![[GCP] Google Cloud Certified:Professional Cloud Architect](https://www.cloudsmog.net/wp-content/uploads/google-cloud-certified_professional-cloud-architect-1200x675.jpg)
※ 他の問題集は「タグ:Professional Cloud Architect の模擬問題集」から一覧いただけます。
この模擬問題集は「Professional Cloud Architect Practice Exam (2021.02.12)」の回答・参考リンクを改定した日本語版の模擬問題集です。
Google Cloud 認定資格 – Professional Cloud Architect – 模擬問題集(全 53問)
Question 01
この問題については JencoMart のケーススタディ を参照してください。
JencoMart のセキュリティチームは、すべての GCP インフラストラクチャを本番リソースと開発リソースの間で管理の職務が分離された最小特権モデルを使用してデプロイできることを望んています。
どのような Google ドメインとプロジェクト構造を推奨しますか?
- A. 2 つの G Suite アカウントを作成します。各アカウントにはアプリケーションごとに 1 つのプロジェクトが含まれている必要があります。
- B. 2 つの G Suite アカウントを作成します。1 つはすべての開発アプリケーション用の 1 つのプロジェクト、もう 1 つはすべての本番アプリケーション用の 1 つのプロジェクトです。
- C. 1 つの G Suite アカウントを作成します。各アプリケーションの各ステージのユーザーをそれぞれのプロジェクトで管理します。
- D. 1 つの G Suite アカウントを作成します。開発/テスト/ステージング環境用の 1 つのプロジェクトと本番環境用の 1 つのプロジェクトでユーザーを管理します。
Correct Answer: D
最小特権と職務分離の原則はセキュリティの観点から本質的に関連している概念です。
両方の背後にある目的は人々が実際に必要とするよりも高い特権レベルを持つことを防ぐことです。
-最小特権:ユーザーはジョブを実行するために必要な最小限の特権しか持たず、それ以上の権限は持たないようにします。これにより、許可されていないターゲット、ジョブ、監視テンプレートなどのリソースへのアクセスが制限されるため、許可の悪用が減ります。
– 職務分離:ユーザーの特権レベルを制限するだけでなく、ユーザーの職務、ユーザーが実行できる特定のジョブも制限します。ユーザーには 2つ以上の関連する機能の責任を与えてはなりません。これにより、ユーザーが悪意のあるアクションを実行し、そのアクションを隠蔽する能力が制限されます。
Reference contents:
– 職掌分散 | Cloud KMS ドキュメント | Google Cloud
Question 02
この問題については JencoMart のケーススタディ を参照してください。
JencoMart がユーザー認証情報データベースを Google Cloud Platform に移行し、古いサーバーをシャットダウンしてから数日後、新しいデータベースサーバーはSSH 接続への応答を停止します。
それでも、アプリケーションサーバーへのデータベース要求を正しく処理しています。
問題を診断するためにどのステップを踏むべきでしょうか? (回答を 3つ選択してください)
- A. 仮想マシンとディスクを削除して新しいものを作成します。
- B. インスタンスを削除し、ディスクを新しいVM に接続して調査します。
- C. ディスクのスナップショットを取り、新しいマシンに接続して調査します。
- D. マシンが接続しているネットワークのインバウンド ファイアウォール ルールを確認します。
- E. マシンを非常に簡単なファイアウォール ルールで別のネットワークに接続して調査します。
- F. トラブルシューティングのためにインスタンスのシリアル コンソール出力を印刷し、インタラクティブ コンソールを起動して調査します。
Correct Answer: C、D、F
D:「ポート22に接続できません」というエラーメッセージを処理する
– ポートでのSSH アクセスを許可するファイアウォール ルールはありません。ポート 22 でのSSH アクセスはデフォルトですべての Google Compute Engine インスタンスに有効です。アクセスを無効にしている場合はブラウザからのSSH は機能しません。ポート 22 以外 のでSSH を実行する場合はカスタム ファイアウォール ルールを使用してそのポートへのアクセスを有効にする必要があります。
– SSH アクセスを許可するファイアウォール ルールは有効になっていますが、Google Cloud Console サービスからの接続を許可するように構成されていません。ブラウザベースのSSH セッションの送信元 IP アドレスは Google Cloud Console によって動的に割り当てられ、セッションごとに異なる可能性があります。
F:「接続できませんでした。再試行しています…」
– シリアル コンソール出力ページに移動し、文字列「accounts-from-metadata」のプレフィックスが付いた出力行を探すことでデーモンが実行されていることを確認できます。標準イメージを使用していてもシリアル コンソール出力にプレフィックスが表示されない場合は、デーモンが停止している可能性があります。インスタンスを再起動してデーモンを再起動します。
Reference contents:
– ブラウザからの SSH | Compute Engine ドキュメント | Google Cloud
Question 03
この問題については JencoMart のケーススタディ を参照してください。
JencoMart はユーザープロファイル ストレージを Google Cloud Datastore に移行し、アプリケーションサーバーを Google Compute Engine(GCE)に移行することを決定した。
移行中、既存のインフラストラクチャはデータをアップロードするために Google Cloud Datastore にアクセスする必要があります。
どのようなサービス アカウントの鍵管理戦略をお勧めしますか?
- A. オンプレミスのインフラストラクチャと GCE VM のサービス アカウント キーをプロビジョニングします。
- B. オンプレミスのインフラストラクチャにユーザー アカウントで認証し、VM に対してサービス アカウント キーをプロビジョニングします。
- C. オンプレミスのインフラストラクチャにサービス アカウント キーをプロビジョニングし、VM に Google が管理する暗号鍵を使用します。
- D. オンプレミスのインフラストラクチャに Google Kubernetes Engine のカスタム認証サービスを導入し、VM に Google が管理する暗号鍵を使用します。
Correct Answer: C
他のクラウド プロバイダで行われているデータ処理があり、処理したデータを GCP に転送する場合は、外部クラウド上の仮想マシンからサービス アカウントを利用してそのデータを GCP にプッシュすることができます。そのためには、サービス アカウントを作成する際にサービス アカウント キーを作成してダウンロードし、外部プロセスからそのキーを使用して Google Cloud API を呼び出す必要があります。
Reference contents:
– サービス アカウントについて #サービス アカウント キーの管理 | Cloud IAM ドキュメント | Google Cloud
Question 04
この問題については JencoMart のケーススタディ を参照してください。
JencoMart はアジアへのトラフィックを提供するアプリケーションのバージョンを Google Cloud Platform に構築しました。
JencoMart はビジネス要件と技術的要件に対する成功を測定したいと考えています。
どのような指標を追跡する必要がありますか?
- A. アジアからのリクエストのエラー率。
- B. 米国とアジアの待ち時間の違い。
- C. アジアからの総訪問数、エラー率、および待ち時間。
- D. アジアのユーザーの合計訪問数と平均待ち時間。
- E. データベースに存在する文字セットの数。
Correct Answer: D
シナリオ:
– ビジネス要件:アジアへのサービス拡大
– 技術要件:アジアでの待ち時間を短縮
Question 05
この問題については JencoMart のケーススタディ を参照してください。
JencoMart のアプリケーションの GCP への移行が遅れています。
インフラストラクチャは下図でスループットを最大化したいと考えています。
潜在的なボトルネックは何でしょうか?(回答を 3つ選択してください)
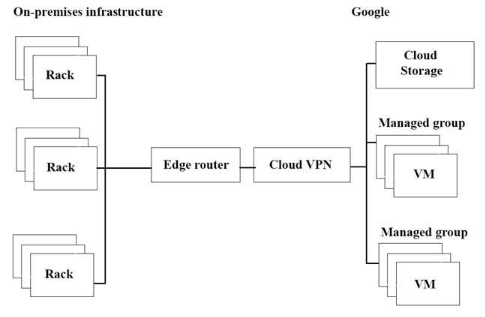
- A. スループットを制限する単一のVPNトンネル。
- B. Google Cloud Storage はこのタスクに適していません 。
- C. 長距離での運用に不向きなコピーコマンド。
- D. GCP のVM の数がオンプレミスのマシンより少ない。
- E. VM の外側に別のストレージ層はこのタスクに適していません。
- F. オンプレミスのインフラとGCP 間のインターネット接続が複雑です。
Correct Answer: A、C、E
Question 06
この問題については JencoMart のケーススタディ を参照してください。
JencoMart はユーザー プロフィールのデータベースを Google Cloud Platform に移行したいと考えています。
どのGCP のデータベースを使うべきでしょうか?
- A. Google Cloud Spanner
- B. Google BigQuery
- C. Google Cloud SQL
- D. Google Cloud Datastore
Correct Answer: D
Google Cloud Datastore の一般的なワークロード:
– ユーザープロファイル
– 製品カタログ
– ゲーム状態
Reference contents:
– クラウド ストレージ オプション | Google Cloud
– Datastore の概要 | Cloud Datastore ドキュメント | Google Cloud
Question 07
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Games は新しいテスト戦略を設計について検討しています。
テスト範囲は他のプラットフォームの既存バックエンドとどのように異なるべきでしょうか?
- A. テストは以前の内容を大きく超えて行います。
- B. 単体テストは不要になり、エンドツーエンドのテストのみを行います。
- C. テストはリリースが実稼働環境に入った後に行います。
- D. テストには GCP インフラストラクチャの直接テストを含めて行います。
Correct Answer: A
シナリオより:
– いくつかのゲームが予想以上に人気があり、アプリケーションサーバー、MySQL データベース、分析ツールのスケーリングに問題がありました。
– GCP 要件はゲームのアクティビティに基づいて動的にスケールアップまたはスケールダウンします。
Question 08
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Games は新しいバックエンドを Google Cloud Platform にデプロイしました。
バックエンドの新バージョンが公開される前に徹底したテストプロセスを作り、テスト環境を経済的な方法で拡張したいと考えています。
どのようにプロセスを設計すべきでしょうか?
