![[GCP] Google Cloud Certified - Professional Cloud Developer](https://www.cloudsmog.net/wp-content/uploads/google-cloud-certified_professional-cloud-developer-1.jpg)
Google Cloud 認定資格 – Professional Cloud Developer – 模擬問題集(全 255問)
Question 001
データ移行の一環として、オンプレミスの仮想マシンから Google Cloud Storage にファイルをアップロードしたいと考えています。
これらのファイルは GCP 環境の Dataproc Hadoop クラスタによって使用されます。
どのコマンドを使用するべきですか?
- A. gsutil cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
- B. gcloud cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
- C. hadoop fs cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
- D. gcloud dataproc cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
Answer: A
gsutil cp コマンドはローカルファイル間のデータのコピーを可能にします。ストレージ。”gsutil config” の実行によって生成される boto ファイル。
Question 002
Google Cloud Platformにアプリケーションを移行し、既存の監視プラットフォームはそのまま使用しています。
今、通知システムが重要な問題に対して遅すぎることに気づきました。
どうしたらいいでしょうか?
- A. モニタリング プラットフォーム全体を Stackdriver に置き換えます。
- B. Compute Engine インスタンスに Stackdriver エージェントをインストールします。
- C. Stackdriver を使用してログをキャプチャしてアラートを出し、既存のプラットフォームに送信します。
- D. 一部のトラフィックを古いプラットフォームに戻し、2 つのプラットフォームで同時に AB テストを実行します。
Answer: A
Reference:
– Cloud Monitoring | Google Cloud
Question 003
MySQL データベースを Google Cloud のマネージド Cloud SQL データベースに移行することを計画しています。
この Cloud SQL インスタンスに接続する Compute Engine 仮想マシン インスタンスがあります。Cloud SQL にアクセスできるようにするために Compute Engine インスタンスの IP をホワイトリストに登録したくありません。
どうすればいいのでしょうか?
- A. Cloud SQL インスタンスのプライベート IP を有効にします。
- B. プロジェクトをホワイトリストに登録して Cloud SQL にアクセスし、ホワイトリストに登録されたプロジェクトに Compute Engine インスタンスを追加します。
- C. 外部インスタンスからデータベースへのアクセスを許可する役割を Cloud SQL で作成し、Compute Engine インスタンスをその役割に割り当てます。
- D. 1 つのプロジェクトで CloudSQL インスタンスを作成します。別のプロジェクトで Compute Engine インスタンスを作成します。これら 2 つのプロジェクト間に VPN を作成して、Cloud SQL への内部アクセスを許可します。
Answer: A
Reference:
– Cloud SQL 接続について | Cloud SQL for MySQL | Google Cloud
Question 004
gcloud コマンドで HTTP (S) ロードバランサをデプロイしています。
export NAME-load-balancer
#create network
gcloud compute networks create $(NAME}
#add instance.
gcloud compute instances create $ (NAME)-backend-instance-1 --subnet $(NAME -no address
# create the instance group
gcloud compute instance-groups unmanaged create ${NAME}-i
gcloud compute instance-groups unmanaged set-named-ports ${NAME}-i -named-ports http:80
gcloud compute instance-groups unmanaged add-instances $(NAME)-i-instances $(NAME)-instance-1
#configure health checks
gcloud compute health-checks create http $(NAME)-http-hc --port 80
# create backend service
gcloud compute backend-services create $(NAME)-http-bes --health-checks ${NAME}-http-hc --protocol HTTP --port-name http --global
gcloud compute backend-services add-backend $(NAME)-http-bes --instance-group $(NAME)-i-balancing-mode RATE --max-rate 100000 --capacity-scaler 1.0-global-instance-group-zone us-east1-d
# create urls maps and forwarding rule
gcloud compute url-maps create $(NAME)-http-urlmap --default-service ${NAME}-http-bes
gcloud compute target-http-proxies create $(NAME)-http-proxy --url-map $(NAME)-http-urlmap
gcloud compute forwarding-rules create $(NAME)-http-fw --global-ip-protocol ICP --target-http-proxy ${NAME}-http-proxy
-ports 80Compute Engine 仮想マシン インスタンスのポート 80 へのヘルス チェックが失敗し、インスタンスにトラフィックが送信されません。この問題を解決したいと思っています。
どのコマンドを実行するべきでしょうか?
- A. gcloud compute instances add-access-config ${NAME}-backend-instance-1
- B. gcloud compute instances add-tags ${NAME}-backend-instance-1 –tags http-server
- C. gcloud compute firewall-rules create allow-lb –network load-balancer –allow tcp –source-ranges 130.211.0.0/22,35.191.0.0/16 –direction INGRESS
- D. gcloud compute firewall-rules create allow-lb –network load-balancer –allow tcp –destination-ranges 130.211.0.0/22,35.191.0.0/16 –direction EGRESS
Answer: C
Reference:
– ネットワーキング ユースケース用に VM を構成する | VPC | Google Cloud
Question 005
Web サイトは Compute Engine にデプロイされています。
マーケティング チームは 3つの異なる Web サイトデザイン間のコンバージョン率をテストしたいと考えています。
どのアプローチを使用するべきでしょうか?
- A. App Engine に Web サイトをデプロイし、トラフィック分割を使用します。
- B. App Engine に Web サイトを 3つの独立したサービスとしてデプロイします。
- C. Cloud Functions に Web サイトをデプロイし、トラフィック分割を使用します。
- D. Cloud Functions に Web サイトを 3つの独立したサービスとしてデプロイします。
Answer: A
Reference:
– トラフィックの分割 | Python 2 の App Engine スタンダード環境 | Google Cloud
Question 006
ディレクトリ local-scripts とそのすべてのコンテンツをローカル ワークステーションから Compute Engine 仮想マシン インスタンスにコピーする必要があります。
どのコマンドを使用するべきでしょうか?
- A. gsutil cp –project my-gcp-project -r ~/local-scripts/ gcp-instance-name:~/server-scripts/ –zone us-east1-b
- B. gsutil cp –project my-gcp-project -R ~/local-scripts/ gcp-instance-name:~/server-scripts/ –zone us-east1-b
- C. gcloud compute scp –project my-gcp-project –recurse ~/local-scripts/ gcp-instance-name:~/server-scripts/ –zone us-east1-b
- D. gcloud compute mv –project my-gcp-project –recurse ~/local-scripts/ gcp-instance-name:~/server-scripts/ –zone us-east1-b
Answer: C
Reference:
– gcloud compute copy-files | Google Cloud CLI Documentation
Question 007
Stackdriver Monitoring Agent がインストールされた Compute Engine 仮想マシン インスタンスにアプリケーションをデプロイしています。
アプリケーションはインスタンス上の UNIX プロセスです。UNIX プロセスが少なくとも 5 分間実行されていない場合にアラートを受け取る必要があります。アプリケーションを変更してメトリックまたはログを生成することはできません。
どのアラート条件を構成する必要がありますか?
- A. Uptime check
- B. Process health
- C. Metric absence
- D. Metric threshold
Answer: B
Reference:
– 指標ベースのアラート ポリシーの動作 | Cloud Monitoring | Google Cloud
Question 008
ANSI-SQL 準拠のデータベースで同一のカラムを持つ 2 つのテーブルがあり、迅速に 1 つのテーブルに統合し、結果セットから重複する行を削除する必要があります。
どうすればよいでしょうか?
- A. SQL で JOIN 演算子を使用してテーブルを結合します。
- B. ネストされた WITH 文を使用してテーブルを結合します。
- C. SQL で UNION 演算子を使用してテーブルを結合します。
- D. SQL で UNION ALL 演算子を使用してテーブルを結合します。
Answer: C
Reference:
– SQL: UNION ALL Operator
Question 009
本番環境にデプロイされたアプリケーションがあります。
新しいバージョンがデプロイされると、アプリケーションが運用環境のユーザーからトラフィックを受信するまで、いくつかの問題は発生しません。影響と影響を受けるユーザーの数の両方を減らしたいと考えています。
どのデプロイメント戦略を使うべきでしょうか?
- A. Blue/Green デプロイ戦略
- B. カナリア テスト戦略
- C. ローリング アップデート デプロイ戦略
- D. 再作成 デプロイ戦略
Answer: B
Reference:
– GKE でのデプロイとテストの戦略の実装 | Cloud アーキテクチャ センター | Google Cloud
– アプリケーションのデプロイとテストの戦略 | Cloud アーキテクチャ センター | Google Cloud
– Six Strategies for Application Deployment – The New Stack
Question 010
会社は 人気のあるアプリケーションのユーザーを米国外に拡大したいと考えています。
アプリケーションのデータベースの 99.999% の可用性を確保し、世界中のユーザーの読み取り待ち時間を最小限に抑えたいと考えています。
どのアクションを実行する必要がありますか? (回答は 2つ)
- A. 「nam-eur-asia1」構成のマルチリージョンの Cloud Spanner インスタンスを作成します。
- B. 「nam3」構成でマルチリージョンの Cloud Spanner インスタンスを作成する。
- C. 少なくとも 3 つの Spanner ノードを持つクラスタを作成します。
- D. 少なくとも 1 つの Spanner ノードを持つクラスタを作成します。
- E. 少なくとも 1 つのノードを持つ別々のリージョンに、最低 2 つの Cloud Spanner インスタンスを作成します。
- F. 異なるデータベース間でデータを複製するために Cloud Dataflow パイプラインを作成します。
Answer: A、C
Question 011
500 MB のファイル サイズ制限が適用された内部ファイル アップロード API を App Engine に移行する必要があります。
何をするべきですか?
- A. FTP を使用してファイルをアップロードします。
- B. CPanel を使用してファイルをアップロードします。
- C. 署名付き URL を使用してファイルをアップロードします。
- D. API をマルチパート ファイル アップロード API に変更します。
Answer: C
Reference:
– Google Cloud Platform – Wikipedia
Question 012
アプリケーションを Google Kubernetes Engine (GKE) クラスタにデプロイする予定です。
アプリケーションは /healthz で HTTP ベースのヘルス チェックを公開します。このヘルス チェック エンドポイントを使用してロードバランサによってトラフィックを Pod にルーティングする必要があるかどうかを判断します。
Pod 構成に含める必要があるコード スニペットはどれでしょうか?
- A.
livenessProbe:
httpGet:
path: /healthz
port: 80 - B.
readinessProbe:
httpGet:
path: /healthz
port: 80 - C.
loadbalancerHealthCheck:
httpGet:
path: /healthz
port: 80 - D.
healthCheck:
httpGet:
path: /healthz
port: 80
Answer: B
GKE Ingress コントローラーが readinessProbes をヘルスチェックとして使用するためには Ingressの作成時に Ingress 用の Pod が存在する必要があります。レプリカが 0 にスケールされている場合、デフォルトのヘルスチェックが適用されます。
Question 013
チームメイトから次のコードを確認するように依頼されました。
BigQuery service = BigQueryOptions.newBuilder().build().getService();
public void writeToBigQuery (Collection<Map<String, String>> rows){
for (Map<String, String> row: rows) {
InsertAllRequest insertRequest = InsertAllRequest.newBuilder (
"datasetId", "tableId",
InsertAllRequest.RowToInsert. of (row)) .build();
service.insertAll (insertRequest);
}
}その目的は多数の小さな行を BigQuery テーブルに効率的に追加することです。
チームメイトにどのような改善を提案しますか?
- A. 各リクエストに複数の行を含めます。
- B. 複数のスレッドを作成し、挿入を並列に実行します。
- C. 各行を Cloud Storage オブジェクトに書き出し、BigQuery に読み込みます。
- D. 各行を並行して Cloud Storage オブジェクトに書き込み、BigQuery に読み込みます。
Answer: A
Question 014
Google Kubernetes Engine (GKE) でホストされる JPEG 画像リサイズ API を開発しています。
サービスの呼び出し元は同じ GKE クラスタ内に存在します。クライアントがサービスの IP アドレスを取得できるようにしたいと思います。
何をすべきでしょうか?
- A. GKE サービスを定義します。クライアントは Cloud DNS の A レコードの名前を使用してサービスのクラスタ IP アドレスを検索する必要があります。
- B. GKE サービスを定義します。クライアントは URL のサービス名を使用してサービスに接続する必要があります。
- C. GKE エンドポイントを定義します。クライアントはクライアント コンテナ内の適切な環境変数からエンドポイント名を取得する必要があります。
- D. GKE エンドポイントを定義します。クライアントは Cloud DNS からエンドポイント名を取得する必要があります。
Answer: B
Question 015
Cloud Build を使用して Cloud Source Repositories に保存されているアプリケーション ソースコードをビルドおよびテストしています。
ビルド プロセスには Cloud Build 環境では使用できないビルド ツールが必要です。
何をするべきでしょうか?
- A. ビルド中にインターネットからバイナリをダウンロードします。
- B. カスタム クラウドビルダーイメージを構築し、ビルド手順の中でそのイメージを参照します。
- C. バイナリを Cloud Source Repositories のリポジトリに含め、ビルドスクリプトで参照します。
- D. Cloud Build パブリック問題追跡システムに機能リクエストを提出し、Cloud Build 環境にバイナリを追加するよう依頼します。
Answer: B
Question 016
Compute Engine の仮想マシンインスタンスにアプリケーションをデプロイしています。
アプリケーションはログファイルをディスクに書き込むように構成されています。アプリケーションコードを変更せずにStackdriver Loggingでログを表示したいと考えています。
何をするべきでしょうか?
- A. Stackdriver Logging エージェントをインストールし、アプリケーション ログを送信するように構成します。
- B. Stackdriver Logging ライブラリを使用し、アプリケーションから Stackdriver Logging に直接ログを記録します。
- C. インスタンスのメタ データにログ ファイル フォルダ パスを指定し、アプリケーション ログを送信するように構成します。
- D. ログが Stackdriver Logging に自動的に送信されるように、/var/log にログを記録するようにアプリケーションを変更します。
Answer: A
Question 017
サービスは Cloud Storage から読み込んだ画像にテキストを追加します。
混雑する時期には Cloud Storage へのリクエストは HTTP 429 の「Too Many Requests」ステータスコードで失敗します。
このエラーはどのように処理すればよいでしょうか?
- A. オブジェクトに cache-control ヘッダーを追加します。
- B. Google Cloud Console から割り当ての増加をリクエストします。
- C. 切り捨てられた指数バックオフ戦略でリクエストを再試行します。
- D. Cloud Storage バケットのストレージ クラスをマルチリージョンに変更します。
Answer: C
Reference:
– 使用量上限 | Gmail | Google Developers
Question 018
Android / iOS アプリで使用される API を構築しています。
API は次のことを行う必要があります。
– HTTPs をサポート
– 帯域幅のコストを最小限に抑える
– モバイルアプリと簡単に統合
どの API アーキテクチャを使用しますか?
- A. RESTful APIs
- B. MQTT for APIs
- C. gRPC-based APIs
- D. SOAP-based APIs
Answer: C
Reference:
– How to Build a REST API for Mobile App? – DevTeam.Space
Question 019
アプリケーションはユーザーからの入力を受け取り、それをユーザーの連絡先に公開します。
この入力は Cloud Spanner のテーブルに保存されます。アプリケーションはレイテンシーに対してより敏感であり、一貫性に対してより敏感ではありません。
このアプリケーションの Cloud Spanner からの読み取りをどのように実行する必要がありますか?
- A. 読み取り専用トランザクションを実行します。
- B. 単一読み取り方式を使用して古い読み取りを実行します。
- C. 単一読み取り方法を使用して強力な読み取りを実行します。
- D. 読み書きトランザクションを使用して古い読み取りを実行します。
Answer: B
Reference:
– ゲーム データベースとして Cloud Spanner を使用する場合のベスト プラクティス | Cloud アーキテクチャ センター | Google Cloud
Question 020
アプリケーションは Google Kubernetes Engine (GKE) クラスタにデプロイされています。
アプリケーションの新しいバージョンがリリースされると CI / CD ツールはspec.template.spec.containers[0].image 値を更新して新しいアプリケーション バージョンの Docker イメージを参照します。Deployment オブジェクトが変更を適用するとき、新しいバージョンの少なくとも 1 つのレプリカをデプロイし、新しいレプリカが健全になるまで以前のレプリカを維持したいと思います。
以下に示す GKE Deployment オブジェクトにどのような変更を加えるべきですか?
apiVersion: apps/v1
kind: Deployment
metadata:
name: ecommerce-frontend-deployme
spec:
replicas: 3
selector:
matchLabels:
app: ecommerce-frontend
template:
metadata:
labels:
app: ecommerce-frontend
spec:
containers
name: ecommerce-frontend-webapp
image: ecommerce-frontend-webapp:1.7.9
ports:
containerPort: 80- A. デプロイメント戦略を RollingUpdate に設定し、maxSurge を 0 に、maxUnavailable を 1 に設定する。
- B. デプロイメント戦略を RollingUpdate に設定し、maxSurge を 1、maxUnavailable を 0 に設定します。
- C. デプロイメント戦略を Recreate に設定し、maxSurge を 0 に、maxUnavailable を 1 に設定します。
- D. デプロイメント戦略を Recreate に設定し、maxSurge を 1、maxUnavailable を 0 に設定します。
Answer: B
Question 021
簡単な HTML アプリケーションをインターネット上で公開することを計画しています。
このサイトにはアプリケーションの FAQ に関する情報が保存されています。アプリケーションは静的で画像、HTML、CSS、Javascript が含まれています。できるだけ少ない手順でこのアプリケーションをインターネット上で利用できるようにしたいと考えています。
どうすればいいでしょうか?
- A. アプリケーションを Cloud Storage にアップロードします。
- B. App Engine 環境にアプリケーションをアップロードする。
- C. Apache Web サーバがインストールされた Compute Engine インスタンスを作成します。アプリケーションをホストする Apache Web サーバを設定します。
- D. 最初にアプリケーションをコンテナ化します。このコンテナを Google Kubernetes Engine (GKE) にデプロイし、アプリケーションをホストする GKE Pod に外部 IP アドレスを割り当てます。
Answer: A
Reference:
– 静的ウェブサイトをホストする | Cloud Storage | Google Cloud
Question 022
会社は新しい API を App Engine スタンダード環境にデプロイしました。
テスト中に API が期待どおりに動作しませんでした。アプリケーションを再デプロイせず、アプリケーション コード内の問題を診断するために長期にわたってアプリケーションを監視する必要があります。
どのツールを使用するべきでしょうか?
- A. Stackdriver Trace
- B. Stackdriver Monitoring
- C. Stackdriver Debug Snapshots
- D. Stackdriver Debug Logpoints
Answer: D
Reference:
– GCP Stackdriver Tutorial : Debug Snapshots, Traces, Logging and Logpoints | by Romin Irani
Question 023
Stackdriver Logging エージェントを使用し、Compute Engine 仮想マシンインスタンスから Stackdriver にアプリケーションのログファイルを送信したいと思います。
Stackdriver Logging エージェントをインストールした後、最初に何をするべきでしょうか?
- A. プロジェクトで Error Reporting API を有効化します。
- B. インスタンスすべての Cloud API へのフルアクセスを許可します。
- C. アプリケーションのログ ファイルをカスタムソースとして構成する。
- D. アプリケーションのログ エントリに一致するフィルタを持つ Stackdriver Logs シンクのエクスポートを作成します。
Answer: C
Question 024
会社には数百人の従業員に分析情報を提供する BigQuery データマートがあります。
とあるユーザーは重要なワークロードを中断することなくジョブを実行したいと考えています。このユーザーはこれらのジョブの実行にかかる時間については気にしていません。会社のコストと自分の労力を最小限に抑えながら、この要求を満たしたいと考えています。
どうすればいいのでしょうか?
- A. ジョブをバッチ ジョブとして実行するようユーザーに依頼します。
- B. ユーザーがジョブを実行するための別のプロジェクトを作成します。
- C. 既存のプロジェクトにユーザーを job.user ロールとして追加します。
- D. 重要なワークロードが実行されていないときにユーザーがジョブを実行できるようにします。
Answer: A
Question 025
開発時間を最小限に抑えながら、本番環境でのサービスの低下についてオンコール エンジニアに通知したいと考えています。
どうするべきでしょうか?
- A. Cloud Functions を使用してリソースを監視し、アラートを生成します。
- B. Cloud Pub/Sub を使用してリソースを監視し、アラートを生成します。
- C. Stackdriver Error Reporting を使用してエラーをキャプチャし、アラートを生成します。
- D. Stackdriver Monitoring を使用してリソースを監視し、アラートを生成します。
Answer: D
Question 026
XMLHttpRequest を使用してコンテンツのためにサードパーティ API と通信するユーザー インターフェース (UI) を持つ単一ページの Web アプリケーションを作成しています。
API の結果によって UI に表示されるデータは同じ Web ページに表示される他のデータよりも重要度が低いため、リクエストによっては API のデータが UI に表示されないことも許容されます。しかし、API への呼び出しによってユーザー インターフェースの他の部分のレンダリングが遅れることがあってはなりません。API レスポンスがエラーやタイムアウトの場合でもアプリケーションのパフォーマンスを向上させたいと考えています。
どうすればいいのでしょうか?
- A. API へのリクエストの非同期オプションを false に設定し、タイムアウトまたはエラーが発生したときに API の結果を表示するウィジェットを省略します。
- B. API へのリクエストの非同期オプションを true に設定し、タイムアウトまたはエラーが発生したときに API の結果を表示するウィジェットを省略します。
- C. API 呼び出しからタイムアウトまたはエラー例外をキャッチし、API レスポンスが成功するまで指数バックオフを試行し続けます。
- D. API 呼び出しからタイムアウトまたはエラー例外をキャッチし、UI ウィジェットにエラーレスポンスを表示します。
Answer: B
Question 027
Compute Engine インスタンスで実行し、任意のユーザーの Google ドライブにファイルを書き込む Web アプリケーションを作成しています。
Google ドライブ API に認証するためにアプリケーションを構成する必要があります。
どうすればいいでしょうか?
- A. https://www.googleapis.com/auth/drive.file スコープを使用する OAuth クライアント ID を使用し、各ユーザーのアクセストークンを取得します。
- B. ドメイン全体の権限を委譲された OAuth クライアント ID を使用します。
- C. App Engine サービスアカウントと https://www.googleapis.com/auth/drive.file スコープを使用し、署名付き JSON Web Token (JWT) を生成します。
- D. ドメイン全体の権限を委譲された App Engine のサービスアカウントを使用します。
Answer: A
Reference:
– API 固有の承認および認証情報 | Google Drive | Google Developers
Question 028
Google Kubernetes Engine (GKE) クラスタを作成し、次のコマンドを実行します。
> gcloud container clusters create large-cluster --num-nodes 200コマンドは次のエラーで失敗します。
insufficient regional quota to satisfy request: resource “CPUS”: request requires ‘200.0’ and is short ‘176.0’ project has quota of ‘24.0’ with ‘24.0’ availableこのエラー問題を解決するために何をするべきでしょうか?
- A. Google Cloud Console で追加の GKE 割り当てをリクエストします。
- B. Google Cloud Console で追加の Compute Engine 割り当てをリクエストします。
- C. サポート ケースを開いて、追加の GKE 割り当てをリクエストする。
- D. クラスタ内のサービスを分離し、より少ないコア数で機能するように新しいクラスタを書き換えます。
Answer: B
Question 029
タイムスタンプ、口座番号 (文字列)、取引金額 (数値) という 3 つの列を含むログ ファイルを解析しています。
一意の口座番号ごとにすべての取引金額の合計を効率的に計算したいと考えています。
どのデータ構造を使うべきでしょうか?
- A. リンクされたリスト
- B. ハッシュテーブル
- C. 2 次元配列
- D. コンマ区切りの文字列
Answer: B
Question 030
会社には従業員の出張や経費に関する情報を保持する「Master」という名前の BigQuery データセットがあります。
このデータセットは従業員の部署ごとに整理されています。つまり、従業員は自分の部門の情報のみを表示できる必要があります。セキュリティ フレームワークを適用して最小限の手順でこの要件を適用したいと考えています。
どうすればいいでしょうか?
- A. 部門ごとに個別のデータセットを作成します。特定の部門の特定のデータセットからレコードを選択するには適切な WHERE 句を使用してビューを作成します。マスター データセットのレコードにアクセスするには、このビューを承認してください。この部門固有のデータセットに対する権限を従業員に付与します。
- B. 部門ごとに個別のデータセットを作成します。部門ごとにデータ パイプラインを作成して、マスター データセットから部門の特定のデータセットに適切な情報をコピーします。この部門固有のデータセットに対する権限を従業員に付与します。
- C. マスター データセットという名前のデータセットを作成します。マスター データセットの部門ごとに個別のビューを作成します。部門の特定のビューへのアクセス権を従業員に付与します。
- D. マスター データセットという名前のデータセットを作成します。マスター データセットの部門ごとに個別のテーブルを作成します。部門の特定のテーブルへのアクセス権を従業員に付与します。
Answer: C
Question 031
実稼働中のアプリケーションがあります。
これはマネージド インスタンス グループによって制御される Compute Engine 仮想マシン インスタンスにデプロイされます。トラフィックは HTTP (S) ロードバランサを介してインスタンスにルーティングされ、ユーザーはアプリケーションにアクセスできません。アプリケーションが利用できない場合に警告する監視手法を実装したいと考えています。
どの技術を選択するべきでしょうか?
- A. スモークテスト
- B. Stackdriver の稼働時間チェック
- C. Cloud Load Balancing – ヘルスチェック
- D. マネージド インスタンス グループ – ヘルス チェック
Answer: B
Reference:
– Stackdriver Monitoring Automation Part 3: Uptime Checks | by Charles | Google Cloud – Community | Medium
Question 032
サーバ アプリケーションの負荷テストを行っています。
最初の 30 秒間で以前はアクティブでなかった Cloud Storage バケットが 2,000 件/秒の書き込みリクエストと 7,500 件/秒の読み取りリクエストに対応していることを確認しました。リクエストが増大するにつれて、アプリケーションは Cloud Storage JSON API から断続的に 5xx と 429 の HTTP レスポンスを受け取るようになりました。Cloud Storage API からの失敗した応答を減少させたいと考えています。
どうすればよいでしょうか?
- A. 多数の個々の Cloud Storage バケットにアップロードを分散します。
- B. Cloud Storage とのインターフェースに JSON API の代わりに XML API を使用します。
- C. アプリケーションからアップロードを呼び出しているクライアントに HTTP レスポンスコードを返します。
- D. アプリケーション クライアントからのアップロード速度を制限し、休止中のバケットのピーク リクエスト レートに徐々に到達するようにします。
Answer: D
Reference:
– リクエスト レートとアクセス配信のガイドライン | Cloud Storage | Google Cloud
Question 033
アプリケーションはマネージド インスタンス グループによって制御されます。
マネージド インスタンス グループ内のすべてのインスタンス間で大規模な読み取り専用データセットを共有したいと考えています。各インスタンスが迅速に起動し、ファイル システムを介して非常に低いレイテンシーでデータセットにアクセスできるようにする必要があります。またソリューションの総コストを最小限に抑えたいと考えています。
どうすればいいでしょうか?
- A. データを Cloud Storage バケットに移動し、Cloud Storage FUSE を使用してバケットをファイル システムにマウントします。
- B. データを Cloud Storage バケットに移動し、起動スクリプトを使用してデータをインスタンスのブートディスクにコピーします。
- C. データを Compute Engine 永続ディスクに移動してそのディスクを読み取り専用モードで複数の Compute Engine 仮想マシン インスタンスに接続します。
- D. データを Compute Engine の永続ディスクに移動してスナップショットを作成し、スナップショットから複数のディスクを作成して各ディスクを独自のインスタンスに接続します。
Answer: C
Question 034
同じ Virtual Private Cloud (VPC) 内の複数のクライアントから呼び出される必要がある Compute Engine 仮想マシンインスタンス上でホストされる HTTP API を開発しています。
クライアントがサービスの IP アドレスを取得できるようにしたいです。
どうすればいいでしょうか?
- A. 静的な外部 IP アドレスを確保し、HTTP(S) ロードバランサ サービスの転送ルールに割り当てます。クライアントはこの IP アドレスを使用してサービスに接続する必要があります。
- B. 静的な外部 IP アドレスを確保し、HTTP(S) ロードバランサ サービスの転送ルールに割り当てる。その後、Cloud DNS で A レコードを定義します。クライアントは A レコードの名前を使用してサービスに接続する必要があります。
- C. https://[INSTANCE_NAME].[ZONE].c.[PROJECT_ID].internal/ という URL でインスタンス名に接続し、クライアントが Compute Engine 内部 DNS を使用することを確認します。
- D. クライアントが https://[API_NAME]/[API_VERSION]/ の URL でインスタンス名に接続することによって Compute Engine の内部 DNS を使用することを確認します。
Answer: C
Question 035
アプリケーションは Stackdriver にログを記録しています。
すべての /api/alpha/* エンドポイントですべてのリクエストの数を取得したいと考えています。
どうすればいいでしょうか?
- A. path:/api/alpha/ の Stackdriver カウンタ指標を追加します。
- B. エンドポイント: /api/alpha/* の Stackdriver カウンタ指標を追加します。
- C. ログを Cloud Storage にエクスポートし、/api/alpha に一致する行をカウントします。
- D. ログを Cloud Pub/Sub にエクスポートし、/api/alpha に一致する行をカウントします。
Answer: B
Question 036
マイクロサービス モデルに従うようにモノリシック アプリケーションを再構築したいと考えています。
この変更がビジネスに与える影響を最小限に抑えながら効率的に達成したいと考えています。
どのアプローチを取るべきでしょうか?
