![[GCP] Google Cloud Certified - Associate Cloud Engineer](https://www.cloudsmog.net/wp-content/uploads/google-cloud-certified_associate-cloud-engineer-1.jpg)
Google Cloud 認定資格 – Associate Cloud Engineer – 模擬問題集(全 197問)
Question 001
会社のすべての従業員は Google アカウントを持っています。
運用チームは Compute Engine で多数のインスタンスを管理する必要があります。このチームの各メンバーはサーバへの管理アクセスのみが必要です。セキュリティ チームは資格情報の展開が運用上効率的であることを確認し、特定のインスタンスにアクセスしたユーザーを特定できる必要があります。
何をするべきでしょうか?
- A. 新しい SSH キー ペアを生成します。チームの各メンバーに秘密鍵を渡します。各インスタンスのメタデータで公開鍵を構成します。
- B. チームの各メンバーに新しい SSH キー ペアを生成し、公開キーを送信するように依頼します。構成管理ツールを使用し、これらのキーを各インスタンスにデプロイします。
- C. チームの各メンバーに新しい SSH キー ペアを生成し、公開キーを Google アカウントに追加するように依頼します。このチームに対応する Google グループに compute.osAdminLogin ロールを付与します。
- D. 新しい SSH キー ペアを生成します。チームの各メンバーに秘密鍵を渡します。Cloud Platform プロジェクトでプロジェクト全体の公開 SSH キーとして公開鍵を構成し、各インスタンスでプロジェクト全体の公開 SSH キーを許可します。
Answer: C
Reference:
–アクセス方法を選択する | Compute Engine ドキュメント | Google Cloud
Question 002
単一のサブネットを持つカスタム VPC を作成する必要があります。
サブネットの範囲はできるだけ大きくする必要があります。
どの範囲を使用する必要がありますか?
- A. 0.0.0.0/0
- B. 10.0.0.0/8
- C.172.16.0.0/12
- D.192.168.0.0/16
Answer: B
Question 003
Google Cloud Platform のリレーショナル データ向けの費用対効果の高いソリューションを選択して構成したいと考えています。
地理的な 1 か所で運用データの小さなセットを操作しています。ポイントインタイム リカバリをサポートする必要があります。
何をするべきでしょうか?
- A. Cloud SQL (MySQL) を選択します。[バイナリ ログを有効にする] オプションが選択されていることを確認します。
- B. Cloud SQL (MySQL) を選択します。フェイルオーバー レプリカの作成オプションを選択します。
- C. Cloud Spanner を選択し、インスタンスを 2 つのノードでセットアップします。
- D. Cloud Spanner を選択し、インスタンスをマルチリージョンとして設定します。
Answer: A
Reference:
– インスタンスの復元について | Cloud SQL for MySQL | Google Cloud
Question 04
可能な限り少ない手順で複数のゾーンで実行される Compute Engine インスタンスのグループのネットワーク負荷分散の自動修復を構成したいと考えています。
VM が 10 秒ずつ 3回試行しても応答しない場合は VM の再作成を構成する必要があります。
何をするべきでしょうか?
- A. 既存のインスタンス グループを参照するバックエンド構成で HTTP ロードバランサを作成し、ヘルスチェックを正常 (HTTP) に設定します。
- B. 既存のインスタンス グループを参照するバックエンド構成で HTTP ロードバランサを作成し、バランシング モードを定義し、最大 RPS を 10 に設定します。
- C. マネージド インスタンス グループを作成し、自動修復ヘルス チェックを正常 (HTTP) に設定します。
- D. マネージド インスタンス グループを作成し、自動スケーリング設定がオンになっていることを確認します。
Answer: C
Question 005
gcloud に複数の構成を使用しています。
できるだけ少ない手順で非アクティブな構成の構成済み Kubernetes Engine クラスタを確認したいと考えています。
何をするべきでしょうか?
- A. gcloud config configurations を使用し、出力を確認します。
- B. gcloud config configurations activate と gcloud config list を使用し、出力を確認します。
- C. kubectl config get-contexts を使用し、出力を確認します。
- D. kubectl config use-context と kubectl config view を使用し、出力を確認します。
Answer: D
Reference:
– Kubernetes Engine: kubectl config | by Daz Wilkin | Google Cloud – Community | Medium
Question 006
会社では Cloud Storage を使用して災害復旧用のアプリケーション バックアップ ファイルを保存しています。
Google のベストプラクティスに従います。
どのストレージ オプションを使用する必要がありますか?
- A. Multi-Regional ストレージ
- B. Regional ストレージ
- C. Nearline ストレージ
- D. Coldline ストレージ
Answer: D
Reference:
–ストレージ クラス | Cloud Storage | Google Cloud
Question 007
数名の従業員は Google Cloud Platform を使用してプロジェクトを作成し、会社が払い戻す個人のクレジット カードでその費用を支払っています。
会社はこれらすべてのプロジェクトを 1 つの新しい請求先アカウントに集約したいと考えています。
何をするべきでしょうか?
- A. cloud-billing@google.com に銀行口座の詳細を連絡し、会社の法人請求先アカウントをリクエストします。
- B. Google サポートでチケットを作成し、電話でクレジット カードの詳細を共有する電話を待ちます。
- C. Google プラットフォーム コンソールでリソース管理に移動し、すべてのプロジェクトをルート組織に移動します。
- D. Google Cloud Console で新しい請求先アカウントを作成し、支払い方法を設定します。
Answer: D
Reference:
–40+ Google Cloud Interview Questions and Answers in 2022 – Whizlabs Blog
Question 008
IP 10.0.3.21 でライセンス サーバを探すアプリケーションがあります。
Compute Engine 上にライセンスサーバをデプロイする必要があります。アプリケーションの構成を変更せず、アプリケーションがライセンスサーバに到達できるようにしたいと思います
何をするべきでしょうか?
- A. gcloud を使用して IP 10.0.3.21 を静的内部 IP アドレスとして予約し、ライセンス サーバに割り当てます。
- B. gcloud を使用して IP 10.0.3.21 を静的パブリック IP アドレスとして予約し、ライセンス サーバに割り当てます。
- C. IP 10.0.3.21 をカスタムのエフェメラル IP アドレスとして使用し、ライセンス サーバに割り当てます。
- D. 自動エフェメラル IP アドレスを使用してライセンス サーバを起動し、それを静的内部 IP アドレスに昇格させます。
Answer: A
Question 009
アプリケーションを App Engine にデプロイしています。
リクエスト率に基づいてインスタンスの数をスケーリングする必要があります。常に少なくとも 3 つの占有されていないインスタンスが必要です。
どのスケーリング タイプを使用する必要がありますか?
- A. 3 つのインスタンスを使用した手動スケーリング。
- B. min_instances を 3 に設定した基本スケーリング。
- C. max_instances を 3 に設定した基本スケーリング。
- D. min_idle_instances を 3 に設定した自動スケーリング。
Answer: D
Reference:
–インスタンスの管理方法 | Python 2 の App Engine スタンダード環境 | Google Cloud
Question 010
適切な IAM ロールが定義された開発プロジェクトがあります。
本番プロジェクトを作成しており、可能な限り少ない手順で新しいプロジェクトに同じ IAM ロールを持たせたいと考えています。
何をするべきでしょうか?
- A. gcloud iam roles copy を使用し、本番プロジェクトを宛先プロジェクトとして指定します。
- B. gcloud iam roles copy を使用し、組織を宛先組織として指定します。
- C. Google Cloud Console で「ロールからロールを作成」機能を使用します。
- D. Google Cloud Console で「ロールの作成」機能を使用し、該当するすべての権限を選択します。
Answer: A
Reference:
–gcloud iam roles copy | Google Cloud CLI Documentation
Question 011
Compute Engine で VM を動的にプロビジョニングする方法が必要です。
正確な仕様は、専用の構成ファイルにあります。Google のベストプラクティスに従います。
どの方法を使用する必要がありますか?
- A. Google Cloud Deployment Manager
- B. Cloud Composer
- C. マネージド インスタンス グループ
- D. 非マネージド インスタンス グループ
Answer: A
Reference:
–仮想マシン インスタンス | Compute Engine ドキュメント | Google Cloud
Question 012
Kubernetes Engine にデプロイする必要がある Dockerfile があります。
何をするべきでしょうか?
- A. kubectl app deploy <dockerfilename> を使用します。
- B. gcloud app deploy <dockerfilename> を使用します。
- C. Dockerfile から Docker イメージを作成し、Container Registry にアップロードします。そのイメージを指すデプロイメント YAML ファイルを作成します。kubectl を使用し、そのファイルでデプロイメントを作成します。
- D. Dockerfile から Docker イメージを作成し、Cloud Storage にアップロードします。そのイメージを指すデプロイメント YAML ファイルを作成します。kubectl を使用し、そのファイルでデプロイメントを作成します。
Answer: C
Reference:
–コンテナ化されたウェブ アプリケーションのデプロイ | Kubernetes Engine | Google Cloud
Question 013
開発チームはプロジェクト用に新しい Jenkins サーバを必要としています。
可能な限り少ない手順でサーバを展開する必要があります。
何をするべきでしょうか?
- A. Jenkins Java WAR をダウンロードして App Engine Standard にデプロイします。
- B. 新しい Compute Engine インスタンスを作成し、コマンドライン インターフェースから Jenkins をインストールします。
- C. Compute Engine で Kubernetes クラスタを作成し、Jenkins Docker イメージを使用してデプロイを作成します。
- D. GCP Marketplace を使用して Jenkins ソリューションを起動します。
Answer: D
Reference:
–Jenkins を使用して Compute Engine に分散ビルドを実行する | Cloud アーキテクチャ センター | Google Cloud
Question 014
デプロイでリソースをダウンタイムせずに Deployment Manager でデプロイを更新する必要があります。
どのコマンドを使用する必要がありますか?
- A. gcloud deployment-manager deployments create –config <deployment-config-path>
- B. gcloud deployment-manager deployments update –config <deployment-config-path>
- C. gcloud deployment-manager resources create –config <deployment-config-path>
- D. gcloud deployment-manager resources update –config <deployment-config-path>
Answer: B
Reference:
–gcloud deployment-manager deployments update | Google Cloud CLI Documentation
Question 015
BigQuery で重要なクエリを実行する必要がありますが多くのレコードが返されることが予想されます。
クエリの実行にかかる費用を事前に把握したいと考えています。オンデマンド料金を使用しています。
何をするべきでしょうか?
- A. このクエリを定額料金に切り替えてからオンデマンドに戻すよう手配してください。
- B. コマンドラインを使用してドライラン クエリを実行して読み取られたバイト数を見積もります。次に Google Cloud 料金計算ツールを使用し、その推定バイト数をドルに換算します。
- C. コマンドラインを使用してドライラン クエリを実行して返されるバイト数を見積もります。次に Google Cloud 料金計算ツールを使用し、その推定バイト数をドルに換算します。
- D. select count (*) を実行してクエリが検索するレコードの数を把握します。次に Google Cloud 料金計算ツールを使用し、その行数をドルに換算します。
Answer: B
Reference:
–ストレージとクエリの費用の見積もり | BigQuery | Google Cloud
Question 016
Google Cloud Platform で実行する単一のバイナリ アプリケーションがあります。
基盤となるインフラストラクチャの CPU 使用率に基づいて、アプリケーションを自動的にスケーリングすることにしました。組織のポリシーでは仮想マシンを直接使用する必要があります。アプリケーションのスケーリングが運用上効率的であり、できるだけ早く完了するようにする必要があります。
何をするべきでしょうか?
- A. Google Kubernetes Engine クラスタを作成し、水平 Pod 自動スケーリングを使用してアプリケーションをスケーリングします。
- B. インスタンス テンプレートを作成し、自動スケーリングが構成されたマネージド インスタンス グループでそのテンプレートを使用します。
- C. インスタンス テンプレートを作成し、時刻に基づいてスケールアップ、スケールダウンするマネージド インスタンス グループでテンプレートを使用します。
- D. 一連のサードパーティ ツールを使用して Stackdriver の CPU 使用率のモニタリングに基づいて、アプリケーションのスケールアップとスケールダウンに関する自動化を構築します。
Answer: B
Question 017
あなたは 3 つの別々のプロジェクトから Google Cloud Platform サービスの費用を分析しています。
この情報を使用し、標準のクエリ構文で今後 6 か月間のサービスの種類別の日次、月次のサービス コスト見積もりを作成します。
何をするべきでしょうか?
- A. 請求書を Cloud Storage バケットにエクスポートし、分析のために Cloud Bigtable にインポートします。
- B. 請求書を Cloud Storage バケットにエクスポートし、分析のために Google スプレッドシートにインポートします。
- C. トランザクションをローカル ファイルにエクスポートし、デスクトップ ツールで分析を実行します。
- D. 請求書を BigQuery データセットにエクスポートし、分析のためにタイム ウィンドウ ベースの SQL クエリを作成します。
Answer: D
Question 018
特定の Cloud Storage リージョン バケットに保存されている動画が 90 日後に Coldline に移動され、作成から 1 年後に削除されるようにポリシーを設定する必要があります。
ポリシーをどのように設定する必要がありますか?
- A. SetStorageClass、Delete アクションで Age 条件を使用して Cloud Storage Object Lifecycle Management を使用します。SetStorageClass アクションを 90 日に設定し、Delete アクションを 275 日 (365 – 90) に設定します。
- B. SetStorageClass、Delete アクションで Age 条件を使用して Cloud Storage Object Lifecycle Management を使用します。SetStorageClass アクションを 90 日に Delete アクションを 365 日に設定します。
- C. gsutil rewrite を使用して削除アクションを 275 日 (365-90) に設定します。
- D. gsutil rewrite を使用して削除アクションを 365 日に設定します。
Answer: B
Question 019
Cloud SQL に接続する必要がある Linux VM があります。
適切なアクセス権を持つサービス アカウントを作成しました。VM がデフォルトの Compute Engine サービス アカウントではなく、このサービス アカウントを使用するようにします。
何をするべきでしょうか?
- A. Web コンソールを使用して VM を作成する場合は [ID と API アクセス] セクションでサービス アカウントを指定します。
- B. サービス アカウントの JSON 秘密鍵をダウンロードします。プロジェクト メタデータで、その JSON をキー compute-engine-service-account の値として追加します。
- C. サービス アカウントの JSON 秘密鍵をダウンロードします。VM のカスタム メタデータでその JSON をキー compute-engine-service-account の値として追加します。
- D. サービス アカウントの JSON 秘密鍵をダウンロードします。VM を作成し、VM に SSH 接続して JSON を ~/.gcloud/compute-engine-service-account.json に保存します。
Answer: A
Reference:
–サービス アカウントを使用したワークロードを認証 | Compute Engine ドキュメント | Google Cloud
Question 020
新しいバージョンの機能をテストするために Compute Engine で SQL Server 2017 のインスタンスを作成しました。
最小限の手順でこのインスタンスに接続したいと考えています。
何をするべきでしょうか?