- A. 本番負荷をシミュレーションするためのスケーラブルな環境を GCP で構築します。
- B. 既存のインフラストラクチャを使用して GCP ベースのバックエンドをスケールでテストします。
- C. GCP 内部のリソースを使用してアプリケーションの各コンポーネントにストレステストを構築し、負荷をシミュレートします。
- D. GCP に静的環境を作成して様々なレベルの負荷をテストします。
Correct Answer: A
シナリオから:
[ゲームバックエンドプラットフォームの要件]
– ゲームアクティビティに基づいて動的にスケールアップまたはスケールダウン
– 管理されたNoSQLデータベースサービスに接続
– Linux ディストロをカスタマイズして実行
Question 09
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Games は継続的デリバリー パイプラインの構築を検討しています。
アーキテクチャには多くの小さなサービスが含まれており、迅速にアップデートやロールバックができるようにしたいと考えています。
Mountkirk Games は次のような要件があります。
– サービスは米国とヨーロッパの複数の地域に冗長的に展開されている
– フロントエンドサービスのみインターネット上で公開している
– 自社のサービスに単一のフロントエンド IP を提供できる。
– 不変のデプロイメント アーティファクト
どのプロダクトを組み合わせればよいでしょうか?
- A. Google Cloud Storage、Google Cloud Dataflow、Google Compute Engine
- B. Google Cloud Storage、Google App Engine、Google Network Load Balancer
- C. Google Kubernetes Registry、Google Container Engine、Google HTTP(S) Load Balancer
- D. Google Cloud Functions、Google Cloud Pub/Sub、Google Cloud Deployment Manager
Correct Answer: C
Question 10
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Games のゲーミングサーバーが自動的に正しくスケーリングされていません。
先月に新機能を公開し、突然大人気になりました。
記録的な数のユーザーがサービスを利用していますが、多くのユーザーが503エラーが表示され、非常に遅いレスポンスになっています。
何を調べるべきでしょうか?
- A. データベースがオンラインであることを確認してください。
- B. プロジェクトの割り当てを超えていないことを確認します。
- C. 新しい機能コードでパフォーマンスのバグが発生していないことを確認します。
- D. 負荷テストチームが本番環境に対してツールを実行していないことを確認します。
Correct Answer: B
エラー 503はサービス利用不可の表示です。もしデータベースがオンラインであれば、誰もが 503 のエラーになります。
Reference contents:
– レスポンス エラーのトラブルシューティング | App Engine 用 Cloud Endpoints Frameworks
Question 11
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Games は分離されたアプリケーション環境をデプロイするための再現性と構成可能なメカニズムを作成する必要があります。
開発者とテスターはお互いの環境やリソースにアクセスできますが、ステージング環境や本番環境のリソースにはアクセスできません。ステージング環境は本番環境から一部のサービスへのアクセスが必要です。
開発環境をステージングと本番環境から分離するにはどうすればよいのでしょうか?
- A. 開発用とテスト用のプロジェクトと、ステージング用と本番用のプロジェクトを作成します。
- B. 開発用とテスト用のネットワークと、ステージング用と本番用のネットワークを作成します。
- C. 開発用に 1つのサブネットワークを作成し、ステージング用と本番用に別のネットワークを作成します。
- D. 開発用に 1つのプロジェクトを作成し、ステージング用に 2つ目のプロジェクトを作成し、本番用に3つ目のプロジェクトを作成します。
Correct Answer: D
Reference contents:
– Google App Engine Go 1.12+ スタンダード環境のドキュメント
– エンタープライズ企業のベスト プラクティス #プロジェクト構造を指定する | ドキュメント | Google Cloud
– GCP Project のベストプラクティス
– GCP の IAM をおさらいしよう. この記事は Google Cloud Japan Customer… | by Yutty Kawahara | google-cloud-jp
Question 12
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Games は新しいゲームのためにリアルタイム分析プラットフォームを構築を考えています。
新しいプラットフォームは技術的要件を満たす必要があります。
どの組み合わせが要件を満たすことができるでしょうか?
- A. Google Kubernetes Engine、Google Cloud Pub/Sub、Google Cloud SQL
- B. Google Cloud Dataflow、Google Cloud Storage、Google Cloud Pub/Sub、Google BigQuery
- C. Google Cloud SQL、Google Cloud Storage、Google Cloud Pub/Sub、Google Cloud Dataflow
- D. Google Cloud Dataproc、Google Cloud Pub/Sub、Google Cloud SQL、Google Cloud Dataflow
- E. Google Cloud Pub/Sub、Google Compute Engine、Google Cloud Storage、Google Cloud Dataproc
Correct Answer: B
Google 独自の高速プライベート ネットワークを搭載した Google Cloud Pub/Sub を使用して世界中のどこからでも毎秒 数百万件のストリーミング イベントを取り込むことができます。Google Cloud Dataflow を使用してストリームを処理し、信頼性の高い、正確に 1回限りの低レイテンシーのデータ変換を実現します。変換されたデータをクラウドネイティブのデータ ウェアハウス サービスである Google BigQuery にストリームして SQL や一般的な可視化ツールを使って即時に分析することができます。
シナリオから:
ゲームのバックエンドを Google Compute Engine にデプロイしてストリーミング指標を取得し、集中的なアナリティクスを実行できるようにする予定です。
[ゲーム分析プラットフォームの要件]
– ゲームアクティビティに基づいて動的にスケールアップまたはスケールダウン
– ゲームサーバーから直接オンザフライで受信データを処理する
– モバイルネットワークが遅いために到着が遅れたデータを処理する
– SQL クエリが少なくとも 10 TB の履歴データにアクセスできるようにする
– ユーザーのモバイル端末で定期的にアップロードされるファイルの処理
– フル マネージド サービスのみを利用する
Reference contents:
– ストリーム分析ソリューション | Google Cloud
Question 13
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Games は現在の分析と統計レポートモデルから Google Cloud Platform の技術的要件を満たすものに移行したいと考えています。
移行計画に含まれるべきステップはどれでしょうか?(回答を 2つ選択してください)
- A. 現在のバッチ ET Lコードを Google Cloud Dataflow に移行した場合の影響を評価します。
- B. Google BigQuery のパフォーマンスを向上させるためにデータを非正規化するスキーマ移行計画を作成します。
- C.単一のMySQL データベースからMySQL クラスタに移動する方法を示すアーキテクチャ図を計画します。
- D. 以前のゲームの 10 TBの分析データを GoogleCloud SQL インスタンスに読み込み、完全なデータセットに対してテストクエリを実行し、正常に完了したことを確認します。
- E. Google Cloud Armor を統合して Google Cloud Storage にアップロードされた分析ファイルで発生する可能性のあるSQL インジェクション攻撃から防御します。
Correct Answer: A、B
Question 14
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Games のコンピュート ワークロードの技術アーキテクチャを分析し、定義する必要があります。
Mountkirk Games のビジネス要件と技術的要件を考慮してください。
何をすべきでしょうか?
- A. ネットワーク ロードバランサを作成します。プリエンプティブル Google Compute Engine インスタンスを使用します。
- B. ネットワーク ロードバランサを作成します。標準の Google Compute Engine インスタンスを使用します。
- C. マネージド インスタンス グループと自動スケーリング ポリシーを持つグローバル負荷分散を作成します。プリエンプティブル Google Compute Engine インスタンスを使用します。
- D. マネージド インスタンス グループと自動スケーリング ポリシーを持つグローバル負荷分散を作成します。標準の Google Compute Engine インスタンスを使用します。
Correct Answer: D
Question 15
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Games はクラウドとテクノロジーの改善が利用可能になったときに活用できるように将来に向けたソリューションを設計したいと考えています。
どのステップを踏むべきでしょうか?(回答を 2つ選択してください)
- A. 将来のユーザーの行動を予測するための機械学習モデルのトレーニングに使用できるように、現在財政的に可能な限り多くの分析データとゲーム活動データを保存します。
- B. ゲームバック エンド アーティファクトをコンテナイメージにパッケージ化し、Google Kubernetes Engine で実行してゲーム アクティビティに基づいてスケールアップやスケールダウンができるようにします。
- C. Jenkins とSpinnaker を使用してCI/CD パイプラインをセットアップし、カナリア リリースを自動化して開発速度を向上させます。
- D. データベースに追加のプレーヤーデータを保存する必要がある新しいゲーム機能を追加するときのダウンタイムを減らすために、スキーマのバージョン管理ツールを採用します。
- E. Linux 仮想マシンに毎週のローリング メンテナンス プロセスを実装して重要なカーネルパッチとパッケージの更新を適用し、ゼロデイ脆弱性のリスクを軽減できるようにします。
Correct Answer: B、E
シナリオから:
現在のテクノロジー スタックでは必要なスケーラビリティを実現できません。そのため、現在の MySQL から自動スケーリングと低レイテンシの負荷分散が可能な環境へと移行し、物理サーバーの管理作業を不要にしたいと考えています。
Question 16
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Games はモバイル ネットワークの遅延の変化に対する分析プラットフォームの回復力をテストする方法を設計することを望んでいます。
何をすべきでしょうか?