- A. アプリケーションを Compute Engine にデプロイし、自動スケーリングを有効にします。
- B. アプリケーションの機能を段階的に適切なマイクロサービスに置き換えます。
- C. 単一の作業で適切なマイクロサービスを使用してモノリシック アプリケーションをリファクタリングし、デプロイします。
- D. モノリスとは別の適切なマイクロサービスを使用して新しいアプリケーションを構築し、完成したら置き換えます。
Answer: B
Reference:
– モノリシック アプリケーションを Google Kubernetes Engine のマイクロサービスに移行する | Google Cloud への移行
Question 037
既存のアプリケーションはユーザー状態情報を単一の MySQL データベースに保持します。
この状態情報はユーザー固有であり、ユーザーがアプリケーションを使用している時間に大きく依存します。MySQL データベースはさまざまなユーザーのスキーマを維持および強化するという課題を引き起こしています。
どのストレージ オプションを選択すべきでしょうか?
- A. Cloud SQL
- B. Cloud Storage
- C. Cloud Spanner
- D. Cloud Datastore / Cloud Firestore
Answer: D
Reference:
– Database Migration Service | Google Cloud
Question 038
新しい API を構築しています。
画像の保存コストを最小限に抑え、画像提供の待ち時間を短縮したいと考えています。
どのアーキテクチャを使うべきでしょうか?
- A. Cloud Storage を基盤とする App Engine
- B. 永続ディスクに支えられた Compute Engine
- C. Cloud Filestore がサポートする Transfer Appliance
- D. Cloud Storage を基盤とする Cloud Content Delivery Network (CDN)
Answer: D
Question 039
開発チームはプロジェクトで Cloud Build を使用して Docker イメージを構築し、Container Registry にプッシュしたいと考えています。
運用チームが管理する一元化された安全に管理された Docker レジストリにすべての Docker イメージを公開する必要があります。
何をするべきでしょうか?
- A. Container Registry を使用し、各開発チームのプロジェクトにレジストリを作成します。Cloud Build ビルドを構成し、Docker イメージをプロジェクトのレジストリにプッシュします。各開発チームのレジストリへのアクセス権を運用チームに付与します。
- B. Container Registry が構成されている運用チーム用に別のプロジェクトを作成します。各デベロッパー チームのプロジェクトの Cloud Build サービス アカウントに適切な権限を割り当て、運用チームのレジストリへのアクセスを許可します。
- C. Container Registry が構成されている運用チーム用に別のプロジェクトを作成します。開発チームごとにサービス アカウントを作成して適切なアクセス許可を割り当て、運用チームのレジストリにアクセスできるようにします。サービス アカウント キー ファイルをソース コード リポジトリに保存し、運用チームのレジストリに対して認証するために使用します。
- D. Compute Engine 仮想マシン インスタンスにオープン ソースの Docker レジストリをデプロイする運用チーム用の別のプロジェクトを作成します。各開発チームのユーザー名とパスワードを作成します。ユーザー名とパスワードをソース コード リポジトリに保存し、運用チームの Docker レジストリに対して認証するために使用します。
Answer: B
Reference:
– Container Registry | Google Cloud
Question 040
アプリケーションを Google Kubernetes Engine (GKE) クラスタにデプロイする予定です。
アプリケーションは水平方向にスケーリングでき、アプリケーションの各インスタンスには安定したネットワーク ID と独自の永続ディスクが必要です。
どの GKE オブジェクトを使用するべきでしょうか?
- A. Deployment
- B. StatefulSet
- C. ReplicaSet
- D. ReplicaController
Answer: B
Reference:
– Chapter 10. StatefulSets: deploying replicated stateful applications – Kubernetes in Action
Question 041
Cloud Build を使用して Docker イメージを構築しています。
ビルドを変更してユニットを実行し、統合テストを実行する必要があります。障害が発生した場合、ビルド履歴にビルドが失敗した段階を明確に表示させたいと考えています。
どうすればいいでしょうか?
- A. Dockerfile に RUN コマンドを追加し、ユニットテストと統合テストを実行します。
- B. ユニットテストと統合テストをコンパイルするための単一のビルドステップを持つ Cloud Build ビルド設定ファイルを作成する。
- C. ユニットテストと統合テストのために別の Cloud Build パイプラインを生成する Cloud Build ビルド設定ファイルを作成します。
- D. ユニットテストと統合テストをコンパイルして実行するための別々の Cloud Build ステップを持つ Cloud Build ビルド構成ファイルを作成します。
Answer: D
Question 042
コードはプロジェクト A の Cloud Functions で実行されています。
プロジェクト B が所有する Cloud Storage バケットにオブジェクトを書き込むことになっていますが、書き込み呼び出しが「403 Forbidden」というエラーで失敗しています。
問題を解決するにはどうすればよいですか?
- A. ユーザーアカウントに Cloud Storage バケットの roles/storage.objectCreator のロールを付与します。
- B. ユーザーアカウントに service-PROJECTA@gcf-admin-robot.iam.gserviceaccount.com サービスアカウント用の roles/iam.serviceAccountUser のロールを付与します。
- C. service-PROJECTA@gcf-admin-robot.iam.gserviceaccount.com サービスアカウントに Cloud Storage バケットの roles/storage.objectCreator のロールを付与します。
- D. プロジェクト B で Cloud Storage API を有効化します。
Answer: C
Question 043
この問題は HipLocal のケーススタディを参照してください。
HipLocal の .net ベースの認証サービスは断続的な負荷で失敗します。
どうすればいいでしょうか?
- A. 自動スケーリングに App Engine を使用します。
- B. 自動スケーリングに Cloud Functions を使用します。
- C. サービスに Compute Engine クラスタを使用します。
- D. サービスに Compute Engine 仮想マシン インスタンスを使用します。
Answer: C
Reference:
– Autoscaling an Instance Group with Custom Cloud Monitoring Metrics
Question 044
この問題は HipLocal のケーススタディを参照してください。
HipLocal の API では時折アプリケーションに障害が発生しています。
この問題のトラブルシューティングのためにアプリケーション情報を特別に収集したいと考えています。
どうすればいいでしょうか?
- A. 仮想マシンのスナップショットを頻繁に作成します。
- B. Cloud Logging エージェントを仮想マシンにインストールします。
- C. Cloud Monitoring エージェントを仮想マシンにインストールします。
- D. Cloud Trace を使用してパフォーマンスのボトルネックを探します。
Answer: B
Question 045
この問題は HipLocal のケーススタディを参照してください。
HipLocal は永続ディスクに保存されたデータを照会するために Cloud Interconnect を使用して Hadoop インフラを GCP に接続しています。
どの IP 戦略を使うべきでしょうか?
- A. 手動でサブネットを作成します。
- B. オートモード サブネットを作成します。
- C. 複数のピアリング VPC を作成します。
- D. NAT 用に単一のインスタンスをプロビジョニングします。
Answer: A
Question 046
この問題は HipLocal のケーススタディを参照してください。
社内アプリへのアクセスを可能にするために HipLocal はどのサービスを利用すべきでしょうか?
- A. Cloud VPN
- B. Cloud Armor
- C. Virtual Private Cloud
- D. Cloud Identity-Aware Proxy
Answer: D
Reference:
– オンプレミス アプリの IAP の概要 | Identity-Aware Proxy | Google Cloud
Question 047
この問題は HipLocal のケーススタディを参照してください。
HipLocal はオンコールエンジニアの数を減らし、手作業によるスケーリングをなくしたいと考えています。
どのサービスを選択するべきでしょうか?(回答は 2 つ)
- A. Google App Engine サービスを使用します。
- B. サーバレスの Google Cloud Functions を使用します。
- C. Knative を使用してサーバレス アプリケーションを構築およびデプロイします。
- D. 自動デプロイに Google Kubernetes Engine を使用します。
- E. デプロイには大規模な Google Compute Engine クラスタを使用します。
Answer: C、D
Question 048
この問題は HipLocal のケーススタディを参照してください。
ビジネス要件を満たすために HipLocal はアプリケーションの状態をどのように保存する必要がありますか?
- A. ローカル SSD を使用してステートを保存します。
- B. MySQLの前に Memcached レイヤーを配置します。
- C. ステート ストレージを Cloud Spanner に移行します。
- D. MySQL インスタンスを Cloud SQL に置き換えます。
Answer: D
Question 049
この問題は HipLocal のケーススタディを参照してください。
HipLocal がパブリック API に使用する必要があるサービスはどれですか?
- A. Cloud Armor
- B. Cloud Functions
- C. Cloud Endpoints
- D. Shielded Virtual Machines
Answer: C
Question 050
この問題は HipLocal のケーススタディを参照してください。
HipLocal はビジネスと技術的な要件を満たしつつ、MySQL の耐障害性を向上させたいと考えています。
どのような構成を選択すればよいのでしょうか?
- A. Compute Engine の現在のシングル インスタンス MySQL と Compute Engine の複数の読み取り専用 MySQL サーバを使用します。
- B. Compute Engine で現在のシングル インスタンス MySQL を使用し、外部マスター構成で Cloud SQL にデータをレプリケートする。
- C. 現在のシングル インスタンスの MySQL インスタンスを Cloud SQL に置き換え、高可用性を構成します。
- D. 現在のシングル インスタンスの MySQL インスタンスを Cloud SQL に置き換えると、Google は追加の構成なしで冗長性を提供します。
Answer: C
Question 051
アプリケーションは複数の Google Kubernetes Engine クラスタで動作しています。
これらは各クラスタの Deployment によって管理され、各クラスタに Pod の複数のレプリカが作成されています。すべてのクラスタの Deployment のすべてのレプリカの stdout に送信されたログを表示したいと思います。
どのコマンドを使用するべきでしょうか?
- A. kubectl logs [PARAM]
- B. gcloud logging read [PARAM]
- C. kubectl exec “it [PARAM] journalctl
- D. gcloud compute ssh [PARAM] “-command= sudo journalctl
Answer: B
Question 052
Cloud Build を使用して Cloud Source Repositories リポジトリにコミットされた各ソースコードに新しい Docker イメージを作成しています。
アプリケーションはマスター ブランチへのコミットごとに構築されます。マスター ブランチに対して行われた特定のコミットを自動化された方法でリリースしたいと考えています。
何をするべきでしょうか?
- A. 新しいリリースのビルドを手動でトリガーします。
- B. Git タグ パターンでビルド トリガーを作成します。新しいリリースには Git タグ規則を使用します。
- C. Git ブランチ名パターンでビルド トリガーを作成します。新しいリリースには Git ブランチの命名規則を使用します。
- D. 2つ目の Cloud Build トリガーを使用し、ソースコードを 2 番目の Cloud Source Repositories リポジトリにコミットします。このリポジトリは新規リリースにのみ使用します。
Answer: B
Reference:
– Set up Automated Builds
Question 053
MySQL から Cloud Bigtable に移行されるテーブルのスキーマを設計しています。
MySQL のテーブルは以下の通りです。
AccountActivity
(
Account id int,
Event_timestamp datetime,
Transction_type string,
Amount numeric(18, 4)
) primary key (Account_id, Event_timestamp)このテーブルの Cloud Bigtable の行キーはどのように設計すればよいのでしょうか?
- A. Set Account_id as a key.
- B. Set Account_id_Event_timestamp as a key.
- C. Set Event_timestamp_Account_id as a key.
- D. Set Event_timestamp as a key.
Answer: B
Question 054
Compute Engine にデプロイされたアプリケーションのメモリ使用量を表示したいです。
どうすればいいでしょうか?
- A. Stackdriver クライアント ライブラリをインストールします。
- B. Stackdriver Monitoring エージェントをインストールします。
- C. Stackdriver Metrics Explorer を使用します。
- D. Google Cloud Consoleを使用します。
Answer: B
Reference:
– Google Cloud Platform: how to monitor memory usage of VM instances – Stack Overflow
Question 055
BigQuery API を使用し、数分ごとに BigQuery で数百のクエリを実行する分析アプリケーションがあります。
これらのクエリの実行にかかる時間を調べたいと考えています。
どうすればいいでしょうか?
- A. Stackdriver Monitoring を使用し、スロットの使用状況をプロットします。
- B. Stackdriver Trace を使用し、API 実行時間をプロットします。
- C. Stackdriver Trace を使用し、クエリ実行時間をプロットします。
- D. クエリ実行時間をプロットするために Stackdriver Monitoring を使用します。
Answer: D
Question 056
Cloud Spanner 顧客データベースのスキーマを設計しています。
電話番号配列フィールドを顧客テーブルに格納します。またユーザーが電話番号で顧客を検索できるようにします。
このスキーマをどのように設計するべきでしょうか?
- A. Customers という名前のテーブルを作成します。顧客の電話番号を保持するテーブルの Array フィールドを追加する。
- B. Customers という名前のテーブルを作成します。Phones という名前のテーブルを作成します。電話番号から CustomerId を見つけるために Phones テーブルに CustomerId フィールドを追加します。
- C. Customers という名前のテーブルを作成します。顧客の電話番号を保持するテーブル内にArrayフィールドを追加する。Array フィールドにセカンダリ インデックスを作成します。
- D. 親テーブルとして Customers という名前のテーブルを作成します。Phones という名前のテーブルを作成し、このテーブルを Customer テーブルにインターリーブします。Phones テーブルの電話番号フィールドにインデックスを作成します。
Answer: D
Question 057
http://www.altostrat.com/ の URL 経由でアクセスできるようにする必要がある App Engine に単一の Web サイトをデプロイしています。
どうすればいいでしょうか?
- A. Google 検索セントラルでドメインの所有権を確認します。App Engine の正規名 ghs.googlehosted.com を指す DNS CNAME レコードを作成します。
- B. Google 検索セントラルでドメインの所有権を確認します。単一のグローバル App Engine IP アドレスを指す A レコードを定義します。
- C. dispatch.yaml でマッピングを定義し、ドメイン www.altostrat.com を App Engine サービスに向けます。App Engine の正規名 ghs.googlehosted.com を指す DNS CNAME レコードを作成します。
- D. dispatch.yaml でマッピングを定義し、ドメイン www.altostrat.com を App Engine サービスに向けます。単一のグローバル App Engine IP アドレスを指す A レコードを定義します。
Answer: A
Reference:
– カスタム ドメインのマッピング | .NET の App Engine フレキシブル環境に関するドキュメント | Google Cloud
Question 058
継承した App Engine でアプリケーションを実行しています。
アプリケーションが安全でないバイナリを使用しているかどうか、または XSS 攻撃に対して脆弱であるかどうかを確認したいと考えています。
どうすればいいでしょうか?
- A. Cloud Amor
- B. Stackdriver Debugger
- C. Cloud Security Scanner
- D. Stackdriver Error Reporting
Answer: C
Reference:
– Security Command Center | Google Cloud
Question 059
ソーシャル メディア アプリケーションに取り組んでいます。
ユーザーが画像をアップロードできる機能を追加することを計画しています。これらの画像は 2 MB ~ 1 GB のサイズになります。この機能のためのインフラ運用のオーバーヘッドを最小限に抑えたいと考えています。
どうすればいいでしょうか?
- A. アプリケーションを変更して画像を直接受け取り、他のユーザー情報を保存するデータベースに保存します。
- B. Cloud Storage の署名付き URL を作成するようにアプリケーションを変更します。これらの署名付き URL をクライアント アプリケーションに転送し、画像を Cloud Storage にアップロードします。
- C. ユーザーの画像を受け入れるように GCP に Web サーバをセットアップし、アップロードされたファイルを保持するファイル ストアを作成します。ファイル ストアから画像を取得するようにアプリケーションを変更します。
- D. Cloud Storage でユーザーごとに個別のバケットを作成します。各バケットへの書き込みアクセスを許可する個別のサービス アカウントを割り当てます。ユーザー情報に基づいて、サービス アカウント資格情報をクライアント アプリケーションに転送します。アプリケーションはこのサービス アカウントを使用し、画像を Cloud Storage にアップロードします。
Answer: B
Reference:
– 署名付き URL を活用して Cloud Storage に画像ファイルを直接アップロードするアーキテクチャを設計する | Google Cloud 公式ブログ
Question 060
アプリケーションはカスタム マシン イメージとしてビルドされます。
マシン イメージの複数の固有のデプロイメントがあります。各デプロイは独自のテンプレートを持つ別のマネージド インスタンス グループです。各デプロイメントには固有の設定値のセットが必要です。これらの固有の値を各配備に提供しますが、すべてのデプロイで同じカスタム マシン イメージを使用する必要があります。Compute Engine ですぐに使える機能を使用したいと思っています。
どうすればいいでしょうか?
- A. 固有の構成値を永続ディスクに配置します。
- B. Cloud Bigtable テーブルに一意の構成値を配置します。
- C. インスタンス テンプレートの起動スクリプトに一意の構成値を配置します。
- D. インスタンス テンプレートのインスタンス メタデータに一意の構成値を配置します。
Answer: D
Reference:
– インスタンス グループ | Compute Engine ドキュメント | Google Cloud
Question 061
ローカルでテストした場合、アプリケーションのパフォーマンスは良好ですが Compute Engine インスタンスにデプロイすると実行速度が大幅に低下します。
問題を診断する必要があります。
何をするべきでしょうか?
- A. Google Cloud サポートにチケットを提出し、アプリケーションがローカルでより高速に実行されることを示します。
- B. Cloud Debugger のスナップショットを使用し、アプリケーションの特定時点の実行を確認します。
- C. Cloud Profiler を使用し、アプリケーション内のどの機能に最も時間がかかっているかを判断します。
- D. Logging コマンドをアプリケーションに追加し、Cloud Logging を使用してレイテンシー問題が発生する場所を確認します。
Answer: C
Question 062
App Engineでアプリケーションを実行しています。
アプリケーションは Stackdriver Trace で計装されています。/product-details リクエストは次の図のように /sku-details にある 4 つの既知の固有の製品に関する詳細をレポートします。リクエストが完了するまでの時間を短縮したいと思います。
どうすればいいでしょうか?
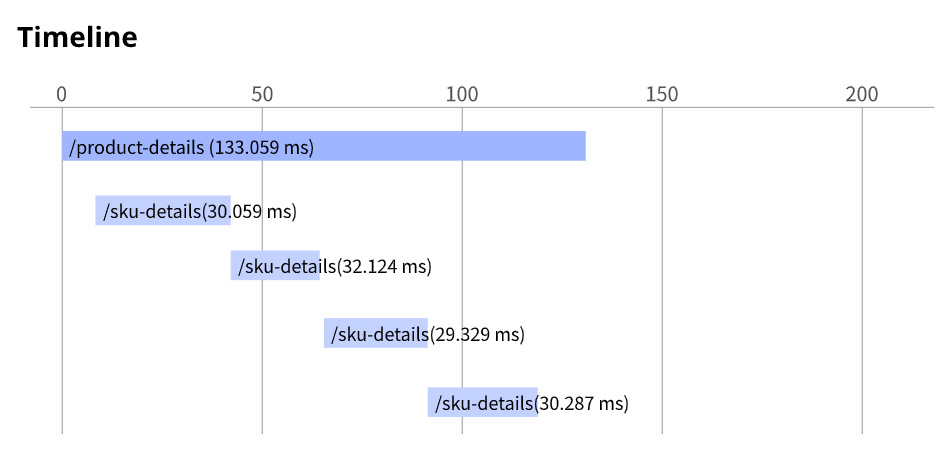
- A. インスタンス クラスのサイズを増やします。
- B. 永続ディスクのタイプを SSD に変更します。
- C. /product-details を変更し、リクエストを並行して実行します。
- D. /sku-details 情報をデータベースに保存し、Web サービス呼び出しをデータベース クエリに置き換えます。
Answer: C
Question 063
会社にはアプリケーション情報を BigQuery に保持するデータ ウェアハウスがあります。
BigQuery データ ウェアハウスは 2 PB のユーザー データを保持します。最近、会社は EU ユーザーを含むようにユーザー ベースを拡大し、次の要件に準拠する必要があります。
– 会社はユーザーの要求に応じてすべてのユーザー アカウント情報を削除する必要があります。
– すべての EU ユーザー データは EU ユーザー専用の 1 つのリージョンに保存する必要があります。
どのようなアクションを実行するべきでしょうか?(回答は 2 つ)
- A. BigQuery 連携クエリを使用し、Cloud Storage からデータをクエリします。
- B. EU ユーザーに関する情報のみを保持する EU 地域でデータセットを作成します。
- C. EU ユーザーのみの情報を保存するために EU リージョンに Cloud Storage バケットを作成します。
- D. ユーザー レコードを除外し、Cloud Dataflow パイプラインを使用してデータを再アップロードします。
- E. BigQuery で DML ステートメントを使用し、リクエストに基づいてユーザー レコードを更新または削除します。
Answer: B、E
Reference:
– BigQuery とは | Google Cloud
Question 064
Google App Engine スタンダード環境は次のとおりです。
– service: production
– instance_class: B1
アプリケーションを 5 つのインスタンスに制限したいと考えています。
構成に含める必要があるコード スニペットはどれでしょうか?
- A. manual_scaling: instances: 5 min_pending_latency: 30ms
- B. manual_scaling: max_instances: 5 idle_timeout: 10m
- C. basic_scaling: instances: 5 min_pending_latency: 30ms
- D. basic_scaling: max_instances: 5 idle_timeout: 10m
Answer: D
Question 065
分析システムは BigQuery データセットに対してクエリを実行します。
SQL クエリはバッチで実行され、SQL ファイルの内容を BigQuery CLI に渡します。次に BigQuery CLI 出力を別のプロセスにリダイレクトしますが、クエリの実行時に BigQuery CLI からパーミッション エラーが発生しているため、この問題を解決したいと考えています。
何をするべきでしょうか?
- A. サービス アカウントに BigQuery データ閲覧者と BigQuery ジョブ ユーザーのロールを付与します。
- B. サービス アカウントに BigQuery データ編集者と BigQuery データ閲覧者の役割を付与します。
- C. SQL クエリから BigQuery でビューを作成し、CLI でビューから SELECT* を作成します。
- D. BigQuery で新しいデータセットを作成し、ソース テーブルを新しいデータセットにコピーします。新しいデータセットとテーブルを CLI からクエリします。
Answer: A
Question 066
アプリケーションは Compute Engine で実行されており、少数のリクエストで持続的な障害が発生しています。
原因を 1 つの Compute Engine インスタンスに絞り込みましたが、インスタンスが SSH に応答しませんでした。
何をするべきでしょうか?
- A. マシンを再起動します。
- B. シリアルポートの出力を有効にして確認します。
- C. マシンを削除して、新しいマシンを作成します。
- D. ディスクのスナップショットを取り、新しいマシンに使用します。
Answer: B
Question 067
全体的な CPU 使用率に応じて自動的にスケーリングするように Compute Engine インスタンス グループを構成しました。
しかし、クラスタがインスタンスを追加し終わる前にアプリケーションのレスポンス レイテンシーが急激に増加します。インスタンス グループのオートスケーラー構成を変更することでエンドユーザーにより一貫したレイテンシー体験を提供したいと思います
どのような構成に変更するべきでしょうか?(回答は 2 つ)
- A. インスタンス グループ テンプレートに AUTOSCALE というラベルを追加します。
- B. グループに追加されたインスタンスのクールダウン期間を短縮します。
- C. インスタンス グループ オートスケーラーのターゲット CPU 使用率を増やします。
- D. インスタンス グループ オートスケーラーのターゲット CPU 使用率を減らします。
- E. インスタンス グループ内の個々の VM のヘルスチェックを削除します。
Answer: B, D
Question 068
マネージド インスタンス グループで管理されているアプリケーションがあります。
アプリケーションの新バージョンをデプロイする場合、コストを最小限に抑え、インスタンスの数を増やすことができません。新しいインスタンスが作成されるたびに新しいインスタンスが健全である場合にのみデプロイが継続されるようにしたいと思います。
どうすればいいのでしょうか?
- A. maxSurge を 1、maxUnavailable を 0 に設定し、ローリングアクションを実行する。
- B. maxSurge を 0、maxUnavailable を 1 に設定し、ローリングアクションを実行します。
- C. maxHealthy を 1、maxUnhealthy を 0 に設定し、ローリングアクションを実行します。
- D. maxHealthy を 0、maxUnhealthy を 1 に設定し、ローリングアクションを実行します。
Answer: B
Reference:
– MIG で VM 構成の更新を自動的に適用する | Compute Engine ドキュメント | Google Cloud
Question 069
アプリケーションではホストの Compute Engine 仮想マシン インスタンスに保存されている認証情報を使用して GCP プロダクトに対してサービス アカウントを認証する必要があります。
これらの認証情報をホスト インスタンスにできるだけ安全に配布する必要があります。
どうすればいいでしょうか?
- A. HTTP 署名付き URL を使用し、必要なリソースへのアクセスを安全に提供します。
- B. インスタンスのサービス アカウント Application Default Credentials を使用し、必要なリソースを認証します。
- C. インスタンスのデプロイ後に Google Cloud コンソールから P12 ファイルを生成し、アプリケーションを開始する前に資格情報をホスト インスタンスにコピーします。
- D. 認証情報 JSON ファイルをアプリケーションのソース リポジトリにコミットし、CI / CD プロセスでインスタンスにデプロイされたソフトウェアと一緒にパッケージ化します。
Answer: B
Reference:
– Compute Engine へのリクエストの承認 | Compute Engine ドキュメント | Google Cloud
Question 070
アプリケーションは Google Kubernetes Engine (GKE) クラスタにデプロイされます。
このアプリケーションを Cloud Load Balancing HTTP(S) 負荷分散用の外部で公開したいと考えています。
どうすればいいでしょうか?
- A. GKE Ingress リソースを構成します。
- B. GKE Service リソースを構成します。
- C. タイプ:LoadBalancer で GKE Ingress リソースを構成します。
- D. タイプ:LoadBalancer の GKE Service リソースを構成します。
Answer: A
Reference:
– HTTP(S) 負荷分散用 GKE Ingress | Google Kubernetes Engine(GKE) | Google Cloud
Question 071
会社はオンプレミスの Hadoop 環境をクラウドに移行することを計画しています。
HDFS に保存されているデータのストレージ コストとメンテナンスの増大は会社にとって大きな懸念事項です。また、既存のデータ分析ジョブや既存のアーキテクチャへの変更は最小限に抑えたいと考えています。
どのように移行を進めるべきでしょうか?
- A. Hadoop に保存されているデータを BigQuery に移行します。オンプレミスの Hadoop 環境ではなく BigQuery から情報を取得するようにジョブを変更します。
- B. SSD の代わりに HDD を使用して Compute Engine インスタンスを作成し、コストを節約します。次に既存の環境を Compute Engine インスタンスの新しい環境に完全に移行します。
- C. Google Cloud Platform で Dataproc クラスタを作成し、Hadoop 環境を新しい Dataproc クラスタに移行します。HDFS データをより大きな HDD ディスクに移動して、ストレージ コストを節約します。
- D. Google Cloud Platform で Dataproc クラスタを作成し、Hadoop コード オブジェクトを新しいクラスタに移行します。データを Cloud Storage に移動し、Dataproc コネクタを利用してそのデータに対してジョブを実行します。
Answer: D
Question 072
データは Cloud Storage バケットに保存されます。
仲間の開発者は Cloud Storage からダウンロードしたデータが原因で API のパフォーマンスが低下していると報告しています。問題を調査して Google Cloud サポート チームに詳細を提供したいと考えています。
どのコマンドを実行する必要がありますか?
- A. gsutil test “o output.json gs://my-bucket
- B. gsutil perfdiag “o output.json gs://my-bucket
- C. gcloud compute scp example-instance:~/test-data “o output.json gs://my-bucket
- D. gcloud services test “o output.json gs://my-bucket
Answer: B
Reference:
– Sometimes get super-slow download rates from Google Cloud Storage, severely impacting workflow
Question 073
Cloud Build build を使用して Docker イメージを開発、テスト、本番の各環境にプロモートしようとしています。
同じ Docker イメージがこれらの各環境にデプロイされることを確実にする必要があります。
ビルドの Docker イメージはどのように識別するべきでしょうか?
- A. 最新の Docker イメージタグを使用します。
- B. 一意の Docker イメージ名を使用します。
- C. Docker イメージのダイジェストを使用します。
- D. セマンティック バージョニングの Docker イメージ タグを使用します。
Answer: C
Question 074
会社はレポートを Cloud Storage バケットにアップロードするアプリケーションを作成しました。
レポートがバケットにアップロードされたらメッセージを Cloud Pub/Sub トピックにパブリッシュします。実装に少しの労力がかかるソリューションを実装したいと考えています。
どうすればいいでしょうか?
