、ビューをモデル トレーニング データとして使用します。予測時に、未加工の入力データに対する変換を指定せずに BigQuery の ML.EVALUATE 句を使用します。
- D. Dataflow を使用してすべてのデータを前処理します。予測時には、入力データに対してそれ以上の変換を指定せずに BigQuery の ML.EVALUATE 句を使用します。
Answer: A
Question 172
あなたは会社の株価を分析しています。
5 秒ごとに過去 30 秒間のデータの移動平均を計算する必要があります。Pub/Sub からデータを読み取り、Dataflow を使用して分析を行っています。
ウィンドウ化されたパイプラインをどのように設定するべきでしょうか?
- A. 5 秒間の固定ウィンドウを使用します。次のトリガーを設定して結果を出力します。
AfterProcessingTime.pastFirstElementInPane().plusDelayOf (Duration.standardSeconds(30)) - B. 30 秒の固定ウィンドウを使用します。次のトリガーを設定して結果を出力します。
AfterWatermark.pastEndOfWindow().plusDelayOf (Duration.standardSeconds(5)) - C. 5 秒間のスライディング ウィンドウを使用します。次のトリガーを設定して結果を出力します。
AfterProcessingTime.pastFirstElementInPane().plusDelayOf (Duration.standardSeconds(30)) - D. 持続時間 30 秒、期間 5 秒のスライディング ウィンドウを使用します。次のトリガーを設定して結果を出力します。
AfterWatermark.pastEndOfWindow ()
Answer: D
Question 173
アプリケーション イベントを Pub/Sub トピックに発行するパイプラインを設計しています。
メッセージの順序は重要ではありませんが、分析のために結果を BigQuery に読み込む前に、ばらばらな 1 時間間隔でイベントを集計する必要があります。
このデータを処理して BigQuery にロードし、大量のイベントに合わせて確実にスケーリングするには、どのテクノロジーを使用するべきでしょうか?
- A. 新しいメッセージがトピックにパブリッシュされるたびに Pub/Sub トリガーを使用して実行される必要なデータ処理を実行する Cloud Functions を作成します。
- B. Cloud Functions を 1 時間ごとに実行するようにスケジュールし、Pub/Sub トピックから利用可能なすべてのメッセージを取得して必要な集計を実行します。
- C. バッチ Dataflow ジョブを 1 時間ごとに実行するようにスケジュールし、Pub/Sub トピックから利用可能なすべてのメッセージを取得して必要な集計を実行します。
- D. Pub/Sub トピックから継続的に読み取り、タンブリング ウィンドウを使用して必要な集計を実行するストリーミング データフロー ジョブを作成します。
Answer: D
Question 174
あなたは Dialogflow を使用して会社のモバイル アプリ用のチャットボットを作成することを計画している大規模な金融機関で働いています。
古いチャット ログを確認し、カスタマー サービスに連絡するという各顧客の意図に基づいて、各会話にタグを付けました。お客様のリクエストの約 70% は 10 インテント以内で解決される単純なリクエストです。問い合わせの残りの 30% ははるかに長く、より複雑な要求を必要とします。
最初にどのインテントを自動化するべきでしょうか?
- A. リクエストの 70% をカバーする 10 個のインテントを自動化して、ライブ エージェントがより複雑なリクエストを処理できるようにします。
- B. より複雑なリクエストはエージェントの時間をより多く必要とするため、最初に自動化します。
- C. 最短インテントと最長インテントのブレンドを自動化して、すべてのインテントを代表するようにします。
- D. ソフトウェアが混乱しないように「支払い」などの一般的な単語が 1 回しか表示されない場所でインテントを自動化します。
Answer: A
Question 175
あなたの会社は BigQuery を使用してデータ ウェアハウスを実装しており、データ モデルの設計を任されています。
スター データ スキーマを使用してオンプレミスの販売データ ウェアハウスを BigQuery に移行しましたが、過去 30 日間のデータをクエリするときにパフォーマンスの問題に気づきました。
Google のベスト プラクティスに基づいて、ストレージ コストを増加させずにクエリを高速化するにはどうすればよいですか?