- A. モバイル クライアントの解析トラフィックに追加の遅延を注入できる障害注入ソフトウェアをゲーム解析プラットフォームに導入します。
- B. モバイルのエミュレータから GCP 仮想マシンで実行できるテスト クライアントを構築し、世界中の GCP リージョンで複数のコピーを実行して現実的なトラフィックを生成します。
- C. モバイル デバイスからアップロードされた分析ファイルの処理を開始する前に、ランダムな量の遅延を導入する機能を追加します。
- D. プレイヤーのモバイル デバイスで動作し、世界中の GCP リージョンで実行されている分析エンドポイントからの応答時間を収集する以前のゲームを作成します。
Correct Answer: C
Question 17
この問題については Mountkirk Games のケーススタディ を参照してください。
Mountkirk Gamesのデータベース ワークロードの技術的なアーキテクチャーを分析し、定義する必要があります。
ビジネス要件と技術的要件を考慮して、何をすべきでしょうか?
- A. 時系列データには Google Cloud SQL を使用し、履歴データのクエリには Google Cloud Bigtableを使用します。
- B. Google Cloud SQL をMySQL の代わりに使用し、履歴データのクエリには Google Cloud Spanner を使用します。
- C. Google Cloud Bigtable をMySQL の代わりに使用し、ヒストリカル データ クエリには Google BigQuery を使用します。
- D. 時系列データには Google Cloud Bigtable を使用し、トランザクションデータには Google Cloud Spanner を使用し、履歴データのクエリには Google BigQuery を使用します。
Correct Answer: D
Question 18
この問題については Mountkirk Games のケーススタディ を参照してください。
ゲームアクティビティを時系列データベースサービスに保存します。
Mountkirk Games の技術的要件を満たすマネージド ストレージ オプションはどれでしょうか?
- A. Google Cloud Bigtable
- B. Google Cloud Spanner
- C. Google BigQuery
- D. Google Cloud Datastore
Correct Answer: A
Question 19
この問題については Mountkirk Games のケーススタディ を参照してください。
新しいゲーム バックエンド プラットフォーム アーキテクチャを担当しています。
ゲームは REST API を経由してバックエンドと通信します。Google のベスト プラクティスに従います。
バックエンドをどのように設計すべきでしょうか?
- A. バックエンドのインスタンス テンプレートを作成します。リージョンごとに複数のゾーンのマネージド インスタンス グループにデプロイします。L4 ロードバランサを使用します。