- A. デスクトップに RDP クライアントをインストールします。ポート 3389 のファイアウォール ルールが存在することを確認します。
- B. デスクトップに RDP クライアントをインストールします。Google Cloud Console で Windows ユーザー名とパスワードを設定します。認証情報を使用してインスタンスにログインします。
- C. Google Cloud Console で Windows パスワードを設定します。ポート 22 のファイアウォール ルールが存在することを確認します。Google Cloud Console で RDP ボタンをクリックし、認証情報を入力してログインします。
- D. Google Cloud Console で Windows ユーザー名とパスワードを設定します。ポート 3389 のファイアウォール ルールが存在することを確認します。Google Cloud Console で RDP ボタンをクリックし、認証情報を入力してログインします。
Answer: B
Reference:
–SQL Server in the Google Cloud | by Falafel Software Bloggers | Falafel Software | Medium
Question 021
デフォルトのリージョンとゾーンで実行されている 1 つの GCP アカウントと、デフォルト以外のリージョンとゾーンで実行されている別のアカウントがあります。
コマンドライン インターフェースを使用し、これら 2 つの Google Cloud Platform アカウントで新しい Compute Engine インスタンスを開始したいと考えています。
何をするべきでしょうか?
- A. gcloud config configurations create [NAME] を使用して 2 つの構成を作成します。gcloud config configurations activate [NAME] を実行し、Compute Engine インスタンスを起動するコマンドを実行するときにアカウントを切り替えます。
- B. gcloud config configurations create [NAME] を使用して 2 つの構成を作成します。gcloud configurations list を実行し、Compute Engine インスタンスを起動します。
- C. gcloud configurations activate [NAME] を使用して 2 つの構成をアクティブ化します。gcloud config list を実行し、Compute Engine インスタンスを開始します。
- D. gcloud configurations activate [NAME] を使用して 2 つの構成をアクティブ化します。gcloud configurations list を実行し、Compute Engine インスタンスを起動します。
Answer: A
Question 022
複雑な Deployment Manager テンプレートを大幅に変更し、プロジェクトにコミットする前に、定義されたすべてのリソースの依存関係が適切に満たされていることを確認したいと考えています。
変更に関する最も迅速なフィードバックが必要です。
何をするべきでしょうか?
- A. Python で作成された Deployment Manager テンプレート内で詳細なログ ステートメントを使用します。
- B. Google Cloud Console の Stackdriver Logging ページで Deployment Manager 実行のアクティビティを監視します。
- C. 同じ構成の別のプロジェクトに対して Deployment Manager テンプレートを実行し、障害を監視します。
- D. 同じプロジェクトで -preview オプションを使用して Deployment Manager テンプレートを実行し、相互に依存するリソースの状態を観察します。
Answer: D
Reference:
–デプロイを更新する | Cloud Deployment Manager のドキュメント | Google Cloud
Question 023
時系列データを処理するパイプラインを構築しています。
ボックス 1、2、3、4 に入れる必要がある Google Cloud Platform サービスはどれでしょうか?
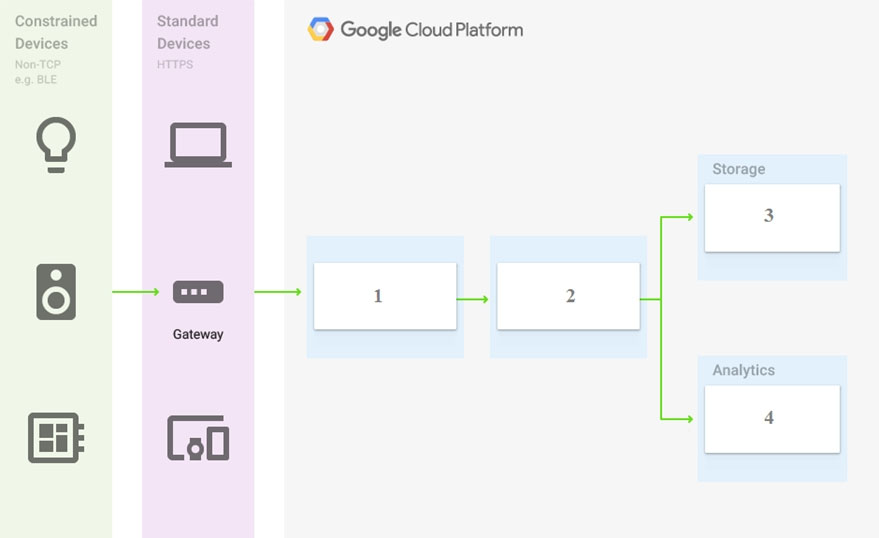
- A. Cloud Pub/Sub、Cloud Dataflow、Datastore、BigQuery
- B. Firebase Cloud Messaging、Cloud Pub/Sub、Cloud Spanner、BigQuery
- C. Cloud Pub/Sub、Cloud Storage、BigQuery、Cloud Bigtable
- D. Cloud Pub/Sub、Cloud Dataflow、Cloud Bigtable、BigQuery
Answer: D
Reference:
–時系列データの処理: チュートリアル | Cloud アーキテクチャ センター | Google Cloud
Question 024
開発環境を提供する App Engine アプリケーションのプロジェクトがあります。
必要なテストが成功したので運用環境として機能する新しいプロジェクトを作成したいと考えています。
何をするべきでしょうか?
- A. gcloud を使用して新しいプロジェクトを作成し、アプリケーションを新しいプロジェクトにデプロイします。
- B. gcloud を使用して新しいプロジェクトを作成し、デプロイされたアプリケーションを新しいプロジェクトにコピーします。
- C. 現在の App Engine デプロイメントを新しいプロジェクトにコピーする Deployment Manager 構成ファイルを作成します。
- D. gcloud を使用してアプリケーションを再度デプロイし、プロジェクト パラメータに新しいプロジェクト名を指定して新しいプロジェクトを作成します。
Answer: A
Question 025
外部監査人のために BigQuery で IAM アクセス監査ロギングを構成する必要があります。
Google のベストプラクティスに従います。
何をするべきでしょうか?
- A. 事前定義された IAM ロール「logging.viewer」「bigQuery.dataViewer」に監査者グループを追加します。
- B. auditers グループを 2 つの新しいカスタム IAM ロールに追加します。
- C. 監査人のユーザー アカウントを「logging.viewer」「bigQuery.dataViewer」の定義済み IAM ロールに追加します。
- D. 監査人ユーザー アカウントを 2 つの新しいカスタム IAM ロールに追加します。
Answer: A
Reference:
–監査関連ジョブ機能の IAM ロール | IAM のドキュメント | Google Cloud
Question 026
特定の Cloud Storage バケットにデータを書き込めるようにするには Compute Engine インスタンスのセットに対する権限を設定する必要があります。
Google のベストプラクティスに従います。
何をするべきでしょうか?
- A. アクセス スコープを持つサービス アカウントを作成し、アクセス スコープ「https://www.googleapis.com/auth/devstorage.write_only」を使用します。
- B. アクセス スコープを持つサービス アカウントを作成し、アクセス スコープ「https://www.googleapis.com/auth/cloud-platform」を使用します。
- C. サービス アカウントを作成し、そのバケットの IAM ロール「storage.objectCreator」に追加します。
- D. サービス アカウントを作成し、そのバケットの IAM ロール「storage.objectAdmin」に追加します。
Answer: C
Question 027
機密データが 3 つの Cloud Storage バケットに保存されており、データ アクセス ロギングを有効にしています。
可能な限り少ないステップを使用し、これらのバケットの特定のユーザーのアクティビティを確認したいと考えています。メタデータ ラベルの追加と、それらのバケットから表示されたファイルを確認する必要があります。
何をするべきでしょうか?
- A. Google Cloud Console を使用し、アクティビティ ログをフィルタリングして情報を表示します。
- B. Google Cloud Console を使用し、Stackdriver ログをフィルタリングして情報を表示します。
- C. Google Cloud Console の [Cloud Storage] セクションでバケットを表示します。
- D. Stackdriver でトレースを作成して情報を表示します。
Answer: A
Question 028
あなたは GCP プロジェクトのプロジェクト オーナーであり、Cloud Storage のバケットとファイルを管理する権限を同僚に委任したいと考えています。
Google が推奨するプラクティスに従う必要があります。
同僚にどの IAM ロールを付与する必要がありますか?
- A. プロジェクト編集者
- B. ストレージ管理者
- C. ストレージ オブジェクト管理者
- D. ストレージ オブジェクト作成者
Answer: B
Question 029
Cloud Storage バケットに、外部企業と共有したいオブジェクトがあります。
オブジェクトには機密データが含まれています。コンテンツへのアクセスを 4 時間後に削除したいと考えています。外部企業には特定のユーザーベースのアクセス権限を付与できる Google アカウントがありません。必要な手順が最も少なく、最も安全な方法を使用したい。
何をするべきでしょうか?
- A. 有効期限が 4 時間の署名付き URL を作成し、その URL を会社と共有します。
- B. オブジェクト アクセスを「パブリック」に設定し、オブジェクト ライフサイクル管理を使用して 4 時間後にオブジェクトを削除します。
- C. ストレージ バケットを静的 Web サイトとして構成し、オブジェクトの URL を会社に提供します。4 時間後にストレージ バケットからオブジェクトを削除します。
- D. 外部企業がアクセスする専用の新しい Cloud Storage バケットを作成します。オブジェクトをそのバケットにコピーします。4 時間経過後にバケットを削除します。
Answer: A
Question 030
クラスタ オートスケーラー機能を有効にして Google Kubernetes Engine (GKE) クラスタを作成しています。
クラスタの各ノードがコンテナ メトリックをサードパーティの監視ソリューションに送信する監視ポッドを実行することを確認する必要があります。
何をするべきでしょうか?
- A. StatefulSet オブジェクトに監視ポッドをデプロイします。
- B. 監視ポッドを DaemonSet オブジェクトにデプロイします。
- C. Deployment オブジェクトで監視ポッドを参照します。
- D. GKE クラスタの作成時にクラスタ初期化子でモニタリング ポッドを参照します。
Answer: B
Question 031
App Engine アプリケーションから Cloud Pub/Subメッセージを送受信したいと考えています。
Cloud Pub/Sub API は現在無効になっています。サービス アカウントを使用してアプリケーションを API に対して認証します。アプリケーションで Cloud Pub/Sub を使用できることを確認したいと考えています。
何をするべきでしょうか?
- A. Google Cloud Console の API ライブラリで Cloud Pub/Sub API を有効にします。
- B. サービスアカウントからCloud Pub/Sub APIにアクセスすると、自動的に有効になるようにします。
- C. Deployment Manager を使用してアプリケーションをデプロイします。デプロイされるアプリケーションによって使用されるすべての API の自動有効化に依存します。
- D. App Engine のデフォルト サービス アカウントに Cloud Pub/Sub 管理者の役割を付与します。Cloud Pub/Sub への最初の接続で、アプリケーションで API を有効にします。
Answer: A
Question 032
Google Cloud Platform のさまざまなプロジェクトに分散されているリソースを監視する必要があります。
レポートを同じ Stackdriver Monitoring ダッシュボードに統合したいと考えています。
何をするべきでしょうか?
- A. 共有 VPC を使用してすべてのプロジェクトを接続し、Stackdriver をプロジェクトの 1 つにリンクします。
- B. プロジェクトごとに Stackdriver アカウントを作成します。各プロジェクトで、そのプロジェクトのサービス アカウントを作成し、他のすべてのプロジェクトで Stackdriver Account Editor の役割を付与します。
- C. 単一の Stackdriver アカウントを構成し、すべてのプロジェクトを同じアカウントにリンクします。
- D. プロジェクトの 1 つに対して単一の Stackdriver アカウントを構成します。Stackdriver でグループを作成し、そのグループの条件として他のプロジェクト名を追加します。
Answer: C
Question 033
マネージド インスタンス グループ内の Compute Engine VM にアプリケーションをデプロイしています。
アプリケーションは常に実行されている必要がありますが GCP プロジェクトごとに VM のインスタンスを 1 つだけ実行する必要があります。
インスタンス グループをどのように構成する必要がありますか?
- A. 自動スケーリングをオンに設定し、インスタンスの最小数を 1 に設定してから、インスタンスの最大数を 1 に設定します。
- B. 自動スケーリングをオフに設定し、インスタンスの最小数を 1 に設定してから、インスタンスの最大数を 1 に設定します。
- C. 自動スケーリングをオンに設定し、インスタンスの最小数を 1 に設定してから、インスタンスの最大数を 2 に設定します。
- D. 自動スケーリングをオフに設定し、インスタンスの最小数を 1 に設定してから、インスタンスの最大数を 2 に設定します。
Answer: A
Question 034
my-project という名前の GCP プロジェクト内で割り当てられた IAM ユーザーと役割を確認したいと考えています。
何をするべきでしょうか?
- A. gcloud iam roles list を実行し、出力セクションを確認します。
- B. gcloud iam service-accounts list を実行し、出力セクションを確認します。
- C. プロジェクトに移動し、Google Cloud Console の [IAM] セクションに移動します。メンバーとロールを確認します。
- D. プロジェクトに移動し、Google Cloud Console の [ロール] セクションに移動します。ロールとステータスを確認します。
Answer: C
Question 035
新しい請求先アカウントを作成し、それを既存の Google Cloud Platform プロジェクトにリンクする必要があります。
何をするべきでしょうか?
- A. GCP プロジェクトの Project Billing Manager であることを確認します。既存のプロジェクトを更新し、既存の請求先アカウントにリンクします。
- B. GCP プロジェクトの Project Billing Manager であることを確認します。新しい請求先アカウントを作成し、新しい請求先アカウントを既存のプロジェクトにリンクします。
- C. 請求先アカウントの請求管理者であることを確認します。新しいプロジェクトを作成し、新しいプロジェクトを既存の請求先アカウントにリンクします。
- D. 請求先アカウントの請求管理者であることを確認します。既存のプロジェクトを更新して、既存の請求先アカウントにリンクします。
Answer: B
Question 036
すべてのサービス アカウントを管理する proj-sa という 1 つのプロジェクトがあります。
このプロジェクトのサービス アカウントを使用して proj-vm という別のプロジェクトで実行されている VM のスナップショットを取得できるようにしたいと考えています。
何をするべきでしょうか?
- A. サービス アカウントから秘密鍵をダウンロードし、各 VM のカスタム メタデータに追加します。
- B. サービス アカウントから秘密鍵をダウンロードし、その秘密鍵を各 VM の SSH キーに追加します。
- C. サービス アカウントに proj-vm というプロジェクトで Compute Storage Admin の IAM ロールを付与します。
- D. VM を作成するときに Compute Engine のサービス アカウントの API スコープを読み取り/書き込みに設定します。
Answer: C
Question 037
プロジェクト内に App Engine アプリケーションを含む Google Cloud Platform プロジェクトを作成しました。
最初に us-central リージョンから提供されるようにアプリケーションを構成しました。ここでアプリケーションを asia-northeast1 リージョンから提供する必要があります。
何をするべきでしょうか?