- A. データを非正規化します。
- B. 顧客 ID ごとにデータを分割します。
- C. ビューでディメンション データを具体化します。
- D. 取引日ごとにデータを分割します。
Answer: D
Reference:
スキーマとデータ転送の概要 | BigQuery | Google Cloud
Question 176
5 年分のログデータを Cloud Storage にアップロードしました。
ユーザーから、ログ データの一部のデータ ポイントが想定範囲外であることが報告されました。これはエラーを示しています。この問題に対処し、コンプライアンス上の理由から元のデータを保持しながら、将来プロセスを再度実行できるようにする必要があります。
何をするべきでしょうか?
- A. Cloud Storage から BigQuery にデータをインポートします。新しい BigQuery テーブルを作成し、エラーのある行をスキップします。
- B. Compute Engine インスタンスを作成し、Cloud Storage にデータの新しいコピーを作成します。エラーのある行をスキップします。
- C. Cloud Storage からデータを読み取り、想定範囲外の値をチェックし、値を適切なデフォルトに設定し、更新されたレコードを Cloud Storage の新しいデータセットに書き込む Dataflow ワークフローを作成します。
- D. Cloud Storage からデータを読み取り、想定範囲外の値をチェックし、値を適切なデフォルトに設定し、更新されたレコードを Cloud Storage の同じデータセットに書き込む Dataflow ワークフローを作成します。
Answer: C
Question 177
Google Cloud で構造化データのバッチ パイプラインを再構築したいと考えています。
PySpark を使用して大規模なデータ変換を行っていますが、パイプラインの実行に 12 時間以上かかっています。開発とパイプラインの実行時間を短縮するには、サーバーレス ツールと SOL 構文を使用します。生データはすでに Cloud Storage に移動しています。
速度と処理の要件を満たしながら Google Cloud でパイプラインを構築するにはどうすればよいですか。
- A. PySpark コマンドを SparkSQL クエリに変換してデータを変換し、Dataproc でパイプラインを実行してデータを BigQuery に書き込みます。
- B. データを Cloud SQL に取り込み、PySpark コマンドを SparkSQL クエリに変換してデータを変換し、機械学習のために BigQuery から連携キューを使用します。
- C. Cloud Storage から BigQuery にデータを取り込み、PySpark コマンドを BigQuery SQL クエリに変換してデータを変換し、変換を新しいテーブルに書き込みます。
- D. Apache Beam Python SDK を使用して変換パイプラインを構築し、データを BigQuery に書き込みます。
Answer: C
Question 178
テキスト ファイルを取り込んで変換する Dataflow パイプラインをテストしています。
ファイルは gzip で圧縮され、エラーは配信不能キューに書き込まれ、SideInputs を使用してデータを結合しています。
パイプラインの完了に予想よりも時間がかかっていることに気付きました。
Dataflow ジョブを迅速に処理するにはどうすればよいですか?
- A. 圧縮された Avro ファイルに切り替えます。
- B. バッチサイズを減らします。
- C. エラーをスローするレコードを再試行します。
- D. SideInput の代わりに CoGroupByKey を使用する。
Answer: D
Question 179
PII (個人を特定できる情報) データを含む可能性のあるファイルを Cloud Storage にストリーミングし、最終的には BigQuery にストリーミングするリアルタイム予測エンジンを構築しています。
名前と電子メールが結合キーとしてよく使用されるため、機密データがマスクされていても参照整合性が維持されていることを確認する必要があります。
Cloud Data Loss Prevention API (DLP API) をどのように使用して、許可されていない個人が PII データにアクセスできないようにするべきでしょうか?