- B. バックエンドのインスタンス テンプレートを作成します。リージョンごとに単一ゾーンのマネージド インスタンス グループにデプロイします。L4 ロードバランサを使用します。
- C. バックエンドのインスタンス テンプレートを作成します。すべてのリージョンに複数のゾーンのマネージ ドインスタンス グループにデプロイします。L7 ロードバランサを使用します。
- D. バックエンドのインスタンス テンプレートを作成します。すべてのリージョンに単一ゾーンのマネージド インスタンス グループにデプロイします。L7 ロードバランサを使用します。
Correct Answer: A
Layer 4 ロードバランサは TCP/UDP 負荷分散です。
Layer 7 ロードバランサは HTTP(S) 負荷分散です
Reference contents:
– ロードバランサの選択 | 負荷分散 | Google Cloud
– Can I use TCP in a RESTful service?
– Load Balancing Layer 4 and Layer 7
Question 20
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth のCTOは接続された車両からの生データを使用して現場の車両がいつクリティカルな故障が起きる時期を特定できるようにしたいと考えています。
アナリストが車両データを一元的にクエリできるようにする必要があります。
どのアーキテクチャをお勧めしますか?
- A.
- B.
- C.
- D.
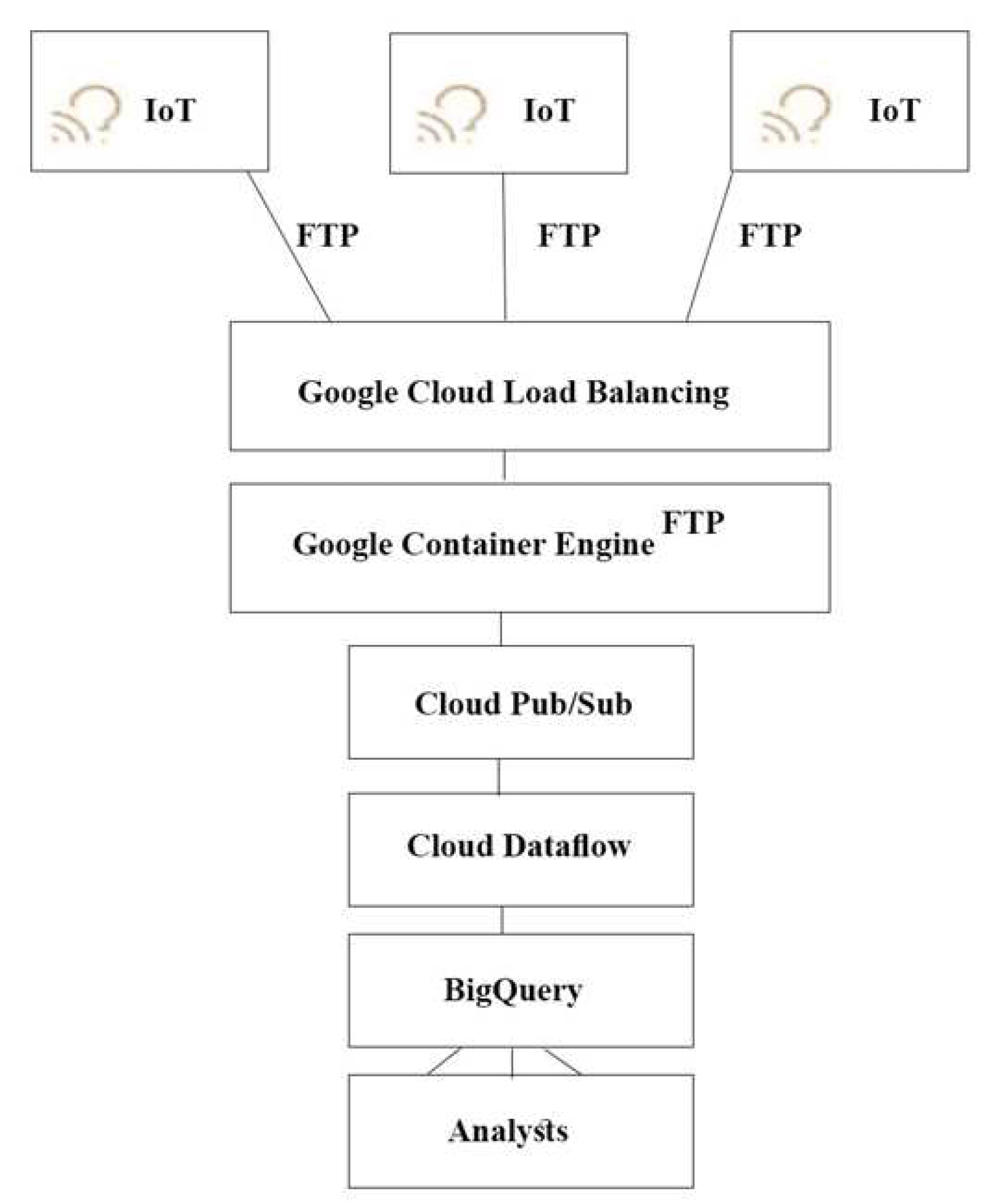
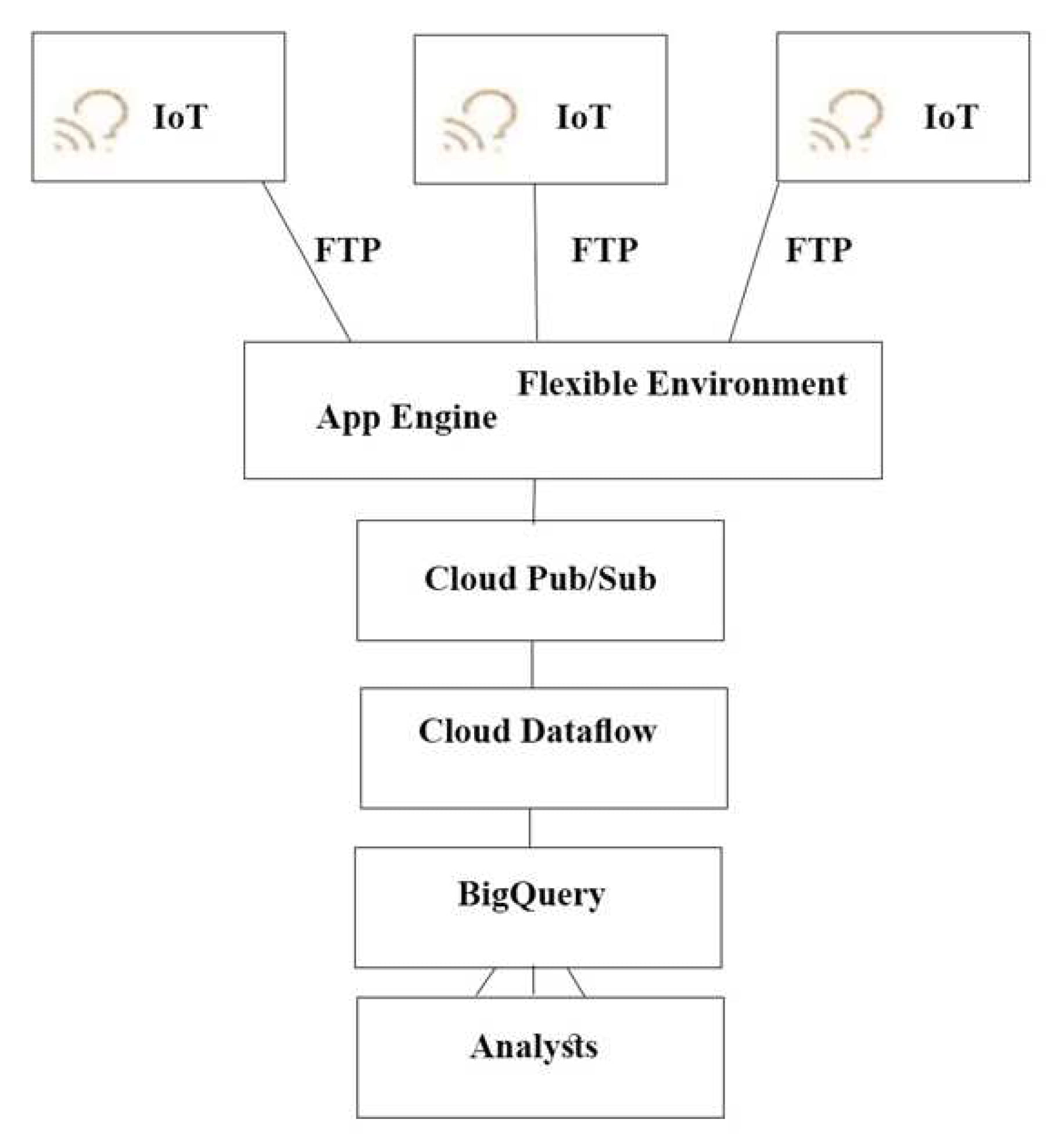
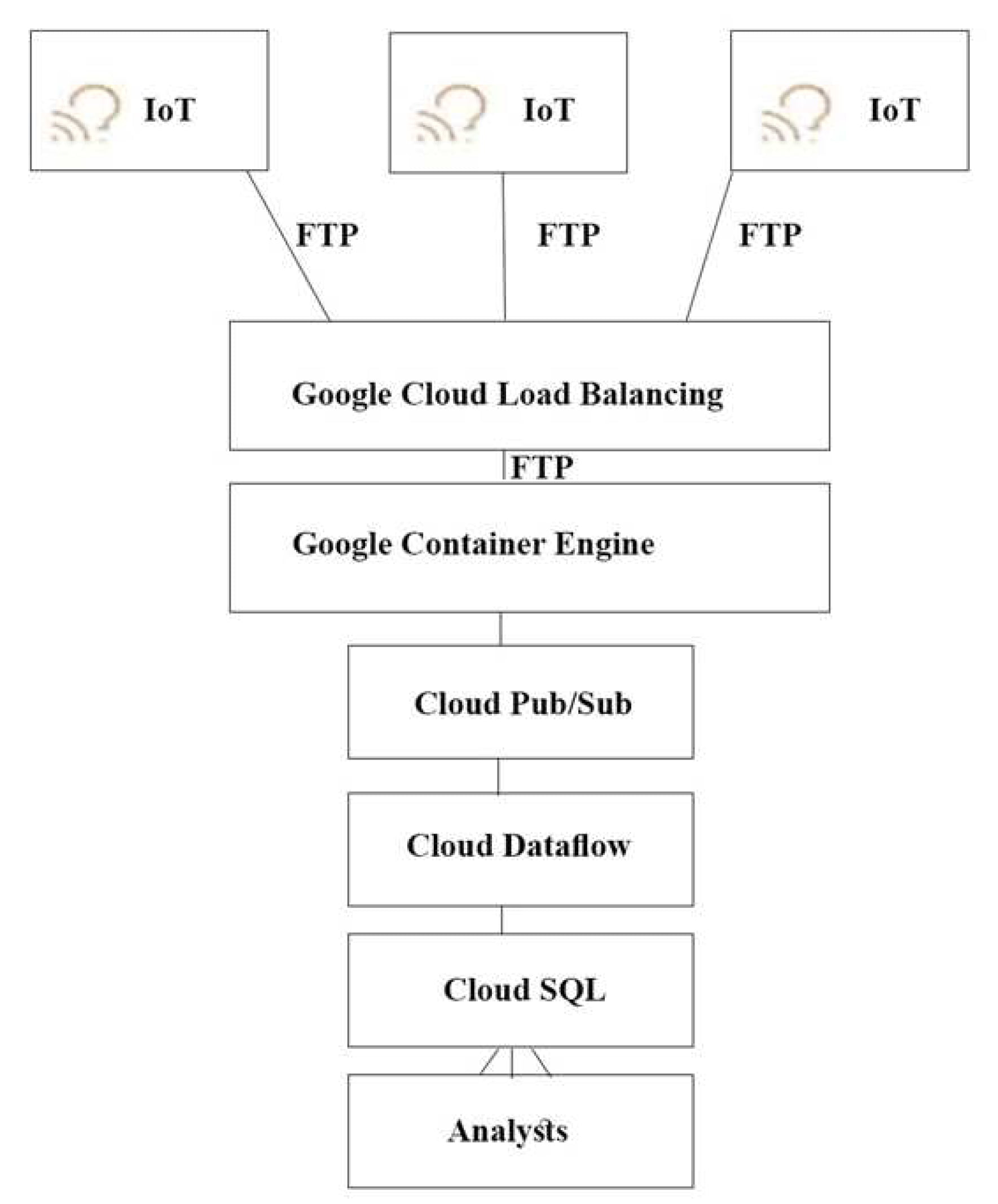
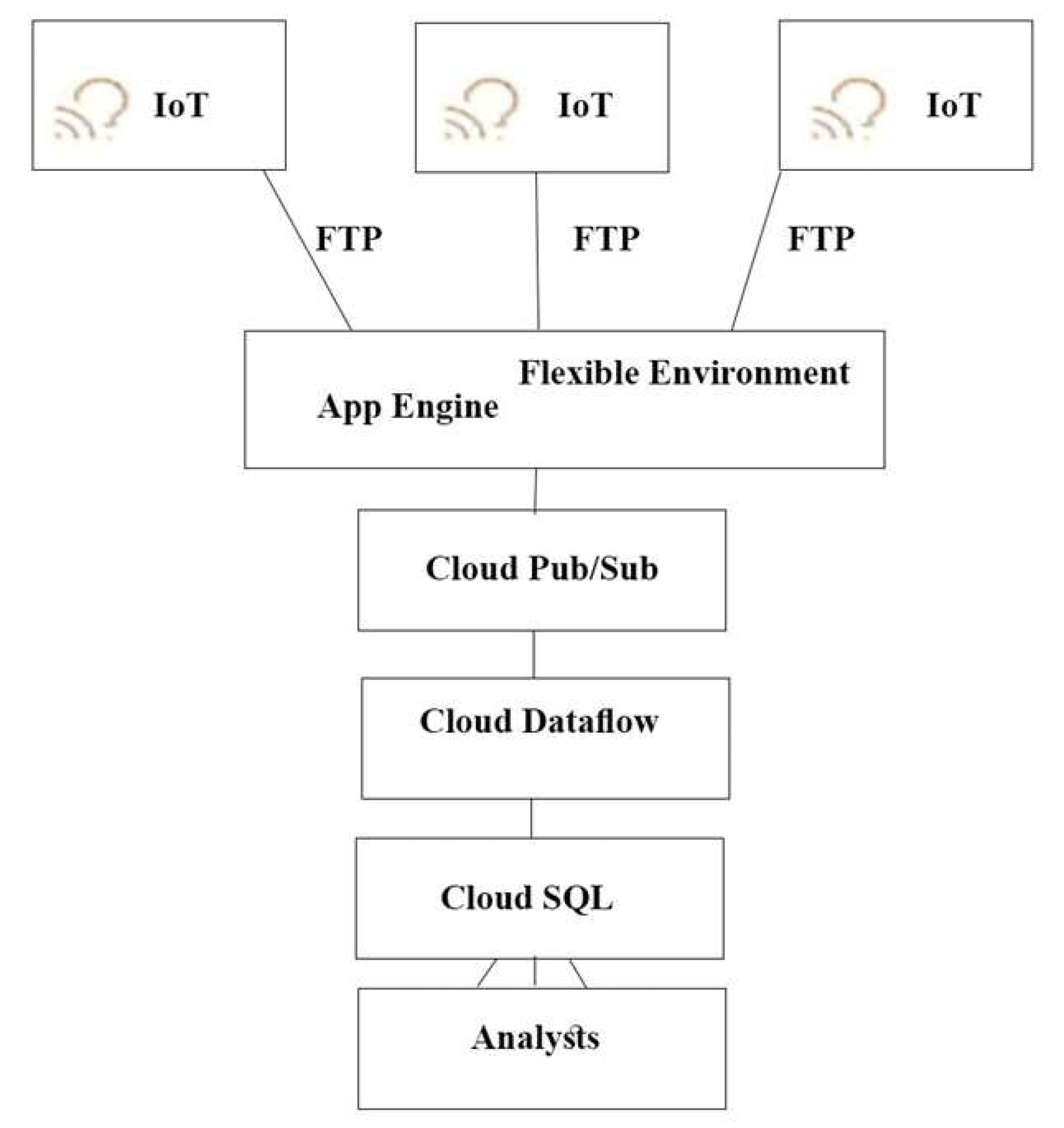
Correct Answer: A
push エンドポイントはロードバランサーになります。
コンテナクラスタを利用することができます。
Google Cloud Pub/Sub for Stream Analytics
Reference contents:
– Cloud Pub/Sub | Google Cloud
– Google Cloud IoT – フルマネージド IoT サービス
– Cloud IoT Core での Connected Vehicle Platform の設計 #データの取り込み | ソリューション
– Google Says Cloud IoT Core Useful for Connected Vehicle Data Analysis
Question 21
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth の開発チームは、会社のビジネス要件を満たすAPI の作成を検討しています。
開発チームはカスタム フレームワークを作成することなく、開発に集中させたいと考えています。
どの方法を使うべきでしょうか?