- A. オブジェクトが変更されたときに Cloud Pub/Sub 通知をトリガーするように Cloud Storage バケットを構成します。
- B. ファイルを受け取る App Engine アプリケーションを作成します。受信したらメッセージを Cloud Pub/Sub トピックにパブリッシュします。
- C. Cloud Storage バケットによってトリガーされる Cloud Functions を作成します。Cloud Functions で Cloud Pub/Sub トピックにメッセージを発行します。
- D. ファイルを受信するために Google Kubernetes Engine クラスタにデプロイされたアプリケーションを作成します。受信したらメッセージを Cloud Pub/Sub トピックにパブリッシュします。
Answer: A
Reference:
– Pub/Sub notifications for Cloud Storage
Question 075
チームメイトから Cloud Datastore のアカウント残高にクレジットを追加する以下のコードを確認するように依頼されました。
チームメイトにどのような改善をするべきでしょうか?
public Entity creditAccount (long accountId, long creditAmount) {
Entity account = datastore.get
(keyFactory.newKey (accountId));
account = Entity.builder (account).set(
"balance", account.getLong ("balance") + creditAmount).build()
datastore.put (account);
return account;
}- A.祖先クエリでエンティティを取得します。
- B. エンティティを取得してトランザクションに入れます。
- C. 強力で一貫性のあるトランザクション データベースを使用します。
- D. 関数からアカウント エンティティを返しません。
Answer: B
Question 076
会社ではソースコードを Cloud Source Repositories リポジトリに保存しています。
会社はソース コードがリポジトリにコミットされるたびにコードをビルドしてテストしたいと考えており、管理され、運用オーバーヘッドが最小限のソリューションを必要としています。
どのような方法を使用するべきでしょうか?
- A. ソースコードのコミットごとに構成されたトリガーで Cloud Build を使用します。
- B. Google Cloud Marketplace 経由でデプロイされ、ソースコードのコミットを監視するように構成された Jenkins を使用します。
- C. ソースコードのコミットを監視するように構成されたオープンソースの継続的インテグレーション ツールで Compute Engine 仮想マシン インスタンスを使用します。
- D. ソース コード コミット トリガーを使用し、App Engine サービスをトリガーしてソース コードをビルドする Cloud Pub/Sub トピックにメッセージをプッシュします。
Answer: A
Question 077
プロジェクト B の Cloud Pub/Sub トピックに対して安全に認証する必要があるプロジェクト A で Compute Engine がホストするアプリケーションを作成しています。
どうすればいいでしょうか?
- A. プロジェクト B が所有するサービス アカウントを使用してインスタンスを構成します。サービス アカウントを Cloud Pub/Sub パブリッシャーとしてプロジェクト A に追加します。
- B. プロジェクト A が所有するサービス アカウントを使用してインスタンスを構成します。サービス アカウントをトピックのパブリッシャーとして追加します。
- C. プロジェクト B が所有するサービス アカウントの秘密鍵を使用するようにアプリケーションのデフォルト認証情報を構成します。サービス アカウントを Cloud Pub/Sub パブリッシャーとしてプロジェクト A に追加します。
- D. プロジェクト A が所有するサービス アカウントの秘密鍵を使用するようにアプリケーションの既定の資格情報を構成します。トピックのパブリッシャーとしてサービス アカウントを追加します。
Answer: B
Question 078
Compute Engine で財務部門用の企業ツールを開発しており、ユーザーを認証して財務部門の人間であることを確認する必要があります。
どうすればいいでしょうか?
- A. HTTP(s) ロードバランサの Cloud Identity-Aware Proxy を有効にし、財務部門のユーザーを含む Google グループにアクセスを制限します。提供された JSON Web トークンをアプリケーション内で確認します。
- B. HTTP(s) ロードバランサの Cloud Identity-Aware Proxy を有効にし、財務部門のユーザーを含む Google グループへのアクセスを制限します。財務チームの全員にクライアント側証明書を発行し、アプリケーションで証明書を検証します。
- C. Cloud Armor Security Policies を構成して企業 IP アドレス範囲のみにアクセスを制限します。提供された JSON Web トークンをアプリケーション内で検証します。
- D. Cloud Armor Security Policiesを構成して企業の IP アドレス範囲のみにアクセスを制限します。財務チームの全員にクライアント側の証明書を発行し、アプリケーションで証明書を検証します。
Answer: A
Question 079
API バックエンドが複数のクラウド プロバイダで実行されています。
API のネットワーク遅延に関するレポートを生成したいと考えています。
どのような手順で実行するべきでしょうか?(回答は 2 つ)
- A. Zipkin コレクタを使用してデータを収集します。
- B. Fluentd エージェントを使用してデータを収集します。
- C. Stackdriver Trace を使用してレポートを生成します。
- D. Stackdriver Debugger を使用してレポートを生成します。
- E. Stackdriver Profiler を使用してレポートを生成します。
Answer: A、C
Question 080
この問題は HipLocal のケーススタディを参照してください。
ユーザー アクティビティを保存するために HipLocal が使用するべきデータベースはどれでしょうか?
- A. BigQuery
- B. Cloud SQL
- C. Cloud Spanner
- D. Cloud Datastore
Answer: A
Question 081
この問題は HipLocal のケーススタディを参照してください。
HipLocal はアクセス制御を構成しています。
どのようなファイアウォール構成を実装するべきでしょうか?
- A. ポート 443 ですべてのトラフィックをブロックします。
- B. ネットワークへのすべてのトラフィックを許可します。
- C. 特定のタグのポート 443 でトラフィックを許可します。
- D. ネットワークへのポート 443 のすべてのトラフィックを許可します。
Answer: C
Question 082
この問題は HipLocal のケーススタディを参照してください。
HipLocal のデータ サイエンス チームはユーザー レビューを分析したいと考えています。
どのようにデータを準備するべきでしょうか?
- A. レビュー データセットの秘匿化には Cloud Data Loss Prevention API を使用します。
- B. Cloud Data Loss Prevention API を使用してレビュー データセットの匿名化を行います。
- C. レビュー データセットの秘匿化に Cloud Natural Language Processing API を使用します。
- D. Cloud Natural Language Processing API を使用してレビュー データセットの匿名化を行います。
Answer: B
Question 083
この問題は HipLocal のケーススタディを参照してください。
HipLocal がアプリケーションの状態を保存し、規定されたビジネス要件を満たすにはどのデータベース サービスに移行するべきでしょうか?
- A. Cloud Spanner
- B. Cloud Datastore
- C. キャッシュとしての Cloud Memorystore
- D. リージョンごとに個別の Cloud SQL クラスタ
Answer:D
Question 084
本番環境にデプロイされたアプリケーションがあります。
新しいバージョンがデプロイされたらすべての本番トラフィックがアプリケーションの新しいバージョンにルーティングされるようにする必要があります。また、新しいバージョンに問題が発生した場合に元に戻せるように以前のバージョンをデプロイしたままにしておくことも必要です。
どのデプロイ戦略を使用するべきでしょうか?
- A. Blue/Green デプロイ戦略
- B. カナリア テスト戦略
- C. ローリング デプロイ戦略
- D. 再作成 デプロイ戦略
Answer: A
Question 085
既存の Apache / MySQL / PHP アプリケーション スタックを単一のマシンから Google Kubernetes Engine に移植しています。
アプリケーションをコンテナ化する方法を決定する必要があります。アプローチは可用性に関して Google が推奨するベスト プラクティスに従う必要があります。
どうするべきでしょうか?
- A. 各コンポーネントを個別のコンテナにパッケージ化します。実装プローブとライブネス プローブを実装します。
- B. アプリケーションを単一のコンテナにパッケージ化します。プロセス管理ツールを使用して、各コンポーネントを管理します。
- C. 各コンポーネントを個別のコンテナにパッケージ化します。スクリプトを使用してコンポーネントの起動を調整します。
- D. アプリケーションを単一のコンテナにパッケージ化します。コンテナへのエントリポイントとして bash スクリプトを使用し、各コンポーネントをバックグラウンド ジョブとして生成します。
Answer: A
Reference:
–コンテナ構築のおすすめの方法 | Cloud アーキテクチャ センター | Google Cloud
Question 086
Compute Engine インスタンスで起動するアプリケーションをソフトウェア開発プロセスの環境 (開発、QA、ステージング、本番) に対応する複数の異なるプロジェクトに分けて開発しています。
各プロジェクトのインスタンスのアプリケーション コードは同じですが構成が異なります。デプロイ中、各インスタンスはサービスを提供する環境に基づいてアプリケーションの構成を受け取る必要があります。このフローを構成するためのステップ数を最小限に抑えたいと考えています。
どうすればいいでしょうか?
- A. インスタンスを作成するときに gcloud コマンドを使用して起動スクリプトを構成し、正しい環境を示すプロジェクト名を決定します。
- B. 各プロジェクトでそれが提供する環境を値とするメタデータ キー環境を構成します。デプロイ ツールを使用してインスタンス メタデータをクエリし、環境値に基づいてアプリケーションを構成します。
- C. 選択したデプロイ ツールを各プロジェクトのインスタンスにデプロイします。デプロイ ジョブを使用してバージョン管理システムから適切な構成ファイルを取得し、各インスタンスにアプリケーションをデプロイするときに構成を適用します。
- D. 各インスタンスの起動中に environment という名前のインスタンス カスタム メタデータ キーを構成します。この値はインスタンスが提供する環境です。デプロイ ツールを使用してインスタンス メタデータをクエリし、環境値に基づいてアプリケーションを構成します。
Answer: B
Reference:
–VM メタデータについて | Compute Engine ドキュメント | Google Cloud
Question 087
顧客、注文、在庫のデータを Cloud Spanner 内のリレーショナル テーブルとして保存する e コマース アプリケーションを開発しています。
最近の負荷テスト中に Cloud Spanner のパフォーマンスが期待どおりに直線的にスケーリングしていないことがわかりました。
原因はどれでしょうか?
- A. 32 ビットの数値に 64 ビットの数値型を使用します。
- B. 任意精度の値に対する STRING データ型を使用します。
- C. 単調に増加する主キーとしてのバージョン 1 UUID を使用します。
- D. パラメータ化された SQL クエリの STARTS_WITH キーワードの代わりに LIKE を使用します。
Answer:C
Question 088
Cloud Pub/Sub サブスクリプションからクレジット カード データを読み取るアプリケーションを開発しています。
コードを記述し、単体テストを完了しました。Google Cloud にデプロイする前に Cloud Pub/Sub 統合をテストする必要があります。
どうすればいいでしょうか?
- A. メッセージを発行するサービスを作成し、Cloud Pub/Sub エミュレーターをデプロイします。パブリッシング サービスでランダムなコンテンツを生成し、エミュレーターにパブリッシュします。
- B. アプリケーションにメッセージを発行するサービスを作成します。本番環境の Cloud Pub/Sub からメッセージを収集し、パブリッシング サービスを通じてそれらを再生します。
- C. メッセージを発行するサービスを作成し、Cloud Pub/Sub エミュレーターをデプロイします。本番環境の Cloud Pub/Sub からメッセージを収集し、エミュレーターに公開します。
- D. メッセージを発行するサービスを作成し、Cloud Pub/Sub エミュレーターをデプロイします。パブリッシング サービスからエミュレータにテスト メッセージの標準セットをパブリッシュします。
Answer:D
Question 089
単一の Cloud Pub/Sub トピックにサブスクライブしてメッセージを受信し、対応する行をデータベースに挿入するアプリケーションを設計しています。
アプリケーションは Linux で実行され、プリエンプティブル仮想マシンを活用してコストを削減します。正常なシャットダウンを開始するシャットダウン スクリプトを作成する必要があります。
どうすればいいでしょうか?
- A. プロセス間シグナルを使用してデータベースから切断するようにアプリケーション プロセスに通知するシャットダウン スクリプトを記述します。
- B. サインインしているすべてのユーザーに Compute Engine インスタンスがダウンするというメッセージをブロードキャストし、現在の作業を保存してサインアウトするように指示するシャットダウン スクリプトを作成します。
- C. アプリケーションによって 5 分ごとにポーリングされる場所にファイルを書き込むシャットダウン スクリプトを作成します。ファイルが読み取られた後、アプリケーションはデータベースから切断されます。
- D. シャットダウンが進行中であることを通知するメッセージを Pub/Sub トピックにパブリッシュするシャットダウン スクリプトを作成します。アプリケーションはメッセージを読み取った後、データベースから切断します。
Answer: A
Reference:
–シャットダウン スクリプトの実行 | Compute Engine ドキュメント | Google Cloud
Question 090
小さなスタートアップ企業の Web 開発チームで働いています。
チームは Cloud Storage や Cloud Build などの Google Cloud サービスを使用して Node.js アプリケーションを開発しており、バージョン管理に Git リポジトリを使用しています。上司から週末に電話があり、会社の Web サイトの 1 つを緊急に更新するように指示されました。開発者はあなただけです。仕事用のラップトップを持っておらず、会社以外のコンピュータにソースコードをローカルに保存することは許可されていません。
開発者 環境をどのように設定しますか?
- A. テキスト エディターと Git コマンド ラインを使用して公共のコンピューターからソース コードの更新をプル リクエストとして送信します。
- B. テキスト エディターと Git コマンド ラインを使用して公共のコンピューターで実行されている仮想マシンからソース コードの更新をプル リクエストとして送信します。
- C. Cloud Shell と組み込みのコード エディタを開発に使用してソース コードの更新をプル リクエストとして送信します。
- D. Cloud Storage バケットを使用して編集が必要なソースコードを保存します。バケットを公共のコンピューターにドライブとしてマウントし、コード エディターを使用してコードを更新します。バケットのバージョニングを有効にしてチームの Git リポジトリを参照します。
Answer:C
Reference:
–Contributing to projects – GitHub Enterprise Server 3.3 Docs
Question 091
チームは Google Kubernetes Engine で実行されるサービスを開発しています。
Google が推奨する手法を使用してログ データを標準化し、最小限の手順でデータをより有用なものにする必要があります。
どうすればいいでしょうか? (回答は 2 つ)
- A. ログ分析を容易にするために BigQuery へのアプリケーション ログの集約エクスポートを作成します。
- B. ログ分析を容易にするために Cloud Storage へのアプリケーション ログの集約エクスポートを作成します。
- C. ログ出力を単一行の JSON として標準出力 (stdout) に書き込み、構造化ログとして Cloud Logging に取り込みます。
- D. アプリケーション コードで Logging API を使用して構造化されたログを Cloud Logging に書き込むことを義務付けます。
- E. Pub/Sub API を使用して構造化データを Pub/Sub に書き込み、Dataflow ストリーミング パイプラインを作成してログを正規化し、分析のために BigQuery に書き込むことを義務付けます。
Answer:A、D
Question 092
Google Cloud での新しいアプリケーションのデプロイ手法を設計しています。
デプロイ計画の一環として、ライブ トラフィックを使用して新しいアプリケーションと既存のアプリケーションの両方のパフォーマンス メトリックを収集したいと考えています。起動前に完全な実稼働負荷に対してテストする必要があります。
どうすればいいでしょうか?
- A. カナリア テスト戦略を使用します。
- B. Blue/Green デプロイ戦略を使用します。
- C. ローリングアップデート デプロイ戦略を使用します。
- D. デプロイ時にトラフィック ミラーリングで A/B テスト戦略を使用します。
Answer:D
Reference:
–アプリケーションのデプロイとテストの戦略 | Cloud アーキテクチャ センター | Google Cloud
Question 093
Cloud Storage API を使用するアプリケーションをサポートしています。
ログを確認し、API からの複数の HTTP 503 Service Unavailable エラー応答を発見しました。アプリケーションはエラーをログに記録し、それ以上のアクションは実行しません。成功率を向上させるために Google が推奨する再試行ロジックを実装したいと考えています。
どのアプローチを取るべきですか?
- A. 設定された数の失敗がログに記録された後、バッチで失敗を再試行します。
- B. 設定された時間間隔で最大回数まで各失敗を再試行します。
- C. 最大試行回数まで時間間隔を増やしながら各失敗を再試行します。
- D. 最大試行回数まで時間間隔を減らしながら各失敗を再試行します。
Answer:C
Question 094
認証サービスからの監査イベントの取り込みを再設計してトラフィックの大幅な増加を処理できるようにする必要があります。
現在、監査サービスと認証システムは同じ Compute Engine 仮想マシンで実行されています。新しいアーキテクチャで次の Google Cloud ツールを使用する予定です。
– それぞれが認証サービスのインスタンスを実行する複数の Compute Engine マシン
– それぞれが監査サービスのインスタンスを実行する複数の Compute Engine マシン
– 認証サービスからイベントを送信するための Cloud Pub/Sub。
システムが大量のメッセージを処理し、効率的にスケーリングできるようにするにはトピックとサブスクリプションをどのように設定する必要がありますか?
- A. Cloud Pub/Sub トピックを 1 つ作成します。Pull サブスクリプションを 1 つ作成して監査サービスがメッセージを共有できるようにします。
- B. Cloud Pub/Sub トピックを 1 つ作成します。監査サービス インスタンスごとに 1 つの Pull サブスクリプションを作成してサービスがメッセージを共有できるようにします。
- C. Cloud Pub/Sub トピックを 1 つ作成します。エンドポイントが監査サービスの前にあるロードバランサを指す 1 つの Push サブスクリプションを作成します。
- D. 認証サービスごとに 1 つの Cloud Pub/Sub トピックを作成します。1 つの監査サービスで使用されるトピックごとに 1 つの Pull サブスクリプションを作成します。
- E. 認証サービスごとに 1 つの Cloud Pub/Sub トピックを作成します。トピックごとに 1 つの Push サブスクリプションを作成し、エンドポイントが 1 つの監査サービスを指すようにします。
Answer: A
Question 095
Google Cloud で実行される有名なステートレス Web アプリケーションを開発しています。
トラフィックがない日もあれば、急増する日もあるなど、ユーザーからのトラフィックは予測不可能できません。アプリケーションを自動的にスケールアップおよびスケールダウンする必要があり、アプリケーションの実行に関連するコストを最小限に抑える必要があります。
どうすればいいでしょうか?
- A. Cloud Firestore をデータベースとして Python でアプリケーションを構築します。アプリケーションを Cloud Run にデプロイします。
- B. Cloud Firestore をデータベースとして C# でアプリケーションを構築します。アプリケーションを App Engine フレキシブル環境にデプロイします。
- C. Cloud SQL をデータベースとして Python でアプリケーションを構築します。アプリケーションを App Engine スタンダード環境にデプロイします。
- D. Cloud Firestore をデータベースとして Python でアプリケーションを構築します。自動スケーリングを使用して、アプリケーションを Compute Engine マネージド インスタンス グループにデプロイします。
Answer: A
Question 096
他の Google Cloud リソースにアクセスする Cloud Functions を作成しました。
最小権限の原則を使用して環境を保護したいと考えています。
どうすればいいでしょうか?
- A. リソースにアクセスするための編集者 権限を持つ新しいサービス アカウントを作成します。デプロイ担当者にはアクセス トークンを取得するためのアクセス許可が与えられます。
- B. リソースにアクセスするためのカスタム IAM ロールを持つ新しいサービス アカウントを作成します。デプロイ担当者にはアクセス トークンを取得するためのアクセス許可が与えられます。
- C. リソースにアクセスするための編集者権限を持つ新しいサービス アカウントを作成します。デプロイ担当者には、新しいサービス アカウントとして機能する権限が与えられます。
- D. リソースにアクセスするためのカスタム IAM ロールを持つ新しいサービス アカウントを作成します。デプロイ担当者には新しいサービス アカウントとして機能する権限が与えられます。
Answer:D
Reference:
–Least privilege for Cloud Functions using Cloud IAM | Google Cloud Blog
Question 097
Google Kubernetes Engine (GKE) クラスタ内の顧客に専用のブログ ソフトウェアをデプロイする SaaS プロバイダがいます。
各顧客が自分のブログにのみアクセスでき、他の顧客のワークロードに影響を与えないように安全なマルチテナント プラットフォームを構成したいと考えています。
どうすればいいでしょうか?
- A. GKE クラスタでアプリケーション レイヤのシークレットを有効にしてクラスタを保護します。
- B. テナントごとに名前空間をデプロイして各ブログのデプロイでネットワーク ポリシーを使用します。
- C. GKE Audit Logging を使用して悪意のあるコンテナを特定し、検出時に削除する。
- D. ブログ ソフトウェアのカスタム イメージを構築し、Binary Authorization を使用して信頼できないイメージのデプロイを防止します。
Answer: B
Reference:
–クラスタ マルチテナンシー | Google Kubernetes Engine(GKE) | Google Cloud
Question 098
Compute Engine アプリケーションを Google Kubernetes Engine に移行することにしました。
コンテナ イメージをビルドし、Cloud Build を使用して Artifact Registry にプッシュする必要があります。
どうすればいいでしょうか? (回答は 2 つ)
- A. アプリケーションのソースコードを含むディレクトリで gcloud builds submit を実行します。
- B. アプリケーションのソース コードを含むディレクトリで gcloud run deploy app-name –image gcr.io/$PROJECT_ID/app-name を実行します。
- C. アプリケーション ソース コードを含むディレクトリで gcloud container images add-tag gcr.io/$PROJECT_ID/app-name gcr.io/$PROJECT_ID/app-name:latest を実行します。
- D. アプリケーション ソース ディレクトリで次の内容を含む cloudbuild.yaml という名前のファイルを作成します。
name: ‘gcr.io/cloud-builders/docker’
steps:
args: [‘build’, ‘-t’, ‘gcr.io/$PROJECT_ID/app-name’, ‘.’]
name: ‘gcr.io/cloud-buliders/docker’
args: [‘push’, ‘gcr.io$PROJECT_ID/app-name’] - E. アプリケーション ソース ディレクトリで次の内容を含む cloudbuild.yaml という名前のファイルを作成します。
contents:
steps:
name: ‘gcr.io/cloud-builders/gcloud’
args: [‘app’, ‘deploy’]
timeout: ‘1600s’
Answer:A、D
Question 099
従業員が社内でコミュニティ イベントを開催できるようにする社内アプリケーションを開発しています。
単一の Compute Engine インスタンスにアプリケーションをデプロイしました。会社は Google Workspace (旧:G Suite) を使用しており、会社の従業員がどこからでもアプリケーションに対して認証できるようにする必要があります。
どうすればいいでしょうか?
- A. インスタンスにパブリック IP アドレスを追加し、ファイアウォール ルールを使用してインスタンスへのアクセスを制限します。会社のプロキシを唯一の送信元 IP アドレスとして許可します。
- B. インスタンスの前に HTTP(S) ロードバランサを追加し、Identity-Aware Proxy (IAP) を設定します。会社のドメインが Web サイトにアクセスできるように IAP 設定を構成します。
- C. 会社のネットワークと Google Cloud のインスタンスの VPC ロケーションの間に VPN トンネルを設定します。必要なファイアウォール ルールとルーティング情報をオンプレミス ネットワークと Google Cloud ネットワークの両方に構成します。
- D. インスタンスにパブリック IP アドレスを追加し、インターネットからのトラフィックを許可します。ランダム ハッシュを生成し、このハッシュを含み、インスタンスを指すサブドメインを作成します。この DNS アドレスを会社の従業員に配布します。
Answer: B
Question 100
開発チームは App Engine で構築した Node.js アプリケーションをステージング環境から本番環境に移行するために Cloud Build を使用しています。
このアプリケーションはステージング環境の webphotos-staging という名前の Cloud Storage バケットに保存されている写真の複数のディレクトリに依存しています。移行後、これらの写真は本番環境の webphotos-prod という名前の Cloud Storage バケットで利用できる必要があります。可能であればプロセスを自動化したいとも考えています。
どうすればいいでしょうか?
- A. 写真を webphotos-prod に手動でコピーします。
- B. アプリケーションの app.yami ファイルに起動スクリプトを追加して写真を webphotos-staging から webphotos-prod に移動します。
- C. 移行ステップの前に引数を使用して cloudbuild.yaml ファイルにビルド ステップを追加します。
name: ‘gcr.io/cloud-builders/gsutil
args: [‘cp’, ‘-r’, ‘gs://webphotos-staging’, ‘gs://webphotos-prod’]
waitFor: [‘-‘] - D. 移行ステップの前に引数を使用して cloudbuild.yaml ファイルにビルド ステップを追加します。
name: gcr.io/cloud-builders/gcloud
args: [‘cp’, ‘-A’, ‘gs://webphotos-staging’, ‘gs://webphotos-prod’]
waitFor: [‘-‘]
Answer:C
Question 101
HTTP と HTTPS の両方でアクセスでき、Compute Engine インスタンスで実行される Web アプリケーションを開発しています。
アプリのメンテナンスを行うためにリモート ラップトップから Compute Engine インスタンスの 1 つに SSH 接続する必要がある場合があります。
Google が推奨するベスト プラクティスに従いながらインスタンスをどのように構成するべきでしょうか?
- A. TCP プロキシ ロードバランサの背後にあるプライベート IP アドレスを使用して、Compute Engine の Web サーバ インスタンスでバックエンドを設定します。
- B. ファイアウォール ルールを構成して、すべてのメッシュの上り(内向き)トラフィックが Compute Engine の Web サーバに接続できるようにします。各サーバには一意の外部 IP アドレスがあります。
- C. SSH アクセス用に Cloud Identity-Aware Proxy API を構成します。次にアプリケーション Web トラフィック用の HTTP(S) ロードバランサの背後にあるプライベート IP アドレスを使用して Compute Engine サーバを構成します。
- D. HTTP(S) ロードバランサの外部にあるプライベート IP アドレスを使用して Compute Engine の Web サーバ インスタンスでバックエンドを設定します。パブリック IP アドレスを使用して要塞ホストを設定し、ファイアウォール ポートを開きます。要塞ホストを使用して Web インスタンスに接続します。
Answer:C
Reference:
–高度な方法による Linux VM への接続 #TCP 用 Identity-Aware Proxy(IAP)を介した接続 | Compute Engine ドキュメント | Google Cloud
Question 102
Linux を実行している Compute Engine インスタンスでホストされているパッケージ化されたアプリケーションと社内で開発されたアプリケーションが混在しています。
これらのアプリケーションは、ログ レコードをテキストとしてローカル ファイルに書き込み、ログを Cloud Logging に書き込む必要があります。
どうすればいいでしょうか?
- A. ファイルの内容を Linux Syslog デーモンにパイプします。
- B. Google バージョンの fluentd を Compute Engine インスタンスにインストールします。
- C. Compute Engine インスタンスに Google バージョンの collectd をインストールします。
- D. cron を使用して 1 日 1 回ログ ファイルを Cloud Storage にコピーするジョブをスケジュールします。
Answer: B
Reference:
–Logging エージェントを構成する | Google Cloud
Question 103
アプリケーション用に「fully baked」または「golden」の Compute Engine イメージを作成する必要があります。
アプリケーションが実行されている環境 (テスト、ステージング、本番) に応じてアプリケーションをブートストラップして適切なデータベースに接続する必要があります。
どうすればいいでしょうか?
- A. 適切なデータベース接続文字列をイメージに埋め込み、環境ごとに異なるイメージを作成します。
- B. Compute Engine インスタンスを作成するときに接続するデータベースの名前を含むタグを追加します。アプリケーションで Compute Engine API にクエリを実行して現在のインスタンスのタグを取得し、そのタグを使用して適切なデータベース接続文字列を作成します。
- C. Compute Engine インスタンスを作成するときに DATABASE のキーと適切なデータベース接続文字列の値を持つメタデータ項目を作成します。アプリケーションで DATABASE 環境変数を読み取り、その値を使用して適切なデータベースに接続します。
- D. Compute Engine インスタンスを作成するときに DATABASE のキーと適切なデータベース接続文字列の値を持つメタデータ項目を作成します。アプリケーションで、メタデータ サーバに DATABASE 値をクエリし、その値を使用して適切なデータベースに接続します。
Answer:D
Question 104
Google Kubernetes Engine クラスタにデプロイされるマイクロサービス ベースのアプリケーションを開発しています。
アプリケーションは Cloud Spanner データベースの読み取りと書き込みを行う必要があります。コードの変更を最小限に抑えながらセキュリティのベスト プラクティスに従います。
Google Spanner 認証情報を取得するにはアプリケーションをどのように構成するべきでしょうか?
- A. 適切なサービス アカウントを構成し、Workload Identity を使用して Pod を実行します。
- B. アプリケーション資格情報を Kubernetes シークレットとして保存し、環境変数として公開します。
- C. 適切なルーティング ルールを構成し、VPC ネイティブ クラスタを使用してデータベースに直接接続する。
- D. Cloud Key Management Service を使用してアプリケーション資格情報を保存し、データベース接続が確立されるたびにそれらを取得します。
Answer: A
Reference:
–Google Kubernetes Engine から Cloud SQL に接続する | Cloud SQL for MySQL | Google Cloud
Question 105
Cloud SQL と通信する Compute Engine インスタンスにアプリケーションをデプロイしています。
Cloud SQL Proxy を使用してアプリケーションのインスタンスに関連付けられたサービス アカウントを使用し、アプリケーションがデータベースと通信できるようにします。サービス アカウントに割り当てられたロールに最小限のアクセスを提供するという、Google が推奨するベスト プラクティスに従います。
どうすればいいでしょうか?
- A. プロジェクト編集者の役割を割り当てます。
- B. プロジェクト所有者の役割を割り当てます。
- C. Cloud SQL クライアントの役割を割り当てます。
- D. Cloud SQL 編集者の役割を割り当てます。
Answer:C
Reference:
–Cloud SQL Auth Proxy について | Cloud SQL for MySQL | Google Cloud
Question 106
チームは Google Kubernetes Engine (GKE) で実行されるステートレス サービスを開発しています。
GKE クラスタで実行されている他のサービスのみがアクセスできる新しいサービスをデプロイする必要があります。サービスは変化する負荷に対応するためにできるだけ迅速にスケーリングする必要があります。
どうすればいいでしょうか?