- A. PII データを暗号化トークンに置き換えて仮名を作成し、トークン化されていないデータをロックダウン ボタンに保存します。
- B. すべての PII データを編集し、未編集のデータのバージョンをロックダウンされたバケットに保存します。
- C. BigQuery のすべてのテーブルをスキャンし、PII を含むデータをマスクします。
- D. PII データを暗号フォーマット保持トークンに置き換えて仮名を作成します。
Answer: D
Question 180
あなたは、図書館の書籍と各書籍に関する情報 (著者や発行年など) を追跡するアプリケーションを、オンプレミスのデータ ウェアハウスから BigQuery に移行しています。
現在のリレーショナル データベースでは、著者情報は別のテーブルに保持され、共通キーで書籍情報に結合されています。
スキーマ設計に関する Google の推奨プラクティスに基づいて、借用した各本の著者に関するクエリの最適な速度を確保するために、データをどのように構造化しますか?
- A. スキーマを同じに保ち、書籍と各属性の異なるテーブルを維持し、現在行っているようにクエリを実行します。
- B.幅が広く、著者の名、姓、生年月日などを含む各属性の列を含むテーブルを作成します。
- C.書籍と著者に関する情報を含むテーブルを作成しますが、著者フィールドを著者列内にネストします。
- D. スキーマを同じに保ち、すべてのテーブルを結合するビューを作成し、常にビューに対してクエリを実行します。
Answer: C
Question 181
データ ポイントを取得して GUID を返すサービスを使用して、新しい Web サイト ユーザーにグローバル一意識別子 (GUID) を付与する必要があります。
このデータは、パイプライン内のマイクロサービスを介して行う HTTP 呼び出しを介して、内部システムと外部システムの両方から供給されます。毎秒数万のメッセージがあり、マルチスレッド化できます。システムの背圧が心配です。
その背圧を最小限に抑えるために、パイプラインをどのように設計するべきでしょうか?
- A. HTTP 経由でサービスを呼び出します。
- B. クラス定義で静的にパイプラインを作成します。
- C. DoFn の startBundle メソッドで新しいオブジェクトを作成します。
- D. ジョブを 10 秒単位でバッチ処理します。
Answer: D
Question 182
あなたは、データ ウェアハウスを Google Cloud に移行し、オンプレミス データセンターを廃止しています。
これは会社の優先事項であるため、クラウドへの初期データ ロードに帯域幅が使用可能になることがわかっています。転送されるファイルの数は多くありませんが、各ファイルは 90 GB です。さらに、トランザクション システムで Google Cloud 上の倉庫をリアルタイムで継続的に更新する必要があります。
データを移行し、ウェアハウスへの書き込みを継続するにはどのツールを使用するべきでしょうか?
- A. 移行用に Storage Transfer Service、リアルタイム更新に Pub/Sub と Cloud Data Fusion。
- B. 移行用に BigQuery Data Transfer Service、リアルタイム更新に Pub/Sub と Dataproc。
- C. 移行用に gsutil、リアルタイム更新に Pub/Sub と Dataflow。
- D. 移行とリアルタイム更新の両方に gsutil。
Answer: C
Question 183
Cloud Bigtable を使用して、各主要指数の株式市場データを保持および提供しています。
取引アプリケーションを提供するには、ストリーミングされている最新の株価のみにアクセスする必要があります。
最も単純なクエリでデータにアクセスできるようにするには、行キーとテーブルをどのように設計するべきでしょうか?
- A. すべてのインデックスに対して 1 つの一意のテーブルを作成し、インデックスとタイムスタンプを行キーの設計として使用します。
- B. すべてのインデックスに対して 1 つの一意のテーブルを作成し、逆タイムスタンプを行キーの設計として使用します。
- C. インデックスごとに個別のテーブルを用意し、行キーの設計としてタイムスタンプを使用します。
- D. インデックスごとに個別のテーブルを用意し、行キーの設計として逆タイムスタンプを使用します。
Answer: A
Question 184
あなたは、ストリーミング API を介してデータが BigQuery にストリーミングされるレポート専用のデータ ウェアハウスを構築しています。
Google のベスト プラクティスに従って、データ用のステージング テーブルと運用テーブルの両方を用意します。取り込み部分またはレポート部分のパフォーマンスに影響を与えることなく、マスター データセットが 1 つだけになるようにするには、データの読み込みをどのように設計するべきでしょうか?