- A. Google Cloud Endpoints で Google App Engine を利用して販売店やパートナー向けのAPI に注力します。
- B. JAX-RS JerseyJava ベースのフレームワークで Google App Engine を使用します。一般向けのAPI に注力します。
- C. Swagger(Open API Specification)フレームワークで Google App Engine を利用して一般向けのAPI に注力します。
- D. Django(Python)コンテナでGoogle Container Engine を利用して一般向けのAPI に注力します。
- E. Swagger (Open API Specification) フレームワークを使用したTomcat コンテナで Google Container Engine を利用して販売店やパートナー向けのAPI に注力します。
Correct Answer: A
Google Cloud Endpoints を使用して、API の開発、デプロイ、保護、監視を行います。Google Cloud Endpoints はOpen API 仕様または Google API フレームワークのいずれかを使用することで、API 開発のあらゆるフェーズで必要なツールを提供します。
Question 22
この問題については TerramEarth のケーススタディ を参照してください。
開発チームは車両データを取得するための構造化されたAPI を作成しました。
サードパーティがこの車両イベントデータを使用する販売店向けのツールを開発できるようにデータに対する権限委譲をサポートしたいと考えています。
どうすればよいでしょうか?
- A. OAuth 2.0 互換のアクセス制御システムを構築または活用します。
- B. SAML 2.0 による SSO 互換性を認証システムに組み込みます。
- C. パートナーシステムの送信元 IP アドレスに基づいてデータアクセスを制限します。
- D. 信頼できるサードパーティに提供できる各販売店のセカンダリ資格情報を作成します。
Correct Answer: A
[OAuth 2.0 を使用したアプリケーションの権限委譲]
Google Cloud API はOAuth 2.0 をサポートしており、権限はサポートされているメソッドに対するきめ細かな認証を提供します。GCP はサービス アカウント OAuth とユーザー アカウント OAuth の両方をサポートしており、3-legged OAuth とも呼ばれます。
Reference contents:
– Using OAuth 2.0 to Access Google APIs | Google Identity
– エンドユーザーとして認証する | Google Cloud
– 有効期間が短いサービス アカウント認証情報の作成 | Cloud IAM のドキュメント | Google Cloud
Question 23
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth は現場にある 2,000万台の車両をすべてクラウドに接続することを計画しています。
これにより、1時間に 40 TB、1秒間に 2,000万台の 600 バイトのレコードが記録される量が増加します。
データの取り込みはどのように設するべきでしょうか?
- A. 車両は Google Cloud Storage にデータを書き込みます。
- B. 車両は Google Cloud Pub/Sub にデータを書き込みます。
- C. 車両は Google BigQuery にデータをストリーミングします。
- D. 車両は既存のシステム(FTP)を利用してデータを書き込みます。
Correct Answer: C
シナリオでは「アップロードされたデータファイルを単一のサーバーから読み取り、データ ウェアハウスに書き込みます。」となっているので Google Cloud Pub/Sub ではなく、Google BigQuery になる。
ストリームされたデータはテーブルへの最初のストリーミング挿入から数秒以内にリアルタイムで分析できるようになります。
Google BigQuery にデータを読み込むジョブを使用する代わりに tabledata.insertAll メソッドを使用して、一度に 1 レコードずつ BigQuery にデータをストリーミングできます。このアプローチを使用すると、読み込みジョブの実行遅延を発生させることなく、データのクエリを実行できます。
Reference contents:
– BigQuery 特集: データの取り込み
– BigQuery へのデータのストリーミング | Google Cloud
– Google Cloud Platform Japan 公式ブログ: GCP と Maps API によるスケーラブルな位置情報分析プラットフォームの構築
Question 24
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth のダウンタイムを削減するためのビジネス要件を分析したことで、顧客の部品待機時間を短縮することで時間の大幅な節約を実現できることがわかりました。
3週間の集計報告時間の短縮に注力することにしました。
プロセスにどのような変更を加えることをお勧めするべきでしょうか?
- A. CSV からバイナリ形式への移行し、FTP からSFTP への移行して指標の機械学習分析を開発します。
- B. FTP からストリーミングへの移行し、CSV からバイナリ形式への移行して指標の機械学習分析を開発します。
- C. フリートセルラーの接続性を 80 %に高め、FTP からストリーミングに移行して指標の機械学習分析を開発します。
- D. FTP からSFTP への移行し、メトリックの機械学習分析を開発して、ディーラーのローカル在庫を一定の割合で増加させます。
Correct Answer: B
セルラー接続とはモバイルデータ通信(3G)を利用して接続できるモデルです。
Fleet cellular(フリートセルラー)とは世界最大のセルラーネットワークを所持する企業です。
Avro バイナリ形式は、圧縮されたデータを読み込むのに適した形式です。Avro データはデータ ブロックが圧縮されている場合でもデータを並行して読み込むことができるため、読み込みが高速になります。
Google Cloud Storage はHTTP チャンク転送エンコードに基づいた gsutil ツールまたは Boto ライブラリを使用したストリーミング転送をサポートしています。ストリーミング データを使用すると、データを最初に別のファイルに保存しなくてもデータが利用可能になったらすぐに Google Cloud Storage アカウントとの間でデータをストリーミングすることができます。ストリーミング転送はデータを生成するプロセスがあり、アップロードする前にデータをローカルにバッファリングしたくない場合や計算パイプラインの結果を直接 Google Cloud Storage に送信したい場合に便利です。
Reference contents:
– ストリーミング転送 | Cloud Storage | Google Cloud
– データの読み込みの概要 #データ取り込み方法の選択 | BigQuery | Google Cloud
Question 25
この問題については TerramEarth のケーススタディ を参照してください。
Google Cloud Platform を採用することで TerramEarth の従来のエンタープライズ プロセスの中で大きな変化が起こるのはどれでしょうか?
- A. 運用コスト/設備投資、LANの変更、キャパシティ プランニング
- B. キャパシティ プランニング、TCO、運用コスト/設備投資
- C. キャパシティ プランニング、利用率測定、データセンター拡張
- D. データセンター拡張、TCO、利用率測定
Correct Answer: B
TCO とは Total cost of ownership の略で 総所有コスト を意味する。
Reference contents:
– データセンター プロフェッショナルのための Google Cloud: コンピューティング #キャパシティ プランニングとリソースのプロビジョニング
Question 26
この問題については TerramEarth のケーススタディ を参照してください。
データ検索を高速化するために、より多くの車両がセルラー接続にアップグレードされ、ETLプロセスにデータを送信できるようになります。
現在のFTP 転送プロセスはエラーが発生しやすく、接続に失敗するとファイルの最初からデータ転送を再起動してしまうことが頻繁に起きていますします。ソリューションの信頼性を向上させ、セルラー接続でのデータ転送時間を最小限に抑えたいと考えています。
どうすればよいでしょうか?
- A. FTP サーバーの Google Container Engine クラスタを使用します。Google Cloud Multi-Regional Storage バケットにデータを保存します。バケット内のデータを使用してETL プロセスを実行します。
- B. 異なるリージョンにあるFTP サーバーを実行している複数の Google Container Engine クラスタを使用します。米国、欧州、アジアの Google Cloud Multi-Regional Storage バケットにデータを保存します。バケット内のデータを使用してETL プロセスを実行します。
- C. HTTP(S) を経由した Google Cloud API を使用し、米国、EU、アジアの異なる Google Cloud Multi-Regional Storage バケットの場所にファイルを直接転送します。バケット内のデータを使用してETL プロセスを実行します。
- D. HTTP(S) を経由した Google Cloud API を使用し、米国、EU、アジアの別の Google Cloud Regional Storage バケット ロケーションにファイルを直接転送します。ETL プロセスを実行して、各リージョナル バケットからデータを取得します。
Correct Answer: C
セルラー接続とはモバイルデータ通信(3G)を利用して接続できるモデルです。
Question 27
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth は世界中に車両 2,000万台を配備しています。
車両の場所に基づいて、その遠隔測定データはGoogle Cloud Storage(GCS)の地域バケット(米国、欧州、アジア)に保存されています。
CTOは生の遠隔測定データを使ってレポートを実行して 100 km 後に車両が故障する理由を特定するように依頼してきました。このジョブをすべてのデータに対して実行したいと考えています。
このジョブを実行する最も費用対効果の高い方法は何でしょうか?
- A. すべてのデータを 1つのゾーンに移動して Google Cloud Dataproc クラスタを起動してジョブを実行します。
- B. すべてのデータを 1つのリージョンに移動して Google Cloud Dataproc クラスタを起動してジョブを実行します
- C. 各リージョンでクラスタを起動して生データを前処理して圧縮し、マルチリージョン バケットに移動して Google Cloud Dataproc クラスタを使用してジョブを終了します。
- D. 各リージョンでクラスタを起動して生データを前処理して圧縮し、データをリージョン バケットに移動して Google Cloud Dataproc クラスタを使用してジョブを完了します。
Correct Answer: C
ストレージは地理的に多様な(100 マイル離れている)2つのレプリケートを保証し、より良いリモート レイテンシと可用性を得ることができます。
さらに重要なのはマルチリージョンがエンドユーザーにコンテンツを提供するためにエッジキャッシングとCDNを大きく活用していることです。
このような冗長性とキャッシングはすべてマルチリージョンには、地理的に多様なエリア間の同期と一貫性を確保するためのオーバーヘッドが発生することを意味します。このように、マルチリージョンは書き込み、一度に何度も読むというシナリオにははるかに適しています。これは、ウェブサイトのコンテンツの配信、動画のストリーミング、インタラクティブなワークロードの実行、モバイル アプリケーションやゲーム アプリケーションなど、世界中で頻繁にアクセスされる(「ホットな」オブジェクトなど)ことを意味します。
Reference contents:
– バケットのロケーション | Cloud Storage | Google Cloud
– 主な用語 #地域的な冗長性 | Cloud Storage | Google Cloud
– Google Cloud Storage : What bucket class for the best performance?