- A. Vertical Pod Autoscaler を使用してコンテナをスケーリングし、ClusterIP サービスを介して公開します。
- B. Vertical Pod Autoscaler を使用してコンテナをスケーリングし、NodePort サービスを介して公開します。
- C. Horizontal Pod Autoscaler を使用してコンテナをスケーリングし、ClusterIP サービスを介して公開します。
- D. Horizontal Pod Autoscaler を使用してコンテナをスケーリングし、NodePort サービスを介して公開します。
Answer:C
Question 107
最近、モノリシック アプリケーションをマイクロサービスに分割して Google Cloud に移行しました。
マイクロサービスの 1 つは Cloud Functions を使用してデプロイされます。アプリケーションをモダナイズするときに下位互換性のないサービスの API に変更を加えます。元の API を使用する既存の呼び出し元と新しい API を使用する新しい呼び出し元の両方をサポートする必要があります。
どうすればいいでしょうか?
- A. 元の Cloud Functions をそのままにして新しい API を使用して 2 つ目の Cloud Functions をデプロイします。ロードバランサを使用してバージョン間で呼び出しを分散します。
- B. 元の Cloud Functions をそのままにして変更された API のみを含む 2 つ目の Cloud Functions をデプロイします。呼び出しは、正しい関数に自動的にルーティングされます。
- C. 元の Cloud Functions をそのままにして、新しい API を使用して 2 つ目の Cloud Functions をデプロイします。Cloud Endpoints を使用してバージョン管理された API を公開する API ゲートウェイを提供します。
- D. 新しい API をサポートするためにコードを変更した後、Cloud Functions を再デプロイします。API の両方のバージョンに対する要求は呼び出しに含まれるバージョン識別子に基づいて実行されます。
Answer:C
Question 108
ユーザーがニュース記事のコメントを読んだり投稿したりできるアプリケーションを開発しています。
Cloud Firestore を使用してユーザーが送信したコメントを保存および表示するようにアプリケーションを構成したいと考えています。
不明な数のコメントと記事をサポートするにはスキーマをどのように設計するべきでしょうか?
- A. 各コメントを記事のサブコレクションに保存します。
- B. 各コメントを記事の配列プロパティに追加します。
- C. 各コメントをドキュメントに保存し、コメントのキーを記事の配列プロパティに追加します。
- D. 各コメントをドキュメントに保存し、コメントのキーをユーザー プロファイルの配列プロパティに追加します。
Answer:D
Question 109
最近、アプリケーションを開発しました。
パブリック IP アドレスを持たない Compute Engine インスタンスから Cloud Storage API を呼び出す必要があります。
どうすればいいでしょうか?
- A. キャリア ピアリングを使用します。
- B. VPC ネットワーク ピアリングを使用します。
- C. 共有 VPC ネットワークを使用します。
- D. 限定公開の Google アクセスを使用します。
Answer:D
Reference:
–IP アドレス | Compute Engine ドキュメント | Google Cloud
Question 110
CI / CD チームと協力してチームが導入した新機能のトラブルシューティングを行う開発者です。
CI / CD チームは HashiCorp Packer を使用して開発ブランチから新しい Compute Engine イメージを作成しました。イメージは正常にビルドされましたが起動していません。CI / CD チームで問題を調査する必要があります。
どうすればいいでしょうか?
- A. 新しい機能ブランチを作成し、ビルド チームにイメージの再構築を依頼します。
- B. デプロイされた仮想マシンをシャットダウンし、ディスクをエクスポートしてからディスクをローカルにマウントしてブート ログにアクセスします。
- C. Packer をローカルにインストールし、Compute Engine イメージをローカルでビルドしてから個人の Google Cloud プロジェクトで実行します。
- D. シリアル ポートを使用して Compute Engine OS のログを確認し、Cloud Logging のログを確認してシリアル ポートへのアクセスを確認します。
Answer:D
Reference:
– Jenkins、Packer、Kubernetes を使用したイメージ構築の自動化 | Cloud アーキテクチャ センター | Google Cloud
Question 111
Compute Engine インスタンスで実行されるアプリケーションを管理します。また、Compute Engine インスタンスで実行されているスタンドアロンの Docker コンテナで複数のバックエンド サービスを実行しています。
バックエンド サービスをサポートする Compute Engine インスタンスは複数のリージョンのマネージド インスタンス グループによってスケーリングされます。呼び出し元のアプリケーションを疎結合にしたいと考えています。リクエストで見つかった HTTP ヘッダーの値に基づいて選択された個別のサービス実装を呼び出すことができる必要があります。
バックエンド サービスを呼び出すにはどの Google Cloud 機能を使用するべきでしょうか?
- A. Traffic Director
- B. Service Directory
- C. Anthos サービス メッシュ
- D. 内部 HTTP(S) ロードバランサ
Answer: A
Reference:
– Traffic Director | Google Cloud
Question 112
チームは会社の e コマース プラットフォームを開発しています。
ユーザーは Web サイトにログインし、ショッピング カートに商品を追加します。ユーザーは 30 分間操作がないと自動的にログアウトされます。ユーザーが再度ログインするとショッピング カートが保存されます。
Google が推奨するベスト プラクティスに従ってユーザーのセッションとショッピング カートの情報をどのように保存しますか?
- A. セッション情報を CLoud Pub/Sub に保存し、ショッピング カート情報を Cloud SQL に保存する。
- B. ショッピング カートの情報をファイル名が SESSION ID である Cloud Storage 上のファイルに保存します。
- C. セッションとショッピング カートの情報を複数の Compute Engine インスタンスで実行されている MySQL データベースに保存します。
- D. セッション情報を Memorystore for Redis または Memorystore for Memcached に保存し、ショッピング カート情報を Cloud Firestore に保存します。
Answer:D
Question 113
Google Kubernetes Engine クラスタ内のさまざまなチームが使用するアプリケーションのリソース共有ポリシーを設計しています。
すべてのアプリケーションが実行に必要なリソースにアクセスできるようにする必要があります。
どうすればいいでしょうか? (回答は 2 つ)
- A. オブジェクト仕様でリソースの制限と要求を指定します。
- B. 各チームの名前空間を作成し、リソース クォータを各名前空間に添付します。
- C. LimitRange を作成して各名前空間のデフォルトのコンピューティング リソース要件を指定します。
- D. アプリケーションごとに Kubernetes サービス アカウント (KSA) を作成し、各 KSA を名前空間に割り当てます。
- E. Anthos Policy Controller を使用してすべての名前空間にラベル アノテーションを適用します。taints と tolerations を使用して名前空間のリソース共有を許可します。
Answer:B、C
Reference:
– Kubernetes サービス アカウントを使用する | Google Kubernetes Engine(GKE) | Google Cloud
Question 114
次の設計要件を持つ新しいアプリケーションを開発しています。
– アプリケーション インフラストラクチャの作成と変更はバージョン管理され、監査可能です。
– アプリケーションおよびデプロイ インフラストラクチャは Google マネージド サービスを可能な限り使用します。
– アプリケーションはサーバレス コンピューティング プラットフォームで実行されます。
アプリケーションのアーキテクチャをどのように設計する必要がありますか?
- A.
- 1. アプリケーションとインフラストラクチャのソース コードを Git リポジトリに保存します。
- 2. Cloud Build を使用して Terraform でアプリケーション インフラストラクチャをデプロイします。
- 3. アプリケーションをパイプライン ステップとして Cloud Functions にデプロイします。
- B.
- 1. Google Cloud Marketplace から Jenkins をデプロイし、Jenkins で継続的インテグレーション パイプラインを定義します。
- 2. パイプライン ステップを構成して Git リポジトリからアプリケーション ソース コードをプルします。
- 3. アプリケーション ソース コードをパイプライン ステップとして App Engine にデプロイします。
- C.
- 1. Cloud Build で継続的インテグレーション パイプラインを作成し、Deployment Manager テンプレートを使用してアプリケーション インフラストラクチャをデプロイするようにパイプラインを構成します。
- 2. パイプライン ステップを構成して最新のアプリケーション ソース コードを含むコンテナを作成します。
- 3. コンテナをパイプライン ステップとして Compute Engine インスタンスにデプロイします。
- D.
- 1. gcloud コマンドを使用してアプリケーション インフラストラクチャをデプロイします。
- 2. Cloud Build を使用してアプリケーションのソースコードを変更するための継続的インテグレーション パイプラインを定義します。
- 3. Git リポジトリからアプリケーション ソース コードをプルするパイプライン ステップを構成し、コンテナ化されたアプリケーションを作成します。
4. 新しいコンテナをパイプライン ステップとして Cloud Run にデプロイします。
Answer: A
Reference:
–Google Cloud での CI / CD
Question 115
Google Cloud のさまざまなプロジェクトでコンテナを作成して実行しています。
開発中のアプリケーションは Google Kubernetes Engine (GKE) 内から Google Cloud サービスにアクセスする必要があります。
どうすればいいでしょうか?
- A. Google サービス アカウントを GKE ノードに割り当てます。
- B. Google サービス アカウントを使用して Workload Identity で Pod を実行します。
- C. Google サービス アカウントの資格情報を Kubernetes シークレットとして保存します。
- D. GKE ロールベースのアクセス制御 (RBAC) で Google サービス アカウントを使用する。
Answer: B
Question 116
NFS 共有に構成を格納するレガシー アプリケーションをコンテナ化しました。
このアプリケーションを Google Kubernetes Engine (GKE) にデプロイする必要があり、構成が取得されるまでアプリケーションがトラフィックを処理しないようにする必要があります。
どうすればいいでしょうか?
- A. gsutil ユーティリティを使用して起動時に Docker コンテナ内からファイルをコピーし、ENTRYPOINT スクリプトを使用してサービスを開始します。
- B. GKE クラスタに PersistentVolumeClaim を作成します。ボリュームから構成ファイルにアクセスし、ENTRYPOINT スクリプトを使用してサービスを開始します。
- C. Dockerfile で COPY ステートメントを使用して構成をコンテナ イメージにロードします。構成が使用可能であることを確認し、ENTRYPOINT スクリプトを使用してサービスを開始します。
- D. 起動スクリプトを GKE インスタンス グループに追加してノードの起動時に NFS 共有をマウントします。構成ファイルをコンテナにコピーし、ENTRYPOINT スクリプトを使用してサービスを開始します。
Answer: B
Reference:
–Linux VM での起動スクリプトの使用 | Compute Engine ドキュメント | Google Cloud
Question 117
チームは PostgreSQL データベースと Cloud Run を使用して新しいアプリケーションを開発しています。
すべてのトラフィックが Google Cloud で非公開に保たれるようにする責任があります。マネージド サービスを使用し、Google が推奨するベスト プラクティスに従います。
どうすればいいでしょうか?
- A.
- 1. 同じプロジェクトで Cloud SQL と Cloud Run を有効にします。
- 2. Cloud SQL のプライベート IP アドレスを構成し、プライベート サービス アクセスを有効にします。
- 3. サーバレス VPC アクセス コネクタを作成します。
- 4. コネクタを使用して Cloud SQL に接続するように Cloud Run を構成します。
- B.
- 1. PostgreSQL を Compute Engine 仮想マシン (VM) にインストールし、同じプロジェクトで Cloud Run を有効にします。
- 2. VM のプライベート IP アドレスを構成し、プライベート サービス アクセスを有効にします。
- 3. サーバレス VPC アクセス コネクタを作成します。
- 4. コネクタを使用して PostgreSQL をホストする VM に接続するように Cloud Run を構成します。
- C.
- 1. Cloud SQL と Cloud Run を異なるプロジェクトで使用します。
- 2. Cloud SQL のプライベート IP アドレスを構成し、プライベート サービス アクセスを有効にします。
- 3. サーバレス VPC アクセス コネクタを作成します。
- 4. 2 つのプロジェクト間に VPN 接続を設定し、コネクタを使用して Cloud SQL に接続するように Cloud Run を構成します。
- D.
- 1. Compute Engine VM に PostgreSQL をインストールし、さまざまなプロジェクトで Cloud Run を有効にします。
- 2. VM のプライベート IP アドレスを構成し、プライベート サービス アクセスを有効にします。
- 3. サーバレス VPC アクセス コネクタを作成します。
- 4. 2 つのプロジェクト間に VPN 接続を設定し、コネクタを使用して PostgreSQL をホストする VM にアクセスするように Cloud Run を構成します。
Answer: A
Question 118
クライアントが特定の期間、Web サイトからファイルをダウンロードできるようにするアプリケーションを開発しています。
Google が推奨するベスト プラクティスに従いながらこのタスクを完了するにはアプリケーションをどのように設計するべきでしょうか?
- A. ファイルを電子メールの添付ファイルとしてクライアントに送信するようにアプリケーションを構成します。
- B. ファイルの Cloud Storage 署名付き URL を生成して割り当てます。クライアントがダウンロードできる URL を作成します。
- C. 有効期限が指定された一時的な Cloud Storage バケットを作成し、バケットにダウンロード権限を付与します。ファイルをコピーし、クライアントに送信します。
- D. 有効期限が指定された HTTP Cookie を生成します。時間が有効な場合は Cloud Storage バケットからファイルをコピーし、クライアントがファイルをダウンロードできるようにします。
Answer: B
Question 119
開発チームは既存のモノリシック アプリケーションを構成可能な一連のマイクロサービスにリファクタリングするように依頼されました。
新しいアプリケーションに実装する必要のある設計要素はどれでしょうか? (回答は 2 つ)
- A. マイクロサービスの呼び出し元が使用するのと同じプログラミング言語でマイクロサービス コードを開発します。
- B. マイクロサービスの実装とマイクロサービスの呼び出し元の間で API コントラクト アグリーメントを作成します。
- C. すべてのマイクロサービス実装とマイクロサービス呼び出し元の間で非同期通信をリクエストします。
- D. パフォーマンス要件に対応するためにマイクロサービスの十分なインスタンスが実行されていることを確認します。
- E. 現在のインターフェースと互換性がなくなる可能性がある将来の変更を許可するバージョン管理スキームを実装します。
Answer: B
Question 120
新しいアプリケーションを Google Kubernetes Engine にデプロイしましたがパフォーマンスが低下しています。
ログは Cloud Logging に書き込まれ、Prometheus サイドカー モデルを使用して指標を取得しています。ログからのメトリックとデータを関連付けてパフォーマンスの問題をトラブルシューティングし、コストを最小限に抑えながらリアルタイムのアラートを送信する必要があります。
どうすればいいでしょうか?
- A. Cloud Logging ログからカスタム指標を作成し、Prometheus を使用して Cloud Monitoring REST API を使用して結果をインポートします。
- B. Cloud Logging のログと Prometheus 指標を Cloud Bigtable にエクスポートします。クエリを実行して結果を結合し、Google データポータルで分析します。
- C. Cloud Logging のログをエクスポートし、Prometheus 指標を BigQuery にストリーミングします。繰り返しクエリを実行して結果を結合し、Cloud Tasks を使用して通知を送信します。
- D. Prometheus 指標をエクスポートし、Cloud Monitoring を使用してそれらを外部指標として表示します。Cloud Monitoring を構成してログからログベースの指標を作成し、それらを Prometheus データと関連付けます。
Answer:D
Reference:
– Cloud Logging のモニタリング データによる GKE アプリのトラブルシューティング迅速化 | Google Cloud 公式ブログ
– Prometheus 指標の使用 | オペレーション スイート | Google Cloud
Question 121
オンプレミスから Google Cloud への会社のアプリケーションの移行を計画する任務を負っています。
会社のモノリシック アプリケーションは e コマース Web サイトです。アプリケーションは Google Cloud にデプロイされたマイクロサービスに段階的に移行されます。会社の収益の大部分はオンライン販売によって生み出されているため、移行中のリスクを最小限に抑えることが重要です。機能に優先順位を付け、移行する最初の機能を選択する必要があります。
どうすればいいでしょうか?
- A. フロントエンドと製品データベースに統合されている製品カタログを移行します。
- B. フロントエンド、注文データベース、サードパーティの支払いベンダーに統合された支払い処理を移行します。
- C.注文データベース、在庫システム、サードパーティの配送ベンダーと統合された注文フルフィルメントを移行します。
- D. フロントエンド、カート データベース、在庫システム、支払い処理システムに統合されたショッピング カートを移行します。
Answer: A
Question 122
チームは Google Kubernetes Engine で実行されるサービスを開発しています。
チームのコードは Cloud Source Repositories に保存されています。コードを本番環境にデプロイする前に、コードのバグをすばやく特定する必要があります。自動化に投資して開発者のフィードバックを改善し、プロセスをできるだけ効率的にしたいと考えています。
どうすればいいでしょうか?
- A. Spinnaker を使用して Git タグに基づくコードからコンテナ イメージの構築を自動化します。
- B. Cloud Build を使用して Git タグに基づくコードからコンテナ イメージのビルドを自動化します。
- C. Spinnaker を使用して本番環境へのコンテナ イメージのデプロイを自動化します。
- D. Cloud Build を使用してフォークされたバージョンに基づくコードからコンテナ イメージのビルドを自動化します。
Answer: B
Reference:
–Kubernetes Source to Prod | Spinnaker
Question 123
チームは Cloud Identity によって維持されるユーザー ID を使用して実行されるアプリケーションを Google Cloud で開発しています。
アプリケーションの各ユーザーにはメッセージが発行される関連付けられた Cloud Pub/Sub トピックと、同じユーザーが発行されたメッセージを取得する Cloud Pub/Sub サブスクリプションがあります。許可されたユーザーのみが、独自の特定の Cloud Pub/Sub トピックとサブスクリプションをパブリッシュ、サブスクライブできるようにする必要があります。
どうすればいいでしょうか?
- A. リソース レベルでユーザー ID を pubsub.publisher ロールと pubsub.subscriber ロールにバインドします。
- B. プロジェクト レベルでユーザー ID に pubsub.publisher ロールと pubsub.subscriber ロールを付与します。
- C. ユーザー ID に pubsub.topics.create、pubsub.subscriptions.create 権限を含むカスタム ロールを付与します。
- D. pubsub.publisher、pubsub.subscriber ロールを持つサービス アカウントとして実行するようにアプリケーションを構成します。
Answer: A
Question 124
Google Kubernetes Engine の採用と VS Code や IntelliJ を含む開発環境との統合を促進する開発者ツールを評価しています。
どうすればいいでしょうか?
- A. Cloud Code を使用してアプリケーションを開発します。
- B. Cloud Shell 統合コード エディタを使用してコードと構成ファイルを編集します。
- C. Cloud Notebook インスタンスを使用してデータを取り込んで処理し、モデルをデプロイします。
- D. Cloud Shell を使用してコマンドラインからインフラストラクチャとアプリケーションを管理します。
Answer: A
Reference:
–Cloud Code | Google Cloud
Question 125
App Engine スタンダード環境と Memorystore for Redis を使用する e コマース Web アプリケーションを開発しています。
ユーザーがアプリにログインするとアプリケーションはユーザーの情報 (セッション、名前、住所、設定など) をキャッシュします。この情報はチェックアウト時にすばやく取得できるように保存されます。ブラウザでアプリケーションをテストしているときに 502 Bad Gateway エラーが発生します。アプリケーションが Memorystore に接続していないと判断しました。
このエラーの理由は何でしょうか?
- A. Memorystore for Redis インスタンスがパブリック IP アドレスなしでデプロイされました。
- B. App Engine インスタンスとは異なるリージョンでサーバレス VPC アクセス コネクタを構成しました。
- C. DevOps チームによるインフラストラクチャのアップデート中に App Engine と Memorystore 間の接続を許可するファイアウォール ルールが削除されました。
- D. App Engine インスタンスとは異なる可用性の高いゾーンの別のサブネットでサーバレス VPC アクセス コネクタを使用するようにアプリケーションを構成しました。
Answer: B
Reference:
–レスポンス エラーのトラブルシューティング | OpenAPI を使用した Cloud Endpoints | Google Cloud
Question 126
チームは Google Cloud で実行されるサービスを開発しています。
データ処理サービスを構築する必要があり、Cloud Functions を使用します。関数によって処理されるデータは機密情報です。呼び出しが許可されたサービスからのみ行われるようにし、機能を保護するために Google が推奨するベスト プラクティスに従う必要があります。
どうすればいいでしょうか?
- A. プロジェクトで Identity-Aware Proxy を有効にし、権限を使用して機能アクセスを保護します。
- B. Cloud Functions ビューアーの役割を持つサービス アカウントを作成し、そのサービス アカウントを使用して関数を呼び出します。
- C. Cloud Functions Invoker ロールを持つサービス アカウントを作成し、そのサービス アカウントを使用して関数を呼び出します。
- D. 保護する関数と同じプロジェクトで呼び出し元サービスの OAuth 2.0 クライアント ID を作成し、これらの資格情報を使用して関数を呼び出します。
Answer:C
Question 127
アプリケーションを Compute Engine にデプロイしています。
Compute Engine インスタンスの 1 つを起動できませんでした。
どうすればいいでしょうか? (回答は 2 つ)
- A. ファイル システムが破損しているかどうかを確認します。
- B. 別の SSH ユーザーとして Compute Engine にアクセスします。
- C. インスタンスでのファイアウォール ルール、またはルートのトラブルシューティング。
- D. インスタンスの起動ディスクが完全にいっぱいかどうかを確認します。
- E. インスタンスとの間のネットワーク トラフィックがドロップされているかどうかを確認します。
Answer:A、D
Question 128
Web アプリケーションは企業のイントラネットにデプロイされます。
Web アプリケーションを Google Cloud に移行する必要があります。Web アプリケーションは会社の従業員のみが使用でき、出張中に従業員がアクセスできる必要があります。アプリケーションの変更を最小限に抑えながら Web アプリケーションのセキュリティとアクセシビリティを確保する必要があります。
どうすればいいでしょうか?
- A. アプリケーションへの HTTP(S) リクエストごとに認証資格情報を確認するようにアプリケーションを構成します。
- B. Identity-Aware Proxy を構成し、従業員がパブリック IP アドレスを介してアプリケーションにアクセスできるようにします。
- C. ユーザーに企業アカウントへのログインを要求する Compute Engine インスタンスを構成します。Web アプリケーションの DNS を変更してプロキシ Compute Engine インスタンスを指すようにします。認証後、Compute Engine インスタンスは Web アプリケーションとの間でリクエストを転送します。
- D. ユーザーに企業アカウントへのログインを要求する Compute Engine インスタンスを構成します。Web アプリケーションの DNS を変更してプロキシ Compute Engine インスタンスを指すようにします。認証後、Compute Engine は Web アプリケーションをホストするパブリック IP アドレスに HTTP リダイレクトを発行します。
Answer: B
Question 129
HTTP Cloud Functions を使用してデスクトップ ブラウザとモバイル アプリケーション クライアントの両方からのユーザー アクティビティを処理するアプリケーションがあります。
この関数は HTTP POST を使用したすべてのメトリック送信のエンドポイントとして機能します。従来の制限により、関数は Web またはモバイル セッションでユーザーがリクエストしたドメインとは別のドメインにマップする必要があります。Cloud Functions のドメインは https://fn.example.com です。デスクトップおよびモバイル クライアントはドメイン https://www.example.com を使用します。関数の HTTP レスポンスにヘッダーを追加してこれらのブラウザおよびモバイル セッションのみがメトリクスを Cloud Functions に送信できるようにする必要があります。
どのレスポンス ヘッダーを追加するべきでしょうか?
- A. Access-Control-Allow-Origin: *
- B. Access-Control-Allow-Origin: https://*.example.com
- C. Access-Control-Allow-Origin: https://fn.example.com
- D. Access-Control-Allow-origin: https://www.example.com
Answer:D
Question 130
POST 経由で呼び出される HTTP Cloud Functions があります。
各送信のリクエスト本文には数値データとテキスト データを含むフラットでネストされていない JSON 構造があります。Cloud Functions が完了すると収集されたデータは多くのユーザーが並行して進行中の複雑な分析にすぐに利用できるようになります。
サブミッションをどのように永続化する必要がありますか?
- A. 各 POST リクエストの JSON データを Datastore に直接永続化します。
- B. POST リクエストの JSON データを変換し、BigQuery にストリーミングします。
- C. POST リクエストの JSON データを変換し、リージョンの Cloud SQL クラスタに保存します。
- D. 各 POST リクエストの JSON データを個別のファイルとして Cloud Storage 内に保存し、ファイル名にリクエスト識別子を含めます。
Answer: B
Question 131
セキュリティ チームは Google Kubernetes Engine で実行されているすべてのデプロイ済みアプリケーションを監査しています。
監査を完了した後、チームは一部のアプリケーションがクラスタ内のトラフィックをクリア テキストで送信していることを発見しました。アプリケーションへの変更を最小限に抑え、Google からのサポートを維持しながら、すべてのアプリケーション トラフィックをできるだけ迅速に暗号化する必要があります。
どうすればいいでしょうか?
- A. ネットワーク ポリシーを使用し、アプリケーション間のトラフィックをブロックします。
- B. Istio をインストールし、アプリケーションの名前空間でプロキシ インジェクションを有効にしてから mTLS を有効にします。
- C. アプリケーション内で信頼できるネットワークの範囲を定義し、それらのネットワークからのトラフィックのみを許可するようにアプリケーションを構成します。
- D. 自動化されたプロセスを使用してアプリケーションの SSL 証明書を Let’s Encrypt から要求し、それらをアプリケーションに追加します。
Answer: B
Question 132
一部のアプリケーションを Google Cloud に移行しました。
オンプレミスとクラウドにデプロイされたアプリケーションの両方にオンプレミスにデプロイされた従来の監視プラットフォームを使用しています。クラウド アプリケーションのタイム クリティカルな問題に対する通知システムの応答が遅いことがわかりました。
どうすればいいでしょうか?
- A. モニタリング プラットフォームを Cloud Monitoring に置き換えます。
- B. Compute Engine インスタンスに Cloud Monitoring エージェントをインストールします。
- C. 一部のトラフィックを古いプラットフォームに戻します。2 つのプラットフォームで同時に A/B テストを実行します。
- D. Cloud Logging と Cloud Monitoring を使用してログを取得して監視し、アラートを送信します。それらを既存のプラットフォームに送信します。
Answer:D
Question 133
最近、Google Kubernetes Engine にアプリケーションをデプロイしましたがアプリケーションの新しいバージョンをリリースする必要があります。
新しいバージョンで問題が発生した場合に備え、以前のバージョンに即座にロールバックする機能が必要です。
どのデプロイ モデルを使用する必要がありますか?
- A. ローリング デプロイを実行し、デプロイ完了後に新しいアプリケーションをテストします。
- B. A/B テストを実行し、新しいテストが実装された後、定期的にアプリケーションをテストします。
- C. Blue/Green デプロイを実行し、デプロイ後に新しいアプリケーションをテストします。完了。
- D. カナリア デプロイを実行し、新しいバージョンのデプロイ後に新しいアプリケーションを定期的にテストします。
Answer:C
Question 134
Google ドライブの API にアクセスし、ユーザーからファイルを Google ドライブに保存する許可を取得する必要がある JavaScript Web アプリケーションを開発しました。
アプリケーションの承認アプローチを選択する必要があります。
どうすればいいでしょうか?
- A. API キーを作成します。
- B. SAML トークンを作成します。
- C. サービス アカウントを作成します。
- D. OAuth クライアント ID を作成します。
Answer:D
Reference:
–API 固有の承認および認証情報 | Google Drive | Google Developers
Question 135
後にそれらの購入をキャンセルまたは変更できる顧客からの購入を処理する e コマース アプリケーションを管理します。
注文量が非常に変動しやすく、バックエンドの注文処理システムが一度に 1 つの要求しか処理できないことがわかりました。使用量に関係なく、顧客のためにシームレスなパフォーマンスを確保したいと考えています。顧客の注文更新リクエストは生成された順序で実行されることが重要です。
どうすればいいでしょうか?
- A. WebSocket を介して購入および変更要求をバックエンドに送信します。
- B. 購入と変更のリクエストを REST リクエストとしてバックエンドに送信します。
- C. pull モードで Cloud Pub/Sub サブスクライバーを使用し、Datastore を使用して注文を管理します。
- D. push モードで Cloud Pub/Sub サブスクライバーを使用し、Datastore を使用して注文を管理します。
Answer:C
Reference:
– pull サブスクリプション | Cloud Pub/Sub ドキュメント | Google Cloud
Question 136
会社は顧客の購入履歴を保存し、次の要件を満たすデータベース ソリューションを必要としています。
– 顧客は送信後すぐに購入を照会できます。
– さまざまなフィールドで購入をソートできます。
– 異なるレコード形式を同時に保存できます。
これらの要件を満たすストレージ オプションはどれでしょうか?
- A. ネイティブ モードの Cloud Firestore
- B. オブジェクト読み取りを使用した Cloud Storage
- C. SQL SELECT ステートメントを使用した Cloud SQL
- D. グローバル クエリを使用した Datastore モードの Cloud Firestore
Answer: A
Question 137
最近、Cloud Run で新しいサービスを開発しました。
新しいサービスはカスタム サービスを使用して認証し、トランザクション情報を Cloud Spanner データベースに書き込みます。発生するボトルネックを特定しながら、アプリケーションが最大 5,000 の読み取り/秒 および 1,000 の書き込み/秒 トランザクションをサポートできることを確認する必要があり、テスト インフラストラクチャは自動スケーリングできる必要があります。
どうすればいいでしょうか?