- A. 追加専用モデルのステージング テーブルを用意し、ステージングに書き込まれた変更で 3 時間ごとに運用テーブルを更新します。
- B. 追加専用モデルのステージング テーブルを用意し、ステージングに書き込まれた変更で 90 分ごとに運用テーブルを更新します。
- C.ステージングされたデータを本番テーブルに移動し、ステージング テーブルの内容を3時間ごとに削除するステージング テーブルを用意します。
- D.ステージングされたデータを本番テーブルに移動し、ステージング テーブルの内容を30分ごとに削除するステージング テーブルを用意します。
Answer: C
Question 185
新しいバッチ ジョブを Dataflow に発行します。
ジョブは正常に開始され、いくつかの要素を処理した後、突然失敗してシャットダウンします。パイプライン内の特定の DoFn に関連するエラーを見つける Dataflow モニタリング インターフェースに移動します。
エラーの最も可能性の高い原因は何ですか?
- A. ジョブの検証
- B. ワーカー コードの例外
- C. グラフまたはパイプラインの構築
- D. 権限が不十分
Answer: B
Question 186
新しい顧客は Google Cloud コンピューティング リソースの正味消費量とリソースを使用したユーザーを示す日次レポートを要求しました。
これらの日次レポートを迅速かつ効率的に生成する必要があります。
何をするべきでしょうか?
- A. Cloud Logging データを BigQuery に毎日エクスポートする。プロジェクト、ログの種類、リソース、およびユーザーでフィルタリングするビューを作成します。
- B. Cloud Logging のデータをプロジェクト、リソース、ユーザー別にフィルタリングする。次に、データを CSV 形式でエクスポートします。
- C. Cloud Logging のデータをプロジェクト、ログの種類、リソース、ユーザーでフィルタリングし、そのデータを BigQuery にインポートします。
- D. Cloud Logging データを CSV 形式で Cloud Storage にエクスポートします。Dataprep を使用してデータをクレンジングし、プロジェクト、リソース、ユーザーでフィルタリングします。
Answer: A
Question 187
開発チームと外部チームには Visualization という名前のフォルダーに、プロジェクト ビューアーの Identity and Access Management (IAM) ロールがあります。
開発チームは Cloud Storage と BigQuery の両方からデータを読み取れるようにする必要がありますが、外部チームは BigQuery からのみデータを読み取れるようにする必要があります。
何をするべきでしょうか?
- A. acme-raw-data プロジェクトの外部チームに対する Cloud Storage IAM 権限を削除します。
- B. 外部チーム CIDR 範囲からのすべてのイングレス トラフィックを拒否する Virtual Private Cloud (VPC) ファイアウォール ルールを acme-raw-data プロジェクトに作成します。
- C. プロジェクトと BigQuery の両方を制限付き API として含む VPC Service Controls 境界を作成します。外部チーム ユーザーを境界のアクセス レベルに追加します。
- D. プロジェクトと Cloud Storage の両方を制限付き API として含む VPC Service Controls 境界を作成します。開発チームのユーザーを境界のアクセス レベルに追加します。
Answer: D
Question 188
あなたのスタートアップには、現在アジアの 1 つの地域の顧客にサービスを提供している Web アプリケーションがあります。
あなたのスタートアップが世界中の顧客にサービスを提供できるようにするための資金調達を目標にしています。現在の目標はコストを最適化することであり、資金調達後の目標はグローバルなプレゼンスとパフォーマンスを最適化することです。
ネイティブ JDBC ドライバーを使用する必要があります。
何をするべきでしょうか?