Question 28
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth は遠隔測定データを収集のためにサーバーとセンサーに接続されているトラックを所有しています。
来年にはそれらのデータを使って機械学習モデルをトレーニングしたいと考えています。また、コスト削減のためにデータをクラウドに保存を検討しています。
どうすればいいのでしょうか?
- A. 車両のコンピュータにデータを1時間ごとのスナップショットに圧縮させ、Google Cloud Storage Nearline バケットに保存します。
- B. 遠隔測定データをリアルタイムでデータを圧縮するストリーミング Dataflow ジョブにプッシュし、Google BigQuery に保存します。
- C. 遠隔測定データをリアルタイムでデータを圧縮するストリーミング Dataflow ジョブにプッシュし、Google Cloud Bigtable に保存します。
- D. 車両のコンピュータに1時間ごとのスナップショットでデータを圧縮させ、Google Cloud Storage Coldline バケットに保存します。
Correct Answer: D
Google Cloud Storage は可用性が低めで、ストレージの最小保存期間が 90 日間、データアクセスの費用が1回あたりの運用コストが高いことなどから、せいぜい年に 1 回程度しか読み取りや変更を行わないデータに適しています。
例えば、以下のような場合です。
コールドデータ ストレージ – 法的または規制上の理由で保存されているデータなど、アーカイブされたデータを Google Cloud Archive Storage として低コストで保存でき、必要な場合は使用できます。
災害復旧 – 災害復旧時では復旧にかかる時間が重要です。Google Cloud Cloud Storage では Google Cloud Archive Storage として保存されているデータに低レイテンシでアクセスできます。
Reference contents:
– Storage classes #Coldline Storage | Google Cloud
Question 29
この問題については TerramEarth のケーススタディ を参照してください。
農業部門では完全自律走行車の実験を行っています。
アーキテクチャでは、車両の運転中に強堅なセキュリティを促進したいと考えています。
どのアーキテクチャを検討すべきでしょうか?(回答を 2つ選択してください)
- A. 車両のモジュール間のすべてのマイクロサービス 呼び出しを信頼できないものとします。
- B. 安全なアドレス空間を保障するために接続性のための IPv6 を採用します。
- C. 信頼された仮想トラステッド プラットフォーム モジュール(vTPM)を使用し、起動のファームウェアおよびバイナリを確認します。
- D. 関数型プログラミング言語を使用して、コード実行サイクルを分離します。
- E. 冗長性のために複数の接続サブシステムを使用します。
- F. 車両の駆動電子機器をファラデーケージで囲み、チップを分離します。
Correct Answer: A、C
Question 30
この問題については TerramEarth のケーススタディ を参照してください。
油圧などの運転パラメーターは TerramEarth の各車両で調整可能で、環境条件に応じて効率を高めることができます。
第一の目標は現場にある 2,000万台のセルラー車とよび接続されていない車両すべての運用効率を向上させることです。
この目標を達成するにはどうすればよいのでしょうか?
- A. エンジニアにデータのパターンを検査してもらい、運用上の調整を自動的に行うルールを持ったアルゴリズムを作成します。
- B. すべての運転データを取得して理想的な運転を特定する機械学習モデルをトレーニングし、ローカルで運転調整を自動的に行います。
- C. Google Cloud Dataflow ストリーミングジョブをスライディング ウィンドウで実装し、Google Cloud Messaging を使用して自動的に運転調整を行います。
- D. すべての運用データを取得して理想的な運転を特定する機械学習モデルをトレーニングし、Google Cloud Machine Learning(ML)でホストして運用調整を自動的に行う。
Correct Answer: D
Reference contents:
– Google Cloud Blog:ゲスト投稿 : Ocado Technology の GCP Census で BigQuery の利用状況を分析
Question 31
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth は欧州のGDPR 規制に準拠するため、欧州の顧客から生成されたデータに個人データが含まれている場合は 36 ヶ月後に削除する必要があります。
新しいアーキテクチャではこのデータは Google Cloud Storage と Google BigQuery の両方に保存されています。
どうすればいいのでしょうか?
- A. 欧州データ用の Google BigQuery テーブルを作成してテーブルの保持期間を 36ヶ月に設定します。Google Cloud Storage の場合は gsutil を使用して age 条件を 36 ヶ月としたDelete アクションを使用してライフサイクル管理を有効にします。
- B. 欧州データ用の Google BigQuery テーブルを作成し、テーブルの保持期間を 36 ヶ月に設定します。Google Cloud Storage の場合は gsutil を使用して age 条件を 36 ヶ月とした SetStorageClass を Non にするアクションを作成します。
- C. 欧州データ用の Google BigQuery の時間パーティション分割テーブルを作成してパーティションの有効期間を36ヶ月に設定します。Google Cloud Storage の場合は gsutil を使用して age 条件を 36 ヶ月としたDelete アクションを使用してライフサイクル管理を有効にします。
- D. 欧州データ用の Google BigQuery の時間パーティション分割テーブルを作成してパーティションの有効期間を36ヶ月に設定します。Google Cloud Storage の場合は gsutil を使用して age 条件を 36 ヶ月とした SetStorageClass を Non にするアクションを作成します。
Correct Answer: A
Reference contents
– テーブルの管理 #テーブルの有効期限を更新する | BigQuery | Google Cloud
– オブジェクトのライフサイクル管理 | Cloud Storage | Google Cloud
– BigQueryのテーブルを一定期間経過後削除する defaultTableExpirationMs – kikumotoのメモ帳
Question 32
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth はデータ ファイルを Google Cloud Storage に保存することにしました。
1 年分のデータを保存し、ファイルの保存コストを最小限に抑えるために Google Cloud Storage のライフサイクル管理を設定する必要があります。
どのアクションを行うべきでしょうか?
- A. 次の Google Cloud Storage ライフサイクル管理を作成します。
- 1. Age: 30、Storage Class: Standard、Action: Set to Coldline
- 2. Age: 365、Storage Class: Coldline、Action: Delete
- B. 次の Google Cloud Storage ライフサイクル管理を作成します。
- 1. Age: 30、Storage Class: Coldline、Action: Set to Nearline
- 2. Age: 91、Storage Class: Coldline、Action: Set to Nearline
- C. 次の Google Cloud Storage ライフサイクル管理を作成します。
- 1. Age: 90、Storage Class: Standard、Action: Set to Nearline
- 2. Age: 91、Storage Class: Nearline、Action: Set to Coldline
- D. 次の Google Cloud Storage ライフサイクル管理を作成します。
- 1. Age: 30、Storage Class: Standard、Action: Set to Coldline
- 2. Age: 365、Storage Class: Nearline、Action: Delete
Correct Answer: A
Reference contents:
– オブジェクトのライフサイクルの管理 | Cloud Storage | Google Cloud
– GCSライフサイクル機能を使ってファイルを定期削除する
Question 33
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth のデータ ウェアハウスに信頼性が高くスケーラブルなGCP ソリューションを実装する必要があります。
TerramEarth のビジネス要件と技術的要件を考慮してください。
何をすべきでしょうか?
- A. 既存のデータ ウェアハウスを Google BigQuery に置き換え、パーティション分割テーブルを使用します。
- B. 既存のデータ ウェアハウスを96 CPUの Google Compute Engine インスタンスに置き換えます。
- C. 既存のデータ ウェアハウスを Google BigQuery に置き換え、外部データソース(フェデレーション データソース)を使用します。
- D. 既存のデータ ウェアハウスを 96CPUの Google Compute Engine インスタンスに置き換え、32 CPUの Google Compute Engine プリエンプティブル インスタンスを使用します。
Correct Answer: A
Question 34
この問題については TerramEarth のケーススタディ を参照してください。
すべての受信データを Google BigQuery に書き込むアーキテクチャが新しく導入されました。
データに不整合があることに気づきました。コストを管理しながら日々自動でデータ品質を確保したいと考えています。
何をするべきでしょうか?
- A. 取り込みプロセスでデータを受信するストリーミング型の Google Cloud Dataflow ジョブを設定します。Google Cloud Dataflow パイプラインでデータをクリーンアップする。
- B. Google BigQuery からデータを読み取ってクリーンアップする Google Cloud Function を作成してトリガーします。Google Compute Engine インスタンスから Google Cloud Functionをトリガーします。
- C. Google BigQuery のデータに SQL 文を作成してビューとして保存します。ビューを毎日実行し、結果を新しいテーブルに保存します。
- D. Google Cloud Dataprep を使用してソースとして Google BigQuery テーブルを構成します。データをクリーンアップするために毎日のジョブをスケジュールします。
Correct Answer: A
Google Cloud Dataprep は内部で Google Cloud Storage や Google BigQuery との間で読み取り/書き込みを行い、Google Cloud Dataflow ジョブとして実行されます。
Google BigQuery にある受信データを Google Cloud Dataflow での抽出(取り込み)して加工(バッジ処理)を施し、 Google BigQuery に流し込む形が良い。
Reference contents:
– Cleaning data in a data processing pipeline
– GCP入門[第7回]ビッグデータその3 Cloud Dataflow / Cloud Dataprep
– BigQuery と Cloud DataFlow でデータ分析基盤を作る練習(データ加工編)
– Dataflow と BigQuery を使用した Google Cloud での ETL 処理 | Qwiklabs
Question 35
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth の技術的要件を考慮すると、GCP で計画外の車両のダウンタイムをどのように削減するべきでしょうか?