- A. テスト ハーネスを構築してリクエストを生成し、それを Cloud Run にデプロイします。Cloud Logging を使用して VPC フロー ログを分析します。
- B. 負荷テストを動的に生成するために Locust または JMeter イメージを実行する Google Kubernetes Engine クラスタを作成します。Cloud Trace を使用して結果を分析します。
- C. Cloud Task を作成してテスト負荷を生成する。Cloud Scheduler を使用して 1 分あたり 60,000 の Cloud Task トランザクションを 10 分間実行します。Cloud Monitoring を使用して結果を分析します。
- D. Marketplace の LAMP スタック イメージを使用する Compute Engine インスタンスを作成し、Apache Bench を使用してサービスに対する負荷テストを生成します。Cloud Trace を使用して結果を分析します。
Answer: B
Question 138
CI / CD パイプラインに Cloud Build を使用して特定のファイルを Compute Engine 仮想マシンにコピーするなど、いくつかのタスクを完了しています。
パイプラインでは同じパイプライン内の後続のビルダーがアクセスできるようにパイプライン内の 1 つのビルダーで生成されたフラット ファイルが必要です。
パイプライン内のすべてのビルダーがファイルにアクセスできるようにするにはファイルをどのように保存するべきでしょうか?
- A. Compute Engine インスタンスのメタデータを使用し、ファイルの内容を保存および取得します。
- B. ファイルの内容を /workspace のファイルに出力します。後続のビルド ステップで同じ /workspace ファイルから読み取ります。
- C. gsutil を使用し、ファイルの内容を Cloud Storage オブジェクトに出力します。後続のビルド ステップで同じオブジェクトから読み取ります。
- D. curl を介して HTTP POST を実行するビルド引数を別の Web サーバに追加して 1 つのビルダーで値を保持します。後続のビルド ステップから curl 経由で HTTP GET を使用して、値を読み取ります。
Answer: B
Question 139
会社の開発チームは Docker ビルドでさまざまなオープン ソース オペレーティング システムを使用したいと考えています。
会社の環境で公開されたコンテナでイメージが作成された場合、それらをスキャンして Common Vulnerabilities and Exposures (CVE) を探す必要があります。スキャン プロセスがソフトウェア開発の俊敏性に影響を与えてはなりません。可能な限りマネージド サービスを使用したいと考えています。
どうすればいいでしょうか?
- A. Container Registry で脆弱性スキャン設定を有効にします。
- B. コードのチェックインでトリガーされる Cloud Functions を作成し、CVE のコードをスキャンします。
- C. 開発環境で非商用ベース イメージの使用を禁止します。
- D. Cloud Monitoring を使用して Cloud Build の出力を確認し、脆弱なバージョンが使用されているかどうかを判断します。
Answer: A
Question 140
Cloud Build を使用して継続的インテグレーション パイプラインを構成し、Google Kubernetes Engine (GKE) への新しいコンテナ イメージのデプロイを自動化しています。
パイプラインはソース コードからアプリケーションをビルドし、個別のステップで単体テストと統合テストを実行し、コンテナを Container Registry にプッシュします。アプリケーションは Python Web サーバ上で実行されます。
Dockerfile は次のとおりです。
FROM python:3.7-alpine -
COPY . /app -
WORKDIR /app -
RUN pip install -r requirements.txt
CMD [ "gunicorn", "-w 4", "main:app" ]Cloud Build の実行が完了するまでに予想以上の時間がかかっていることに気付きました。ビルド時間を短縮したいと思っています。
どうすればいいでしょうか? (回答は 2 つ)
- A. Cloud Build の実行にはより高い CPU を備えた仮想マシン (VM) のサイズを選択します。
- B. VPC 内の Compute Engine VM に Container Registry をデプロイし、それを使用して最終的なイメージを保存します。
- C. ビルド構成ファイルで –cache-from 引数を使用し、後続のビルドのために Docker イメージをキャッシュします。
- D. Dockerfile の基本イメージを ubuntu:latest に変更し、パッケージ マネージャー ユーティリティを使用して Python 3.7 をインストールします。
- E. アプリケーションのソースコードを Cloud Storage に保存し、gsutil を使用してソースコードをダウンロードするようにパイプラインを構成します。
Answer:A、C
Question 141
バージョン管理システム、Cloud Build、Container Registry で構成される CI / CD パイプラインを構築しています。
新しいタグがリポジトリにプッシュされるたびに Cloud Build ジョブがトリガーされます。このジョブは、新しいコードで単体テストを実行し、新しい Docker コンテナ イメージをビルドして、それを Container Registry にプッシュします。パイプラインの最後のステップでは、新しいコンテナを本番環境の Google Kubernetes Engine (GKE) クラスタにデプロイする必要があります。次の要件を満たすツールとデプロイ戦略を選択する必要があります。
– ゼロダウンタイムが発生します
– テストは完全に自動化されています
– ユーザーにロールアウトする前にテストできる
– 必要に応じてすばやくロールバックできます
どうすればいいでしょうか?
- A. 新しいコードの A/B テストとして構成された Spinnaker パイプラインをトリガーし、成功した場合はコンテナを本番環境にデプロイします。
- B. 新しいコードのカナリア テストとして構成された Spinnaker パイプラインをトリガーし、成功した場合はコンテナを運用環境にデプロイします。
- C. Kubernetes CLI ツールを使用して別の Cloud Build ジョブをトリガーし、カナリア テストを実行できる GKE クラスタに新しいコンテナをデプロイします。
- D. Kubernetes CLI ツールを使用する別の Cloud Build ジョブをトリガーし、シャドーテストを実行できる GKE クラスタに新しいコンテナをデプロイします。
Answer:D
Reference:
–アプリケーションのデプロイとテストの戦略 #シャドーテスト パターン | Cloud アーキテクチャ センター | Google Cloud
Question 142
運用チームからプロジェクト内で実行されている Cloud Bigtable、Memorystore、Cloud SQL データベースを一覧表示するスクリプトを作成するよう依頼されました。
スクリプトではユーザーがフィルター式を送信して表示される結果を制限できるようにする必要があります。
どのようにデータを取得しますか?
- A. HBase API、Redis API、MySQL 接続を使用してデータベース リストを取得します。結果を結合し、フィルタを適用して結果を表示します
- B. HBase API、Redis API、MySQL 接続を使用してデータベース リストを取得します。結果を個別にフィルタを適応してそれらを組み合わせて結果を表示します
- C. gcloud bigtable instances list、gcloud redis instances list、gcloud sql databases list を実行します。アプリケーション内でフィルタを使用し、結果を表示します
- D. gcloud bigtable instances list、gcloud redis instances list、gcloud sql databases list を実行します。各コマンドで –filter フラグを使用し、結果を表示します
Answer:D
Question 143
Google Kubernetes Engine でホストされている新しいヨーロッパ バージョンの Web サイトをデプロイする必要があります。
現在の Web サイトと新しい Web サイトは同じ HTTP(S) ロードバランサの外部 IP アドレスを介してアクセスする必要がありますがドメイン名は異なります。
どうすればいいでしょうか?
- A. 新しいドメインに一致するホスト ルールで新しい Ingress リソースを定義します。
- B. 新しいドメインに一致するホスト ルールで既存の Ingress リソースを変更します。
- C. 既存の IP アドレスを loadBalancerIP として指定して、タイプ LoadBalancer の新しいサービスを作成します。
- D. 新しい Ingress リソースを生成し、既存の IP アドレスを kubernetes.io/ingress.global-static-ip-name アノテーション値として指定します
Answer: B
Question 144
ユーザーが昼夜を問わずゲームを操作するため、トラフィック パターンが予測できないシングルプレイヤー モバイル ゲーム バックエンドを開発しています。
リクエストを処理するのに十分なリソースを確保することでコストを最適化しながら過剰なプロビジョニングを最小限に抑える必要があります。また、トラフィックの急増を効率的に処理するシステムも必要です。
どのコンピューティング プラットフォームを使用するべきでしょうか?
- A. Cloud Run
- B. マネージド インスタンス グループを使用する Compute Engine
- C. 非マネージド インスタンス グループを使用する Compute Engine
- D. クラスタの自動スケーリングを使用する Google Kubernetes Engine
Answer: A
Question 145
会社の開発チームはローカル環境からリソースを管理したいと考えています。
各チームの Google Cloud プロジェクトへのデベロッパー アクセスを有効にするよう依頼されました。Google が推奨するベスト プラクティスに従って効率を最大化します。
どうすればいいでしょうか?
- A. ユーザーをプロジェクトに追加し、関連する役割をユーザーに割り当て、関連する各プロジェクト ID をユーザーに提供します。
- B. ユーザーをプロジェクトに追加し、関連する役割をユーザーに割り当て、関連する各プロジェクト番号をユーザーに提供します。
- C. グループを作成し、ユーザーをそのグループに追加し、関連する役割をグループに割り当ててから、関連する各プロジェクト ID をユーザーに提供します。
- D. グループを作成し、ユーザーをグループに追加し、関連する役割をグループに割り当ててから、関連する各プロジェクト番号をユーザーに提供します。
Answer:C
Question 146
会社の製品チームには Google Kubernetes Engine (GKE) クラスタで実行されているステートレスな分散サービスを自動スケーリングするという顧客の要求に基づく新しい要件があります。
この機能は 2 週間後に公開されるため、変更を最小限に抑えるソリューションを見つけたいと考えています。
どうすればいいでしょうか?
- A. 垂直 Pod 自動スケーリングをデプロイし、CPU 負荷に基づいてスケーリングします。
- B. 垂直 Pod 自動スケーリングをデプロイし、カスタム指標に基づいてスケーリングします。
- C. 水平 Pod 自動スケーリングをデプロイし、CPU 負荷に基づいてスケーリングします。
- D. 水平 Pod 自動スケーリングをデプロイし、カスタム指標に基づいてスケーリングします。
Answer:C
Question 147
アプリケーションは Compute Engine で実行されるコードによって編成された一連の疎結合サービスで構成されています。
特定のバージョンのサービスを見つけて使用する新しい Compute Engine インスタンスをアプリケーションで簡単に立ち上げたいと考えています。
これはどのように構成しますか?
- A. サービス エンドポイント情報を実行時に取得され、目的のサービスへの接続に使用されるメタ データとして定義します。
- B. サービス エンドポイント情報を実行時に取得され、目的のサービスへの接続に使用されるラベル データとして定義します。
- C. 実行時に環境変数から取得され、目的のサービスへの接続に使用されるサービス エンドポイント情報を定義します。
- D. サービスを定義して、固定のホスト名とポートを使用して目的のサービスに接続します。エンドポイントのサービスを新しいバージョンに置き換えます。
Answer: B
Question 148
Google Kubernetes Engine (GKE) で実行されるマイクロサービス ベースのアプリケーションを開発しています。
一部のサービスはさまざまな Google Cloud API にアクセスする必要があります。
Google が推奨するベスト プラクティスに従って、クラスタでこれらのサービスの認証をどのように設定しますか? (回答は 2 つ)
- A. GKE ノードにアタッチされたサービス アカウントを使用します。
- B. gcloud コマンドライン ツールを使用し、クラスタで Workload Identity を有効にします。
- C. シークレット管理サービスから Google サービス アカウント キーにアクセスします。
- D. Google サービス アカウント キーを中央シークレット管理サービスに保存します。
- E. gcloud を使用し、roles/iam.workloadIdentity を使用して Kubernetes サービス アカウントと Google サービス アカウントをバインドします。
Answer:B、E
Question 149
開発チームは .NET レガシ アプリケーションの保守を任されています。
アプリケーションは時折変更され、最近更新されました。目標は環境から環境へと CI / CD パイプラインを移動しながら、アプリケーションが一貫した結果を提供できるようにすることです。外部要因とホスティング環境間の依存関係が問題にならないようにしながら、デプロイ コストを最小限に抑える必要がありますがコンテナは組織でまだ承認されていません。
どうすればいいでしょうか?
- A. .NET Core を使用してアプリケーションを書き直し、Cloud Run にデプロイします。リビジョンを使用して環境を分離します。
- B. Cloud Build を使用してビルドごとに新しい Compute Engine イメージとしてアプリケーションをデプロイします。各環境でこのイメージを使用します。
- C. MS Web Deploy を使用してアプリケーションをデプロイし、常に最新のパッチ適用済み MS Windows Server ベース イメージを Compute Engine で使用するようにします。
- D. Cloud Build を使用してアプリケーションをパッケージ化し、Google Kubernetes Engine クラスタにデプロイします。名前空間を使用して環境を分離します。
Answer: B
Question 150
コンテナ化されたアプリケーションの新しいバージョンはテスト済みで Google Kubernetes Engine の本番環境にデプロイする準備ができています。
運用前の環境で新しいバージョンの完全な負荷テストを行うことができなかったため、デプロイ後にパフォーマンスの問題がないことを確認する必要があり、デプロイは自動化する必要があります。
どうすればいいでしょうか?
- A. Cloud Load Balancing を使用し、バージョン間のトラフィックをゆっくりと増やします。Cloud Monitoring を使用してパフォーマンスの問題を探します。
- B. カナリア デプロイを使用し、継続的デリバリー パイプラインを介してアプリケーションをデプロイします。Cloud Monitoring を使用してパフォーマンスの問題を探します。メトリックがサポートするようにトラフィックを増加させます。
- C. Blue/Green デプロイを使用し、継続的デリバリー パイプラインを介してアプリケーションをデプロイします。Cloud Monitoring を使用してパフォーマンスの問題を探し、指標がそれをサポートしているときに完全に起動します。
- D. kubectl を使用してアプリケーションをデプロイし、spec.updateStrategv.type を RollingUpdate に設定します。Cloud Monitoring を使用してパフォーマンスの問題を探し、問題がある場合は kubectl rollback コマンドを実行します。
Answer:D
Question 151
Cloud Run でホストされている Web サイトのトラフィックが急増したときの応答が遅すぎると、ユーザーから苦情が寄せられています。
トラフィックのピーク時により優れたユーザー エクスペリエンスを提供したいと考えています。
どうすればいいでしょうか?
- A. アプリケーションの起動時にデータベースからアプリケーション構成と静的データを読み取ります。
- B. ビルド時にアプリケーション構成と静的データをアプリケーション イメージにパッケージ化します。
- C. 応答がユーザーに返された後、バックグラウンドで可能な限り多くの作業を実行します。
- D. タイムアウトの例外とエラーによって Cloud Run インスタンスがすぐに終了し、代わりのインスタンスを開始できるようにします。
Answer: B
Question 152
あなたは、給与処理用の内部アプリケーションに取り組んでいる開発者です。
従業員がタイムシートを送信できるようにするアプリケーションのコンポーネントを構築しています。これにより、いくつかの手順が開始されます。
– タイムシートが送信されたことを通知する電子メールが従業員とマネージャーに送信されます。
– ベンダーの API の給与処理にタイムシートが送信されます。
– 人数計画のためにタイムシートがデータ ウェアハウスに送信されます。
これらの手順は相互に依存しておらず、任意の順序で完了することができます。新しいステップが検討されており、異なる開発チームによって実装されます。各開発チームは、それぞれのステップに固有のエラー処理を実装します。
どうすればいいでしょうか?
- A. 対応するダウンストリーム システムを呼び出して必要なアクションを完了するステップごとに、Cloud Function をデプロイします。
- B. 各ステップの Pub/Sub トピックを作成します。ダウンストリーム開発チームごとにサブスクリプションを作成して、ステップのトピックをサブスクライブします。
- C. タイムシート提出用の Pub/Sub トピックを作成する。下流の開発チームごとにサブスクリプションを作成して、トピックをサブスクライブします。
- D. Google Kubernetes Engine にデプロイされるタイムシート マイクロサービスを作成します。マイクロサービスは、各ダウンストリーム ステップを呼び出し、正常な応答を待ってから次のステップを呼び出します。
Answer:C
Question 153
マイクロサービス アーキテクチャを使用するアプリケーションを設計しています。
クラウドとオンプレミスにアプリケーションをデプロイする予定です。アプリケーションがオンデマンドでスケールアップできるようにし、マネージド サービスを可能な限り使用できるようにする必要があります。
どうすればいいでしょうか?
- A. Anthos によって管理される複数の Google Kubernetes Engine (GKE) クラスタ上のマルチクラスタ デプロイでオープンソースの Istio をデプロイします。
- B. Anthos を使用して各環境に GKE クラスタを作成し、Cloud Run for Anthos を使用してアプリケーションを各クラスタにデプロイします。
- C. Anthos を使用して各環境に GKE クラスタをインストールし、Cloud Build を使用して各クラスタにアプリケーションの Deployment を作成します。
- D. クラウドに GKE クラスタを作成し、オープンソースの Kubernetes をオンプレミスにインストールします。外部ロードバランサ サービスを使用し、2 つの環境にトラフィックを分散します。
Answer: B
Question 154
Knative で実行されているオンプレミス コンテナを Google Cloud に移行したいと考えています。
移行がアプリケーションのデプロイ戦略に影響を与えないようにする必要があり、完全に管理されたサービスを使用したいと考えています。
コンテナをデプロイするには、どの Google Cloud サービスを使用しますか?
- A. Cloud Run
- B. Compute Engine
- C. Google Kubernetes Engine
- D. App Engine フレキシブル環境
Answer: A
Question 155
このアーキテクチャ図は何千ものデバイスからデータをストリーミングするシステムを示しています。
パイプラインにデータを取り込み、データを保存し、SQL ステートメントを使用してデータを分析したいと考えています。
ステップ 1、2、3、4 で使用する Google Cloud サービスはどれでしょうか?
- A.
- 1. App Engine
- 2. Cloud Pub/Sub
- 3. BigQuery
- 4. Cloud Firestore
- B.
- 1. Dataflow
- 2. Cloud Pub/Sub
- 3. Cloud Firestore
- 4. BigQuery
- C.
- 1. Cloud Pub/Sub
- 2. Dataflow
- 3. BigQuery
- 4. Cloud Firestore
- D.
- 1. Cloud Pub/Sub
- 2. Dataflow
- 3. Cloud Firestore
- 4. BigQuery
Answer:D
Question 156
会社ではゾーン障害によるGoogle Kubernetes Engine (GKE) API停止が発生したばかりです。
将来ゾーンで障害が発生した場合にユーザーへのサービスの中断を最小限に抑え、可用性の高い GKE アーキテクチャをデプロイしたいと考えています。
どうすればいいでしょうか?
- A. ゾーン クラスタをデプロイします。
- B. リージョン クラスタをデプロイします。
- C. マルチゾーン クラスタをデプロイします。
- D. GKE オンプレミス クラスタをデプロイします。
Answer: B
Question 157
チームは Google Cloud で実行されるサービスを開発しています。
Cloud Pub/Sub トピックに送信されたメッセージを処理してから保存したいと考えています。データの重複やデータの競合を避けるために、各メッセージは 1 回だけ処理する必要があります。最も安価で最もシンプルなソリューションを使用する必要があります。
どうすればいいでしょうか?
- A. Dataproc ジョブでメッセージを処理し、出力をストレージに書き込みます。
- B. Apache Beam の PubSubIO パッケージを使用して Dataflow ストリーミング パイプラインでメッセージを処理し、出力をストレージに書き込みます。
- C. Cloud Functions を使用してメッセージを処理し、データを重複排除するジョブを実行できる BigQuery の場所に結果を書き込みます。
- D. Dataflow ストリーミング パイプラインでメッセージを取得して Cloud Bigtable に保存し、別の Dataflow ストリーミング パイプラインを使用してメッセージの重複を取り除きます。
Answer: B
Question 158
Google Kubernetes Engine でコンテナ化されたアプリケーションを実行しています。
コンテナ イメージは Container Registry に保存されます。チームは CI / CD プラクティスを使用しています。既知の重大な脆弱性を持つコンテナのデプロイを防ぐ必要があります。
どうすればいいでしょうか?
- A.
- – Web Security Scanner を使用してアプリケーションを自動的にクロールします
- – アプリケーション ログでスキャン結果を確認し、コンテナに既知の重大な脆弱性がないことを証明します。
- – Binary Authorization を使用してコンテナがデプロイされる前に証明書の提供を強制するポリシーを実装します。
- B.
- – Web Security Scanner を使用してアプリケーションを自動的にクロールします。
- – Cloud Console のスキャンの詳細ページでスキャン結果を確認し、コンテナに既知の重大な脆弱性がないことを証明します。
- – Binary Authorization を使用してコンテナがデプロイされる前に証明書の提供を強制するポリシーを実装します。
- C.
- – Container Scanning API を有効にして脆弱性スキャンを実行します。
- – Cloud Console の Container Registry で脆弱性レポートを確認し、コンテナに既知の重大な脆弱性がないことを証明します
- – Binary Authorization を使用してコンテナがデプロイされる前に証明書の提供を強制するポリシーを実装します。
- D.
- – Container Scanning API を有効にして脆弱性スキャンを実行します。
- – Container Scanning API を介してプログラムで脆弱性レポートを確認し、コンテナに既知の重大な脆弱性がないことを証明します。
- – Binary Authorization を使用してコンテナがデプロイされる前に証明書の提供を強制するポリシーを実装します。
Answer:D
Question 159
ユーザーが管理するキーとユーザーが管理するサービス アカウントを使用して Cloud Storage API に対して認証するオンプレミス アプリケーションがあります。
アプリケーションは Dedicated Interconnect リンクを介して限定公開の Google アクセスを使用して Cloud Storage に接続します。Cloud Storage バケット内のオブジェクトにアクセスするためのアプリケーションからのリクエストが 403 Permission Denied エラー コードで失敗していることに気付きました。
この問題の考えられる原因は何でしょうか?
- A. バケット内のフォルダ構造とオブジェクト パスが変更されている。
- B. サービス アカウントの定義済みロールの権限が変更されている。
- C. サービス アカウント キーがローテーションされましたが、アプリケーション サーバで更新されていない。
- D. オンプレミス データセンターから Google Cloud への Interconnect リンクが一時的に停止されている。
Answer:C
Question 160
Cloud クライアント ライブラリを使用し、アプリケーション内の画像を Cloud Storage にアップロードしています。
アプリケーションのユーザーはアップロードが完了しないことがあると報告し、クライアント ライブラリは HTTP 504 ゲートウェイ タイムアウト エラーを報告します。アプリケーションのエラーに対する回復力を高めたいと考えています。
アプリケーションにどのような変更を加える必要がありますか?
- A. クライアント ライブラリ呼び出しの周りに指数バックオフ プロセスを記述します。
- B. クライアント ライブラリ呼び出しの周りに 1 秒の待機時間のバックオフ プロセスを記述します。
- C. アプリケーションに再試行ボタンを設計し、エラーが発生した場合にクリックするようユーザーに依頼します。
- D. オブジェクトのキューを作成し、アプリケーションが 10 分後に再試行することをユーザーに通知します。
Answer: A
Question 161
階層データ構造をデータベースに格納するモバイル アプリケーションを構築しています。
このアプリケーションにより、オフラインで作業しているユーザーはオンラインに戻ったときに変更を同期できます。バックエンド サービスは、サービス アカウントを使用してデータベース内のデータを強化します。このアプリケーションは非常に人気があると予想され、シームレスかつ安全にスケーリングする必要があります。
どのデータベースと IAM ロールを使用しますか?
- A. Cloud SQL を使用して roles/cloudsql.editor ロールをサービス アカウントに割り当てます。
- B. Cloud Bigtable を使用し、roles/bigtable.viewer ロールをサービス アカウントに割り当てます。
- C. Cloud Firestore をネイティブ モードで使用し、roles/datastore.user ロールをサービス アカウントに割り当てます。
- D. Cloud Firestore を Datastore モードで使用し、roles/datastore.viewer ロールをサービス アカウントに割り当てます。
Answer:C
Question 162
アプリケーションは複数のゾーンのマネージド インスタンス グループ (MIG) 内の数百の Compute Engine インスタンスにデプロイされています。
重大な脆弱性をすぐに修正するために新しいインスタンス テンプレートをデプロイする必要がありますが、サービスへの影響を回避する必要があります。
インスタンス テンプレートを更新した後、MIG に対してどのような設定を行う必要がありますか?
- A. 最大サージを 100% に設定します。
- B. 更新モードを日和見に設定します。
- C. 最大使用不可を 100% に設定します。
- D. 最小待機時間を 0 秒に設定します。
Answer:D
Question 163
Compute Engine インスタンスが通常の実行レベルで起動するのを妨げる低レベルの Linux 構成ファイルに入力ミスがあります。
今日、Compute Engine インスタンスを作成したばかりでファイルの調整以外のメンテナンスは行っていません。
このエラーをどのように修正する必要がありますか?
- A. scp を使用してファイルをダウンロードし、ファイルを変更してから変更したバージョンをアップロードします。
- B. SSH 経由で Compute Engine インスタンスを構成してログインし、ファイルを変更します。
- C. シリアル ポート経由で Compute Engine インスタンスを構成してログインし、ファイルを変更します。
- D. リモート デスクトップ クライアントを使用して Compute Engine インスタンスを構成してログインし、ファイルを変更する
Answer:C
Question 164
ユーザーに属するファイルを Cloud Storage に保存する必要があるアプリケーションを開発しています。
各ユーザーが Cloud Storage に独自のサブディレクトリを持つようにします。新しいユーザーが作成されると対応する空のサブディレクトリも作成されます。
どうすればいいでしょうか?
- A. 長さが 0 バイトの末尾のスラッシュ (‘/’) で終わるサブディレクトリの名前を持つオブジェクトを作成します。
- B. サブディレクトリの名前でオブジェクトを作成し、そのサブディレクトリ内のオブジェクトをすぐに削除します。
- C. 長さが 0 バイトで WRITER アクセス制御リスト許可を持つサブディレクトリの名前を持つオブジェクトを作成します。
- D. 長さが 0 バイトのサブディレクトリの名前を持つオブジェクトを作成します。Content-Type メタデータを CLOUDSTORAGE_FOLDER に設定します。
Answer: A
Question 165
会社の企業ポリシーではすべてのソース ファイルの最初に著作権に関するコメントが必要であると規定されています。
各ソース commit によってトリガーされるカスタム ステップを Cloud Build に記述したいと考えています。ソースに著作権が含まれていることを検証し、含まれていない場合は後続のステップのために追加するトリガーが必要です。
どうすればいいでしょうか?
- A. /workspace 内のファイルを調べ、各ソース ファイルの著作権を確認して追加する新しい Docker コンテナを構築します。変更されたファイルはソース リポジトリに明示的にコミットされます。
- B. /workspace 内のファイルを調べ、各ソース ファイルの著作権を確認して追加する新しい Docker コンテナを構築します。変更されたファイルをソース リポジトリにコミットする必要はありません。
- C. Cloud Storage バケット内のファイルを調べ、各ソース ファイルの著作権を確認して追加する新しい Docker コンテナを構築します。変更されたファイルは Cloud Storage バケットに書き戻されます。
- D. Cloud Storage バケット内のファイルを調べ、各ソース ファイルの著作権を確認して追加する新しい Docker コンテナを構築します。変更されたファイルはソース リポジトリに明示的にコミットされます。
Answer: A
Question 166
Google Kubernetes Engine (GKE) にデプロイされたアプリケーションの 1 つで断続的なパフォーマンスの問題が発生しています。
チームはサードパーティのログ ソリューションを使用しています。ログを表示できるように GKE クラスタの各ノードにこのソリューションをインストールします。
どうすればいいでしょうか?
- A. サードパーティのソリューションを DaemonSet としてデプロイします。
- B. コンテナ イメージを変更して監視ソフトウェアを含めます。
- C. SSH を使用して GKE ノードに接続し、ソフトウェアを手動でインストールします。
- D. Terraform を使用してサードパーティ ソリューションをデプロイし、ロギング Pod を Kubernetes デプロイとしてデプロイします。
Answer: A
Question 167
この問題は HipLocal のケーススタディを参照してください。
ユーザーの大幅な増加に対応できるようにアプリケーションをスケーリングするには HipLocal がアーキテクチャをどのように再設計しますか?
- A. Google Kubernetes Engine (GKE) を使用し、アプリケーションをマイクロサービスとして実行します。専用の GKE ノードで MySQL データベースを実行します。
- B. 複数の Compute Engine インスタンスを使用して MySQL を実行し、状態情報を保存します。GCP マネージド ロードバランサを使用してインスタンス間で負荷を分散します。スケーリングにはマネージド インスタンス グループを使用します。
- C. Memorystore を使用してセッション情報を保存し、CloudSQL を使用して状態情報を保存する。GCP マネージド ロードバランサを使用してインスタンス間で負荷を分散します。スケーリングにはマネージド インスタンス グループを使用します。
- D. Cloud Storage バケットを使用してアプリケーションを静的 Web サイトとして提供し、別の Cloud Storage バケットを使用してユーザー状態情報を保存します。
Answer:C
Question 168
この問題は HipLocal のケーススタディを参照してください。
機能要件を満たす安定したテスト環境を QA チームに提供し続けながら HipLocal は API 開発速度をどのように向上させますか?
- A. コードに単体テストを含め、すべてのテストが合格ステータスになるまで QA へのデプロイを防止します。
- B. コードにパフォーマンス テストを含め、すべてのテストが合格ステータスになるまで QA へのデプロイを禁止します。
- C. QA 環境のヘルスチェックを作成し、環境が正常でない場合は後で API を再デプロイします。
- D. トラフィック分割を使用して API を App Engine に再デプロイします。エラーが見つかった場合は QA トラフィックを新しいバージョンに移動しないでください。
Answer: A
Question 169
この問題は HipLocal のケーススタディを参照してください。
HipLocal のアプリケーションは Cloud Client Libraries を使用して Google Cloud とやり取りします。
HipLocal はアプリケーションの最小特権アクセスを実装するために Cloud クライアント ライブラリで認証と承認を構成する必要があります。
どうすればいいでしょうか?