- A. 最初に Cloud Spanner を使用して単一リージョン インスタンスを構成し、資金を確保した後でマルチリージョン Cloud Spanner インスタンスを構成します。
- B. 最初に Cloud SQL for PostgreSQL の高可用性インスタンスを使用し、資金を確保した後、米国、ヨーロッパ、アジアのレプリケーションで Cloud Bigtable を使用します。
- C. 最初に Cloud SQL for PostgreSQL ゾーン インスタンスを使用し、資金を確保した後で米国、ヨーロッパ、アジアで Cloud Bigtable を使用する。
- D. 最初に Cloud SQL for PostgreSQL ゾーン インスタンスを使用し、資金を確保した後、高可用性構成の Cloud SQL for PostgreSQL を使用します。
Answer: A
Question 189
オンプレミス データセンターから Google Cloud に 1 PB のデータを移行する必要があります。移行中のデータ転送時間は、数時間しかかかりません。
安全な接続を介して大規模なデータ転送を容易にするために Google が推奨する方法に従う必要があります。
何をするべきでしょうか?
- A. オンプレミス データセンターと Google Cloud の間に Cloud Interconnect 接続を確立してから、Storage Transfer Service を使用します。
- B. Transfer Appliance を使用し、エンジニアに手動でデータの暗号化、復号化、および検証を依頼します。
- C. Cloud VPN 接続を確立し、gcloud compute scp ジョブを並行して開始し、チェックサムを実行してデータを検証します。
- D. データを 3 TB のバッチに減らし、gsutil を使用してデータを転送し、チェックサムを実行してデータを検証します。
Answer: A
Question 190
Cloud Storage から BigQuery に CSV ファイルを読み込んでいます。
ファイルには、同じ列の STRING と INT64 などのデータ型の不一致や、電話番号や住所などの値のフォーマットの不一致など、既知のデータ品質の問題があります。データ品質を維持し、必要なクレンジングと変換を実行するには、データ パイプラインを作成する必要があります。
何をするべきでしょうか?
- A. データを BigQuery に読み込む前に Data Fusion を使用してデータを変換します。
- B. データを BigQuery にロードする前に Data Fusion を使用して CSV ファイルを AVRO などの自己記述型データ形式に変換します。
- C. CSV ファイルを目的のスキーマでステージング テーブルにロードし、SQL で変換を実行してから、結果を最終的な宛先テーブルに書き込みます。
- D. 目的のスキーマでテーブルを作成し、CSV ファイルをテーブルにロードして、SQL を使用してその場で変換を実行します。
Answer: A
Question 191
あなたは e コマース サイトで顧客が購入する可能性を予測する新しいディープ ラーニング モデルを開発しています。
元のトレーニング データと新しいテスト データの両方に対してモデルの評価を実行した後、モデルがデータをオーバーフィットしていることに気付きました。新しいデータを予測するときのモデルの精度を向上させたい。
何をするべきでしょうか?
- A. トレーニング データセットのサイズを増やし、入力フィーチャの数を増やします。
- B. トレーニング データセットのサイズを増やし、入力フィーチャの数を減らします。
- C. トレーニング データセットのサイズを縮小し、入力フィーチャの数を増やします。
- D. トレーニング データセットのサイズを縮小し、入力フィーチャの数を減らします。
Answer: B
Question 192
あなたはチャットボットを実装して、オンライン小売業者が顧客サービスを合理化できるようにしています。
チャットボットは、テキストと音声の両方の問い合わせに応答できる必要があります。ローコードまたはノーケードのオプションを探しており、チャットボットを簡単にトレーニングしてキーワードへの回答を提供できるようにしたいと考えています。
何をするべきでしょうか?