- A. 既存の GCP プロジェクトのデフォルトのリージョン プロパティ設定を asia-northeast1 に変更します。
- B. 既存の App Engine アプリケーションのリージョン プロパティ設定を us-central から asia-northeast1 に変更します。
- C. 既存の GCP プロジェクトに 2 つ目の App Engine アプリケーションを作成し、アプリケーションを提供するリージョンとして asia-northeast1 を指定します。
- D. 新しい GCP プロジェクトを作成し、この新しいプロジェクト内に App Engine アプリケーションを作成します。アプリケーションを提供するリージョンとして asia-northeast1 を指定します。
Answer: D
Question 038
Cloud Spanner インスタンスでテーブル データを表示、編集できるように 3 人のユーザーにアクセス権を付与する必要があります。
何をするべきでしょうか?
- A. gcloud iam roles describe roles/spanner.databaseUser を実行し、ユーザーをロールに追加します。
- B. gcloud iam roles describe roles/spanner.databaseUser を実行し、ユーザーを新しいグループに追加します。グループをロールに追加します。
- C. gcloud iam roles describe roles/spanner.viewer –project my-project を実行し、ユーザーをロールに追加します。
- D. gcloud iam roles describe roles/spanner.viewer -project my-project を実行し、ユーザーを新しいグループに追加してグループをロールに追加します。
Answer: B
Question 039
新しい Google Kubernetes Engine (GKE) クラスタを作成し、サポートされている安定したバージョンの Kubernetes が常に実行されるようにしたいと考えています。
何をするべきでしょうか?
- A. GKE クラスタのノード自動修復機能を有効にします。
- B. GKE クラスタのノード自動アップグレード機能を有効にします。
- C. GKE クラスタで利用可能な最新のクラスタ バージョンを選択します。
- D. GKE クラスタのノード イメージとして Container-Optimized OS (cos) を選択します。
Answer: B
Question 040
負荷分散するインスタンス グループがあります。
ロード バランサーがクライアント SSL セッションを終了するようにします。インスタンス グループは HTTPS 経由でパブリック Web アプリケーションを提供するために使用されます。Google のベストプラクティスに従います。
何をするべきでしょうか?
- A. HTTP (S) ロード バランサを構成します。
- B. 内部 TCP ロード バランサを構成します。
- C. 外部 SSL プロキシ ロード バランサを設定します。
- D. 外部 TCP プロキシ ロード バランサを設定します。
Answer: A
Reference:
–外部 HTTP(S) 負荷分散の概要 | Google Cloud
Question 041
Nearline Storage バケットにアップロードする必要がある 1 つのファイルに 32 GB のデータがあります。
使用している WAN 接続の定格は 1 Gbps で、その接続に接続しているのはあなただけです。ファイルを高速に転送するために、定格の 1 Gbps をできるだけ多く使用したいと考えています。
どのようにファイルをアップロードする必要がありますか?
- A. gsutil の代わりに Google Cloud Console を使用してファイルを転送します。
- B. ファイル転送で gsutil を使用して並列複合アップロードを有効にします。
- C. 転送を開始するマシンの TCP ウィンドウ サイズを小さくします。
- D. バケットのストレージ クラスを Nearline から Multi-Regional に変更します。
Answer: B
Question 042
以下で指定された YAML ファイルを使用して myapp1 というマイクロサービスを Google Kubernetes Engine クラスタにデプロイしました。
apiVersion: apps/vi
kind: Deployment
metadata:
name: myappl-deployment
spec:
selector:
matchLabels:
app: myapp1
replicas: 2
template:
metadata:
labels:
app: myappi
spec: containers:
- name: main-container
image: gcr.io/my-company-repo/myappi:1.4
env:
- name: DB_PASSWORD
value: "tough2guess!"
ports: - containerPort: 8080データベース パスワードがプレーン テキストで保存されないように、この構成をリファクタリングする必要があります。Google のベストプラクティスに従います。
何をするべきでしょうか?
- A. YAML ファイルではなく、コンテナの Docker イメージ内にデータベース パスワードを保存します。
- B. Secret オブジェクト内にデータベース パスワードを保存します。YAML ファイルを変更し、Secret から DB_PASSWORD 環境変数を設定します。
- C. ConfigMap オブジェクト内にデータベース パスワードを格納します。YAML ファイルを変更して ConfigMap から DB_PASSWORD 環境変数を設定します。
- D. データベース パスワードを Kubernetes 永続ボリューム内のファイルに保存し、永続ボリューム クレームを使用してボリュームをコンテナにマウントします。
Answer: B
Question 043
マネージド インスタンス グループ内の複数の仮想マシンでアプリケーションを実行しており、Auto Scaling が有効になっています。
自動スケーリング ポリシーは、インスタンスの CPU 使用率が 80% を超えた場合に追加のインスタンスがグループに追加されるように構成されています。VM はインスタンス グループが VM の上限である 5 つに達するまで、またはインスタンスの CPU 使用率が 80% に低下するまで追加されます。インスタンスに対する HTTP ヘルスチェックの初期遅延は 30 秒に設定されています。仮想マシン インスタンスはユーザーが使用できるようになるまでに約 3 分かかります。インスタンス グループが自動スケーリングされると、エンドユーザー トラフィックのレベルをサポートするために必要以上のインスタンスが追加されることがわかります。自動スケーリング時にインスタンス グループのサイズを適切に維持したい。
何をするべきでしょうか?
- A. インスタンスの最大数を 1 に設定します。
- B. インスタンスの最大数を 3 に減らします。
- C. HTTP ヘルス チェックの代わりに TCP ヘルス チェックを使用します。
- D. HTTP ヘルスチェックの初期遅延を 200 秒に増やします。
Answer: D
Question 044
一連のバッチ処理ジョブのコンピューティング リソースを選択して構成する必要があります。
これらのジョブは完了するまでに約 2 時間かかり、毎晩実行されます。サービス コストを最小限に抑えます。
何をするべきでしょうか?
- A. Google Kubernetes Engine を選択します。インスタンス タイプが小さい単一ノード クラスタを使用します。
- B. Google Kubernetes Engine を選択します。マイクロ インスタンス タイプで 3 ノード クラスタを使用します。
- C. Compute Engine を選択します。適切な標準マシンタイプのプリエンプティブル VM インスタンスを使用します。
- D. Compute Engine を選択します。マイクロ バーストをサポートする VM インスタンス タイプを使用します。
Answer: C
Question 045
最近、新しいバージョンのアプリケーションを App Engine にデプロイしたところ、リリースにバグが見つかりました。
すぐにアプリケーションを以前のバージョンに戻す必要があります。
何をするべきでしょうか?
- A. gcloud app restore を実行します。
- B. Google Cloud Consolen の App Engine ページで元に戻す必要があるアプリケーションを選択し、[元に戻す] をクリックします。
- C. Google Cloud Console の [App Engine のバージョン] ページでトラフィックの 100% を以前のバージョンにルーティングします。
- D. 元のバージョンを別のアプリケーションとして展開します。次に App Engine の設定に移動し、アプリケーション間でトラフィックを分割して、元のバージョンがリクエストの 100% を処理するようにします。
Answer: C
Question 046
gcloud app deploy を使用して App Engine アプリケーションをデプロイしましたが、目的のプロジェクトにデプロイされませんでした。
これが発生した理由と、アプリケーションがデプロイされた場所を見つけたいと考えています。
何をするべきでしょうか?
- A. アプリケーションの app.yaml ファイルを確認し、プロジェクトの設定を確認します。
- B. アプリケーションの web-application.xml ファイルを確認し、プロジェクトの設定を確認します。
- C. Deployment Manager に移動し、アプリケーションの展開の設定を確認します。
- D. Cloud Shell に移動し、gcloud config list を実行してデプロイに使用される Google Cloud 構成を確認します。
Answer: D
Reference:
–App Engine フレキシブル環境でのデプロイのトラブルシューティング | OpenAPI を使用した Cloud Endpoints | Google Cloud
Question 047
メンテナンスが発生したときに使用できるように 10 個の Compute Engine インスタンスを構成したいと考えています。
要件では、これらのインスタンスがクラッシュした場合に自動的に再起動を試みる必要があると規定されています。また、インスタンスはシステム メンテナンス中も含めて高可用性である必要があります。
何をするべきでしょうか?
- A. インスタンスのインスタンス テンプレートを作成します。「自動再起動」をオンに設定します。「オンホスト メンテナンス」を VM インスタンスの移行に設定します。インスタンス テンプレートをインスタンス グループに追加します。
- B. インスタンスのインスタンス テンプレートを作成します。「自動再起動」をオフに設定します。[ホスト メンテナンス] を [VM インスタンスを終了する] に設定します。インスタンス テンプレートをインスタンス グループに追加します。
- C. インスタンスのインスタンス グループを作成します。「自動修復」ヘルスチェックを正常 (HTTP) に設定します。
- D. インスタンスのインスタンス グループを作成します。[マシンの作成を再試行しない] の [高度な作成オプション] 設定がオフに設定されていることを確認します。
Answer: A
Question 048
Cloud Storage で静的 Web サイトをホストしています。
最近、このサイトに PDF ファイルへのリンクが含まれるようになりました。現在、ユーザーがこれらの PDF ファイルへのリンクをクリックすると、ブラウザはファイルをローカル システムに保存するように求めます。代わりに、ユーザーにファイルをローカルに保存するように求めるプロンプトを表示せずに、クリックした PDF ファイルをブラウザ ウィンドウ内に直接表示する必要があります。
何をするべきでしょうか?
- A. ウェブサイトのフロントエンドで Cloud CDN を有効にします。
- B. PDF ファイル オブジェクトで [一般公開で共有] を有効にします。
- C. PDF ファイル オブジェクトの Content-Type メタデータを application/pdf に設定します。
- D. Content-Type のキーと application/pdf の値を持つストレージ バケットにラベルを追加します。
Answer: C
Question 049
現在、2 つの vCPU と 4 GB のメモリで構成されている仮想マシンがあります。
メモリ不足で仮想マシンを 8 GB のメモリにアップグレードしたいと考えています。
何をするべきでしょうか?
- A. ライブ マイグレーションを利用し、より多くのメモリを搭載したマシンにワークロードを移動します。
- B. gcloud を使用して VM にメタデータを追加します。キーを required-memory-size に設定し、値を 8 GB に設定します。
- C. VM を停止し、マシン タイプを n1-standard-8 に変更して VM を起動します。
- D. VM を停止し、メモリを 8 GB に増やして VM を起動します。
Answer: D
Question 050
Compute Engine にデプロイする本番環境とテスト ワークロードがあります。
運用 VM はテスト VM とは異なるサブネットにある必要があります。全ての
VM は追加のルートを作成することなく、内部 IP を介して相互に到達できる必要があります。VPC と 2 つのサブネットを設定する必要があります。
これらの要件を満たす構成はどれですか?
- A. 2 つのサブネットを持つ単一のカスタム VPC を作成します。各サブネットを異なるリージョンごとに異なる CIDR 範囲で作成します。
- B. 2 つのサブネットを持つ単一のカスタム VPC を作成します。同じリージョンに同じ CIDR 範囲で各サブネットを作成します。
- C. それぞれが単一のサブネットを持つ 2 つのカスタム VPC を作成します。各サブネットを異なるリージョンごとに異なる CIDR 範囲で作成します。
- D. それぞれが単一のサブネットを持つ 2 つのカスタム VPC を作成します。同じリージョンに同じ CIDR 範囲で各サブネットを作成します。
Answer: A
Question 051
HTTPS Web アプリケーション用の自動スケーリング マネージド インスタンス グループを作成する必要があります。
異常な VM が確実に再作成されるようにする必要があります。
何をするべきでしょうか?
- A. ポート 443 でヘルス チェックを作成し、マネージド インスタンス グループの作成時にそれを使用します。
- B. マネージド インスタンス グループを作成するときにシングルゾーンではなくマルチゾーンを選択します。
- C. インスタンス テンプレートでラベル「health-check」を追加します。
- D. インスタンス テンプレートでハートビートをメタデータ サーバに送信する起動スクリプトを追加します。
Answer: A
Reference:
–マネージド インスタンス グループ (MIG) を作成するための基本的なシナリオ | Compute Engine ドキュメント | Google Cloud
Question 052
会社にはデータ ウェアハウジングに BigQuery を使用する Google Cloud Platform プロジェクトがあります。
データ サイエンス チームは頻繁に変更され、メンバーはほとんどいません。このチームのメンバーがクエリを実行できるようにする必要があります。Google のベストプラクティスに従います。
何をするべきでしょうか?
- A.
- 1. データ サイエンティストのユーザー アカウントごとに IAM エントリを作成します。
2. グループに BigQuery jobUser ロールを割り当てます。
- 1. データ サイエンティストのユーザー アカウントごとに IAM エントリを作成します。
- B.
- 1. データ サイエンティストのユーザー アカウントごとに IAM エントリを作成します。
2. グループに BigQuery dataViewer ユーザー ロールを割り当てます。
- 1. データ サイエンティストのユーザー アカウントごとに IAM エントリを作成します。
- C.
- 1. Cloud Identity で専用の Google グループを作成します。
- 2. 各データ サイエンティストのユーザー アカウントをグループに追加します。
- 3. グループに BigQuery jobUser ロールを割り当てます。
- D.
- 1. Cloud Identity で専用の Google グループを作成します。
- 2. 各データ サイエンティストのユーザー アカウントをグループに追加します。
- 3. グループに BigQuery dataViewer ユーザー ロールを割り当てます。
Answer: C
Reference:
–Cloud SQL 連携クエリ | BigQuery
Question 053
あなたの会社には Compute Engine で実行されている 3 レイヤーのソリューションがあります。
現在のインフラストラクチャの構成を以下に示します。

各レイヤーには、そのレイヤー内のすべてのインスタンスに関連付けられたサービス アカウントがあります。次のように、レイヤーの間で TCP ポート 8080 での通信を有効にする必要があります。
– レイヤー #1 のインスタンスはレイヤー #2 と通信する必要があります。
– レイヤー #2 のインスタンスはレイヤー #3 と通信する必要があります。
何をするべきでしょうか?
- A.
- 1. 次の設定でイングレス ファイアウォール ルールを作成します。
ターゲット: すべてのインスタンス
ソース フィルタ: IP 範囲 (範囲を 10.0.2.0/24 に設定)
プロトコル: すべて許可 - 2. 次の設定でイングレス ファイアウォール ルールを作成します。
ターゲット: すべてのインスタンス
ソース フィルタ: IP 範囲 (範囲を 10.0.1.0/24 に設定)
プロトコル: すべて許可
- 1. 次の設定でイングレス ファイアウォール ルールを作成します。
- B.