- A. API キーを作成します。API キーを使用して Google Cloud とやり取りします。
- B. デフォルトのコンピューティング サービス アカウントを使用して Google Cloud とやり取りする。
- C. アプリケーションのサービス アカウントを作成します。アプリケーションの秘密鍵をエクスポートしてデプロイします。サービス アカウントを使用して Google Cloud とやり取りします。
- D. アプリケーションとアプリケーションで使用される各 Google Cloud API のサービス アカウントを作成します。アプリケーションで使用される秘密鍵をエクスポートしてデプロイします。1 つの Google Cloud API でサービス アカウントを使用し、Google Cloud とやり取りします。
Answer:C
Question 170
オンプレミス データセンターを Google Cloud に移行する最終段階にいます。
締め切りが迫っており、廃止予定のサーバで Web API が実行されていることを発見しました。Google Cloud への移行中にこの API をモダナイズするためのソリューションを推奨する必要があります。
最新の Web API は次の要件を満たす必要があります。
– 毎月末のトラフィックの多い時間帯に自動スケーリング
– Python 3.x で書かれています
– 開発者は頻繁なコード変更に対応して新しいバージョンを迅速にデプロイできなければなりません
この移行のコスト、労力、運用上のオーバーヘッドを最小限に抑える必要があります。
どうすればいいでしょうか?
- A. App Engine フレキシブル環境にコードをモダナイズしてデプロイします。
- B. App Engine スタンダード環境でコードをモダナイズしてデプロイします。
- C. モダナイズされたアプリケーションを n1-standard-1 Compute Engine インスタンスにデプロイします。
- D. 開発チームにアプリケーションを書き直して Google Kubernetes Engine で Docker コンテナとして実行するよう依頼します。
Answer: B
Question 171
Google Kubernetes Engine クラスタで実行される複数のマイクロサービスで構成されるアプリケーションを開発しています。
1 つのマイクロサービスはオンプレミスで実行されているサードパーティ データベースに接続する必要があります。資格情報をデータベースに保存し、セキュリティのベスト プラクティスに従ってこれらの資格情報をローテーションできるようにする必要があります。
どうすればいいでしょうか?
- A. 認証情報をサイドカー コンテナ プロキシに保存し、それを使用してサードパーティ データベースに接続します。
- B. サービス メッシュを構成し、マイクロサービスの Pod からデータベースへのトラフィックを許可または制限します。
- C. 認証情報を暗号化されたボリューム マウントに保存し、Persistent Volume Claim をクライアント Pod に関連付けます。
- D. 資格情報を Kubernetes シークレットとして保存し、Cloud Key Management Service プラグインを使用して暗号化と復号化を処理します。
Answer:D
Question 172
Google Cloud で実行される会社の e コマース プラットフォームの支払いシステムを管理します。
会社は内部監査目的で 1 年間、コンプライアンス要件を満たすために 3 年間、ユーザー ログを保持する必要があります。オンプレミス ストレージの使用量を最小限に抑え、簡単に検索できるようにするには新しいユーザー ログを Google Cloud に保存する必要があります。ログが正しく保存されていることを確認しながら、労力を最小限に抑えたいと考えています。
どうすればいいでしょうか?
- A. バケット ロックがオンになっている Cloud Storage バケットにログを保存します。
- B. 3 年間の保持期間で Cloud Storage バケットにログを保存します。
- C. ログを Cloud Logging にカスタムの保持期間を持つカスタム ログとして保存します。
- D. 1 年間の保持期間で Cloud Storage バケットにログを保存します。1 年後、保持期間が 2 年の別のバケットにログを移動します。
Answer:C
Question 173
会社には Google Cloud に保存されているすべてのデータを顧客管理の暗号鍵で暗号化することを要求する新しいセキュリティ イニシアチブがあります。
Cloud Key Management Service (KMS) を使用して鍵へのアクセスを構成する予定です。「職務分離」の原則とGoogle が推奨するベスト プラクティスに従う必要があります。
どうすればいいでしょうか? (回答は 2 つ)
- A. 独自のプロジェクトで Cloud KMS をプロビジョニングします。
- B. Cloud KMS プロジェクトに所有者を割り当てないでください。
- C. キーが使用されているプロジェクトで Cloud KMS をプロビジョニングします。
- D. Cloud KMS のキーが使用されているプロジェクトのオーナーに roles/cloudkms.admin ロールを付与します。
- E. Cloud KMS の鍵が使用されているプロジェクトの所有者とは異なるユーザーに Cloud KMS プロジェクトの所有者の役割を付与します。
Answer:A、B
Question 174
オンプレミスの Linux 仮想マシン (VM) で実行されているスタンドアロン Java アプリケーションを費用対効果の高い方法で Google Cloud に移行する必要があります。
リフト アンド シフト アプローチを採用しないことに決め、代わりにアプリケーションをコンテナに変換して最新化することを計画しています。
このタスクをどのように達成する必要がありますか?
- A. Migrate for Anthos を使用し、VM をコンテナとして Google Kubernetes Engine (GKE) クラスタに移行します。
- B. VM を raw ディスクとしてエクスポートし、イメージとしてインポートします。インポートしたイメージから Compute Engine インスタンスを作成します。
- C. Migrate for Compute Engine を使用して VM を Compute Engine インスタンスに移行し、Cloud Build を使用してそれをコンテナに変換します。
- D. Jib を使用してソース コードから Docker イメージを構築し、Artifact Registry にアップロードします。アプリケーションを GKE クラスタにデプロイし、アプリケーションをテストします。
Answer:D
Question 175
最近、組織はレガシー アプリケーションを Google Kubernetes Engine に再プラットフォーム化する取り組みを開始しました。
モノリシック アプリケーションをマイクロサービスに分解する必要があります。複数のインスタンスには共有ファイル システムに保存されている構成ファイルへの読み取りおよび書き込みアクセス権があります。この移行を管理するために必要な労力を最小限に抑え、アプリケーション コードの書き直しを避けたいと考えています。
どうすればいいでしょうか?
- A. 新しい Cloud Storage バケットを作成し、FUSE を介してコンテナにマウントします。
- B. 新しい永続ディスクを作成し、ボリュームを共有 PersistentVolume としてマウントします。
- C. 新しい Filestore インスタンスを作成し、ボリュームを NFS PersistentVolume としてマウントします。
- D. 新しい ConfigMap と volumeMount を作成して、構成ファイルの内容を保存します。
Answer:C
Question 176
開発チームは Java を使用していくつかの Cloud Functions を構築し、対応する統合およびサービス テストも行いました。
関数をビルドしてデプロイし、Cloud Build を使用してテストを開始します。Cloud Build ジョブは、コードの検証に成功した直後にデプロイの失敗を報告しています。
どうすればいいでしょうか?
- A. Cloud Functions インスタンスの最大数を確認します。
- B. Cloud Build トリガーに正しいビルド パラメータがあることを確認します。
- C. truncated exponential backoff ポーリング戦略を使用してテストを再試行します。
- D. Cloud Build サービス アカウントに Cloud Functions 開発者ロールが割り当てられていることを確認します。
Answer:D
Question 177
Istio を使用して Google Kubernetes Engine (GKE) でマイクロサービス アプリケーションを管理します。
GKE クラスタに Istio AuthorizationPolicy、Kubernetes NetworkPolicy、mTLS を実装することでマイクロサービス間の通信チャネルを保護します。特定の URL への 2 つの Pod 間の HTTP リクエストが失敗し、他の URL への他のリクエストは成功することがわかりました。
接続の問題の原因は何でしょうか?
- A. Kubernetes NetworkPolicy リソースが Pod 間の HTTP トラフィックをブロックしています。
- B. HTTP リクエストを開始する Pod が正しくない TCP ポートを介してターゲット Pod に接続しようとしています。
- C. クラスタの承認ポリシーがアプリケーション内の特定のパスに対する HTTP 要求をブロックしている。
- D. クラスタには許可モードで構成された mTLS がありますが Pod のサイドカー プロキシは暗号化されていないトラフィックをプレーン テキストで送信しています。
Answer:C
Question 178
最近、オンプレミスのモノリシック アプリケーションを Google Kubernetes Engine (GKE) のマイクロサービス アプリケーションに移行しました。
このアプリケーションは CRM システムや個人を特定できる情報 (PII) を含む MySQL データベースなど、オンプレミスのバックエンド サービスに依存しています。バックエンド サービスは規制要件を満たすためにオンプレミスのままにしておく必要があります。オンプレミス データセンターと GCP の間に Cloud VPN 接続を確立しました。GKE 上のマイクロサービス アプリケーションからバックエンド サービスへの一部のリクエストが帯域幅の変動によるレイテンシの問題が原因で失敗し、アプリケーションがクラッシュしていることに気付きました。
レイテンシの問題にどのように対処しますか?
- A. Memorystore を使用し、頻繁にアクセスされる PII データをオンプレミスの MySQL データベースからキャッシュします。
- B. Istio を使用し、GKE 上のマイクロサービスとオンプレミス サービスを含むサービス メッシュを作成します。
- C. Google Cloud とオンプレミス サービス間の接続用に Cloud VPN トンネルの数を増やします。
- D. Cloud VPN のデフォルト値から最大転送単位 (MTU) の値を減らし、ネットワーク層のパケット サイズを減らします。
Answer:C
Question 179
会社は新しい API を Compute Engine インスタンスにデプロイしました。
テスト中に API が期待どおりに動作しません。アプリケーションを再デプロイせずにアプリケーション コード内の問題を診断するために 12 時間にわたってアプリケーションを監視したいと考えています。
どのツールを使用しますか?
- A. Cloud Trace
- B. Cloud Monitoring
- C. Cloud Debugger のログポイント
- D. Cloud Debugger のスナップショット
Answer:C
Question 180
複数のマイクロサービスで構成されるアプリケーションを設計しています。
各マイクロサービスには独自の RESTful API があり、個別の Kubernetes サービスとしてデプロイされます。API に変更があった場合にこれらの API のコンシューマーが影響を受けないようにし、API の新しいバージョンがリリースされたときにサードパーティ システムが中断されないようにする必要があります。
Google が推奨するベスト プラクティスに従って、アプリケーションへの接続をどのように構成しますか?
- A. API の URL を使用する Ingress を使用し、リクエストを適切なバックエンドにルーティングします。
- B. Service Discovery システムを活用し、リクエストで指定されたバックエンドに接続します。
- C. 複数のクラスタを使用し、DNS エントリを使用してリクエストを別のバージョン管理されたバックエンドにルーティングします。
- D. 複数のバージョンを同じサービスに結合し、POST リクエストで API バージョンを指定する。
Answer: A
Question 181
チームは金融機関向けのアプリケーションを構築しています。
アプリケーションのフロントエンドは Compute Engine で実行され、データは Cloud SQL と 1 つの Cloud Storage バケットに存在します。アプリケーションは PII を含むデータを収集し、Cloud SQL データベースと Cloud Storage バケットに保存します。PII データを保護する必要があります。
どうすればいいでしょうか?
- A.
- 1. フロントエンドのみが Cloud SQL データベースと通信できるように関連するファイアウォール ルールを作成します。
- 2. IAM を使用し、フロントエンド サービス アカウントのみに Cloud Storage バケットへのアクセスを許可します。
- B.
- 1. フロントエンドのみが Cloud SQL データベースと通信できるように関連するファイアウォール ルールを作成します。
- 2. プライベート アクセスを有効にして、フロントエンドが Cloud Storage バケットに非公開でアクセスできるようにします。
- C.
- 1. Cloud SQL のプライベート IP アドレスを構成します。
- 2. VPC-SC を使用してサービス境界を作成します。
- 3. Cloud SQL データベースと Cloud Storage バケットを同じサービス境界に追加します。
- D.
- 1. Cloud SQL のプライベート IP アドレスを構成します。
- 2. VPC-SC を使用してサービス境界を作成します。
- 3. Cloud SQL データベースと Cloud Storage バケットを異なるサービス境界に追加します。
Answer:C
Question 182
複数のルームをホストし、各ルームのメッセージ履歴を保持するチャット ルーム アプリケーションを設計しています。
データベースとして Cloud Firestore を選択しました。
Cloud Firestore でデータをどのように表すべきでしょうか?
- A. Room の Collection を作成します。Room ごとに Message の内容をリストしたドキュメントを作成します。
- B. Room の Collection を作成します。Room ごとに各 Message のドキュメントを含む Collection を作成します。

- C. Room の Collection を作成します。Room ごとに Message を含むドキュメントの Collection を含むドキュメントを作成します。

- D. Room の Collection を作成し、Room ごとにドキュメントを作成します。Message ごとに 1 つのドキュメントを使用して Message 用に個別の Collection を作成します。各ルームのドキュメントには Message への参照のリストが含まれています。
Answer: C
- A. Room の Collection を作成します。Room ごとに Message の内容をリストしたドキュメントを作成します。

- B. Room の Collection を作成します。Room ごとに各 Message のドキュメントを含む Collection を作成します

- C. Room の Collection を作成します。Room ごとに Message を含むドキュメントの Collection を含むドキュメントを作成します。

- D. Room の Collection を作成し、Room ごとにドキュメントを作成します。Message ごとに 1 つのドキュメントを使用して Message 用に個別の Collection を作成します。各ルームのドキュメントには Message への参照のリストが含まれています。





Answer:C
Question 183
エンド ユーザーからの要求を処理するアプリケーションを開発しています。
許可されていないユーザーへのアクセスを制限しながら許可されたエンド ユーザーがアプリケーションを介して関数に対して認証できるようにするにはアプリケーションによって呼び出される Cloud Functions を保護する必要があります。ソリューションの一部として Google ログインを統合し、Google が推奨するベスト プラクティスに従う必要があります。
どうすればいいでしょうか?
- A. ソース コード リポジトリからデプロイし、ユーザーに roles/cloudfunctions.viewer ロールを付与します。
- B. ソースコード リポジトリからデプロイし、ユーザーに roles/cloudfunctions.invoker ロールを付与します。
- C. gcloud を使用してローカル マシンからデプロイし、ユーザーに roles/cloudfunctions.admin ロールを付与します。
- D. gcloud を使用してローカル マシンからデプロイし、ユーザーに roles/cloudfunctions.developer ロールを付与します。
Answer: B
Question 184
継承した Google Kubernetes Engine で Web アプリケーションを実行しています。
アプリケーションが既知の脆弱性を持つライブラリを使用しているかどうか、または XSS 攻撃に対して脆弱であるかどうかを判断したいと考えています。
どのサービスを使用するべきでしょうか?
- A. Google Cloud Armor
- B. デバッガー
- C. Web セキュリティ スキャナー
- D. エラー報告
Answer:C
Reference:
– Web Security Scanner の概要 | Security Command Center | Google Cloud
Question 185
静的コンテンツをユーザーに提供する高可用性でグローバルにアクセス可能なアプリケーションを構築しています。
ストレージとサービス コンポーネントを構成する必要があります。ユーザーの信頼性を最大限に高めながら管理のオーバーヘッドと待ち時間を最小限に抑える必要があります。
どうすればいいでしょうか?
- A.
- 1. マネージド インスタンス グループを作成し、仮想マシン (VM) 間で静的コンテンツをレプリケートします。
- 2. 外部 HTTP(S) ロードバランサを作成します。
- 3. Cloud CDN を有効にし、マネージド インスタンス グループにトラフィックを送信します。
- B.
- 1. 非マネージド インスタンス グループを作成し、VM 間で静的コンテンツをレプリケートします。
- 2. 外部 HTTP(S) ロードバランサを作成します。
- 3. Cloud CDN を有効にし、非マネージド インスタンス グループにトラフィックを送信します。
- C.
- 1. Standard ストレージ クラスのリージョン Cloud Storage バケットを作成します。静的コンテンツをバケットに入れます。
- 2. 外部 IP アドレスを予約し、外部 HTTP(S) ロードバランサを作成します。
- 3. Cloud CDN を有効にし、トラフィックをバックエンド バケットに送信します。
- D.
- 1. Standard ストレージ クラスのマルチリージョン Cloud Storage バケットを作成します。静的コンテンツをバケットに入れます。
- 2. 外部 IP アドレスを予約し、外部 HTTP(S) ロードバランサを作成します。
- 3. Cloud CDN を有効にし、トラフィックをバックエンド バケットに送信します。
Answer:D
Question 186
この問題は HipLocal のケーススタディを参照してください。
HipLocal は世界中のユーザーに対するサービスの待ち時間を短縮したいと考えています。
ユーザーが存在する場所にデータベースの読み取りレプリカを作成し、それらのレプリカを使用してトラフィックを読み取るようにサービスを構成しました。
最小限の労力ですべてのデータベース対話のレイテンシーをさらに短縮するにはどうすればよいでしょうか?
- A. データベースを Cloud Bigtable に移行し、それを使用してすべてのグローバル ユーザー トラフィックを処理します。
- B. データベースを Cloud Spanner に移行し、それを使用してすべてのグローバル ユーザー トラフィックを処理します。
- C. データベースを Datastore モードの Cloud Firestore に移行し、それを使用してすべてのグローバル ユーザー トラフィックを処理します。
- D. サービスを Google Kubernetes Engine に移行し、ロードバランサ サービスを使用してアプリケーションをより適切にスケーリングします。
Answer: B
Question 187
この問題は HipLocal のケーススタディを参照してください。
サービスレベルの指標と目標に関する HipLocal のビジネス要件に対応する Google Cloud プロダクトはどれですか?
- A. Cloud Profiler
- B. Cloud Monitoring
- C. Cloud Trace
- D. Cloud Logging
Answer: B
Question 188
この問題は HipLocal のケーススタディを参照してください。
最近のセキュリティ監査で Compute Engine でホストされている MySQL データベースの HipLocal のデータベース資格情報が永続ディスクにプレーン テキストで保存されていることが判明しました。
HipLocal はこれらの資格情報が盗まれるリスクを軽減する必要があります。
どうすればいいでしょうか?
- A. サービス アカウントを作成し、そのキーをダウンロードします。キーを使用して Cloud Key Management Service (KMS) に対して認証し、データベースの資格情報を取得します。
- B. サービス アカウントを作成し、そのキーをダウンロードします。キーを使用して Cloud Key Management Service (KMS) に対して認証を行い、データベース資格情報の復号化に使用されるキーを取得します。
- C. サービス アカウントを作成し、roles/iam.serviceAccountUser のロールを付与します。このアカウントになりすまして Cloud SQL Proxy を使用して認証します。
- D. roles/secretmanager.secretAccessor のロールを Compute Engine サービス アカウントに付与します。Secret Manager API を使用してデータベース資格情報を保存してアクセスします。
Answer:D
Question 189
この問題は HipLocal のケーススタディを参照してください。
HipLocal は新しい場所に拡大しています。
アプリケーションが新しいヨーロッパの国で起動されるたびに、追加のデータを取得する必要があります。これはスキーマの絶え間ない変更とアプリケーションの変更をテストするための環境の不足により、開発プロセスの遅延を引き起こしています。
ビジネス要件を満たしながらどのように問題を解決しますか?
- A. テストとデプロイのためにヨーロッパと北米で新しい Cloud SQL インスタンスを作成します。アプリケーションの変更に関するテストを実施するためのローカル MySQL インスタンスを開発者に提供します。
- B. データを Cloud Bigtable に移行します。Cloud SDK を使用してローカルの Cloud Bigtable 開発環境をエミュレートするように開発チームに指示します。
- C. Cloud SQL から Compute Engine でホストされている MySQL に移行します。アメリカとヨーロッパの地域間でホストをレプリケートします。アプリケーションの変更に関するテストを実施するためのローカル MySQL インスタンスを開発者に提供します。
- D. データをネイティブ モードの Cloud Firestore に移行し、ヨーロッパと北米でインスタンスを設定します。Cloud SDK を使用してネイティブ モードの開発環境でローカルの Cloud Firestore をエミュレートするように開発チームに指示します。
Answer:D
Question 190
Go アプリケーションから Cloud Spanner データベースに書き込んでいます。
Google が推奨するベスト プラクティスを使用してアプリケーションのパフォーマンスを最適化したい。
どうすればいいでしょうか?
- A. Cloud クライアント ライブラリを使用して Cloud Spanner に書き込みます。
- B. Google API クライアント ライブラリを使用して Cloud Spanner に書き込みます
- C. カスタム gRPC クライアント ライブラリを使用して Cloud Spanner に書き込みます。
- D. サードパーティの HTTP クライアント ライブラリを使用して Cloud Spanner に書き込みます。
Answer: A
Question 191
Google Kubernetes Engine (GKE) にデプロイされたアプリケーションがあります。
Google Cloud マネージド サービスに対して承認済みのリクエストを行うにはアプリケーションを更新する必要があります。これを 1 回限りの設定にしたいと考えており、セキュリティ キーを自動ローテーションして暗号化されたストレージに保存するというセキュリティのベスト プラクティスに従う必要があります。Google Cloud サービスへの適切なアクセス権を持つサービス アカウントをすでに作成しています。
何をするべきでしょうか?
- A. Workload Identity を使用し、Google Cloud サービス アカウントを GKE Pod に割り当てます。
- B. Google Cloud サービス アカウントをエクスポートし、それを Kubernetes Secret として Pod と共有します。
- C. Google Cloud サービス アカウントをエクスポートし、アプリケーションのソース コードに埋め込む。
- D. Google Cloud サービス アカウントをエクスポートし、HashiCorp Vault にアップロードして、アプリケーションの動的サービス アカウントを生成します。
Answer: A
Reference:
– Workload Identity を使用する | Google Kubernetes Engine(GKE) | Google Cloud
Question 192
Google Kubernetes Engine (GKE) クラスタに数百のマイクロサービスをデプロイすることを計画しています。
マネージド サービスを使用して GKE 上のマイクロサービス間の通信をどのように保護する必要がありますか?
- A. マネージド SSL 証明書でグローバル HTTP(S) ロードバランサを使用してサービスを保護します。
- B. GKE クラスタにオープンソースの Istio をデプロイし、サービス メッシュで mTLS を有効にします。
- C. GKE に cert-manager をインストールして、SSL 証明書を自動的に更新します。
- D. Anthos Service Mesh をインストールし、Service Mesh で mTLS を有効にします。
Answer:D
Question 193
機密性の高い非構造化データ オブジェクトを Cloud Storage バケットに保存してアクセスするアプリケーションを開発しています。
規制要件に準拠するには最初の作成から少なくとも 7 年間はすべてのデータ オブジェクトを利用できるようにする必要があります。3 年以上前に作成されたオブジェクトへのアクセスは非常にまれです (1 年に 1 回未満)。ストレージ コストを最適化しながらオブジェクト ストレージを構成する必要があります。
どうすればいいでしょうか? (回答は 2 つ)
- A. バケットに 7 年間の保持ポリシーを設定します。
- B. IAM Conditions を使用してオブジェクトの作成日から 7 年後にオブジェクトへのアクセスを提供します。
- C. オブジェクトのバージョニングを有効にしてオブジェクトの作成後 7 年間、オブジェクトが誤って削除されるのを防ぎます。
- D. 3 年後にオブジェクトを標準ストレージから Archive ストレージに移動するバケットにオブジェクト ライフサイクル ポリシーを作成します。
- E. バケット内の各オブジェクトの経過時間を確認し、3 年以上経過したオブジェクトを Archive ストレージ クラスの 2 番目のバケットに移動する Cloud Functions を実装します。Cloud Scheduler を使用して毎日のスケジュールで Cloud Functions をトリガーします。
Answer:A、D
Question 194
クラスタの内部に留まる必要があるさまざまなマイクロサービスを使用してアプリケーションを開発しています。
特定の数のレプリカを使用して各マイクロサービスを構成する機能が必要です。また、マイクロサービスがスケーリングするレプリカの数に関係なく、他のマイクロサービスから特定のマイクロサービスに一様に対処する機能も必要です。このソリューションを Google Kubernetes Engine に実装する予定です。
どうすればいいでしょうか?
- A. 各マイクロサービスをデプロイとしてデプロイします。Service を使用してクラスタ内の Deployment を公開し、Service の DNS 名を使用してクラスタ内の他のマイクロサービスからそれをアドレス指定します。
- B. 各マイクロサービスをデプロイとしてデプロイします。Ingress を使用してクラスタ内の Deployment を公開し、Ingress IP アドレスを使用してクラスタ内の他のマイクロサービスから Deployment に対処します。
- C. 各マイクロサービスを Pod としてデプロイします。Service を使用してクラスタ内の Pod を公開し、Service DNS 名を使用してクラスタ内の他のマイクロサービスからマイクロサービスをアドレス指定します。
- D. 各マイクロサービスを Pod としてデプロイします。Ingress を使用してクラスタ内の Pod を公開し、Ingress IP アドレスを使用してクラスタ内の他のマイクロサービスから Pod をアドレス指定します。
Answer: A
Question 195
分散マイクロサービス アーキテクチャを使用するアプリケーションを構築しています。
Java で記述されたマイクロサービスの 1 つでパフォーマンスとシステム リソースの使用率を測定したいと考えています。
どうすればいいでしょうか?
- A. Cloud Profiler を使用してサービスを計測し、サービスの CPU 使用率とメソッドレベルの実行時間を測定します。
- B. Debugger を使用してサービスを計測し、サービス エラーを調査します。
- C. Cloud Trace を使用してサービスを計測し、リクエストのレイテンシを測定します。
- D. OpenCensus を使用してサービスを計測し、サービス レイテンシを測定し、カスタム指標を Cloud Monitoring に書き込みます。
Answer: A
Question 196
チームはさまざまなソースからのニュース記事を集約するアプリケーションを維持する責任があります。
モニタリング ダッシュボードには一般公開されているリアルタイム レポートが含まれており、Compute Engine インスタンス上で Web アプリケーションとして実行されます。外部の利害関係者とアナリストは認証なしで安全なチャネルを介してこれらのレポートにアクセスする必要があります。
この安全なチャネルをどのように構成するべきですか?
- A. インスタンスにパブリック IP アドレスを追加します。インスタンスのサービス アカウント キーを使用してトラフィックを暗号化します。
- B. Cloud Scheduler を使用して 1 時間ごとに Cloud Build をトリガーし、レポートからエクスポートを作成します。レポートをパブリック Cloud Storage バケットに保存します。
- C. モニタリング ダッシュボードの前に HTTP(S) ロードバランサを追加します。通信チャネルを保護するように Identity-Aware Proxy を構成します。
- D. モニタリング ダッシュボードの前に HTTP(S) ロードバランサを追加します。トラフィックの暗号化のためにロードバランサに Google マネージド SSL 証明書を設定します。
Answer:D
Question 197
アプリケーションに単体テストを追加する予定です。
パブリッシュされた Cloud Pub/Sub メッセージがサブスクライバーによって順番に処理されることをアサートできる必要があります。単体テストの費用対効果と信頼性を高める必要があります。
どうすればいいでしょうか?
- A. モッキング フレームワークを実装します。
- B. 各テスターのトピックとサブスクリプションを作成します。
- C. テスターによるフィルターをサブスクリプションに追加します。
- D. Cloud Pub/Sub エミュレータを使用します。
Answer:D
Reference:
– エミュレータを使用したローカルでのアプリのテスト | Cloud Pub/Sub ドキュメント | Google Cloud
Question 198
Cloud Pub/Sub メッセージを読み取って処理するアプリケーションが Google Kubernetes Engine (GKE) にデプロイされています。
各 Pod は 1 分あたり一定数のメッセージを処理します。メッセージが Cloud Pub/Sub トピックにパブリッシュされる頻度は 1 日および 1 週間を通して大きく異なります。これには一度に大規模なメッセージのバッチが時折パブリッシュされることもあります。メッセージをタイムリーに処理できるように GKE Deployment をスケーリングしたいと考えています。
ワークロードを自動的に適応させるには どの GKE 機能を使用しますか?
- A. Auto モードの垂直 Pod オートスケーラー
- B. レコメンデーション モードの垂直 Pod オートスケーラー
- C. 外部メトリックに基づく水平 Pod オートスケーラー
- D. リソース使用率に基づく水平 Pod オートスケーラー
Answer:C
Question 199
Cloud Run を使用して Web アプリケーションをホストしています。
アプリケーション プロジェクト ID とアプリケーションが実行されているリージョンを安全に取得し、この情報をユーザーに表示する必要があります。最もパフォーマンスの高いアプローチを使用したい。
どうすればいいでしょうか?
- A. HTTP リクエストを使用して http://metadata.google.internal/ エンドポイントで Metadata-Flavor: Google ヘッダーを使用して利用可能なメタデータ サーバにクエリを実行します。
- B. Google Cloud コンソールでプロジェクト ダッシュボードに移動し、構成の詳細を収集します。Cloud Run の [Variables & Secrets] タブに移動し、必要な環境変数を Key:Value 形式で追加します。
- C. Google Cloud コンソールでプロジェクト ダッシュボードに移動し、構成の詳細を収集します。アプリケーション構成情報を Cloud Run のインメモリ コンテナ ファイルシステムに書き込みます。
- D. アプリケーションから Cloud Asset Inventory API への API 呼び出しを行い、リクエストをフォーマットしてインスタンス メタデータを含めます。
Answer: A
Question 200
Terraform を使用してラップトップから Google Cloud にリソースをデプロイする必要があります。
Google Cloud 環境のリソースはサービス アカウントを使用して作成する必要があります。Cloud Identity には roles/iam.serviceAccountTokenCreator の Identity and Access Management (IAM) ロールと Terraform を使用してリソースをデプロイするために必要な権限があります。Google が推奨するベスト プラクティスに従って必要なリソースをデプロイするように開発環境を構築したいと考えています。
どうすればいいでしょうか?