- A. Cloud Speech-to-Text API を使用して App Engine で Python アプリケーションを構築します。
- B. Cloud Speech-to-Text API を使用して Compute Engine インスタンスで Python アプリケーションを構築します。
- C. 単純なクエリには Dialogflow を使用し、複雑なクエリには Cloud Speech-to-Text API を使用します。
- D. Dialogflow を使用してチャットボットを実装し、収集された最も一般的なクエリに基づいてインテントを定義します。
Answer: D
Question 193
ある航空宇宙企業は、独自のデータ形式を使用して飛行データを保存しています。
この新しいデータ ソースを BigQuery に接続し、データを BigQuery にストリーミングする必要があります。消費するリソースをできるだけ少なくしながら、効率的にデータを BigQuery にインポートしたいと考えています。
何をするべきでしょうか?
- A. 新しいデータ ソースで定期的な ETL バッチ ジョブを実行する Cloud Functions をトリガーするシェル スクリプトを作成します。
- B. 標準の Dataflow パイプラインを使用して生データを BigQuery に保存し、後でデータを使用するときに形式を変換します。
- C. Apache Hive を使用して、データを CSV 形式で BigQuery にストリーミングする Dataproc ジョブを作成します。
- D. Apache Beam カスタム コネクタを使用して、データを Avro 形式で BigQuery にストリーミングする Dataflow パイプラインを作成します。
Answer: D
Question 194
オンライン証券会社には、大量の取引処理アーキテクチャが必要です。
ジョブをトリガーする安全なキューイング システムを作成する必要があります。ジョブは Google Cloud で実行され、会社の Python API を呼び出して取引を実行します。ソリューションを効率的に実装する必要があります。
何をするべきでしょうか?
- A. Pub/Sub の push サブスクリプションを使用して Cloud Functions をトリガーし、データを Python API に渡します。
- B. Pub/Sub トピックへの push サブスクリプションを作成する Compute Engine インスタンスでホストされるアプリケーションを作成します。
- C. NoSQL データベースにキューを作成するアプリケーションを作成します。
- D. Cloud Composer を使用して Pub/Sub トピックにサブスクライブし、Python API を呼び出します。
Answer: A
Question 195
あなたの会社は、データベースに 10 TB を超える現在のシステムから医療情報の大量の結果セットを取得し、そのデータを新しいテーブルに保存して、さらにクエリを実行できるようにしたいと考えています。
データベースはメンテナンスの少ないアーキテクチャで、SQL 経由でアクセスできる必要があります。大規模な結果セットのデータ分析をサポートできる費用対効果の高いソリューションを実装する必要があります。
何をするべきでしょうか?
- A. Cloud SQL を使用しますが最初にデータをテーブルに整理します。クエリで JOIN を使用してデータを取得します。
- B. BigQuery をデータ ウェアハウスとして使用します。大きなクエリをキャッシュするための出力先を設定します。
- C. スケーラビリティのために Compute Engine マネージド インスタンス グループにインストールされた MySQL クラスタを使用します。
- D. Cloud Spanner を使用してリージョン間でデータを複製します。一連のテーブルのデータを正規化します。
Answer: B
Question 196
オンプレミス データセンターに 15 TB のデータがあり、Google Cloud に転送したいと考えています。
データは毎週変更され、POSIX 準拠のソースに保存されます。ネットワーク運用チームは、公共のインターネットに 500 Mbps の帯域幅を許可しました。Google が推奨する方法に従って、週単位で確実にデータを Google Cloud に転送したいと考えています。
何をするべきでしょうか?
- A. Cloud Scheduler を使用して gsutil コマンドをトリガーします。並列処理を最適化するには、-m パラメーターを使用します。
- B. Transfer Appliance を使用してデータを Google Kubernetes Engine クラスタに移行し、毎週の転送ジョブを構成します。
- C. データ センターにオンプレミス データ用の Storage Transfer Service をインストールし、毎週の転送ジョブを構成します。
- D. Google Cloud 仮想マシンにオンプレミス データ用の Storage Transfer Service をインストールし、毎週の転送ジョブを構成します。
Answer: C
Question 197
ACID 準拠のデータベースを必要とするシステムを設計しています。
障害が発生した場合にシステムが最小限の人間の介入しか必要としないことを確認する必要があります。
何をするべきでしょうか?