- 1. 次の設定でイングレス ファイアウォール ルールを作成します。
ターゲット: レイヤー #2 サービス アカウントを持つすべてのインスタンス
ソース フィルタ: レイヤー #1 サービス アカウントを持つすべてのインスタンス
プロトコル: TCP:8080 を許可 - 2. 次の設定でイングレス ファイアウォール ルールを作成します。
ターゲット: レイヤー #3 サービス アカウントを持つすべてのインスタンス
ソース フィルタ: レイヤー #2 サービス アカウントを持つすべてのインスタンス プロトコル: TCP を許可: 8080
- 1. 次の設定でイングレス ファイアウォール ルールを作成します。
- C.
- 1. 次の設定でイングレス ファイアウォール ルールを作成します。
ターゲット: レイヤー #2 サービス アカウントを持つすべてのインスタンス
ソース フィルタ: レイヤー #1 サービス アカウントを持つすべてのインスタンス
プロトコル: すべてを許可 - 2. 次の設定でイングレス ファイアウォール ルールを作成します。
ターゲット: レイヤー #3 サービス アカウントを持つすべてのインスタンス
ソース フィルタ: レイヤー #2 サービス アカウントを持つすべてのインスタンス
プロトコル: すべてを許可
- 1. 次の設定でイングレス ファイアウォール ルールを作成します。
- D.
- 1. 次の設定でエグレス ファイアウォール ルールを作成します。
- 2. 次の設定で送信ファイアウォール ルールを作成します。
ターゲット: すべてのインスタンス
ソース フィルタ: IP 範囲 (範囲を 10.0.1.0/24 に設定)
プロトコル: TCP を許可: 8080
Answer: B
Question 054
us-central1 リージョンに 1 つの Virtual Private Cloud (VPC) と 1 つのサブネットワークを持つプロジェクトが与えられます。
このサブネットワークには、アプリケーションをホストする Compute Engine インスタンスがあります。europe-west1 リージョンの同じプロジェクトに新しいインスタンスをデプロイする必要があります。この新しいインスタンスにはアプリケーションへのアクセスが必要です。Google のベストプラクティスに従います。
何をするべきでしょうか?
- A.
- 1. 同じ VPC の europe-west1 にサブネットワークを作成します。
- 2. 新しいサブネットワークに新しいインスタンスを作成し、最初のインスタンスのプライベート アドレスをエンドポイントとして使用します。
- B.
- 1. europe-west1 に VPC とサブネットワークを作成します。
- 2. 内部ロード バランサーを使用してアプリケーションを公開します。
- 3. 新しいサブネットワークに新しいインスタンスを作成し、ロード バランサーのアドレスをエンドポイントとして使用します。
- C.
- 1. 同じ VPC の europe-west1 にサブネットワークを作成します。
- 2. Cloud VPN を使用して 2 つのサブネットワークを接続します。
- 3. 新しいサブネットワークに新しいインスタンスを作成し、最初のインスタンスのプライベート アドレスをエンドポイントとして使用します。
- D.
- 1. europe-west1 に VPC とサブネットワークを作成します。
- 2. 2 つの VPC をピアリングします。
- 3. 新しいサブネットワークに新しいインスタンスを作成し、最初のインスタンスのプライベート アドレスをエンドポイントとして使用します。
Answer: A
Question 055
あなたのプロジェクトでは、先月予想よりも多くの費用が発生しました。
調査の結果、開発用 GKE コンテナが膨大な数のログを出力し、その結果、コストが高くなったことが明らかになりました。最小限の手順でログをすばやく無効にしたい。
何をするべきでしょうか?
- A.
- 1. Stackdriver Logging の [ログの取り込み] ウィンドウに移動し、GKE コンテナ リソースのログ ソースを無効にします。
- B.
- 1. Stackdriver Logging の [ログの取り込み] ウィンドウに移動し、GKE クラスタ オペレーション リソースのログ ソースを無効にします。
- C.
- 1. GKE コンソールに移動し、既存のクラスタを削除します。
- 2. 新しいクラスタを再作成します。
- 3. オプションをオフにし、従来の Stackdriver Logging を有効にします。
- D.
- 1. GKE コンソールに移動し、既存のクラスタを削除します。
- 2. 新しいクラスタを再作成します。
- 3. オプションをオフにし、従来の Stackdriver Monitoring を有効にします。
Answer: A
Question 056
App Engine スタンダード環境でホストされているウェブサイトがあります。
ユーザーの 1% に Web サイトの新しいテスト バージョンを表示してもらいたいとします。複雑さを最小限に抑えたいです。
何をするべきでしょうか?
- A. 新しいバージョンを同じアプリケーションにデプロイし、–migrate オプションを使用します。
- B. 新しいバージョンを同じアプリケーションにデプロイし、–splits オプションを使用して、現在のバージョンに 99 の重みを付け、新しいバージョンに 1 の重みを付けます。
- C. 同じプロジェクトで新しい App Engine アプリケーションを作成します。そのアプリケーションに新しいバージョンをデプロイします。App Engine ライブラリを使用し、リクエストの 1% を新しいバージョンにプロキシします。
- D. 同じプロジェクトで新しい App Engine アプリケーションを作成します。そのアプリケーションに新しいバージョンをデプロイします。その新しいアプリケーションにトラフィックの 1% を送信するようにネットワーク ロード バランサーを構成します。
Answer: B
Question 057
マネージド インスタンス グループとしてデプロイされた Web アプリケーションがあります。
段階的にデプロイするアプリケーションの新しいバージョンがあります。Web アプリケーションは現在、ライブ Web トラフィックを受信しています。展開中に使用可能な容量が減少しないようにする必要があります。
何をするべきでしょうか?
- A. maxSurge を 0 に設定し、maxUnavailable を 1 に設定してローリング アクションの開始更新を実行します。
- B. maxSurge を 1 に設定し、maxUnavailable を 0 に設定してローリング アクションの開始更新を実行します。
- C. 更新されたインスタンス テンプレートを使用して新しいマネージド インスタンス グループを作成します。ロードバランサのバックエンド サービスにグループを追加します。新しいマネージド インスタンス グループのすべてのインスタンスが正常になったら、古いマネージド インスタンス グループを削除します。
- D. 新しいアプリケーション バージョンで新しいインスタンス テンプレートを作成します。新しいインスタンス テンプレートで既存のマネージド インスタンス グループを更新します。マネージド インスタンス グループ内のインスタンスを削除してマネージド インスタンス グループが新しいインスタンス テンプレートを使用してインスタンスを再作成できるようにします。
Answer: B
Question 058
ユーザーからのリレーショナル データを格納するアプリケーションを構築しています。
世界中のユーザーがこのアプリケーションを使用します。ユーザーベースのサイズが不明であるため、CTO はスケーリング要件について懸念しています。構成の変更を最小限に抑え、ユーザーの増加に合わせて拡張できるデータベース ソリューションを実装する必要があります。
どのストレージ ソリューションを使用する必要がありますか?
- A. Cloud SQL
- B. Cloud Spanner
- C. Cloud Firestore
- D. Datastore
Answer: B
Question 059
あなたは会社の組織、課金管理者です。
エンジニアリング チームには組織内でプロジェクト作成者の役割があります。エンジニアリング チームがプロジェクトを請求先アカウントにリンクできないようにしたいと考えています。プロジェクトを請求先アカウントにリンクできるのは財務チームだけであり、プロジェクトに他の変更を加えることはできません。
何をするべきでしょうか?
- A. 請求先アカウントの請求先アカウント ユーザーのロールのみを財務チームに割り当てます。
- B. 請求先アカウントの請求先アカウント ユーザーのロールのみをエンジニアリング チームに割り当てます。
- C.財務チームに、請求先アカウントに対する請求先アカウント ユーザーの役割と、組織に対するプロジェクト請求マネージャーの役割を割り当てます。
- D.エンジニアリングチームに、請求先アカウントに対する請求先アカウントユーザーの役割と、組織に対するプロジェクト請求マネージャーの役割を割り当てます。
Answer: C
Question 060
クラスタの自動スケーリングが有効になっている Google Kubernetes Engine (GKE) で実行されているアプリケーションがあります。
アプリケーションは TCP エンドポイントを公開します。このアプリケーションのレプリカがいくつかあります。同じリージョンに Compute Engine インスタンスがありますが、gce-network と呼ばれる別の Virtual Private Cloud (VPC) にあり、最初の VPC と IP 範囲が重複していません。このインスタンスは、GKE 上のアプリケーションに接続する必要があります。労力を最小限に抑えたい。
何をするべきでしょうか?
- A.
- 1. GKE で、アプリケーションの Pod をバックエンドとして使用するタイプ LoadBalancer の Service を作成します。
- 2. サービスの externalTrafficPolicy を Cluster に設定します。
- 3. 作成されたロードバランサのアドレスを使用するように Compute Engine インスタンスを構成します。
- B.
- 1. GKE でアプリケーションの Pod をバックエンドとして使用するタイプ NodePort の Service を作成します。
- 2. 各 VPC に 1 つずつ、2 つのネットワーク インターフェースを持つプロキシと呼ばれる Compute Engine インスタンスを作成します。
- 3. このインスタンスで iptables を使用し、トラフィックを gce-network から GKE ノードに転送します。
- 4. gce-network のプロキシのアドレスをエンドポイントとして使用するように Compute Engine インスタンスを構成します。
- C.
- 1. GKE で、アプリケーションの Pod をバックエンドとして使用するタイプ LoadBalancer の Service を作成します。
- 2. このサービスに注釈を追加します: cloud.google.com/load-balancer-type: Internal
- 3. 2 つの VPC を一緒にピア接続します。
- 4. 作成したロードバランサのアドレスを使用するように Compute Engine インスタンスを構成します。
- D.
- 1. GKE で、アプリケーションの Pod をバックエンドとして使用するタイプ LoadBalancer の Service を作成します。
- 2. マネージド インスタンス グループのインスタンスの内部 IP をホワイトリストに登録するロード バランサーに Cloud Armor セキュリティ ポリシーを追加します。
- 3. 作成されたロードバランサのアドレスを使用するように Compute Engine インスタンスを構成します。
Answer: C
Question 061
あなたの組織は監査ログ ファイルを 3 年間保存する必要がある金融会社です。
組織には何百もの Google Cloud プロジェクトがあります。ログ ファイルを保持するための費用対効果の高いアプローチを実装する必要があります。
何をするべきでしょうか?
- A. Cloud Audit から BigQuery にログを保存するシンクへのエクスポートを作成します。
- B. Cloud Audit から Coldline Storage バケットにログを保存するシンクへのエクスポートを作成します。
- C. Logging API を使用してログを Stackdriver ログから BigQuery にコピーするカスタム スクリプトを作成します。
- D. これらのログを Cloud Pub/Sub にエクスポートし、Cloud Dataflow パイプラインを作成してログを Cloud SQL に保存します。
Answer: B
Reference:
–Cloud Audit Logs の概要 | Cloud Logging | Google Cloud
Question 062
レイテンシの影響を受けやすいウェブサイトのために GCP で単一のキャッシュ HTTP リバース プロキシを実行したいと考えています。
この特定のリバース プロキシは CPU をほとんど消費しません。30 GB のメモリ内キャッシュが必要で残りのプロセス用にさらに 2 GB のメモリが必要です。コストを最小限に抑えたいです。
このリバース プロキシをどのように実行する必要がありますか?
- A. 32 GB の容量を持つ Cloud Memorystore for Redis インスタンスを作成します。
- B. Compute Engine で実行し、6 個の vCPU と 32 GB のメモリを備えたカスタム インスタンス タイプを選択します。
- C. コンテナ イメージにパッケージ化し、n1-standard-32 インスタンスをノードとして使用して Kubernetes Engine で実行します。
- D. Compute Engine で実行し、インスタンス タイプ n1-standard-1 を選択して、32 GB の SSD 永続ディスクを追加します。
Answer: A
Question 063
独自のデータ センターのベアメタル サーバでアプリケーションをホストしています。
アプリケーションは Cloud Storage にアクセスする必要があります。ただし、セキュリティ ポリシーにより、アプリケーションをホストするサーバがパブリック IP アドレスを持ったり、インターネットにアクセスしたりできなくなります。Google が推奨する方法に従って、アプリケーションに Cloud Storage へのアクセスを提供する必要があります。
何をするべきでしょうか?
- A.
- 1. nslookup を使用し、storage.googleapis.com の IP アドレスを取得します。
- 2. セキュリティ チームと交渉し、サーバにパブリック IP アドレスを付与できるようにします。
- 3. これらのサーバから storage.googleapis.com の IP アドレスへの下りトラフィックのみを許可します。
- B.
- 1. Cloud VPN を使用し、Google Cloud の Virtual Private Cloud (VPC) への VPN トンネルを作成します。
- 2. この VPC で、Compute Engine インスタンスを作成し、このインスタンスに Squid プロキシ サーバをインストールします。
- 3. そのインスタンスをプロキシとして使用して Cloud Storage にアクセスするようにサーバを構成します。
- C.
- 1. Migrate for Compute Engine (以前の Velostrata) を使用して、これらのサーバを Compute Engine に移行します。
- 2. storage.googleapis.com をバックエンドとして使用する内部ロード バランサー (ILB) を作成します。
- 3. この ILB をプロキシとして使用するように新しいインスタンスを構成します。
- D.
- 1. Cloud VPN または Interconnect を使用して、Google Cloud で VPC へのトンネルを作成します。
- 2. Cloud Router を使用して、199.36.153.4/30 のカスタム ルート アドバタイズメントを作成します。VPN トンネルを介して、そのネットワークをオンプレミス ネットワークにアナウンスします。
- 3. オンプレミス ネットワークで、*.googleapis.com を CNAME として limited.googleapis.com に解決するように DNS サーバを構成します。
Answer: D
Question 064
Cloud Pub/Sub トピックからのメッセージを処理するアプリケーションを Cloud Run にデプロイしたいと考えています。
Google のベストプラクティスに従います。
何をするべきでしょうか?
- A.
- 1. そのトピックで Cloud Pub/Sub トリガーを使用する Cloud Function を作成します。
- 2. メッセージごとに Cloud Function から Cloud Run でアプリケーションを呼び出します。
- B.
- 1. Cloud Run が使用するサービス アカウントに roles/pubsub.subscriber のロールを付与します。
- 2. そのトピックの Cloud Pub/Sub サブスクリプションを作成します。3. アプリケーションがそのサブスクリプションからメッセージをプルするようにします。
- C.
- 1. サービス アカウントを作成します。
- 2. Cloud Run アプリケーションのサービス アカウントに Cloud Run Invoker ロールを付与します。
- 3. そのサービス アカウントを使用し、Cloud Run アプリケーションをプッシュ エンドポイントとして使用する Cloud Pub/Sub サブスクリプションを作成します。
- D.