- A. データ ウェアハウスとして Google BigQuery を使用します。すべての車両をネットワークに接続し、Google Cloud Pub/Sub と Google Cloud Dataflow を使用して Google BigQuery にデータをストリームします。分析とレポート作成に Google Data Studio を使用する。
- B. データ ウェアハウスとして Google BigQuery を使用します。すべての車両をネットワークに接続し、gcloud を使用して Google Cloud Multi-Regional Storage バケットに gzip ファイルをアップロードします。分析とレポート作成に Google Data Studio を使用します。
- C. データ ウェアハウスとして Google Cloud Dataproc でのHiveApache Hive を使用します。Google Cloud Multi-Regional Storage バケットに gzip ファイルをアップロードします。このデータを gcloud を使用して Google BigQuery にアップロードします。分析とレポート作成に Google Data Studio を使用します。
- D. データ ウェアハウスとして Google Cloud Dataproc でのHiveApache Hive を使用します。データを直接 Hive の分割テーブルにストリームします。Pig スクリプトを使ってデータを分析します。
Correct Answer: A
Question 36
この問題については TerramEarth のケーススタディ を参照してください。
TerramEarth はセルラーネットワークに接続されている 20 万台の車両のデータを取り込むための新しいアーキテクチャの設計を検討しています。
Googleが推奨するプラクティスに従いたいと考えています。
技術的要件を考慮して、どのコンポーネントをデータの取り込みに使用しますか?
- A. SSL にIngress を備えた Google Kubernetes Engine
- B. 公開鍵/秘密鍵 のペアを持つ Google Cloud IoT Core
- C. プロジェクト全体のSSH 鍵を備えた Google Compute Engine
- D. 特定のSSH 鍵を備えた Google Compute Engine
Correct Answer: B
Question 37
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win のセキュリティチームはGoogle Cloud Platform(GCP)上の本番用仮想マシン(VM)への外部SSHアクセスを無効にしています。
運用チームはVMのリモート管理、Docker コンテナの構築とプッシュ、Google Cloud Storage オブジェクトを管理する必要があります。
何ができるのでしょうか?
- A. 運用エンジニアに Google Cloud Shell を使用するためのアクセス権を付与します。
- B. GCP へのVPN 接続を設定してVM へのSSH アクセスを許可します。
- C. 運用エンジニアがタスクを実行する必要があるときにVM への一時的なSSH アクセスを許可する新しいアクセス要求プロセスを開発します。
- D. 運用チームがタスクを達成するために特定のリモート プロシージャ コールを実行できるようにするAPIサービスを開発チームに構築させる。
Correct Answer: A
Question 38
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win の運用エンジニアはデータベースのバックアップ ファイルのコピーをリモートでアーカイブするための低コストのソリューションを作成したいと考えています。
データベース ファイルは圧縮tar ファイルで現在のデータセンターに保存されています。
どのように進めるべきでしょうか?
- A. gsutil を使用して cron スクリプトを作成してファイルを Google Cloud Coldline Storage バケットにコピーします。
- B. gsutil を使用して cron スクリプトを作成してファイルを Google Cloud Regional Storage バケットにコピーします。
- C. Google Cloud Storage Transfer Service ジョブを作成してファイルを Google Cloud Coldline Storage バケットにコピーします。
- D. Google Cloud Storage Transfer Service ジョブを作成してファイルを Google Cloud Regional Storage バケットにコピーします。
Correct Answer: A
gsutil または Google Cloud Storage Transfer Service を使用するかどうかを決定する際には、この経験則に従ってください。
– オンプレミスの場所からデータを転送する場合は gsutil を使用します。
– 別の Google Cloud Storage プロバイダからデータを転送する場合は、Storage Transfer Service を使用してください。
Reference contents:
– 概要 #gsutil と Storage Transfer Service のどちらを使用するか | Cloud Storage Transfer Service | Google Cloud
– Google Cloud への移行: 大規模なデータセットの転送 #Google が提供するオプション | ソリューション
Question 39
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win はアプリケーション サーバーをデプロイすべきマシンの種類を推奨するように依頼しています。
どのように進めるべきでしょうか?
- A. オンプレミスの物理ハードウェアコアとRAM が最も近い仮想マシンタイプを使用します。
- B. 利用可能な最高のRAM とCPU のマシンタイプにアプリケーション サーバをデプロイします。
- C. 利用可能な最小のインスタンスで本番環境にデプロイし、時間をかけて監視して希望のパフォーマンスに達するまでマシンタイプをスケールアップします。
- D. アプリケーション サーバーの仮想マシンに関連する仮想コア数とRAM を特定し、それらをカスタム マシンタイプに合わせ、パフォーマンスを監視し、希望するパフォーマンスに達するまでマシンタイプをスケールアップします。
Correct Answer: A
Question 40
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win のクラウド移行計画の一環として、トラフィック負荷の急増に対応できるようにマネージド ロギングおよびモニタリングシステムをセットアップできるようにしたいと考えています。
要件は次になります。
– 使用量の増減に対応するためにインフラストラクチャのスケールアップやスケールダウンが必要になったときに通知を受けること。
– アプリケーションにエラーが発生すると管理者に自動的に通知されること。
– 集約されたログをフィルタリングして、多くのホスト間でアプリケーションの一部をデバッグできること
どの Google StackDriver を使うべきでしょうか?
- A. Logging、Alerts、Insights、Debug
- B. Monitoring、Trace、Debug、Logging
- C. Monitoring、Logging、Alerts、Error Reporting
- D. Monitoring、Logging、Debug、Error Report
Correct Answer: B
Google StackDriver Alerts はありません。アラートは各 StackDriver に備わっている機能の 1つです。
Question 41
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win は一部のアプリケーションをそのままの状態で素早くデプロイすることに成功して、クラウドへのアプリケーションのデプロイに慣れさせたいと考えています。
どの手段がよいでしょうか?
- A. クラウドへの最初の移行として、外部依存関係を持つ自己完結型のアプリケーションを特定します。
- B. 内部依存関係のあるエンタープライズのアプリケーションを特定してクラウドへの最初の移行先として推奨します。
- C. 社内データベースをクラウドに移行し、オンプレミスのアプリケーションへのリクエストの処理を継続することを提案します。
- D. メッセージ キューイング サーバーをクラウドに移行してオンプレミスのアプリケーションへのリクエストの処理を継続することを提案します。
Correct Answer: A
Reference contents:
– Google Cloud への移行: スタートガイド | ソリューション
– Google Cloud 移行を簡単に
– GCP への移行を成功に導く 5 つのフェーズ
Question 42
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win はオンプレミスのMySQL デプロイメントをクラウドに移行する方法について検討しています。
移行中のオンプレミス ソリューションへのダウンタイムとパフォーマンスへの影響を最小限に抑えたいと考えています。
どのアプローチをお勧めしますか?
- A. オンプレミスのMySQL マスター サーバーのダンプを作成し、シャットダウンしてクラウド環境にアップロードし、新しいMySQL クラスタに読み込みます。
- B. クラウド環境にMySQL レプリカサーバー/スレーブを設定し、カットオーバーまでオンプレミスのMySQL マスター サーバから非同期レプリケーションを行うように設定します。
- C. クラウドに新しいMySQL クラスタを作成し、アプリケーションがオンプレミスとクラウドの両方のMySQL マスターに書き込みを開始するように設定し、カットオーバー時に元のクラスタを破棄します。
- D. クラウド環境にMySQL レプリカサーバのダンプを作成し、Google Cloud Datastore に読み込み、カットオーバー時に Google Cloud Datastore に読み書きするようにアプリケーションを構成します。
Correct Answer: B
Question 43
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win はいくつかのレガシーサービスについて Google Stackdriver で新しい稼働時間チェックを構成しました。
Stackdriver ダッシュボードはサービスが正常であると報告していません。
何をすべきでしょうか?
- A. レガシー Web サーバーのすべてに Stackdriver エージェントをインストールします。
- B. Google Cloud Console で稼働時間サーバーの IP アドレスのリストをダウンロードし、内向き ファイアウォール ルールを作成します。
- C. GoogleStackdriverMonitoring-UptimeChecks(https://cloud.google.com/monitoring) 値が一致した場合、User-Agent HTTP ヘッダーを通過するようにロードバランサーを設定します。
- D. GoogleStackdriverMonitoring-UptimeChecks(https://cloud.google.com/monitoring) 値が一致した場合、User-Agent HTTP ヘッダーを含むリクエストを許可するようにレガシーウェブサーバを設定します。
Correct Answer: B
Reference contents:
– 稼働時間チェックの管理 | Cloud Monitoring | Google Cloud
Question 44
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Wm では新しいアプリケーション のUXの一部としてユーザーは自分の画像をアップロードすることができます。
この画像は誰にでも閲覧できます。ユーザーは最小限の待ち時間で画像をアップロードすることができ、ログイン時にメイン アプリケーションのページに画像をすばやく表示できる必要があります。
どの構成を使用する必要がありますか?