- A. ポイントインタイム リカバリを有効にして Cloud SQL for MySQL インスタンスを構成します。
- B. 高可用性を有効にして Cloud SQL for PostgreSQL インスタンスを構成します。
- C. 複数のクラスタで Cloud Bigtable インスタンスを構成します。
- D. マルチリージョン構成で BigQuery テーブルを構成します。
Answer: B
Question 198
オープンソース ベースのツールと Google Kubernetes Engine (GKE) を使用して、ワークフロー パイプラインのスケジューリングを実装しています。
タスクを簡素化および自動化するために Google マネージド サービスを使用したいと考えています。また、共有 VPC ネットワークの考慮事項にも対応する必要があります。
何をするべきでしょうか?
- A. ワークフロー パイプラインに Dataflow を使用します。スケジューリングには Cloud Run トリガーを使用します。
- B. ワークフロー パイプラインに Dataflow を使用します。シェル スクリプトを使用してワークフローをスケジュールします。
- C. 共有 VPC 構成で Cloud Composer を使用します。ホスト プロジェクトに Cloud Composer リソースを配置します。
- D. 共有 VPC 構成で Cloud Composer を使用します。サービス プロジェクトに Cloud Composer リソースを配置します。
Answer: D
Question 199
あなたは BigQuery とデータポータルを使用して、大量の集計データを表示する顧客向けのダッシュボードを設計しています。
大量の同時ユーザーが予想されます。ダッシュボードを最適化して、待ち時間を最小限に抑えて迅速な視覚化を提供する必要があります。
何をするべきでしょうか?
- A. マテリアライズド ビューで BigQuery BI Engine を使用します。
- B. 論理ビューで BigQuery BI Engine を使用します。
- C. ストリーミング データで BigQuery BI Engine を使用します。
- D. 承認済みビューで BigQuery BI Engine を使用します。
Answer: A
Question 200
銀行業界における政府の規制により、顧客の個人を特定できる情報 (PII) の保護が義務付けられています。
あなたの会社では PII がアクセス制御され、暗号化され、主要なデータ保護基準に準拠している必要があります。Cloud Data Loss Prevention (Cloud DLP) を使用することに加えて、Google が推奨するプラクティスに従い、サービス アカウントを使用して PII へのアクセスを制御する必要があります。
何をするべきでしょうか?
- A. 必要な Identity and Access Management (IAM) ロールをすべての従業員に割り当て、プロジェクト リソースにアクセスするための単一のサービス アカウントを作成します。
- B. 1 つのサービス アカウントを使用して Cloud SQL データベースにアクセスし、ユーザーごとに個別のサービス アカウントを使用します。
- C. Cloud Storage を使用して主要なデータ保護基準に準拠します。すべてのユーザーが共有する 1 つのサービス アカウントを使用します。
- D. Cloud Storage を使用して主要なデータ保護基準に準拠します。IAM グループにアタッチされた複数のサービス アカウントを使用して、各グループに適切なアクセス権を付与します。
Answer: A
Question 201
Redis データベースをオンプレミス データセンターから Memorystore for Redis インスタンスに移行する必要があります。
Google が推奨する方法に従い、最小限のコスト、時間、労力で移行を実行したいと考えています。
何をするべきでしょうか?
- A. Redis データベースの RDB バックアップを作成し、gsutil ユーティリティを使用して RDB ファイルを Cloud Storage バケットにコピーしてから RDB ファイルを Memorystore for Redis インスタンスにインポートします。
- B. Compute Engine インスタンスで Redis データベースのセカンダリ インスタンスを作成し、ライブ カットオーバーを実行します。
- C. Dataflow ジョブを作成して、オンプレミス データセンターから Redis データベースを読み取り、そのデータを Memorystore for Redis インスタンスに書き込みます。
- D. シェル スクリプトを作成して Redis データを移行し、新しい Memorystore for Redis インスタンスを作成します。
Answer: A
Question 202
オンプレミス環境のプラットフォームは、毎日 100 GB のデータを生成します。このデータは、何百万もの構造化された JSON テキスト ファイルで構成されています。
パブリック インターネットからオンプレミス環境にアクセスできません。Google Cloud プロダクトを使用して、プラットフォーム データのクエリと調査を行いたい。
何をするべきでしょうか?