- 1. 接続を内部に設定して Cloud Run on GKE にアプリケーションをデプロイします。
- 2. そのトピックの Cloud Pub/Sub サブスクリプションを作成します。
- 3. アプリケーションと同じ Google Kubernetes Engine クラスタで、メッセージを受け取ってアプリケーションに送信するコンテナをデプロイします。
Answer: C
Question 065
コンテナ イメージにパッケージ化されたアプリケーションを新しいプロジェクトにデプロイする必要があります。
アプリケーションは HTTP エンドポイントを公開し、1 日に受け取るリクエストはほとんどありません。コストを最小限に抑えたい。
何をするべきでしょうか?
- A. Cloud Run にコンテナをデプロイします。
- B. Cloud Run on GKE にコンテナをデプロイします。
- C. コンテナを App Engine フレキシブルにデプロイします。
- D. クラスタの自動スケーリングと水平ポッドの自動スケーリングを有効にして、コンテナを GKE にデプロイします。
Answer: A
Question 066
あなたの会社には、数百のプロジェクトと請求先アカウントを持つ既存の GCP 組織があります。
会社は最近、何百ものプロジェクトと独自の請求先アカウントを持つ別の会社を買収しました。両方の GCP 組織のすべての GCP 費用を 1 つの請求書に統合したいと考えています。明日の時点ですべてのコストを統合したいと考えています。
何をするべきでしょうか?
- A. 買収した会社のプロジェクトを会社の請求先アカウントにリンクします。
- B. 買収した会社の請求先アカウントと自分の会社の請求先アカウントを構成して、請求データを同じ BigQuery データセットにエクスポートします。
- C. 買収した会社のプロジェクトを会社の GCP 組織に移行します。移行したプロジェクトを会社の請求先アカウントにリンクします。
- D. 新しい GCP 組織と新しい請求先アカウントを作成します。買収した会社のプロジェクトとあなたの会社のプロジェクトを新しい GCP 組織に移行し、プロジェクトを新しい請求先アカウントにリンクします。
Answer: A
Reference:
–プロジェクトの移行 |リソース マネージャーのドキュメント | Google クラウド
Question 067
Cloud Spanner を使用する Google Cloud でアプリケーションを構築しました。
サポート チームは環境を監視する必要がありますが、テーブル データにはアクセスできません。サポート チームに適切な権限を付与する合理化されたソリューションが必要であり、Google が推奨する方法に従いたいと考えています。
何をするべきでしょうか?
- A. サポート チーム グループを roles/monitoring.viewer ロールに追加します。
- B. サポート チーム グループを roles/spanner.databaseUser ロールに追加します。
- C. サポート チーム グループを roles/spanner.databaseReader ロールに追加します。
- D. サポート チーム グループを roles/stackdriver.accounts.viewer ロールに追加します。
Answer: A
Question 068
分析のために、すべての Compute Engine インスタンスのすべてのログを platform-logs という BigQuery データセットに送信する必要があります。
Cloud Logging エージェントはすべてのインスタンスにすでにインストールされています。コストを最小限に抑えたい。
何をするべきでしょうか?
- A.
- 1. プラットフォーム ログ データセットに対する BigQuery データ編集者のロールをインスタンスで使用されるサービス アカウントに付与します。
- 2. インスタンスのメタデータを更新し、logs-destination: bq://platform-logs という値を追加します。
- B.
- 1. Cloud Logging で logs という Cloud Pub/Sub トピックをシンクとしてログ エクスポートを作成します。
- 2. ログ トピック内のメッセージによってトリガーされる Cloud Function を作成します。
- 3. Cloud Function を構成して Compute Engine 以外からのログをドロップし、Compute Engine ログを platform-logs データセットに挿入します。
- C.
- 1. Cloud Logging で Compute Engine のログのみを表示するフィルタを作成します。
- 2. [エクスポートの作成] をクリックします。
- 3. シンク サービスとして BigQuery を選択し、シンク先として platform-logs データセットを選択します。
- D.
- 1. platform-logs データセットに対する BigQuery User ロールを持つ Cloud Function を作成します。
- 2. この Cloud Function を構成して次のクエリを実行する BigQuery ジョブを作成します。
INSERT INTO dataset.platform-logs (timestamp, log) SELECT timestamp, log FROM compute.logs WHERE timestamp > DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY) - 3 . Cloud Scheduler を使用し、この Cloud Function を 1 日 1 回トリガーします。
Answer: C
Question 069
Deployment Manager を使用して Google Kubernetes Engine クラスタを作成しています。
同じ Deployment Manager のデプロイメントを使用してクラスタの kube-system 名前空間内に DaemonSet も作成したいとします。DaemonSet をクラスタの kube-system 名前空間に作成します。可能な限り少ないサービスを使用するソリューションを望んでいます。
何をするべきでしょうか?
- A. Deployment Manager でクラスタの API を新しいタイプ プロバイダとして追加し、新しいタイプを使用して DaemonSet を作成します。
- B. Deployment Manager Runtime Configurator を使用して DaemonSet 定義を含む新しい Config リソースを作成します。
- C. Deployment Manager を使用して kubectl を使用して DaemonSet を作成する起動スクリプトで Compute Engine インスタンスを作成します。
- D. Deployment Manager のクラスタの定義で kube-system をキーとして DaemonSet マニフェストを値として持つメタデータを追加します。
Answer: A
Reference:
–kubectl をインストールしてクラスタ アクセスを構成する | Google Kubernetes エンジン (GKE)
Question 070
データセンターで実行されるアプリケーションを構築しています。
アプリケーションは、AutoML などの Google Cloud Platform (GCP) サービスを使用します。AutoML への適切なアクセス権を持つサービス アカウントを作成しました。オンプレミス環境から API への認証を有効にする必要があります。
何をするべきでしょうか?
- A. オンプレミス アプリケーションでサービス アカウント資格情報を使用します。
- B. gcloud を使用して、適切な権限を持つサービス アカウントのキー ファイルを作成します。
- C. データセンターと Google Cloud Platform 間の直接相互接続をセットアップし、オンプレミス アプリケーションの認証を有効にします。
- D. IAM & 管理コンソールに移動してサービス アカウントのアクセス許可と同様のアクセス許可をユーザー アカウントに付与し、このユーザー アカウントをデータ センターからの認証に使用します。
Answer: B
Reference:
–始める前に | AutoML Vision | Google Cloud
Question 071
あなたは別のプロジェクトで Container Registryを使って会社のコンテナ イメージを一元的に保存しています。
別のプロジェクトで Google Kubernetes Engine (GKE) クラスタを作成したいと考えています。Kubernetes が Container Registry からイメージをダウンロードできるようにしたいと考えています。
何をすべきでしょうか?
- A. イメージが保存されているプロジェクトでストレージ オブジェクト ビューアーの IAM ロールを Kubernetes ノードで使用されるサービス アカウントに付与します。
- B. GKE クラスタを作成するときに [アクセス スコープ] の下の [すべての Cloud API へのフル アクセスを許可する] オプションを選択します。
- C. サービス アカウントを作成し、Cloud Storage へのアクセス権を付与します。このサービス アカウントの P12 キーを作成し、Kubernetes で imagePullSecrets として使用します。
- D. Cloud Storage の各イメージに ACL を構成してデフォルトの Compute Engine サービス アカウントに読み取り専用アクセスを付与します。
Answer: A
Question 072
以下で指定された YAML ファイルを使用して Google Kubernetes Engine クラスタ内に新しいアプリケーションをデプロイしました。

デプロイされたポッドのステータスを確認すると、そのうちの 1 つがまだ PENDING ステータスになっていることがわかります。

Pod が保留中の状態でスタックしている理由を確認したいと考えています。
何をするべきでしょうか?
- A. myapp-service サービス オブジェクトの詳細を確認し、エラー メッセージを確認します。
- B. myapp-deployment Deployment オブジェクトの詳細を確認し、エラー メッセージを確認します。
- C. myapp-deployment-58ddbbb995-lp86m Pod の詳細を確認し、警告メッセージを確認します。
- D. myapp-deployment-58ddbbb995-lp86m ポッドでコンテナのログを表示し、警告メッセージを確認します。
Answer: C
Reference:
–トラブルシューティング | Cloud Run for Anthos
Question 073
Compute Engine で Windows VM をセットアップしており、RDP 経由で VM にログインできることを確認したいと考えています。
何をするべきでしょうか?
- A. VM が作成されたら Google アカウントの資格情報を使用して VM にログインします。
- B. VM が作成されたら gcloud compute reset-windows-password を使用して VM のログイン認証情報を取得します。
- C. VM を作成するときに 「windows-password」をキーとし、パスワードを値として使用してインスタンスにメタデータを追加します。
- D. VM が作成されたらデフォルトの Compute Engine サービス アカウントの JSON 秘密鍵をダウンロードします。JSON ファイルの資格情報を使用して VM にログインします。
Answer: B
Question 074
dev1 グループのユーザーに対して、単一の Compute Engine インスタンスへの SSH 接続を構成したいと考えています。
このインスタンスはこの特定の Google Cloud Platform プロジェクトで dev1 ユーザーが接続できる唯一のリソースです。
何をするべきでしょうか?
- A. インスタンスのメタデータを enable-oslogin=true に設定します。dev1 グループに compute.osLogin ロールを付与します。Cloud Shell を使用してそのインスタンスに ssh するように指示します。
- B. インスタンスのメタデータを enable-oslogin=true に設定します。そのインスタンスのサービス アカウントをサービス アカウントなしに設定します。Cloud Shell を使用してそのインスタンスに ssh するように指示します。
- C. インスタンスのブロック プロジェクト全体のキーを有効にします。dev1 グループの各ユーザーの SSH キーを生成します。キーを dev1 ユーザーに配布し、サードパーティ ツールを使用して接続するように指示します。
- D. インスタンスのブロック プロジェクト全体のキーを有効にします。SSH キーを生成し、キーをそのインスタンスに関連付けます。キーを dev1 ユーザーに配布し、サードパーティ ツールを使用して接続するように指示します。
Answer: A
Reference:
–アクセス方法を選択する | Compute Engine ドキュメント | Google Cloud
Question 075
Cloud Shell で gcloud コマンドラインを使用して GCP プロジェクトで有効な Google Cloud Platform API のリストを作成する必要があります。
プロジェクト名は my-project です。
何をするべきでしょうか?
- A. gcloud projects list を実行してプロジェクト ID を取得してから gcloud services list –project <project ID> を実行します。
- B. gcloud init を実行して現在のプロジェクトを my-project に設定し、gcloud services list –available を実行します。
- C. gcloud info を実行してアカウントの値を表示し、gcloud services list –account <Account> を実行します。
- D. gcloud projects describe <project ID> を実行してプロジェクトの値を確認してから gcloud services list –available を実行します。
Answer: A
Question 076
App Engine 環境でホストされているアプリケーションの新しいバージョンを構築しています。
アプリケーションを新しいバージョンに完全に切り替える前に 1% のユーザーで新しいバージョンをテストしたいと考えています。
何をするべきでしょうか?
- A. アプリケーションの新しいバージョンを App Engine ではなく Google Kubernetes Engine にデプロイし、Google Cloud Console を使用してトラフィックを分割します。
- B. アプリケーションの新しいバージョンを App Engine ではなく Compute Engine インスタンスにデプロイし、Google Cloud Console を使用してトラフィックを分割します。
- C. 新しいバージョンを別のアプリとして App Engine にデプロイします。次に Google Cloud Console を使用して App Engine を構成し、2 つのアプリ間でトラフィックを分割します。
- D. アプリケーションの新しいバージョンを App Engine にデプロイします。次に Google Cloud Console の App Engine 設定に移動し、それに応じて現在のバージョンと新しくデプロイされたバージョンの間でトラフィックを分割します。
Answer: D
Question 077
Kubernetes の Google Cloud 料金計算ツールを使用して Kubernetes クラスタの費用を見積もる必要があります。
ワークロードには高い IOP が必要であり、ディスク スナップショットも使用します。まず、ノード数、平均時間、平均日数を入力します。
次に何をすべきでしょうか?
- A. ローカル SSD を入力します。永続ディスク ストレージとスナップショット ストレージを入力します。
- B. ローカル SSD を入力します。クラスタ管理の推定コストを追加します。
- C. [GPU の追加] を選択します。永続ディスク ストレージとスナップショット ストレージを入力します。
- D. [GPU の追加] を選択します。クラスタ管理の推定コストを追加します。
Answer: A
Reference:
–Google Cloud 料金計算ツール
Question 078
新しいアプリケーションをホストするために自動スケーリングを有効にした Google Kubernetes Engine を使用しています。
パブリック IP アドレスで HTTPS を使用し、この新しいアプリケーションをパブリックに公開したいと考えています。
何をするべきでしょうか?
- A. アプリケーション用にタイプ NodePort の Kubernetes Service を作成し、Cloud Load Balancer を介してこの Service を公開する Kubernetes Ingress を作成します。
- B. アプリケーション用にタイプ ClusterIP の Kubernetes Service を作成します。このサービスの IP を使用して、アプリケーションのパブリック DNS 名を構成します。
- C. タイプ NodePort の Kubernetes Service を作成し、Kubernetes クラスタの各ノードのポート 443 でアプリケーションを公開します。アプリケーションのパブリック DNS 名をクラスタのすべてのノードの IP で構成して負荷分散を実現します。
- D. クラスタ内に HAProxy ポッドを作成し、アプリケーションのすべてのポッドへのトラフィックを負荷分散します。iptables ルールを使用し、パブリック トラフィックを HAProxy に転送します。HAProxy が実行されているノードのパブリック IP を使用し、アプリケーションの DNS 名を構成します。
Answer: A
Reference:
–Ingress で HTTP(S) ロード バランシングを設定する | Kubernetes Engine | Google Cloud
Question 079
現在 2 つの異なる GCP プロジェクトを実行している Compute Engine インスタンスの複数のグループ間のトラフィックを有効にする必要があります。
Compute Engine インスタンスの各グループは独自の VPC で実行されます。
何をするべきでしょうか?
- A. 両方のプロジェクトが GCP 組織にあることを確認します。新しい VPC を作成し、すべてのインスタンスを追加します。
- B. 両方のプロジェクトが GCP 組織にあることを確認します。1 つのプロジェクトから VPC を共有し、他のプロジェクトの Compute Engine インスタンスがこの共有 VPC を使用するようにリクエストします。
- C. 両方のプロジェクトのプロジェクト管理者であることを確認します。2 つの新しい VPC を作成し、すべてのインスタンスを追加します。
- D. 両方のプロジェクトのプロジェクト管理者であることを確認します。新しい VPC を作成し、すべてのインスタンスを追加します。
Answer: B
Question 080
Google Cloud Platform プロジェクトに新しい監査人を追加したいと考えています。
監査人はすべてのプロジェクト アイテムを読み取ることはできますが、変更することはできません。
監査人の権限をどのように構成する必要がありますか?