- A.
- 1. サービス アカウントのキー ファイルを JSON 形式でダウンロードし、ラップトップにローカルに保存します。
- 2. GOOGLE_APPLICATION_CREDENTIALS 環境変数をダウンロードしたキー ファイルのパスに設定します。
- B.
- 1. コマンドラインから次のコマンドを実行します。
gcloud config set auth/impersonate_service_account service-account-name@project.iam.gserviceacccount.com. - 2. GOOGLE_OAUTH_ACCESS_TOKEN 環境変数を gcloud auth print-access-token コマンドによって返される値に設定します。
- 1. コマンドラインから次のコマンドを実行します。
- C.
- 1. コマンドラインから次のコマンドを実行します。
gcloud auth application-default login. - 2. 開いたブラウザ ウィンドウで個人の資格情報を使用して認証します。
- 1. コマンドラインから次のコマンドを実行します。
- D.
- 1. サービス アカウントのキー ファイルを JSON 形式で Hashicorp Vault に保存します。
- 2. Terraform を Vault と統合してキー ファイルを動的に取得し、有効期間の短いアクセス トークンを使用して Vault に対して認証します。
Answer: B
Question 201
会社では Cloud Logging を使用して大量のログデータを管理しています。
ログをサードパーティ アプリケーションにプッシュして処理するリアルタイムのログ分析アーキテクチャを構築する必要があります。
どうすればいいでしょうか?
- A. Cloud Logging のログ エクスポートを Cloud Pub/Sub に作成します。
- B. BigQuery への Cloud Logging ログ エクスポートを作成します。
- C. Cloud Storage への Cloud Logging ログ エクスポートを作成します。
- D. Cloud Logging のログエントリを読み取り、サードパーティ アプリケーションに送信する Cloud Functions を作成します。
Answer: A
Question 202
それぞれの Cloud Storage バケット内のユーザー オブジェクトのメタデータ内の特定のプロパティを取得する必要がある新しい公開アプリケーションを開発しています。
プライバシーとデータ レジデンシーの要件により、オブジェクト データではなく、メタデータのみを取得する必要があります。取得プロセスのパフォーマンスを最大化する必要があります。
どのようにメタデータを取得しますか?
- A. パッチ方式を使用します。
- B. 作成方法を使用します。
- C. コピー方式を使用します。
- D. fields リクエスト パラメータを使用します。
Answer:D
Question 203
ライブストリームをブロードキャストするマイクロサービス アプリケーションを Google Kubernetes Engine (GKE) にデプロイしています。
予測できないトラフィック パターンと同時にユーザー数の大きな変動が予想されます。アプリケーションは次の要件を満たす必要があります。
– 人気のあるイベント中に自動的にスケーリングし、高可用性を維持
– ハードウェア障害が発生した場合の回復力
デプロイメント パラメーターをどのように構成しますか? (回答は 2 つ)
- A. マルチゾーン ノード プールを使用してワークロードを均等に分散します。
- B. 複数のゾーン ノード プールを使用してワークロードを均等に分散します。
- C. クラスタ オートスケーラーを使用してノード プール内のノード数を変更し、水平 Pod オートスケーラーを使用してワークロードをスケーリングします。
- D. クラスタ ノードを使用して Compute Engine のマネージド インスタンス グループを作成します。マネージド インスタンス グループの自動スケーリング ルールを構成します。
- E. GKE の CPU とメモリの使用率に基づいて Cloud Monitoring でアラート ポリシーを作成します。CPU とメモリの使用率が事前に定義されたしきい値を超えた場合にスクリプトを実行してワークロードをスケーリングするように勤務中のエンジニアに依頼します。
Answer:B、C
Question 204
急速に成長している金融テクノロジーの新興企業で働いています。
Go で記述され、シンガポール リージョン (asia-southeast1) の Cloud Run でホストされている支払い処理アプリケーションを管理します。支払い処理アプリケーションは、同じくシンガポール リージョンにある Cloud Storage バケットに格納されたデータを処理します。このスタートアップはアジア太平洋地域へのさらなる拡大を計画しています。今後 6 か月以内にジャカルタ、香港、台湾にペイメント ゲートウェイをデプロイする予定です。各場所にはトランザクションが行われた国に顧客データが存在する必要があるデータ所在地要件があります。これらのデプロイ コストを最小限に抑える必要があります。
どうすればいいでしょうか?
- A. 各リージョンに Cloud Storage バケットを作成し、各リージョンに決済アプリケーションの Cloud Run サービスを作成します。
- B. 各リージョンに Cloud Storage バケットを作成し、シンガポール リージョンに支払い処理アプリケーションの 3 つの Cloud Run サービスを作成します。
- C. アジア マルチリージョンに 3 つの Cloud Storage バケットを作成し、シンガポール リージョンに支払い処理アプリケーションの 3 つの Cloud Run サービスを作成します。
- D. アジア マルチリージョンで 3 つの Cloud Storage バケットを作成し、シンガポール リージョンで支払い処理アプリケーションの 3 つの Cloud Run リビジョンを作成します。
Answer: A
Question 205
最近、本番環境で実行されている Cloud Spanner データベース インスタンスを持つ新しいチームに参加しました。
上司から Cloud Spanner インスタンスを最適化してデータベースの高い信頼性と可用性を維持しながらコストを削減するよう依頼されました。
どうすればいいでしょうか?
- A. Cloud Logging を使用してエラー ログを確認し、必要な最小容量が見つかるまで、Spanner 処理ユニットを少しずつ減らします。
- B. Cloud Trace を使用して Cloud Spanner への受信リクエストの 1 秒あたりのリクエストをモニタリングし、必要な最小容量が見つかるまで、Cloud Spanner 処理ユニットを少しずつ減らします。
- C. Cloud Monitoring を使用して CPU 使用率をモニタリングし、必要な最小容量が見つかるまで Cloud Spanner 処理ユニットを少しずつ減らします。
- D. スナップショット デバッガーを使用してアプリケーション エラーをチェックし、必要な最小容量が見つかるまで Cloud Spanner 処理ユニットを少しずつ減らします。
Answer:C
Question 206
最近、Go アプリケーションを Google Kubernetes Engine (GKE) にデプロイしました。
運用チームは運用トラフィックが少ない場合でもアプリケーションの CPU 使用率が高いことに気付きました。運用チームからアプリケーションの CPU リソース消費を最適化するよう依頼されました。最も多くの CPU を消費する Go 関数を特定したいと考えています。
どうすればいいでしょうか?
- A. Cloud Logging にデータを記録するために GKE クラスタに Fluent Bit デーモンセットをデプロイします。ログを分析してアプリケーション コードのパフォーマンスに関する洞察を得ます。
- B. Cloud Monitoring でカスタム ダッシュボードを作成してアプリケーションの CPU パフォーマンス指標を評価します。
- C. SSH を使用して GKE ノードに接続します。シェルで top コマンドを実行してアプリケーションの CPU 使用率を抽出します。
- D. Go アプリケーションを変更してプロファイリング データを取得します。Cloud Profiler のフレーム グラフでアプリケーションの CPU メトリックを分析します。
Answer:D
Question 207
チームはアプリケーションが実行されている Google Kubernetes Engine (GKE) クラスタを管理しています。
別のチームがこのアプリケーションとの統合を計画しています。統合を開始する前に他のチームがアプリケーションに変更を加えることはできませんが GKE に統合をデプロイできることを確認する必要があります。
どうすればいいでしょうか?
- A. Identity and Access Management (IAM) を使用してクラスタ プロジェクトに対する Viewer IAM ロールを他のチームに付与します。
- B. 新しい GKE クラスタを作成します。Identity and Access Management (IAM) を使用して、クラスタ プロジェクトに対する編集者の役割を他のチームに付与します。
- C. 既存のクラスタに新しい名前空間を作成します。Identity and Access Management (IAM) を使用してクラスタ プロジェクトに対する編集者の役割を他のチームに付与します。
- D. 既存のクラスタに新しい名前空間を作成します。Kubernetes の役割ベースのアクセス制御 (RBAC) を使用して、新しい名前空間に対する管理者の役割を他のチームに付与します。
Answer:D
Question 208
最近、OpenTelemetry を使用して新しいアプリケーションを計測し、Trace でアプリケーション リクエストのレイテンシを確認したいと考えています。
特定のリクエストが常にトレースされるようにする必要があります。
どうすればいいでしょうか?
- A. 10 分間待ってから Cloud Trace がこれらのタイプの要求を自動的にキャプチャすることを確認します。
- B. 開発プロジェクトからこのタイプのリクエストを繰り返し送信するカスタム スクリプトを作成します。
- C. Cloud Trace API を使用してカスタム属性をトレースに適用します。
- D. 適切なパラメーターを使用して X-Cloud-Trace-Context ヘッダーをリクエストに追加します。
Answer:D
Question 209
Cloud Shell から kubectl を使用して Google Kubernetes Engine (GKE) クラスタに接続しようとしています。
パブリック エンドポイントを使用して GKE クラスタをデプロイしました。
Cloud Shell から次のコマンドを実行します。
gcloud container clusters get-credentials <cluster-name> \
---zone <none> --project <project-name> \kubectl コマンドがエラー メッセージを返さずにタイムアウトすることに気付きました。
この問題の最も可能性の高い原因は何でしょうか?
- A. ユーザー アカウントには kubectl を使用してクラスタとやり取りする権限がありません。
- B. Cloud Shell の外部 IP アドレスはクラスタの承認済みネットワークの一部ではありません。
- C. Cloud Shell は GKE クラスタと同じ VPC の一部ではありません。
- D. VPC ファイアウォールがクラスタのエンドポイントへのアクセスをブロックしている。
Answer: B
Question 210
Cloud Storage バケットに保存された非公開の画像と動画を含む Web アプリケーションを開発しています。
ユーザーは匿名であり、Google アカウントを持っていません。アプリケーション固有のロジックを使用して、画像とビデオへのアクセスを制御したいと考えています。
アクセスをどのように構成しますか?
- A. 各 Web アプリケーション ユーザーの IP アドレスをキャッシュして Google Cloud Armor を使用して名前付き IP テーブルを作成します。ユーザーがバックエンド バケットにアクセスできるようにする Google Cloud Armor セキュリティ ポリシーを作成します。
- B. Storage Object Viewer IAM ロールを allUsers に付与します。Web アプリケーションによる認証後にユーザーがバケットにアクセスできるようにします。
- C. Identity-Aware Proxy (IAP) を構成して Web アプリケーションでユーザーを認証します。IAP による認証後にユーザーがバケットにアクセスできるようにします。
- D. バケットへの読み取りアクセスを許可する署名付き URL を生成します。Web アプリケーションによる認証後にユーザーが URL にアクセスできるようにします。
Answer:D
Question 211
Google Kubernetes Engine (GKE) で Deployment を構成する必要があります。
コンテナがデータベースに接続できることを確認するチェックを含めたいとします。Pod が接続に失敗した場合はコンテナでスクリプトを実行して正常なシャットダウンを完了する必要があります。
デプロイをどのように構成しますか?
- A. 2 つのジョブを作成します。1 つはコンテナがデータベースに接続できるかどうかを確認するジョブでもう 1 つは Pod が失敗した場合にシャットダウン スクリプトを実行するジョブです。
- B. コンテナがデータベースに接続できない場合に失敗するコンテナの livenessProbe を使用して Deployment を作成します。コンテナが失敗した場合にシャットダウン スクリプトを実行する Prestop ライフサイクル ハンドラーを構成します。
- C. サービスの可用性をチェックする PostStart ライフサイクル ハンドラを使用して Deployment を作成します。コンテナが失敗した場合にシャットダウン スクリプトを実行する PreStop ライフサイクル ハンドラーを構成します。
- D. サービスの可用性をチェックする initContainer を使用して Deployment を作成します。Pod に障害が発生した場合にシャットダウン スクリプトを実行する Prestop ライフサイクル ハンドラを構成します。
Answer: B
Question 212
新しい API をデプロイする責任があります。
その API には 3 つの異なる URL パスがあります。
-https://yourcompany.com/students
-https://yourcompany.com/teachers
-https://yourcompany.com/classes
コード内で異なる関数を呼び出すには各 API URL パスを構成する必要があります。
どうすればいいでしょうか?
- A. HTTPS ロードバランサを使用して公開されるバックエンド サービスとして Cloud Functions を 1 つ作成します。
- B. 直接公開される 3 つの Cloud Functions を作成します。
- C. 直接公開される Cloud Functions を 1 つ作成します。
- D. HTTPS ロードバランサを使用して公開される 3 つのバックエンド サービスとして 3 つの Cloud Functions を作成します。
Answer:D
Question 213
マイクロサービス アプリケーションを Google Kubernetes Engine (GKE) にデプロイしています。
アプリケーションは毎日更新されます。Linux オペレーティング システム (OS) で実行される多数の個別のコンテナをデプロイすることを想定しています。新しいコンテナの既知の OS の脆弱性についてアラートを受け取る必要があります。Google が推奨するベスト プラクティスに従います。
どうすればいいでしょうか?
- A. gcloud CLI を使用して Container Analysis を呼び出し、新しいコンテナ イメージをスキャンします。各デプロイの前に脆弱性の結果を確認してください。
- B. Container Analysis を有効にし、新しいコンテナ イメージを Artifact Registry にアップロードします。各デプロイの前に脆弱性の結果を確認してください。
- C. Container Analysis を有効にし、新しいコンテナ イメージを Artifact Registry にアップロードします。各デプロイの前に重大な脆弱性の結果を確認してください。
- D. Container Analysis REST API を使用して Container Analysis を呼び出し、新しいコンテナ イメージをスキャンします。各デプロイの前に脆弱性の結果を確認してください。
Answer: B
Question 214
あなたは大規模な組織の開発者です。
Go で記述されたアプリケーションが本番環境の Google Kubernetes Engine (GKE) クラスタで実行されています。BigQuery へのアクセスを必要とする新しい機能を追加する必要があります。Google が推奨するベスト プラクティスに従って、BigQuery に GKE クラスタへのアクセスを許可したいと考えています。
どうすればいいでしょうか?
- A. BigQuery にアクセスできる Google サービス アカウントを作成します。JSON キーを Secret Manager に追加し、Go クライアント ライブラリを使用して JSON キーにアクセスします。
- B. BigQuery にアクセスできる Google サービス アカウントを作成します。Google サービス アカウントの JSON キーを Kubernetes シークレットとして追加し、このシークレットを使用するようにアプリケーションを構成します。
- C. BigQuery にアクセスできる Google サービス アカウントを作成します。Google サービス アカウントの JSON キーを Secret Manager に追加し、init コンテナを使用して、アプリケーションが使用するシークレットにアクセスします。
- D. Google サービス アカウントと Kubernetes サービス アカウントを作成します。GKE クラスタで Workload Identity を構成し、アプリケーションの Deployment で Kubernetes サービス アカウントを参照します。
Answer:D
Question 215
Python で記述されたアプリケーションが Cloud Run の本番環境で実行されています。
アプリケーションは同じプロジェクト内の Cloud Storage バケットに保存されたデータを読み書きする必要があります。最小権限の原則に従って、アプリケーションへのアクセスを許可したいと考えています。
どうすればいいでしょうか?
- A. カスタムの Identity and Access Management (IAM) ロールを持つユーザー管理サービス アカウントを作成します。
- B. Storage Admin Identity and Access Management (IAM) ロールを持つユーザー管理サービス アカウントを作成します。
- C. Project Editor Identity and Access Management (IAM) ロールを持つユーザー管理サービス アカウントを作成します。
- D. 本番環境で Cloud Run リビジョンにリンクされたデフォルトのサービス アカウントを使用します。
Answer: A
Question 216
チームは Cloud Functions コードの単体テストを開発しています。
コードは Cloud Source Repositories リポジトリに保存されます。テストの実施は顧客の責任です。コードを Cloud Functions にデプロイするために必要な権限を持っているのは特定のサービス アカウントだけです。最初にテストに合格しないとコードをデプロイできないようにする必要があります。
単体テスト プロセスをどのように構成する必要がありますか?
- A. Cloud Build を構成して Cloud Functions をデプロイします。コードがテストに合格すると、デプロイの承認が送信されます。
- B. 特定のサービス アカウントをビルド エージェントとして使用して Cloud Functions をデプロイするように Cloud Build を構成します。デプロイが成功したら単体テストを実行します。
- C. Cloud Build を構成して単体テストを実行します。コードがテストに合格すると開発者は Cloud Functions をデプロイします。
- D. 特定のサービス アカウントをビルド エージェントとして使用して単体テストを実行するように Cloud Build を構成します。コードがテストに合格すると Cloud Build は Cloud Functions をデプロイします。
Answer:D
Question 217
チームは本番プロジェクトの Cloud Run で実行されているアプリケーションでエラーの急増を検出しました。
アプリケーションは Cloud Pub/Sub トピック A からメッセージを読み取り、メッセージを処理し、メッセージをトピック B に書き込むように構成されています。エラーの原因を特定するためにテストを実施したいと考えています。テスト用に一連のモック メッセージを使用できます。
どうすればいいでしょうか?
- A. Cloud Pub/Sub と Cloud Run のエミュレータをローカル マシンにデプロイします。アプリケーションをローカルにデプロイし、アプリケーションのログ レベルを DEBUG または INFO に変更します。トピック A にモック メッセージを書き込み、ログを分析します。
- B. gcloud CLI を使用してトピック A にモック メッセージを書き込みます。アプリケーションのログ レベルを DEBUG または INFO に変更し、ログを分析します。
- C. ローカル マシンに Cloud Pub/Sub エミュレータをデプロイします。本番アプリケーションをローカルの Cloud Pub/Sub トピックに向けます。トピック A にモック メッセージを書き込み、ログを分析します。
- D. Google Cloud コンソールを使用してトピック A にモック メッセージを書き込みます。アプリケーションのログ レベルを DEBUG または INFO に変更し、ログを分析します。
Answer: A
Question 218
ユーザーに代わって Google Cloud API を介して Google Cloud サービスと対話する必要がある Java Web サーバを開発しています。
ユーザーは Google Cloud ID を使用して Google Cloud API に対して認証できる必要があります。
Web アプリケーションにどのワークフローを実装する必要がありますか?
- A.
- 1. ユーザーがアプリケーションにアクセスしたら Google のユーザー名とパスワードの入力を求めます。
- 2. SHA パスワード ハッシュをユーザーのユーザー名と共にアプリケーションのデータベースに保存します。
- 3. アプリケーションは、Authorization リクエスト ヘッダーにユーザーのユーザー名とパスワードのハッシュを含む HTTPS リクエストを使用して Google Cloud API に対して認証を行います。
- B.
- 1. ユーザーがアプリケーションにアクセスしたら Google のユーザー名とパスワードの入力を求めます。
- 2. HTTPS リクエストでユーザーのユーザー名とパスワードを Google Cloud 認可サーバに転送し、アクセス トークンをリクエストします。
- 3. Google サーバはユーザーの認証情報を検証し、アプリケーションにアクセス トークンを返します。
- 4. アプリケーションはアクセス トークンを使用して Google Cloud API を呼び出します。
- C.
- 1. ユーザーがアプリケーションにアクセスしたら要求された権限のリストを含む Google Cloud の同意画面にユーザーをルーティングし、SSO を使用して Google アカウントにサインインするようユーザーに促します。
- 2. ユーザーがサインインして同意するとアプリケーションは Google サーバから認証コードを受け取ります。
- 3. Google サーバはブラウザの Cookie に保存されている認証コードをユーザーに返します。
- 4. ユーザーはCookie の認証コードを使用して Google Cloud API に対して認証を行います。
- D.
- 1. ユーザーがアプリケーションにアクセスしたら要求された権限のリストを含む Google Cloud の同意画面にユーザーをルーティングし、SSO を使用して Google アカウントにサインインするようユーザーに促します。
- 2. ユーザーがサインインして同意するとアプリケーションは Google サーバから認証コードを受け取ります。
- 3. アプリケーションは認証コードをアクセス トークンと交換するよう Google サーバに要求します。
- 4. Google サーバはアプリケーションが Google Cloud API を呼び出すために使用するアクセス トークンで応答します。
Answer:D
Question 219
最近、新しいアプリケーションを開発しました。
Dockerfile なしで Cloud Run にアプリケーションをデプロイしたいと考えています。組織ではすべてのコンテナ イメージを一元管理されたコンテナ リポジトリにプッシュする必要があります。
Google Cloud サービスを使用してコンテナをどのように構築しますか? (回答は 2 つ)
- A. ソース コードを Artifact Registry にプッシュします。
- B. Cloud Build ジョブを送信してイメージをプッシュする。
- C. pack CLI で pack build コマンドを使用します。
- D. gcloud run deploy CLI コマンドに –source フラグを含めます。
- E. gcloud run deploy CLI コマンドに –platform=kubernetes フラグを含めます。
Answer:C、D
Question 220
オンラインの e コマース Web サイトを管理する組織で働いています。
会社は世界中に拡大する予定です。ただし、ストアは現在 1 つの特定の地域にサービスを提供しています。SQL データベースを選択し、組織の成長に合わせて拡張できるスキーマを構成する必要があります。すべての顧客トランザクションを格納するテーブルを作成し、顧客 (CustomerId) とトランザクション (TransactionId) が一意であることを確認したいと考えています。
どうすればいいでしょうか?
- A. 主キーとして設定された TransactionId と CustomerId を持つ Cloud SQL テーブルを作成します。TransactionId には増分番号を使用します。
- B. TransactionId と CustomerId が主キーとして構成された Cloud SQL テーブルを作成する。Transactionid にはランダムな文字列 (UUID) を使用します。
- C. TransactionId と CustomerId が主キーとして設定された Cloud Spanner テーブルを作成する。TransactionId にはランダムな文字列 (UUID) を使用します。
- D. TransactionId と CustomerId が主キーとして設定された Cloud Spanner テーブルを作成する。TransactionId には増分番号を使用します。
Answer:C
Question 221
Go で記述され、Google Kubernetes Engine にデプロイされた Web アプリケーションをモニタリングしています。
CPU とメモリの使用率が増加していることに気付きます。CPU とメモリのリソースを最も多く消費しているソース コードを特定する必要があります。
どうすればいいでしょうか?
- A. VM でスナップショット デバッガー エージェントをダウンロード、インストール、開始します。最も時間がかかる関数のデバッグ スナップショットを取得します。コール スタック フレームを確認し、スタック内のそのレベルにあるローカル変数を特定します。
- B. Cloud Profiler パッケージをアプリケーションにインポートし、Profiler エージェントを初期化します。生成されたフレーム グラフを Google Cloud Console で確認して、時間のかかる関数を特定します。
- C. OpenTelemetry および Trace エクスポート パッケージをアプリケーションにインポートし、トレース プロバイダーを作成します。トレースの概要ページでアプリケーションのレイテンシ データを確認し、ボトルネックが発生している場所を特定します。
- D. Web アプリケーションのログを収集する Cloud Logging クエリを作成します。アプリケーションの最も長い関数の最初と最後のタイムスタンプの差を計算して時間のかかる関数を特定する Python スクリプトを作成します。
Answer: B
Question 222
Google Kubernetes Engine にデプロイされたコンテナがあります。
コンテナの起動が遅い場合があるため、liveness プローブを実装しました。liveness プローブが起動時に失敗することがあります。
どうすればいいでしょうか?
- A. 起動プローブを追加します。
- B. liveness プローブの初期遅延を増やします。
- C. コンテナの CPU 制限を増やします。
- D.準備プローブを追加します。
Answer: B
Question 223
e コマース サイトを管理する組織で働いています。
アプリケーションはグローバル HTTP(S) ロードバランサの背後にデプロイされます。新しい製品レコメンデーション アルゴリズムをテストする必要があります。A/B テストを使用し、ランダム化された方法で新しいアルゴリズムの売上への影響を判断する予定です。
この機能をどのようにテストする必要がありますか?
- A. weights を使用してバージョン間でトラフィックを分割します。
- B. 単一のインスタンスで新しい推奨機能フラグを有効にします。
- C. アプリケーションの新しいバージョンにトラフィックをミラーリングします。
- D. HTTP ヘッダーベースのルーティングを使用します。
Answer: A
Question 224
Deployment リソースを使用して新しいアプリケーション リビジョンを本番環境の Google Kubernetes Engine (GKE) にデプロイする予定です。
コンテナが正しく機能しない可能性があります。リビジョンのデプロイ後に問題が発生した場合のリスクを最小限に抑える必要があります。Google が推奨するベスト プラクティスに従います。
どうすればいいでしょうか?
- A. 80% の PodDisruptionBudget でローリング アップデートを実行します。
- B. HorizontalPodAutoscaler スケールダウン ポリシーの値を 0 にし、ローリング アップデートを実行します。
- C. Deployment を StatefulSet に変換し、80% の PodDisruptionBudget でローリング アップデートを実行します。
- D. Deployment を StatefulSet に変換し、HorizontalPodAutoscaler スケールダウン ポリシーの値を 0 にしてローリング アップデートを実行します。
Answer: A
Question 225
新しいアプリケーション コードを本番環境にプロモートする前にさまざまなユーザーに対してテストを実施する必要があります。
この計画にはリスクが伴いますがアプリケーションの新しいバージョンを運用ユーザーでテストし、オペレーティング システムに基づいてアプリケーションの新しいバージョンに転送されるユーザーを制御したいと考えています。新しいバージョンでバグが発見された場合、アプリケーションの新しくデプロイされたバージョンをできるだけ早くロールバックする必要があります。
どうすればいいでしょうか?
- A. アプリケーションを Cloud Run にデプロイします。リビジョン タグに基づいてトラフィック分割を使用し、ユーザー トラフィックのサブセットを新しいバージョンに転送します。
- B. Anthos Service Mesh を使用して Google Kubernetes Engine にアプリケーションをデプロイします。トラフィック分割を使用して、ユーザー エージェント ヘッダーに基づいてユーザー トラフィックのサブセットを新しいバージョンに転送します。
- C. アプリケーションを App Engine にデプロイします。トラフィック分割を使用し、IP アドレスに基づいてユーザー トラフィックのサブセットを新しいバージョンに転送します。
- D. アプリケーションを Compute Engine にデプロイします。Traffic Director を使用し、事前定義された重みに基づいてユーザー トラフィックのサブセットを新しいバージョンに転送します。
Answer: B
Question 226
チームは給与計算アプリケーションをサポートする対話型音声応答 (IVR) システムのビジネス ロジックを実装するバックエンド アプリケーションを作成しています。
IVR システムには次の技術的特徴があります。
– 各顧客の電話は固有の IVR セッションに関連付けられています。
– IVR システムはセッションごとにバックエンドへの個別の永続的な gRPC 接続を作成します。
– 接続が中断された場合はIVR システムは新しい接続を確立するため、その通話にわずかな遅延が発生します。
バックエンド アプリケーションのデプロイに使用するコンピューティング環境を決定する必要があります。
現在の通話データを使用して次のことを判断します。
– 通話時間は 1 ~ 30 分
– 電話は通常、営業時間内
– 特定の既知の日付 (例: 給料日) の前後、または大規模な給与計算の変更が発生したときに電話の急増がある
コスト、労力、運用上のオーバーヘッドを最小限に抑えたいと考えています。
バックエンド アプリケーションをどこにデプロイするべきでしょうか?
- A. Compute Engine
- B. Standard モードの Google Kubernetes Engine クラスタ
- C. Cloud Functions
- D. Cloud Run
Answer:D
Question 227
MySQL リレーショナル データベース スキーマを使用する Google Cloud でホストされるアプリケーションを開発しています。
アプリケーションには、データベースへの大量の読み取りと書き込みがあり、バックアップと継続的な容量計画が必要になります。チームにはデータベースを完全に管理する時間がありませんが、小さな管理タスクを引き受けることはできます。
データベースをどのようにホストする必要がありますか?
- A. データベースをホストするように Cloud SQL を構成し、スキーマを Cloud SQL にインポートします。
- B. クライアントを使用して Google Cloud Marketplace からデータベースに MySQL をデプロイし、スキーマをインポートします。
- C. データベースをホストするように Cloud Bigtable を構成し、データを Cloud Bigtable にインポートします。
- D. データベースをホストするように Cloud Spanner を構成し、スキーマを Cloud Spanner にインポートします。
- E. データベースをホストするように Cloud Firestore を構成し、データを Cloud Firestore にインポートします。
Answer: A
Question 228
Cloud Run を使用して新しい Web アプリケーションを開発し、コードを Cloud Source Repositories にコミットしています。
可能な限り最も効率的な方法で新しいコードをデプロイしたいと考えています。コンテナをビルドしてコマンド gcloud run deploy を実行する Cloud Build の YAML ファイルをすでに作成しています。
次に何をすべきですか?
- A. コードがリポジトリにプッシュされたときに通知されるように Cloud Pub/Sub トピックを作成します。イベントがトピックに発行されたときにビルド ファイルを実行する Cloud Pub/Sub トリガーを作成します。
- B. 開発ブランチにプッシュされるリポジトリ コードに応答してビルド ファイルを実行するビルド トリガーを作成します。
- C. Webhook URL への HTTP POST 呼び出しに応答してビルド ファイルを実行する Webhook ビルド トリガーを作成します。
- D. 次のコマンドを 24 時間ごとに実行する Cron ジョブを作成します。
gcloud builds submit
Answer: B
Question 229
あなたは大規模な組織の開発者です。
Web アプリケーションを Google Kubernetes Engine (GKE) にデプロイしています。DevOps チームは Cloud Deploy を使用してアプリケーションを GKE の Dev、Test、Prod クラスタにデプロイする CI / CD パイプラインを構築しました。Cloud DeployがDevクラスタにアプリケーションを正常にデプロイした後、それをTestクラスタに自動的に昇格させたいと考えています。
Google が推奨するベスト プラクティスに従って、このプロセスをどのように構成するべきでしょうか?