- A. 画像ファイルを Google Cloud Storage バケットに保存します。Google Cloud Datastore を使用して各ユーザー ID と画像ファイルを使用するメタデータを管理します。
- B. 画像ファイルを Google Cloud Storage バケットに保存します。Google Cloud Storage でアップロードされた画像に固有 ユーザー IDを含むカスタム メタデータを追加します。
- C. 分散ファイルシステムを使用してユーザーの画像を保存します。ストレージのニーズが増加した場合は永続ディスクやノードを追加します。各ユーザーに固有 ID を割り当て、各ファイルの所有者属性を設定して画像のプライバシーを確保します。
- D. 分散ファイルシステムを使用して顧客の画像を保存します。ストレージのニーズが増加した場合は永続ディスクやノードを追加します。Google Cloud SQL データベースを使用して各ユーザー ID と画像ファイルを使用するメタデータを管理します。
Correct Answer: A
Question 45
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win にはエンドポイントの100%をカバーするエンドツーエンドのテストを行っています。
クラウドへの移行によって新しいバグが発生しないようにしたいと考えています。
バグを防ぐためにどのテスト方法を新しく採用するべきでしょうか?
- A. アプリケーション コードで Google Stackdriver Debugger を有効にしてコードにエラーを表示させます。
- B. クラウドのステージング環境に単体テストと本番規模の負荷テストを実施します。
- C. クラウドのステージング環境でエンドツーエンドのテストを実施し、コードが意図したとおりに機能しているかどうかを判断します。
- D. 開発者が新しいリリースがレイテンシーにどの程度の影響を与えるかを測定できるように、カナリアテスト実施します。
Correct Answer: B
Question 46
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win の売上と税務の記録が少なくとも10年間、監査人が頻繁に閲覧できないようにしておきたいと考えています。
コストの最適化が最優先事項です。
どのクラウドサービスを選ぶべきですか?
- A. Google Cloud Coldline Storage でデータを保存し、データにアクセスするには gsutil を使用します。
- B. Google Cloud Nearline Storage でデータを保存し、データにアクセスするには gsutil を使用します。
- C. Google Bigtable でアメリカやヨーロッパを指定してデータを保存し、データにアクセスするには gcloud を使用します。
- D. Google BigQuery でデータを保存し、データにアクセスするにはマネージド インスタンス グループのWebサーバー クラスタを使用します。2つの異なるリージョンにまたがる Google Cloud SQL をミラーリングしてデータを保存し、マネージド インスタンス グループのRedis クラスタでデータにアクセスします。
Correct Answer: A
Question 47
この問題については Dress4Win のケーススタディ を参照してください。
現在、Dress4win のシステムアーキテクチャーは 1つのデータセンターに配置されているため、1部のお客様にとっては待ち時間が長くなります。
将来的にクラウドでの評価とパフォーマンスの最適化を行うため、Dress4win はGCP を利用する際に、システムアーキテクチャーを複数の場所に分散させたいと考えています。
どのアプローチを使うべきなのでしょうか?
- A. リージョナル マネージド インスタンス グループとグローバル負荷分散を使用すると、リージョン マネージド インスタンス グループはトラフィックに応じて各リージョンのインスタンスを個別に成長させることができるため、パフォーマンスを向上させることができます。
- B. グローバル負荷分散を使用して運用チームが管理するより近い仮想マシンのグループにリクエストを転送する仮想マシンのセットを使用します。
- C. リージョン マネージド インスタンス グループとグローバル負荷分散を使用して、異リージョンのゾーン間で自動フェイルオーバーを提供することで信頼性を高める。
- D. グローバル負荷分散を使用して別のマネージド インスタンス グループの一部として、より近い仮想マシンのグループにリクエストを転送する仮想マシンのセットを使用します。
Correct Answer: D
Question 48
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win は既存の使用パターンを反映したデータやトラフィックの増加に対応して、1年後には 10 倍の規模に成長すると予想されています。
CIOは今後 6 ヶ月以内に本番環境のインフラストラクチャーをクラウドに移行するという目標を設定しました。
アプリケーションに大きな変更を加えることなく、この成長に合わせて拡張し、ROI を最大化するためにどのようにソリューションを構成するべきでしょうか?
- A. Web アプリケーション層を Google App Engine に、MySQL を Google Cloud Datastore に、NAS を Google Cloud Storage に移行します。RabbitMQ をデプロイし、Google Cloud Deployment Manager を使用してHadoop サーバーをデプロイする。
- B. RabbitMQ を Google Cloud Pub/Sub に、HadoopをGoogle BigQueryに、NASをGoogle Compute Engine に、Persistent Diskストレージを使用して移行する。Tomcat をデプロイし、Google Cloud Deployment Manager を使ってNginx をデプロイします。
- C. Tomcat とNginx にマネージド インスタンス グループを実装します。MySQ Lを Google Cloud SQL に、RabbitMQ を Google Cloud Pub/Sub に、Hadoop を Google Cloud Dataproc に、NAS を永続ディスクのストレージの Google Compute Engine に移行する。
- D. Tomcat とNginx にマネージド インスタンス グループを実装します。MySQL を Google Cloud SQL に、RabbitMQ を Google Cloud Pub/Sub に、Hadoop を Google Cloud Dataproc に、NAS を Google Cloud Storage に移行します。
Correct Answer: D
Question 49
この問題については Dress4Win のケーススタディ を参照してください。
ビジネス要件を考慮して Webおよびトランザクションデータ レイヤーの展開をどのように自動化しますか?
- A. Google Cloud Deployment Manager を使用して Google Compute Engine にNginx とTomcat をデプロイします。MySQL に代わる Google Cloud SQL サーバーをデプロイします。Google Cloud Deployment Manager を使用してJenkins をデプロイします。
- B. Cloud Launcher を使用してNginx とTomcat をデプロイします。Cloud Launcher を使用してMySQL サーバーをデプロイします。Google Cloud Deployment Manager スクリプトを使用して、Google Compute Engine にJenkins をデプロイします。
- C. Nginx とTomcat を Google App Engine に移行します。高可用性構成でMySQL サーバーを置き換えるために Google Cloud Datastore サーバーをデプロイします。Cloud Launcher を使用してJenkins を Google Compute Engine にデプロイします。
- D. Nginx と Tomcat を Google App Engine に移行します。Cloud Launcher を使用してMySQL サーバーをデプロイします。Cloud Launcher を使用してJenkins を Google Compute Engine にデプロイします。
Correct Answer: A
Question 50
この問題については Dress4Win のケーススタディ を参照してください。
コンピューティング サービスをそのまま移行しても、クラウドでのパフォーマンスを最適化するアーキテクチャーはどれですか?
- A. Google App Engine スタンダード環境を利用してデプロイされた Web アプリケーション
- B. 非マネージド インスタンス グループを利用してデプロイされた RabbitMQ
- C. 高可用性モードで Google Cloud Dataproc Regional を使用してデプロイされた Hadoop/Spark
- D. Jenkins、監視、要塞ホスト、カスタム マシンタイプにデプロイされた セキュリティスキャナー サービス
Correct Answer: A
Question 51
この問題については Dress4Win のケーススタディ を参照してください。
Dress4Win では監査時に法的に準拠するために Google Cloud リソースの構成またはメタデータの変更に関するすべての管理アクションがインサイトできる状態にしなければなりません。
何をすべきでしょうか?
- A. Stackdriver Trace を使用してトレース 分析リストを作成します。
- B. Stackdriver Monitoring を使用してプロジェクトのアクティビティのダッシュボードを作成します。
- C. すべてのプロジェクトで Google Cloud Identity-Aware Proxy を有効にして管理者のグループをメンバーとして追加します。
- D. Google Cloud Console の [アクティビティ]ページとStackdriverLogging を使用して必要なインサイトを提供します。
Correct Answer: A
Question 52
この問題については Dress4Win のケーススタディ を参照してください。
会社はDress4Win の Google Cloud Storage に保存されたデータのセキュリティを担当しています。
すでにGoogle グループを作成し、その Google グループに適切なユーザーを割り当てています。Google のベスト プラクティスに従って要件を満たすために最もシンプルな設計を実装する必要があります。Dress4Win のビジネス要件と技術的要件を考慮してください。
何をすべきでしょうか?
- A. セキュリティ要件を適用するために作成した Google グループに IAM のカスタムロールを割り当てます。Google Cloud Storage にファイルを保存する際に顧客が提供する暗号鍵を使用してデータを暗号化します。
- B. セキュリティ要件を適用するために作成した Google グループに IAM のカスタムロールを割り当てます。Google Cloud Storage にファイルを保存する前にデフォルトのストレージを暗号化して有効にします。
- C. セキュリティ要件を適用するために作成した Google グループにIAM の事前定義ロールを割り当てます。Google Cloud Storage にファイルを保存する際に Google のデフォルトの暗号化を利用します。
- D. セキュリティ要件を実施するために作成した Google グループに事前定義済みの IAM ロールを割り当てます。Google Cloud Storage にファイルを保存する際にデフォルトのCloud KMS で暗号鍵が設定されていることを確認します。
Correct Answer: C
Question 53
この問題については Dress4Win のケーススタディ を参照してください。
ソリューションを移行する前にオンプレミスのアーキテクチャーがビジネス要件を満たしていることを確認する必要があります。
オンプレミスのアーキテクチャーにどのような変更を加えるべきでしょうか?
- A. RabbitMQ を Google Pub/Sub に置き換えます。
- B. MySQL を Google Cloud SQL for MySQL でサポートされているv5.7 にダウングレードします。
- C. コンピュートリソースのサイズを変更して事前に定義された Google Compute Engine のマシンタイプを使用します。
- D. マイクロサービスをコンテナ化して Google Kubernetes Engine でホストします。
Correct Answer: C
Comments are closed