- A. 表示のみのプロジェクト権限を持つカスタムロールを作成します。ユーザーのアカウントをカスタムロールに追加します。
- B. 表示のみのサービス権限を持つカスタムロールを作成します。ユーザーのアカウントをカスタムロールに追加します。
- C. 事前定義の IAM project Viewer ロールを選択します。ユーザーのアカウントをこのロールに追加します。
- D. 事前定義の IAM service Viewer ロールを選択します。ユーザーのアカウントをこのロールに追加します。
Answer: C
Reference:
–IAM を使用したプロジェクトのアクセス制御 | Resource Manager のドキュメント | Google Cloud
Question 081
あなたは会社の Google Kubernetes Engine (GKE) クラスタを運用しており、さまざまなチームが非本番環境のワークロードを実行できます。
機械学習 (ML) チームはモデルをトレーニングするために Nvidia Tesla P100 GPU にアクセスする必要があります。労力とコストを最小限に抑えたいと考えています。
何をするべきでしょうか?
- A. ML チームに accelerator: gpu アノテーションを Pod 仕様に追加するよう依頼します。
- B. GKE クラスタのすべてのノードを再作成し、すべてのノードで GPU を有効にします。
- C. GPU を備えたノードを使用し、Compute Engine の上に独自の Kubernetes クラスタを作成します。このクラスタを ML チーム専用にします。
- D. GPU 対応の新しいノード プールを GKE クラスタに追加します。ML チームに、cloud.google.com/gke -accelerator: nvidia-tesla-p100 nodeSelector を Pod 仕様に追加するよう依頼します。
Answer: D
Question 082
VM は 255.255.255.240 のサブネット マスクを持つサブネットで実行されています。
現在のサブネットには空き IP アドレスがなくなり、新しい VM 用に追加の 10 個の IP アドレスが必要になります。既存の VM と新しい VM はすべてルートを追加しなくても相互に到達できる必要があります。
何をするべきでしょうか?
- A. gcloud を使用し、現在のサブネットの IP 範囲を拡張します。
- B. サブネットを削除し、より広い範囲の IP アドレスを使用してサブネットを再作成します。
- C. 新しいプロジェクトを作成します。共有 VPC を使用し、現在のネットワークを新しいプロジェクトと共有します。
- D. 同じ開始 IP で新しいサブネットを作成しますが現在のサブネットを上書きする範囲を広げます。
Answer: A
Question 083
あなたの組織ではコミュニケーションとコラボレーションに G Suite を使用しています。
組織内のすべてのユーザーが G Suite アカウントを持っています。一部の G Suite ユーザーに Cloud Platform プロジェクトへのアクセスを許可したいと考えています。
何をするべきでしょうか?
- A. ドメインの Google Cloud Console で Cloud Identity を有効にします。
- B. G Suite メールアドレスを使用し、必要な IAM ロールを付与します。
- C. すべてのユーザーのメールアドレスを含む CSV シートを作成します。gcloud コマンドライン ツールを使用し、それらを Google Cloud Platform アカウントに変換します。
- D. G Suite コンソールで cloud-console-users@yourdomain.com という特別なグループにユーザーを追加します。ユーザーがこのグループのメンバーである場合、Cloud Platform のデフォルトの動作に依存し、ユーザー アクセスを許可します。
Answer: B
Reference:
–組織の作成と管理 | Resource Manager のドキュメント | Google Cloud
Question 084
本番プロジェクトと開発プロジェクトの両方にアクセスできる Google Cloud Platform アカウントを持っています。
開発プロジェクトと運用プロジェクトのすべてのコンピューティング インスタンスを毎日一覧表示する自動化されたプロセスを作成する必要があります。
何をするべきでしょうか?
- A. gcloud config を使用して 2 つの構成を作成します。構成を個別にアクティブとして設定するスクリプトを作成します。構成ごとに gcloud compute instances list を使用してコンピューティング リソースのリストを取得します。
- B. gsutil config を使用して 2 つの構成を作成します。構成を個別にアクティブとして設定するスクリプトを作成します。構成ごとに gsutil コンピューティング インスタンス リストを使用し、コンピューティング リソースのリストを取得します。
- C. Cloud Shell に移動し、この情報を Cloud Storage に毎日エクスポートします。
- D. Google Cloud Console に移動し、この情報を Cloud SQL に毎日エクスポートします。
Answer: A
Question 085
5 TB の大きな AVRO ファイルが Cloud Storage バケットに保存されています。
アナリストは SQL のみに精通しており、このファイルに保存されているデータにアクセスする必要があります。できるだけ早く要求を完了するための費用対効果の高い方法を見つけたいと考えています。
何をするべきでしょうか?
- A. Datastore にデータをロードし、それに対して SQL クエリを実行します。
- B. BigQuery テーブルを作成し、BigQuery にデータを読み込みます。このテーブルで SQL クエリを実行し、要求が完了したらこのテーブルを削除します。
- C. Cloud Storage バケットを指す BigQuery で外部テーブルを作成し、これらの外部テーブルで SQL クエリを実行してリクエストを完了します。
- D. Hadoop クラスタを作成し、AVRO ファイルを圧縮して NDFS にコピーします。ファイルをハイブ テーブルにロードし、アナリストが SQL クエリを実行できるようにアクセスできるようにします。
Answer: C
Question 086
Google Cloud Platform サービス アカウントが特定の時点で作成されたことを確認する必要があります。
何をするべきでしょうか?
- A. アクティビティ ログをフィルタリングして構成カテゴリを表示します。リソースの種類をサービス アカウントにフィルタします。
- B. アクティビティ ログをフィルタリングして構成カテゴリを表示します。リソースの種類を Google プロジェクトにフィルタします。
- C. アクティビティ ログをフィルタリングしてデータ アクセス カテゴリを表示します。リソースの種類をサービス アカウントにフィルタします。
- D. アクティビティ ログをフィルタリングしてデータ アクセス カテゴリを表示します。リソースの種類を Google プロジェクトにフィルタします。
Answer: A
Question 087
UDP を使用してポート 636 経由で TLS 経由で到達可能な LDAP サーバを Compute Engine にデプロイしました。
そのポートを介してクライアントが到達できることを確認する必要があります。
何をするべきでしょうか?
- A. LDAP サーバを実行している VM インスタンスにネットワーク タグ allow-udp-636 を追加します。
- B. allow-udp-636 というルートを作成し、ネクスト ホップを LDAP サーバを実行する VM インスタンスに設定します。
- C. 選択したネットワーク タグをインスタンスに追加します。そのネットワーク タグの UDP ポート 636 でのイングレスを許可するファイアウォール ルールを作成します。
- D. LDAP サーバを実行しているインスタンスに選択したネットワーク タグを追加します。そのネットワーク タグの UDP ポート 636 での送信を許可するファイアウォール ルールを作成します。
Answer: C
Question 088
管理している 3 つの Google Cloud Platform プロジェクトのいずれかで Compute Engine サービスを使用するには予算アラートを設定する必要があります。
3 つのプロジェクトはすべて 1 つの請求先アカウントにリンクされています。
何をするべきでしょうか?
- A. プロジェクト請求管理者であることを確認します。関連する請求先アカウントを選択し、適切なプロジェクトの予算とアラートを作成します。
- B. プロジェクト請求管理者であることを確認します。関連する請求先アカウントを選択し、予算とカスタム アラートを作成します。
- C. プロジェクト管理者であることを確認します。関連する請求先アカウントを選択し、適切なプロジェクトの予算を作成します。
- D. プロジェクト管理者であることを確認します。関連する請求先アカウントを選択し、予算とカスタム アラートを作成します。
Answer: A
Question 089
タスクを実行するために 96 個の vCPU を必要とする本番環境に不可欠なオンプレミス アプリケーションを移行しています。
アプリケーションが GCP 上の同様の環境で実行されることを確認したいと考えています。
何をするべきでしょうか?
- A. VM を作成するときはマシン タイプ n1-standard-96 を使用します。
- B. VM を作成するときは Intel Skylake を CPU プラットフォームとして使用します。
- C. Compute Engine のデフォルト設定を使用して VM を作成します。gcloud を使用して実行中のインスタンスを 96 個の vCPU を持つように変更します。
- D. Compute Engine のデフォルト設定を使用して VM を起動し、Rightizing Recommendations に基づいて適宜調整します。
Answer: A
Question 090
Cloud Storage バケットにデータをアーカイブするためのソリューションを構成したいと考えています。
ソリューションは費用対効果が高くなければなりません。複数のバージョンを持つデータは、30 日後にアーカイブする必要があります。以前のバージョンは、レポートのために月に 1 回アクセスされます。このアーカイブ データも、月末に不定期に更新されます。
何をするべきでしょうか?
- A. 30 日後に最新バージョンのデータを Coldline ストレージにアーカイブするバケット ライフサイクル ルールを追加します。
- B. データを新しいバージョンで 30 日後に Nearline ストレージにアーカイブするバケット ライフサイクル ルールを追加します。
- C. 30 日後に Regionalストレージから Coldline ストレージにデータをアーカイブするバケット ライフサイクル ルールを追加します。
- D. 30 日後に Regional ストレージから Nearline ストレージにデータをアーカイブするバケット ライフサイクル ルールを追加します。
Answer: B
Reference:
–オブジェクト ライフサイクルを管理する | Cloud Storage | Google Cloud
Question 091
会社のインフラストラクチャはオンプレミスですが、すべてのマシンが最大容量で稼働している。
あなたはGoogle Cloudにバーストさせたいと考えています。Google Cloud上のワークロードはプライベート IP 範囲を使用してオンプレミスのワークロードに直接通信できる必要があります。
何をするべきでしょうか?
- A. Google Cloud で VPC を共有 VPC のホストとして構成します。
- B. Google Cloud で VPC ネットワーク ピアリング用に VPC を構成します。
- C. オンプレミス環境と Google Cloud の両方で踏み台インスタンスを作成します。パブリック IP アドレスを使用して、両方をプロキシ サーバとして構成します。
- D. オンプレミスのインフラストラクチャと Google Cloud の間に Cloud VPN を設定します。
Answer: D
Question 092
Google Cloud Platform でデータを保存、アーカイブするためのソリューションを選択して構成したいと考えています。
1 つの地理的な場所からのデータのコンプライアンス目標をサポートする必要があります。このデータは 30 日後にアーカイブされ、毎年アクセスする必要があります。
何をするべきでしょうか?
- A. Multi-Regional ストレージを選択します。30 日後に Coldline ストレージにデータをアーカイブするバケット ライフサイクル ルールを追加します。
- B. Multi-Regional ストレージを選択します。30 日後にデータを Nearline ストレージにアーカイブするバケット ライフサイクル ルールを追加します。
- C. Regional ストレージを選択します。30 日後にデータを Nearline ストレージにアーカイブするバケット ライフサイクル ルールを追加します。
- D. 地域ストレージを選択します。30 日後にデータを Coldline ストレージにアーカイブするバケット ライフサイクル ルールを追加します。
Answer: D
Question 093
あなたの会社ではデータ ウェアハウジングに BigQuery を使用しています。
時間の経過とともに会社のさまざまなビジネス ユニットが数百のプロジェクトにわたって 1,000 以上のデータセットを作成してきました。CIO はすべてのデータセットを調べて、employee_ssn 列を含むテーブルを見つけるように求めています。このタスクを実行する労力を最小限に抑えたいと考えています。
何をするべきでしょうか?
- A. Data Catalog に移動し、検索ボックスで employee_ssn を検索します。
- B. bq コマンドライン ツールを使用して組織内のすべてのプロジェクトをループするシェル スクリプトを作成します。
- C. 組織内のすべてのプロジェクトをループし、INFORMATION_SCHEMA.COLUMNS ビューでクエリを実行して employee_ssn 列を見つけるスクリプトを作成します。
- D. 組織内のすべてのプロジェクトをループし、INFORMATION_SCHEMA.COLUMNS ビューでクエリを実行して employee_ssn 列を見つける Cloud Dataflow ジョブを作成します。
Answer: A
Question 094
1 つのプリエンプティブル ノード プールを持つ Google Kubernetes Engine クラスタに 2 つのレプリカを持つ Deployment を作成します。
数分後、kubectl を使用して Pod のステータスを調べ、そのうちの 1 つがまだ Pending ステータスであることを確認します。

最も可能性の高い原因は何ですか?
- A. 保留中の Pod のリソース リクエストが大きすぎて、クラスタの 1 つのノードに収まりません。
- B. クラスタですでに実行されている Pod が多すぎて、保留中の Pod をスケジュールするのに十分なリソースが残っていません。
- C. ノード プールが保留中の Pod によって使用されるコンテナ イメージを pull する権限を持たないサービス アカウントで構成されています。
- D. 保留中の Pod は当初、Deployment の作成と Pod のステータスの確認の間にプリエンプトされたノードでスケジュールされていました。現在、新しいノードで再スケジュールされています。
Answer: D
Question 095
Google Cloud Platform (GCP) プロジェクトの Cloud Spanner Identity Access Management (IAM) ロールにユーザーがいつ追加されたかを確認したいと考えています。
Google Cloud Console で何をする必要がありますか?
- A. Cloud Spanner コンソールを開いて構成を確認します。
- B. IAM と管理コンソールを開き、Cloud Spanner ロールの IAM ポリシーを確認します。
- C. Stackdriver Monitoring コンソールに移動し、Cloud Spanner の情報を確認します。
- D. Stackdriver Logging コンソールに移動し、管理者のアクティビティ ログを確認して Cloud Spanner IAM ロールでフィルタリングします。
Answer: D
Question 096
あなたの会社はエンタープライズ データ ウェアハウスとして BigQuery を実装しました。
複数のビジネス ユニットのユーザーが、このデータ ウェアハウスでクエリを実行します。ただし、BigQuery のクエリ費用が非常に高く、費用を管理する必要があることに気付きました。
どの 2 つの方法を使用する必要がありますか? (2つ選んでください。)
- A. ユーザーをビジネス ユニットから複数のプロジェクトに分割します。
- B. BigQuery データ ウェアハウスにユーザー レベルまたはプロジェクト レベルのカスタム クエリ クォータを適用します。
- C. ビジネス ユニットごとに BigQuery データ ウェアハウスの個別のコピーを作成します。
- D. BigQuery データ ウェアハウスをビジネス ユニットごとに複数のデータ ウェアハウスに分割します。
- E. BigQuery クエリ モデルをオンデマンドから定額に変更します。各プロジェクトに適切な数のスロットを適用します。
Answer: B、E
Question 097
あなたは Google Kubernetes Engine (GKE) 上に製品を構築しています。
単一の GKE クラスタがあります。顧客ごとにそのクラスタで Pod が実行されており、顧客は Pod 内で任意のコードを実行できます。顧客のポッド間の分離を最大化する必要があります。
何をするべきでしょうか?