- A. Cloud Scheduler を使用してオンプレミス環境から Cloud Storage にデータを毎日コピーします。BigQuery Data Transfer Service を使用してデータを BigQuery にインポートします。
- B. Transfer Appliance を使用してオンプレミス環境から Cloud Storage にデータをコピーします。BigQuery Data Transfer Service を使用してデータを BigQuery にインポートします。
- C. オンプレミス データの Transfer Service を使用してオンプレミス環境から Cloud Storage にデータをコピーします。BigQuery Data Transfer Service を使用してデータを BigQuery にインポートします。
- D. BigQuery Data Transfer Service データセット コピーを使用してすべてのデータを BigQuery に転送します。
Answer: C
Question 203
Compute Engine 仮想マシン (n2-standard-32) 上の TensorFlow 機械学習モデルは、トレーニングを完了するのに 2 日かかります。
モデルには、CPU 上で部分的に実行する必要があるカスタム TensorFlow 操作があります。費用対効果の高い方法でトレーニング時間を短縮したいと考えています。
何をするべきでしょうか?
- A. VM タイプを n2-highmem-32 に変更します。
- B. VM タイプを e2-standard-32 に変更します。
- C. GPU ハードウェア アクセラレータを備えた VM を使用してモデルをトレーニングします。
- D. TPU ハードウェア アクセラレータを備えた VM を使用してモデルをトレーニングします。
Answer: C
Question 204
BigQuery ML を使用して機械学習モデルを作成し、Vertex AI を使用してモデルをホストするためのエンドポイントを作成したいと考えています。
これにより、複数のベンダーからの連続ストリーミング データをほぼリアルタイムで処理できるようになります。データに無効な値が含まれている可能性があります。
何をするべきでしょうか?
- A. 新しい BigQuery データセットを作成し、ストリーミング挿入を使用して複数のベンダーからデータを取得します。「取り込み」データセットをフレーミング データとして使用するように BigQuery ML モデルを構成します。
- B. BigQuery ストリーミング挿入を使用して、BigQuery データセット ML モデルがデプロイされている複数のベンダーからデータを取得します。
- C. Pub/Sub トピックを作成し、すべてのベンダー データをそれに送信します。Cloud Functions をトピックに接続してデータを処理し、BigQuery に保存します。
- D. Pub/Sub トピックを作成し、すべてのベンダー データをそれに送信します。Dataflow を使用して Pub/Sub データを処理およびサニタイズし、BigQuery にストリーミングします。
Answer: D
Question 205
Google Kubernetes Engine (GKE) で実行されるデータ処理アプリケーションがあります。
コンテナーは、コンテナー レジストリから利用可能な最新の構成で起動する必要があります。GKE ノードには、GPU、ローカル SSD、8 Gbps 帯域幅が必要です。データ処理インフラストラクチャを効率的にプロビジョニングし、展開プロセスを管理したいと考えています。
何をするべきでしょうか?
- A. Compute Engine 起動スクリプトを使用してコンテナ イメージを pull し、gcloud コマンドを使用してインフラストラクチャをプロビジョニングします。
- B. Cloud Build を使用して Terraform ビルドを使用してジョブをスケジュールし、インフラストラクチャをプロビジョニングして、最新のコンテナ イメージで起動します。
- C. GKE を使用してコンテナを自動スケーリングし、gcloud コマンドを使用してインフラストラクチャをプロビジョニングします。
- D. Dataflow を使用してデータ パイプラインをプロビジョニングし、Cloud Scheduler を使用してジョブを実行します。
Answer: B
Comments are closed