- A.
- 1. clouddeploy-operations トピックからの SUCCEEDED Cloud Pub/Sub メッセージをリッスンする Cloud Build トリガーを作成します。
- 2. Cloud Build を構成して、アプリケーションをテスト クラスタに昇格させるステップを含めます。
- B.
- 1. Google Cloud Deploy API を呼び出してアプリケーションをテスト クラスタに昇格させる Cloud Functions を作成します。
- 2. cloud-builds トピックからの SUCCEEDED Cloud Pub/Sub メッセージによってトリガーされるようにこの関数を構成します。
- C.
- 1. Google Cloud Deploy API を呼び出してアプリケーションをテスト クラスタに昇格させる Cloud Functions を作成します。
- 2. clouddeploy-operations トピックからの SUCCEEDED Cloud Pub/Sub メッセージによってトリガーされるように関数を構成します。
- D.
- 1. gke-deploy ビルダーを使用する Cloud Build パイプラインを作成します。
- 2. cloud-builds トピックからの SUCCEEDED Cloud Pub/Sub メッセージをリッスンする Cloud Build トリガーを作成します。
- 3. このパイプラインを構成して テスト クラスタへのデプロイ手順を実行します。
Answer: A
Question 230
アプリケーションは Google Kubernetes Engine クラスタでコンテナとして実行されています。
安全なアプローチを使用してアプリケーションにシークレットを追加する必要があります。
どうすればいいでしょうか?
- A. Kubernetes シークレットを作成し、そのシークレットを環境変数としてコンテナに渡します。
- B. Cloud Key Management Service (KMS) キーを使用してクラスタでアプリケーション レイヤーのシークレット暗号化を有効にします。
- C. 認証情報を Cloud KMS に保存します。Cloud KMS から認証情報を読み取るための Google サービス アカウント (GSA) を作成します。GSA を .json ファイルとしてエクスポートし、Cloud KMS から認証情報を読み取ることができるボリュームとして .json ファイルをコンテナに渡します。
- D. 認証情報を Secret Manager に保存します。Secret Manager から認証情報を読み取るための Google サービス アカウント (GSA) を作成します。コンテナを実行するための Kubernetes サービス アカウント (KSA) を作成します。Workload Identity を使用して KSA が GSA として機能するように構成します。
Answer:D
Question 231
あなたは金融機関の開発者です。
Cloud Shell を使用して Google Cloud サービスとやり取りします。現在、ユーザー データは一時ディスクに保存されています。ただし、最近可決された規制により、機密情報を一時ディスクに保存することはできなくなりました。ユーザー データ用の新しいストレージ ソリューションを実装する必要があり、コードの変更を最小限に抑えたいと考えています。
ユーザーデータをどこに保存しますか?
- A. Cloud Shell のホーム ディスクにユーザー データを保存し、少なくとも 120 日ごとにログインして、データが削除されないようにします。
- B. Compute Engine インスタンスの永続ディスクにユーザー データを保存します。
- C. ユーザー データを Cloud Storage バケットに保存します。
- D. ユーザー データを BigQuery テーブルに保存します。
Answer: B
Question 232
最近、ログデータを Cloud Storage バケットに毎日転送する Web アプリケーションを開発しました。
認証されたユーザーは重要なイベントについて過去 2 週間のログを定期的に確認します。その後、ログは年に 1 回、外部監査人によってレビューされます。データは 7 年以上保存する必要があります。これらの要件を満たし、コストを最小限に抑えるストレージ ソリューションを提案したいと考えています。
どうすればいいでしょうか? (回答は 2 つ)
- A. バケット ロック機能を使用してデータの保持ポリシーを設定します。
- B. スケジュールされたジョブを実行して、14 日以上経過したオブジェクトのストレージ クラスを Coldline に設定します。
- C. Coldline ストレージ バケットへのアクセスが必要なユーザーのために JSON Web トークン (JWT) を作成します。
- D. ライフサイクル管理ポリシーを作成して 14 日以上経過したオブジェクトのストレージ クラスを Coldline に設定します。
- E. ライフサイクル管理ポリシーを作成して 14 日以上経過したオブジェクトのストレージ クラスを Nearline に設定します。
Answer:A、D
Question 233
チームは Cloud Storage イベントによってトリガーされる Cloud Functions を開発しています。
Google が推奨するベスト プラクティスに従いながら Cloud Functions のテストと開発を加速したいと考えています。
どうすればいいでしょうか?
- A. Cloud Audit Logs が元の Cloud Functions で cloudfunctions.functions.sourceCodeSet 操作を検出したときにトリガーされる新しい Cloud Functions を作成します。モック リクエストを新しい関数に送信して機能を評価します。
- B. Cloud Functions のコピーを作成し、HTTP でトリガーされるようにコードを書き直します。HTTP エンドポイントをトリガーして新しいバージョンを編集およびテストします。モック リクエストを新しい関数に送信して機能を評価します。
- C. Functions Frameworks ライブラリをインストールし、localhost で Cloud Functions を構成します。関数のコピーを作成し、新しいバージョンを編集します。curl を使用して新しいバージョンをテストします。
- D. Google Cloud コンソールで Cloud Functions のコピーを作成します。Google Cloud Console のインライン エディタを使用して新しい関数のソースコードを変更します。新しい関数を呼び出すように Web アプリケーションを変更し、本番環境で新しいバージョンをテストします
Answer: B
Question 234
チームは Google Kubernetes Engine (GKE) で実行されるアプリケーションのビルド パイプラインを構築しています。
セキュリティ上の理由からパイプラインによって生成されたイメージのみを GKE クラスタにデプロイする必要があります。
Google Cloud サービスのどの組み合わせを使用しますか?
- A. Cloud Build、Cloud Storage、Binary Authorization
- B. Cloud Deploy、Cloud Storage、Cloud Armor
- C. Cloud Deploy、Artifact Registry、Cloud Armor
- D. Cloud Build、Artifact Registry、Binary Authorization
Answer:D
Question 235
Cloud Run にデプロイされた本番環境のビジネス クリティカルなアプリケーションをサポートしています。
アプリケーションはアプリケーションの使いやすさに影響を与える HTTP 500 エラーを報告しています。特定の時間枠内でエラー数がリクエストの 15% を超えたときにアラートを受け取る必要があります。
どうすればいいでしょうか?
- A. Cloud Monitoring API を使用する Cloud Functions を作成します。Cloud Scheduler を使用して Cloud Functions を毎日トリガーし、エラー数が定義されたしきい値を超えた場合にアラートを出します。
- B. Google Cloud コンソールの Cloud Run ページに移動し、サービス リストからサービスを選択します。[指標] タブを使用してそのリビジョンのエラー数を視覚化し、ページを毎日更新します。
- C. Cloud Monitoring でアラート ポリシーを作成し、エラー数が定義されたしきい値を超えた場合にアラートを送信します。
- D. Cloud Monitoring API を使用する Cloud Functions を作成します。Cloud Composer を使用して Cloud Functions を毎日トリガーし、エラー数が定義されたしきい値を超えた場合にアラートを出します。
Answer:C
Question 236
API 呼び出し元の認証、クォータの適用、メトリックのレポートを行うパブリック API を構築する必要があります。
このアーキテクチャを完成させるにはどのツールを使用しますか?

- A. App Engine
- B. Cloud Endpoints
- C. Identity-Aware Proxy
- D. HTTP(S) 負荷分散のための GKE Ingress
Answer: B
Question 237
Google Kubernetes Engine での Deployment の更新中にアプリケーションが強制的にシャットダウンされたことに気付きました。
アプリケーションが終了する前にデータベース接続を閉じませんでした。アプリケーションを更新して正常なシャットダウンを確実に完了したいと考えています。
どうすればいいでしょうか?
- A. コードを更新して受信した SIGTERM シグナルを処理し、データベースから正常に切断します。
- B. PodDisruptionBudget を構成して Pod が強制的にシャットダウンされないようにします。
- C. アプリケーションのterminationGracePeriodSecondsを増やします。
- D. アプリケーションをシャットダウンする PreStop フックを構成します。
Answer: A
Question 238
Cloud Run と Cloud Firestore in Datastore モードで実行される新しい小売システムに取り組んでいるリード デベロッパーです。
Web UI の要件はユーザーがシステムにアクセスしたときにシステムが利用可能な製品のリストを表示し、ユーザーがすべての製品を参照できるようにすることです。Cloud Firestore に保存されているすべての利用可能な製品のリストを返すことにより、実用最小限の製品 (MVP) フェーズでこの要件を実装しました。稼働開始から数か月後、Cloud Run インスタンスが HTTP 500: コンテナ インスタンスがビジー時間中にメモリ制限を超えているというエラーで終了していることに気付きました。このエラーは Datastore エンティティの読み取り数の急増と同時に発生します。Cloud Run がクラッシュするのを防ぎ、Datastore エンティティの読み取り回数を減らす必要があります。システムのパフォーマンスを最適化するソリューションを使用したいと考えています。
どうすればいいでしょうか?
- A. 整数オフセットを使用して製品リストを返すクエリを変更します。
- B. 制限を使用して製品リストを返すクエリを変更します。
- C. Cloud Run の構成を変更してメモリの上限を引き上げます。
- D. カーソルを使用して製品リストを返すクエリを変更します。
Answer:D
Question 239
インターネットに接続するマイクロサービス アプリケーションを Google Kubernetes Engine (GKE) にデプロイする必要があります。
A/B テスト方法を使用して新機能を検証したいと考えています。新しいコンテナ イメージ リリースをデプロイするには次の要件があります。
– 新しいコンテナ イメージをデプロイする際のダウンタイムはありません。
– 新しい本番リリースは本番ユーザーのサブセットを使用してテストおよび検証されます。
どうすればいいでしょうか?
- A.
- 1. CI / CD パイプラインを構成してコンテナのバージョンを最新バージョンに置き換えてデプロイ マニフェスト ファイルを更新します。
- 2. Deployment マニフェスト ファイルを適用してクラスタ内に Pod を再作成します。
- 3. アプリケーションの機能を以前のリリース バージョンと比較してアプリケーションのパフォーマンスを検証し、問題が発生した場合はロールバックします。
- B.
- 1. 新しいリリース バージョン用に GKE に 2 番目の名前空間を作成します。
- 2. 必要な数の Pod を使用して 2 番目の名前空間のデプロイ構成を作成します。
- 3. 新しいコンテナ バージョンを 2 番目の名前空間にデプロイします。
- 4. Ingress 構成を更新してトラフィックを新しいコンテナ バージョンの名前空間にルーティングします。
- C.
- 1. GKE クラスタに Anthos Service Mesh をインストールします。
- 2. GKE クラスタに 2 つの Deployment を作成し、それらに異なるバージョン名のラベルを付けます。
- 3. Istio ルーティング ルールを実装して新しいバージョンのアプリケーションを参照する Deployment にトラフィックのごく一部を送信します。
- D.
- 1. Pod を徐々に新しいリリース バージョンに置き換えることでローリング アップデート パターンを実装します。
- 2. ロールアウト中に新しいユーザーのサブセットに対するアプリケーションのパフォーマンスを検証し、問題が発生した場合はロールバックします。
Answer: B
Question 240
チームは大規模な Google Kubernetes Engine (GKE) クラスタを管理しています。
現在、複数のアプリケーション チームが同じ名前空間を使用してクラスタ用のマイクロサービスを開発しています。組織はマイクロサービスを作成するために追加のチームをオンボードすることを計画しています。各チームの作業のセキュリティと最適なパフォーマンスを確保し、複数の環境を構成する必要があります。コストを最小限に抑え Google が推奨するベスト プラクティスに従います。
どうすればいいでしょうか?
- A. 既存のクラスタ内の各チームに対して新しい役割ベースのアクセス制御 (RBAC) を作成し、リソース クォータを定義します。
- B. 既存のクラスタ内の環境ごとに新しい名前空間を作成し、リソース クォータを定義します。
- C. チームごとに新しい GKE クラスタを作成する。
- D. 既存のクラスタ内の各チームに新しい名前空間を作成し、リソース クォータを定義します。
Answer: A
Question 241
Java アプリケーションを Cloud Run にデプロイしました。
アプリケーションは Cloud SQL でホストされているデータベースにアクセスする必要があります。規制要件により、Cloud SQL インスタンスへの接続には内部 IP アドレスを使用する必要があります。
Google が推奨するベスト プラクティスに従って、接続をどのように構成するべきでしょうか?
- A. Cloud SQL 接続を使用して Cloud Run サービスを構成します。
- B. サーバレス VPC アクセス コネクタを使用するように Cloud Run サービスを構成します。
- C. Cloud SQL Java コネクタを使用するようにアプリケーションを構成します。
- D. Cloud SQL Auth Proxy のインスタンスに接続するようにアプリケーションを構成します。
Answer: B
Question 242
アプリケーションは顧客のコンテンツを Cloud Storage バケットに保存し、各オブジェクトは顧客の暗号鍵で暗号化されます。
Cloud Storage 内の各オブジェクトのキーは顧客がアプリケーションに入力します。Cloud Storage からオブジェクトを読み取るときにアプリケーションが HTTP 4xx エラーを受け取っていることがわかりました。
このエラーの考えられる原因は何でしょうか?
- A. 顧客の base64 でエンコードされたキーを使用してオブジェクトの読み取り操作を試みました。
- B. base64 でエンコードされた暗号化キーの SHA256 ハッシュなしで読み取り操作を試みました。
- C. 読み取り操作を試行したときに顧客が指定したものと同じ暗号化アルゴリズムを入力した。
- D. base64 でエンコードされた顧客のキーの SHA256 ハッシュを使用してオブジェクトに対して読み取り操作を試みました。
Answer:C
Question 243
プロジェクト A とプロジェクト B という 2 つの Google Cloud プロジェクトがあります。
プロジェクト B の Cloud Storage バケットに出力を保存する Cloud Functions をプロジェクト A に作成する必要があります。最小権限の原則に従う必要があります。
どうすればいいでしょうか?
- A.
- 1. プロジェクト B で Google サービス アカウントを作成します。
- 2. プロジェクト A のサービス アカウントで Cloud Functions をデプロイします。
- 3. このサービス アカウントにプロジェクト B にあるストレージ バケットに対する roles/storage.objectCreator のロールを割り当てます。
- B.
- 1. プロジェクト A で Google サービス アカウントを作成する
- 2. プロジェクト A のサービス アカウントで Cloud Functions をデプロイします。
- 3. このサービス アカウントにプロジェクト B にあるストレージ バケットに対する roles/storage.objectCreator のロールを割り当てます。
- C.
- 1. プロジェクト A のデフォルトの App Engine サービス アカウント (PROJECT_ID@appspot.gserviceaccount.com) を決定します。
- 2. プロジェクト A でデフォルトの App Engine サービス アカウントを使用して Cloud Functions をデプロイします。
- 3. デフォルトの App Engine サービス アカウントにプロジェクト B にあるストレージ バケットの roles/storage.objectCreator のロールを割り当てます。
- D.
- 1. プロジェクト B のデフォルトの App Engine サービス アカウント (PROJECT_ID@appspot.gserviceaccount.com) を決定します。
- 2. プロジェクト A でデフォルトの App Engine サービス アカウントを使用して Cloud Functions をデプロイします。
- 3. デフォルトの App Engine サービス アカウントにプロジェクト B にあるストレージ バケットの roles/storage.objectCreator のロールを割り当てます。
Answer: B
Question 244
最近、アプリケーションに影響を与える政府規制が可決されました。
コンプライアンスの目的で特定のアプリケーション ログの複製をアプリケーションのプロジェクトからセキュリティ チームに限定されたプロジェクトに送信する必要があります。
どうすればいいでしょうか?
- A. セキュリティ チームのプロジェクトでユーザー定義のログ バケットを作成します。Cloud Logging シンクを構成してアプリケーションのログをセキュリティ チームのプロジェクトのログバケットにルーティングします。
- B. _Required ログ バケットからプロジェクト内のセキュリティ チームのログ バケットにログをコピーするジョブを作成します。
- C. _Default ログ バケット シンク ルールを変更してログをセキュリティ チームのログ バケットに再ルーティングします。
- D. システム イベント ログを _Required ログ バケットからプロジェクトのセキュリティ チームのログ バケットにコピーするジョブを作成します。
Answer: A
Question 245
新しい Go アプリケーションを Cloud Run にデプロイする予定です。
ソースコードは Cloud Source Repositories に保存されます。ソース コードのコミット時に実行されるフル マネージドの自動化された継続的デプロイ パイプラインを構成する必要があります。最も単純なデプロイソリューションを使用したい。
どうすればいいでしょうか?
- A. ワークステーションで cron ジョブを構成して作業ディレクトリで gcloud run deploy –source を定期的に実行します。
- B. Jenkins トリガーを構成して Cloud Source Repositories にコミットされたソースコードごとにコンテナのビルドとデプロイ プロセスを実行します。
- C. ビルドパックを使用して Cloud Run のソース リポジトリから新しいリビジョンの継続的なデプロイを構成する。
- D. Cloud Build を使用して Cloud Source Repositories にコミットされたソースコードごとにコンテナのビルドおよびデプロイ プロセスを実行するように構成されたトリガーを使用します。
Answer:D
Question 246
チームは Google Kubernetes Engine (GKE) クラスタでホストされるアプリケーションを作成しました。
アプリケーションを 2つの異なる地域の2つのGKEクラスターにデプロイされているレガシーRESTサービスに接続する必要があります。アプリケーションとターゲットサービスを弾力性のある方法で接続したい。また、別のポートでレガシーサービスのヘルスチェックを実行できるようにしたいと思います。
接続をどのように設定しますか? (回答は 2 つ)
- A. サイドカー プロキシで Traffic Director を使用してアプリケーションをサービスに接続します。
- B. プロキシレス Traffic Director 構成を使用してアプリケーションをサービスに接続します。
- C. レガシー サービスのファイアウォールを構成してプロキシからのヘルス チェックを許可する。
- D.アプリケーションからのヘルスチェックを許可するようにレガシーサービスのファイアウォールを構成します。
- E. 従来のサービスのファイアウォールを構成して Traffic Director コントロール プレーンからのヘルス チェックを許可します。
Answer:A、C
Question 247
本番環境の Google Kubernetes Engine (GKE) クラスタでアプリケーションを実行しています。
Cloud Deploy を使用してアプリケーションを本番 GKE クラスタに自動的にデプロイします。開発プロセスの一環としてアプリケーションのソース コードを頻繁に変更することを計画しており、変更をリモート ソース コード リポジトリにプッシュする前に変更をテストするツールを選択する必要があります。
ツールセットは次の要件を満たす必要があります。
– 頻繁なローカル変更を自動的にテストします。
– ローカル デプロイは本番デプロイをエミュレートします。
最小限のリソースを使用してラップトップでコンテナのビルドと実行をテストするにはどのツールを使用しますか?
- A. Docker Compose と dockerd
- B. Terraform と kubeadm
- C. Minikube と Skaffold
- D.Kaniko と Tekton
Answer:C
Reference:
– Google Cloud Deploy で Skaffold を使ってみる
– Cloud Code と Skaffold モジュールで Kubernetes マイクロサービス アプリケーションの開発とデバッグを迅速化 | Google Cloud 公式ブログ
Question 248
Cloud Source Repositories と Cloud Build を使用して Python アプリケーションを Cloud Run にデプロイしています。
Cloud Build パイプラインを以下です。
steps:
name: python
entrypoint: pip
args: ["install", "-r", "requirements.txt", "--user"]
name: 'gcr.io/cloud-builders/docker'
args: ['build', '-t',
'us-centrall-docker.pkg.dev/$(PROJECT_ID)/$_REPO_NAME}/myimage: $(SHORT_SHA}',נ'
name: gcr.io/cloud-builders/docker'
args: ['push', 'us-centrall-docker.pkg.dev/${PROJECT_ID}/$(_REPO_NAME}/myimage: $(SHORT_SHA)']
name: google/cloud-sdk
args: ['gcloud', 'run', 'deploy', 'helloworld-$(SHORT_SHA)', --image-us-centrall-docker.pkg.dev/${PROJECT_ID)/$(_REPO_NAME)/myimage: $ (SHORT_SHA)'
, --region', 'us-centrall', '--platform', 'managed'
,--allow-unauthenticated']デプロイ時間を最適化し、不要な手順を回避したいと考えています。
どうすればいいでしょうか?
- A. コンテナを Artifact Registry にプッシュするステップを削除します。
- B. 新しい Docker レジストリを VPC にデプロイし、VPC 内で Cloud Build ワーカー プールを使用してビルド パイプラインを実行します。
- C. Cloud Run インスタンスと同じリージョンにある Cloud Storage バケットにイメージ アーティファクトを保存します。
- D. –cache-from 引数をビルド構成ファイルの Docker ビルド ステップに追加します。
Answer:D
Question 249
イベント駆動型アプリケーションを開発しています。
Pub/Sub に送信されたメッセージを受信するトピックを作成しました。これらのメッセージをリアルタイムで処理する必要があります。アプリケーションは他のシステムから独立している必要があり、新しいメッセージが到着したときにのみコストが発生します。
アーキテクチャをどのように構成する必要がありますか?
- A. アプリケーションを Compute Engine にデプロイします。Cloud Pub/Sub プッシュ サブスクリプションを使用してトピック内の新しいメッセージを処理します。
- B. Cloud Functions にコードをデプロイします。Cloud Functions を呼び出すには Cloud Pub/Sub トリガーを使用します。Cloud Pub/Sub API を使用して Cloud Pub/Sub トピックへのプル サブスクリプションを作成し、そこからメッセージを読み取ります。
- C. アプリケーションを Google Kubernetes Engine にデプロイします。Cloud Pub/Sub API を使用して Cloud Pub/Sub トピックへのプル サブスクリプションを作成し、そこからメッセージを読み取ります。
- D. Cloud Functions にコードをデプロイします。Cloud Pub/Sub トリガーを使用してトピック内の新しいメッセージを処理します。
Answer: B
Question 250
Google Kubernetes Engine (GKE) で実行されているアプリケーションがあります。
アプリケーションは現在ロギング ライブラリを使用しており、標準出力に出力しています。ログを Cloud Logging にエクスポートする必要があり、ログに各リクエストに関するメタデータを含める必要があります。これを実現するには最も簡単な方法を使用します。
どうすればいいでしょうか?
- A. アプリケーションのログ ライブラリを Cloud Logging ライブラリに変更し、ログを Cloud Logging にエクスポートするようにアプリケーションを構成します。
- B. JSON 形式でログを出力するようにアプリケーションを更新し、必要なメタデータを JSON に追加します。
- C. アプリケーションを更新してログを CSV 形式で出力し、必要なメタデータを CSV に追加します。
- D. 各 GKE ノードに Fluent Bit エージェントをインストールし、エージェントが /var/log からすべてのログをエクスポートするようにします。
Answer: A
Question 251
Cloud Run にデプロイされ、Cloud Functions を使用する新しいアプリケーションに取り組んでいます。
新しい機能が追加されるたびに新しい Cloud Functions と Cloud Run サービスがデプロイされます。ENV 変数を使用してサービスを追跡し、サービス間通信を有効にしますが ENV 変数のメンテナンスが難しくなっています。スケーラブルな方法で動的検出を実装したいと考えています。
どうすればいいでしょうか?
- A. Cloud Run Admin API と Cloud Functions API を使用してマイクロサービスを構成し、Google Cloud プロジェクトにデプロイされた Cloud Run サービスと Cloud Functions をクエリします。
- B. Service Directory 名前空間を作成します。API 呼び出しを使用してデプロイ時にサービスを登録し、実行時にクエリを実行します。
- C. Cloud Functions と Cloud Run サービス エンドポイントの名前を変更するには十分に文書化された命名規則を使用します。
- D. 単一の Compute Engine インスタンスに Hashicorp Consul をデプロイします。デプロイ時にサービスを Consul に登録し、実行時にクエリを実行します。
Answer: B
Question 252
コンテナ ファーストのアプローチを採用している金融サービス会社で働いています。
チームはマイクロサービス アプリケーションを開発しています。Cloud Build パイプラインはコンテナ イメージを作成し、回帰テストを実行してイメージを Artifact Registry に公開します。回帰テストに合格したコンテナのみが Google Kubernetes Engine (GKE) クラスタにデプロイされるようにする必要があります。GKE クラスタで Binary Authorization をすでに有効にしています。
何をするべきでしょうか?
- A. アテスターとポリシーを作成します。コンテナ イメージが回帰テストに合格したら Cloud Build を使用して Kritis Signer を実行し、コンテナ イメージの証明書を作成します。
- B. Voucher Server および Voucher Client コンポーネントをデプロイします。コンテナ イメージが回帰テストに合格したら Cloud Build パイプラインのステップとして Voucher Client を実行します。
- C. 関連する名前空間の Pod Security Standard レベルを Restricted に設定します。Cloud Build を使用して回帰テストに合格したコンテナ イメージにデジタル署名します。
- D. 認証者とポリシーを作成します。Cloud Build パイプラインのステップとして回帰テストに合格したコンテナ イメージの証明書を作成します。
Answer: A
Question 253
ベスト プラクティスに準拠するために Cloud Build の手順を確認して更新しています。
現在、ビルド手順は次のとおりです。
1. ソース リポジトリからソース コードを取得します。
2. コンテナ イメージをビルドする
3. ビルドしたイメージを Artifact Registry にアップロードします。
ビルドされたコンテナ イメージの脆弱性スキャンを実行するステップを追加する必要があり、スキャンの結果を Google Cloud で実行されているデプロイ パイプラインで利用できるようにする必要があります。他のチームのプロセスを混乱させる可能性のある変更を最小限に抑えたいと考えています。
どうすればいいでしょうか?
- A. Binary Authorization を有効にし、コンテナ イメージに脆弱性が存在しないことを証明するように構成します。
- B. ビルドされたコンテナ イメージを Docker Hub インスタンスにアップロードし、脆弱性をスキャンします。
- C. Artifact Registry で Container Scanning API を有効にし、ビルドされたコンテナ イメージの脆弱性をスキャンします。
- D. Artifact Registry を Aqua Security インスタンスに追加し、構築されたコンテナ イメージの脆弱性をスキャンします。
Answer:C
Question 254
Google Kubernetes Engine (GKE) でマイクロサービス アプリケーションとしてオンライン ゲーム プラットフォームを開発しています。
ソーシャル メディアのユーザーはアプリケーションへの特定の URL 要求の読み込み時間が長いことに不満を持っています。アプリケーションのパフォーマンスのボトルネックを調査し、ユーザー リクエストの待ち時間が非常に長い HTTP リクエストを特定する必要があります。
どうすればいいでしょうか?
- A. kubectl を使用して GKE ワークロード メトリクスを構成します。Cloud Monitoring に指標を送信するすべての Pod を選択します。Cloud Monitoring でアプリケーション指標のカスタム ダッシュボードを作成して GKE クラスタのパフォーマンスのボトルネックを特定します。
- B. マイクロサービスを更新して HTTP 要求メソッドと URL パスを STDOUT に記録します。ログルーターを使用してコンテナ ログを Cloud Logging に送信します。Cloud Logging でフィルタを作成してさまざまなメソッドと URL パスにわたるユーザー リクエストのレイテンシを評価します。
- C. OpenTelemetry トレース パッケージをインストールしてマイクロサービスを計測します。アプリケーション コードを更新して検査と分析のためにトレースを Trace に送信します。Trace で分析レポートを作成してユーザーの要求を分析します。
- D. GKE ノードに tcpdump をインストールします。tcpdump を実行してネットワーク トラフィックを長期間にわたってキャプチャし、データを収集します。Wireshark を使用してデータ ファイルを分析し、高レイテンシの原因を特定します。
Answer: A
Question 255
Cloud Run にデプロイされた一連の REST API エンドポイントの負荷テストを行う必要があります。
API は HTTP POST リクエストにレスポンスします。
負荷テストは次の要件を満たす必要があります。
– ロードは複数の並列スレッドから開始されます。
– API へのユーザー トラフィックは複数の送信元 IP アドレスから発信されます。
– 負荷は追加のテスト インスタンスを使用してスケール アップできます。
Google が推奨するベスト プラクティスに従います。
負荷テストをどのように構成するべきでしょうか?
- A. cURL がインストールされたイメージを作成し、テスト計画を実行するように cURL を構成します。マネージド インスタンス グループにイメージをデプロイし、VM ごとにイメージの 1 つのインスタンスを実行します。
- B. cURL がインストールされたイメージを作成し、テスト計画を実行するように cURL を構成します。イメージを非マネージド インスタンス グループにデプロイし、VM ごとにイメージの 1 つのインスタンスを実行します。
- C. 分散負荷テスト フレームワークをプライベート Google Kubernetes Engine クラスタにデプロイします。必要に応じて追加の Pod をデプロイしてより多くのトラフィックを開始し、同時ユーザー数をサポートします。
- D. Cloud Shell で分散負荷テスト フレームワークのコンテナ イメージをダウンロードします。Cloud Shell でコンテナの複数のインスタンスを順番に開始して API の負荷を増やします。
Answer:C
Comments are closed