- A. Binary Authorization を使用して顧客の Pod で使用されるコンテナ イメージのみをホワイトリストに登録します。
- B. Container Analysis API を使用して顧客のポッドで使用されるコンテナの脆弱性を検出します。
- C. gvisor に構成されたサンドボックス タイプで GKE ノード プールを作成します。パラメータ runtimeClassName: gvisor を顧客の Pod の仕様に追加します。
- D. GKE ノードに cos_containerd イメージを使用します。値が cloud.google.com/gke-os-distribution: cos_containerd の nodeSelector を顧客の Pod の仕様に追加します。
Answer: C
Reference:
–Kubernetes – Google Kubernetes Engine(GKE) | Google Cloud
Question 098
顧客は Cloud Spanner を使用するソリューションを実装しましたが 1 つのテーブルでレイテンシに関連するパフォーマンスの問題に気づきました。
このテーブルには主キーを使用してユーザーのみがアクセスできます。テーブル スキーマを以下に示します。

問題を解決したい。
何をするべきでしょうか?
- A. テーブルから profile_picture フィールドを削除します。
- B. person_id 列にセカンダリ インデックスを追加します。
- C. 値が単調に増加しないように主キーを変更します。
- D. 次のデータ定義言語 (DDL) を使用してセカンダリ インデックスを作成します。
CREATE INDEX person_id_ix
ON Persons (
person_id,
firstname,
lastname
) STORING (
profile_picture
)
Answer: C
Question 099
財務チームはプロジェクトの請求レポートを表示したいと考えています。
財務チームがプロジェクトへの追加の権限を取得しないようにする必要があります。
何をするべきでしょうか?
- A. 財務チームのグループを roles/billing.user のロールに追加します。
- B. 財務チームのグループを roles/billing.admin のロールに追加します。
- C. 財務チームのグループを roles/billing.viewer のロールに追加します。
- D.財務チームのグループを roles/billing.projectManager のロールに追加します。
Answer: C
Question 100
あなたの組織には Google Cloud プロジェクトへのアクセスを制御するための厳格な要件があります。
サイト信頼性エンジニアリング (SRE) がサポートケースを開いたときに Google Cloud サポート チームからのリクエストを承認できるようにする必要があります。Google のベストプラクティスに従います。
何をするべきでしょうか?
- A. SRE を roles/iam.roleAdmin のロールに追加します。
- B. SRE を roles/accessapproval.approver のロールに追加します。
- C. SRE をグループに追加し、このグループを roles/iam.roleAdmin のロールに追加します。
- D. SRE をグループに追加し、このグループを roles/accessapproval.approver のロールに追加します。
Answer: D
Question 101
他のチームと共有するプロジェクトの Compute Engine インスタンスでアプリケーションをホストする必要があります。
他のチームがそのアプリケーションで誤ってダウンタイムを引き起こさないようにしたいと考えています。
どの機能を使用する必要がありますか?
- A. Shielded VM を使用します。
- B. プリエンプティブル VM を使用します。
- C. 単一テナント ノードを使用します。
- D. インスタンスで削除保護を有効にします。
Answer: D
Question 102
組織は BigQuery のクエリ データセットへのアクセス権をユーザーに付与する必要がありますがユーザーが誤ってデータセットを削除しないようにする必要があります。
Google が推奨する方法に従うソリューションが必要です。
何をするべきでしょうか?
- A. roles/bigquery.dataOwner の代わりに roles/bigquery.user のロールのみにユーザーを追加します。
- B. roles/bigquery.dataOwner の代わりに roles/bigquery.dataEditor のロールのみにユーザーを追加します。
- C. 削除権限を削除してカスタムロールを作成し、そのロールにのみユーザーを追加します。
- D. 削除権限を削除して、カスタムロールを作成します。ユーザーをグループに追加してからグループをカスタムロールに追加します。
Answer: D
Question 103
Ubuntu に Cloud SDK がインストールされた開発者用ラップトップがあります。
Cloud SDK は Google Cloud Ubuntu パッケージ リポジトリからインストールされました。Datastore を使用してラップトップでローカルにアプリケーションをテストしたいと考えています。
何をするべきでしょうか?
- A. gcloud datastore export を使用し、Datastore データをエクスポートします。
- B. gcloud datastore indexes create を使用し、Datastore インデックスを作成します。
- C. apt get install コマンドを使用して、google-cloud-sdk-datastore-emulator コンポーネントをインストールします。
- D. gcloud components install コマンドを使用し、cloud-datastore-emulator コンポーネントをインストールします。
Answer: C
Question 104
あなたの会社は Google Cloud 上に複雑な組織構造を設定しました。
この構造には何百ものフォルダとプロジェクトが含まれています。少数のチーム メンバーのみが階層構造を表示できるようにする必要があります。これらのチーム メンバーに最小限の権限を割り当てる必要があり、Google のベストプラクティスに従います。
何をするべきでしょうか?
- A. ユーザーを roles/browser のロールに追加します。
- B. ユーザーを roles/iam.roleViewer のロールに追加します。
- C. ユーザーをグループに追加し、このグループをロール/ブラウザーに追加します。
- D. ユーザーをグループに追加し、このグループを roles/iam.roleViewer ロールに追加します。
Answer: C
Question 105
あなたの会社にはサービス プロバイダとの Security Assertion Markup Language (SAML) 統合をサポートするシングル サインオン (SSO) ID プロバイダがあります。
あなたの会社には Cloud Identity のユーザーがいます。会社の SSO プロバイダを使用してユーザーを認証する必要があります。
何をするべきでしょうか?
- A. Cloud Identity で Google を ID プロバイダとして SSO を設定し、カスタム SAML アプリにアクセスします。
- B. Cloud Identity で Google をサービス プロバイダとするサードパーティの ID プロバイダで SSO を設定します。
- C. OAuth 2.0 資格情報を取得してユーザーの同意画面を構成し、モバイル & デスクトップ アプリ用に OAuth 2.0 をセットアップします。
- D. OAuth 2.0 資格情報を取得してユーザー同意画面を構成し、Web サーバ アプリケーション用に OAuth 2.0 をセットアップします。
Answer: B
Question 106
あなたの組織には Google Cloud プロジェクトのすべてのサービス アカウントを作成して管理する専任の担当者がいます。
この人にプロジェクトの最小限の役割を割り当てる必要があります。
何をするべきでしょうか?
- A. ユーザーを roles/iam.roleAdmin のロールに追加します。
- B. ユーザーを roles/iam.securityAdmin のロールに追加します。
- C. ユーザーを roles/iam.serviceAccountUser のロールに追加します。
- D. ユーザーを roles/iam.serviceAccountAdmin のロールに追加します。
Answer: D
Question 107
あなたはデータ ウェアハウスのアーカイブ ソリューションを構築しており、データをアーカイブするために Cloud Storage を選択しています。
一部の規制要件では四半期に 1 回、ユーザーがこのアーカイブ データにアクセスできる必要があります。費用対効果の高いオプションを選択したい。
どのストレージ オプションを使用する必要がありますか?
- A. Coldline ストレージ
- B. Nearline ストレージ
- C. Regional ストレージ
- D. Multi-Regional ストレージ
Answer: B
Nearline、Coldline、Archive は超低コスト、高耐久性、高可用性のアーカイブ ストレージを提供します。アクセス頻度が年に 1 回未満のデータの場合、アーカイブはデータを長期保存するための費用対効果の高いストレージ オプションです。また、Coldline はビジネスで四半期に 1 回未満しか触れないと予想されるコールド ストレージ データにも最適です。ウォーム ストレージの場合は、Nearline を選択します。月に 1 回未満のアクセスが予想されるデータですが年間を通じて複数回アクセスする可能性があります。すべてのストレージ クラスがすべての GCP リージョンで利用可能で一貫した API により比類のない 1 秒未満のアクセス速度を提供します。
Reference:
–Cloud Storage | Google Cloud
Question 108
データ サイエンティストのチームが、管理している Google Kubernetes Engine (GKE) クラスタを使用する必要が生じることはまれです。
一部の長時間実行され、再起動できないジョブには GPU が必要でコストを最小限に抑えたいです。
何をするべきでしょうか?
- A. GKE クラスタでノードの自動プロビジョニングを有効にします。
- B. これらのワークロード用の VerticalPodAutscaler を作成します。
- C. プリエンプティブル VM と GPU がそれらの VM に接続されたノード プールを作成します。
- D. GPU を使用してインスタンスのノード プールを作成し、このノード プールで最小サイズ 1 の自動スケーリングを有効にします。
Answer: A
Reference:
–GKE Standard ノードプールで GPU を実行 | Google Kubernetes エンジン (GKE)
Question 109
組織は Active Directory にユーザー ID を持っています。
あなたの組織は ID の信頼できる情報源として Active Directory を使用したいと考えています。あなたの組織は、Google Cloud Platform (GCP) 組織を含むすべての Google サービスで従業員が使用する Google アカウントを完全に制御したいと考えています。
何をするべきでしょうか?
- A. Google Cloud Directory Sync (GCDS) を使用し、ユーザーを Cloud Identity に同期します。
- B. Cloud Identity API を使用してスクリプトを記述し、ユーザーを Cloud Identity に同期します。
- C. Active Directory からユーザーを CSV としてエクスポートし、管理コンソールを介して Cloud Identity にインポートします。
- D. 各従業員にセルフ サインアップを使用して Google アカウントを作成するよう依頼します。各従業員は会社のメール アドレスとパスワードを使用する必要があります。
Answer: A
Reference:
–Google Cloud と Active Directory の連携 | ID とアクセス管理
Question 110
アプリケーションのプロジェクト開発環境が正常に作成されました。
このアプリケーションは Compute Engine と Cloud SQL を使用します。次にこのアプリケーションの運用環境を作成する必要があります。セキュリティ チームはこれら 2 つの環境間のネットワーク ルートの存在を禁止しており、Google が推奨する方法に従うように求めています。
何をするべきでしょうか?
- A. 新しいプロジェクトを作成し、そのプロジェクトで Compute Engine と Cloud SQL API を有効にして開発環境で作成したセットアップを複製します。
- B. 既存の VPC に新しい本番サブネットを作成し、既存のプロジェクトに新しい本番 Cloud SQL インスタンスを作成してそれらのリソースを使用してアプリケーションをデプロイします。
- C. 新しいプロジェクトを作成し、既存の VPC を共有 VPC に変更し、その VPC を新しいプロジェクトと共有して共有 VPC の新しいプロジェクトで開発環境にある設定を複製します。
- D.セキュリティチームに会社の別の部門で使用されている既存の本番プロジェクトでのプロジェクト編集者の役割を付与するよう依頼します。そのロールが付与されたら、そのプロジェクトの開発環境にある設定を複製します。
Answer: A
Question 111
経営陣は特定のプロジェクトのすべてのリソースをレビューするよう外部監査人に依頼しました。
セキュリティ チームは Cloud Identity ドメインのみを指定することにより、組織ノードで Domain Restricted Sharing と呼ばれる組織ポリシーを有効にしました。監査人がそのプロジェクト内のリソースを表示できるだけで、変更できないようにする必要があります。
何をするべきでしょうか?
- A. 監査人に Google アカウントを取得してもらい、プロジェクトの閲覧者の役割を付与します。
- B. 監査人に Google アカウントを取得してもらい、プロジェクトのセキュリティ レビュー担当者の役割を与えます。
- C. Cloud Identity で監査者用の一時的なアカウントを作成し、そのアカウントにプロジェクトの閲覧者の役割を付与します。
- D. Cloud Identity で監査者用の一時的なアカウントを作成し、そのアカウントにプロジェクトのセキュリティ レビュー担当者の役割を付与します。
Answer: C
Question 112
ビジネスにとって重要なワークロードを Compute Engine で実行しています。
このワークロードのブート ディスク上のデータが定期的にバックアップされるようにしたいと考えています。災害が発生した場合に備えて、できるだけ早くバックアップを復元できる必要があります。また、コストを節約するために、古いバックアップを自動的に消去することも必要です。Google のベストプラクティスに従います。
何をするべきでしょうか?
- A. Cloud Function を作成し、インスタンス テンプレートを作成します。
- B. 目的の間隔を使用し、ディスクのスナップショット スケジュールを作成します。
- C. gcloud を使用し、ディスクから新しいディスクを作成する cron ジョブを作成します。
- D. Cloud Task を作成して画像を作成し、それを Cloud Storage にエクスポートします。
Answer: B
Question 113
Cloud Identity and Access Management (Cloud IAM) の役割を外部監査人に割り当てる必要があります。
監査人は、Google Cloud Platform (GCP) 監査ログを確認する権限と、データ アクセス ログを確認する権限を持っている必要があります。
何をするべきでしょうか?
- A. 監査人に IAM ロールの roles/logging.privateLogViewer を割り当てます。Cloud Storage へのログのエクスポートを実行します。
- B. 監査人に IAM ロールの roles/logging.privateLogViewer を割り当てます。監査人に、Cloud IAM ポリシーの変更についてログも確認するよう指示します。
- C. 監査人の IAM ユーザーを logging.privateLogEntries.list 権限を持つカスタムロールに割り当てます。Cloud Storage へのログのエクスポートを実行します。
- D. 監査人の IAM ユーザーを logging.privateLogEntries.list 権限を持つカスタムロールに割り当てます。監査人に Cloud IAM ポリシーの変更についてログも確認するよう指示します。
Answer: B
Question 114
あなたは複数の Google Cloud Platform (GCP) プロジェクトを管理しており、過去 60 日間のすべてのログにアクセスする必要があります。
ログの内容を調べてすばやく分析できるようにしたいと考えています。Google が推奨する方法に従って、すべてのプロジェクトの結合ログを取得する必要があります。
何をするべきでしょうか?
- A. Stackdriver Logging に移動し、resource.labels.project_id=”*” を選択します。
- B. BigQuery データセットへのシンクの宛先を指定して Stackdriver Logging エクスポートを作成します。テーブルの有効期限を 60 日に設定します。
- C. Cloud Storage へのシンクの宛先を持つ Stackdriver Logging エクスポートを作成します。60 日後にオブジェクトを削除するライフサイクル ルールを作成します。
- D. Cloud Scheduler ジョブを構成して Stackdriver から読み取り、ログを BigQuery に保存します。テーブルの有効期限を 60 日に設定します。
Answer: B
Reference:
–Cloud Audit Logging 活用のベスト プラクティス | Google Cloud 公式ブログ
Question 115
可能な限り少ない手順で会社の部門の GCP サービス コストを削減する必要があります。
既存の GCP プロジェクトで構成されているすべてのサービスをオフにする必要があります。
何をするべきでしょうか?
- A.
- 1. このプロジェクトの Project Owners IAM ロールが割り当てられていることを確認します。
- 2. Google Cloud Console でプロジェクトを見つけ、[Shut down] をクリックしてプロジェクト ID を入力します。
- B.
- 1. このプロジェクトの Project Owners IAM ロールが割り当てられていることを確認します。
- 2. Google Cloud Console でプロジェクトに切り替え、リソースを見つけて削除します。
- C.
- 1. このプロジェクトの組織管理者 IAM ロールが割り当てられていることを確認します。
- 2. Google Cloud Console でプロジェクトを見つけ、プロジェクト ID を入力して [Shut down] をクリックします。
- D.
- 1. このプロジェクトの組織管理者 IAM ロールが割り当てられていることを確認します。
- 2. Google Cloud Console でプロジェクトに切り替え、リソースを見つけて削除します。
Answer: A
Question 116
複数のプロジェクトにまたがるアプリケーションのサービス アカウントを構成しています。
ウェブ アプリケーション プロジェクトで実行されている仮想マシン (VM) は crm-databases-proj の BigQuery データセットにアクセスする必要があります。Google が推奨する方法に従って Web アプリケーション プロジェクトのサービス アカウントへのアクセスを許可する必要があります。
何をするべきでしょうか?
- A. Web アプリケーションのプロジェクト オーナーに適切なロールを crm-databases-proj に付与します。
- B. プロジェクト所有者の役割を crm-databases-proj と web-applications プロジェクトに付与します。
- C. プロジェクト所有者の役割を crm-databases-proj に bigquery.dataViewer の役割を Web アプリケーションに付与します。
- D. bigquery.dataViewer ロールを crm-databases-proj に付与し、適切なロールを Web アプリケーションに付与します。
Answer: D
Reference:
–Cloud Audit Logging 活用のベスト プラクティス | Google Cloud 公式ブログ
Question 117
ある従業員が解雇されましたが Google Cloud へのアクセス権は 2 週間後まで削除されませんでした。
この従業員が退職後に顧客の機密情報にアクセスしたかどうかを確認する必要があります。
何をするべきでしょうか?
- A. Cloud Logging でシステム イベント ログを表示します。ユーザーのメールをプリンシパルとして検索します。
- B. Cloud Logging でシステム イベント ログを表示します。ユーザーに関連付けられたサービス アカウントを検索します。
- C. Cloud Logging でデータアクセス監査ログを表示します。ユーザーのメールをプリンシパルとして検索します。
- D. Cloud Logging で管理アクティビティ ログを表示します。ユーザーに関連付けられたサービス アカウントを検索します。
Answer: C
Question 118
GCP サービスで使用するカスタム IAM ロールを作成する必要があります。
ロールのすべての権限は本番環境での使用に適している必要があります。また、カスタムロールのステータスを組織と明確に共有したいと考えています。これは、カスタムロールの最初のバージョンになります。
何をするべきでしょうか?
- A. 役割のアクセス許可に「サポートされている」サポート レベルを使用する役割のアクセス許可を使用します。ロール権限のテスト中に、ロール ステージを ALPHA に設定します。
- B. 役割のアクセス許可に「サポートされている」サポート レベルを使用する役割のアクセス許可を使用します。ロールの権限をテストする際に、ロール ステージを BETA に設定します。
- C. 役割のアクセス許可に「テスト」サポート レベルを使用する役割のアクセス許可を使用します。ロール権限のテスト中に、ロール ステージを ALPHA に設定します。
- D. 役割のアクセス許可に「テスト」サポート レベルを使用する役割のアクセス許可を使用します。ロールの権限をテストする際に、ロール ステージを BETA に設定します。
Answer: A
Question 119
会社にはさまざまなファイル形式の大量の非構造化データがあります。
データに対して ETL 変換を実行したいと考えています。Dataflow ジョブで処理できるように Google Cloud でデータにアクセスできるようにする必要があります。
何をするべきでしょうか?
- A. bq コマンドライン ツールを使用してデータを BigQuery にアップロードします。
- B. gsutil コマンドライン ツールを使用して Cloud Storage にデータをアップロードします。
- C. コンソールのインポート機能を使用してデータを Cloud SQL にアップロードします。
- D. コンソールのインポート機能を使用して Cloud Spanner にデータをアップロードします。
Answer: B
Reference:
–Dataflow を使用してリレーショナル データベースから BigQuery に ETL を実行する | Cloud アーキテクチャ センター | Google Cloud
Question 120
できるだけ少ない手順で複数の Google Cloud プロジェクトを管理する必要があります。
複数のプロジェクトを簡単に管理できるように Google Cloud SDK コマンドライン インターフェース (CLI) を構成したいと考えています。
何をするべきでしょうか?
- A.
- 1. 管理する必要がある各プロジェクトの構成を作成します。
- 2. 割り当てられた各 Google Cloud プロジェクトで作業するときに適切な構成を有効にします。
- B.
- 1. 管理する必要がある各プロジェクトの構成を作成します。
- 2. デフォルト以外のプロジェクトで作業する必要がある場合は gcloud init を使用して構成値を更新します。
- C.
- 1. 管理する必要がある プロジェクトのデフォルト構成を使用します。
- 2. 割り当てられた各 Google Cloud プロジェクトで作業するときに適切な構成を有効にします。
- D.
- 1. 管理する必要がある プロジェクトのデフォルト構成を使用します。
- 2. デフォルト以外のプロジェクトで作業する必要がある場合は gcloud init を使用して構成値を更新します。
Answer: A
Question 121
マネージド インスタンス グループは新しいインスタンスの作成が新しいインスタンスの作成に失敗したことを示すアラートを発生させました。
予想されるアプリケーション トラフィックを処理できるようにするには、テンプレートで指定された実行中のインスタンスの数を維持する必要があります。
何をするべきでしょうか?
- A. インスタンス グループで使用される有効な構文を含むインスタンス テンプレートを作成します。インスタンス名と同じ名前の永続ディスクをすべて削除します。
- B. インスタンス グループで使用される有効な構文を含むインスタンス テンプレートを作成します。テンプレート内のインスタンス名と永続ディスク名の値が同じでないことを確認します。
- C. インスタンス グループで使用されているインスタンス テンプレートに有効な構文が含まれていることを確認します。インスタンス名と同じ名前の永続ディスクをすべて削除します。インスタンス テンプレートで disks.autoDelete プロパティを true に設定します。
- D. 現在のインスタンス テンプレートを削除し、新しいインスタンス テンプレートに置き換えます。テンプレート内のインスタンス名と永続ディスク名の値が同じでないことを確認します。インスタンス テンプレートで disks.autoDelete プロパティを true に設定します。
Answer: A
Reference:
–マネージド インスタンス グループ(MIG)を作成するための基本的なシナリオ | Compute Engine ドキュメント | Google Cloud
Question 122
会社はオンプレミス環境から Google Cloud に移行しています。
Cassandra 環境をバックエンド データベースとして使用する開発チームが複数あります。それらはすべて他の Cassandra インスタンスから分離された開発環境を必要とします。最小限のサポート作業で迅速に Google Cloud に移行したいと考えています。
何をするべきでしょうか?
- A.
- 1. Google Cloud に Cassandra をインストールするための手順ガイドを作成します。
- 2. 開発者がインストラクション ガイドにアクセスできるようにします。
- B.
- 1. 開発者に Cloud Marketplace にアクセスするようにアドバイスします。
- 2. 開発者に開発作業用の Cassandra イメージを起動するよう依頼します。
- C.
- 1. Cassandra Compute Engine インスタンスを構築し、そのスナップショットを作成します。
- 2. スナップショットを使用して開発者用のインスタンスを作成します。
- D.
- 1. Cassandra Compute Engine インスタンスを構築し、そのスナップショットを作成します。
- 2. スナップショットを Cloud Storage にアップロードし、開発者がアクセスできるようにします。
- 3. 開発者が自分で作成できるようにスナップショットから Compute Engine インスタンスを作成する手順を作成します。
Answer: B
Question 123
本番アプリケーションをホストする Compute Engine インスタンスがあります。
インスタンスが CPU リソースの 90% 以上を 15 分以上消費した場合にメールを受信したいと考えています。Google サービスを利用したいと思います。
何をするべきでしょうか?
- A.
- 1. コンシューマ Gmail アカウントを作成します。
- 2. CPU 使用率を監視するスクリプトを作成します。
- 3. CPU 使用率がしきい値を超えたら、そのスクリプトで Gmail アカウントと smtp.gmail.com をポート 25 で SMTP サーバとして使用してメールを送信します。
- B.
- 1. Cloud Monitoring ワークスペースを作成し、Google Cloud Platform (GCP) プロジェクトをそれに関連付けます。
- 2. しきい値をトリガー条件として使用する Cloud Monitoring アラート ポリシーを作成します。
- 3. 通知チャネルでメール アドレスを設定します。
- C.
- 1. Cloud Monitoring ワークスペースを作成し、GCP プロジェクトをそれに関連付けます。
- 2. CPU 使用率をモニタリングし、それをカスタム指標として Cloud Monitoring に送信するスクリプトを作成します。
- 3. Cloud Monitoring でインスタンスの稼働時間チェックを作成します。
- D.
- 1. Cloud Logging で次の正規表現を使用してログベースの指標を作成し、CPU 使用率を抽出します。
CPU Usage: ([0-9] {1,3})% - 2. Cloud Monitoring でこの指標に基づいてアラート ポリシーを作成します。
- 3. 通知チャネルでメール アドレスを設定します。
- 1. Cloud Logging で次の正規表現を使用してログベースの指標を作成し、CPU 使用率を抽出します。
Answer: B
Question 124
Cloud Spanner をバックエンド データベースとして使用するアプリケーションがあります。
アプリケーションには、非常に予測可能なトラフィック パターンがあります。トラフィックに応じて Spanner ノードの数を自動的にスケールアップまたはスケールダウンしたい。
何をするべきでしょうか?
- A. Cloud Monitoring 指標を確認するためにスケジュールに基づいて実行される cron ジョブを作成し、それに応じて Spanner インスタンスのサイズを変更します。
- B. Cloud Spanner の CPU がしきい値を超えたときにオンコール SRE メールにアラートを送信する Cloud Monitoring アラート ポリシーを作成します。SRE はそれに応じてリソースをスケールアップまたはスケールダウンします。
- C. Cloud Spanner の CPU がしきい値を超えたときに Google Cloud サポートのメールにアラートを送信する Cloud Monitoring アラート ポリシーを作成します。Google サポートはそれに応じてリソースをスケールアップまたはスケールダウンします。
- D. Cloud Spanner の CPU がしきい値を上回ったり下回ったりしたときに Webhook にアラートを送信する Cloud Monitoring アラート ポリシーを作成します。HTTP をリッスンし、それに応じて Spanner リソースのサイズを変更する Cloud Function を作成します。
Answer: D
Question 125
会社は Compute Engine インスタンスで実行される Apache ウェブサーバに大きなファイルを公開しています。
プロジェクトで実行されているアプリケーションは、Apache Web サーバだけではありません。Google Cloud で測定したサーバの下りネットワーク コストが今月 100 ドルを超えたときにメールを受信したいと考えています。
何をするべきでしょうか?
- A. 100 ドルの金額、100% のしきい値、メールの通知タイプを使用してプロジェクトに予算アラートを設定します。
- B. 100 ドルの金額、100% のしきい値、メールの通知タイプを使用して請求先アカウントに予算アラートを設定します。
- C. 請求データを BigQuery にエクスポートします。BigQuery を使用して当月の Apache ウェブサーバのエクスポートされた課金データの下りネットワーク コストを合計し、100 ドルを超えた場合にメールを送信する Cloud Function を作成します。Cloud Scheduler を使用して Cloud Function をスケジュールし、1 時間ごとに実行します。
- D. Cloud Logging エージェントを使用して Apache ウェブサーバのログを Cloud Logging にエクスポートします。BigQuery を使用して当月の Cloud Logging の HTTP レスポンス ログ データを解析し、すべての HTTP レスポンスのサイズに現在の Google Cloud 下り料金を掛けた合計が 100 ドルを超える場合にメールを送信する Cloud Function を作成します。Cloud Scheduler を使用して Cloud Function をスケジュールし、1 時間ごとに実行します。
Answer: C
Question 126
複数の Google Cloud プロダクトを使用する Google Cloud 上のソリューションを設計しました。会社からソリューションのコストを見積もるよう依頼されました。
毎月の総コストの見積もりを提供する必要があります。
何をするべきでしょうか?
- A. ソリューション内の各 Google Cloud プロダクトについて、プロダクトの料金ページで料金の詳細を確認してください。Google Cloud 料金計算ツールを使用して各 Google Cloud プロダクトの月額費用を合計します。
- B. ソリューション内の各 Google Cloud プロダクトについて、プロダクトの料金ページで料金の詳細を確認します。製品ごとに予想される月額費用をまとめた Google スプレッドシートを作成します。
- C. Google Cloud でソリューションをプロビジョニングします。ソリューションを 1 週間プロビジョニングしたままにします。Cloud Console の [請求レポート] ページに移動します。1 週間のコストを掛けて 1 か月のコストを決定します。
- D. Google Cloud でソリューションをプロビジョニングします。ソリューションを 1 週間プロビジョニングしたままにします。Cloud Monitoring を使用してプロビジョニングされたリソースと使用されたリソースの量を確認します。1 週間のコストを掛けて 1 か月のコストを決定します。
Answer: A
Question 127
ポート 443 で SSL 暗号化された TCP トラフィックを受信するアプリケーションがあります。
このアプリケーションのクライアントは世界中にあります。クライアントの待ち時間を最小限に抑えたい。
どの負荷分散オプションを使用する必要がありますか?
- A. HTTPS ロードバランサ
- B.ネットワークロードバランサ
- C. SSL プロキシ ロード バランサ
- D. 内部 TCP/UDP ロード バランサ。ターゲット インスタンスで 0.0.0.0/0 からの上りトラフィックを許可するファイアウォール ルールを追加します。
Answer: C
Reference:
–外部 SSL プロキシ ロード バランシングの概要 | 負荷分散 | Google Cloud
Question 128
汎用の Compute Engine インスタンスにアプリケーションがあり、Zonal SSD Persistent Disk で過剰なディスク読み取りスロットリングが発生しています。
アプリケーションは、主にディスクから大きなファイルを読み取ります。ディスク サイズは現在 350 GB です。コストを最小限に抑えながら、最大量のスループットを提供したいと考えています。
何をするべきでしょうか?
- A. ディスクのサイズを 1 TB に増やします。
- B. インスタンスに割り当てられた CPU を増やします。
- C. インスタンスでローカル SSD を使用するように移行します。
- D. インスタンスでリージョン SSD を使用するように移行します。
Answer: C
Reference:
–パフォーマンス要件を満たすようにディスクを構成する | Compute Engine ドキュメント | Google Cloud
Question 129
Dataproc クラスタは範囲 172.16.20.128/25 の単一のサブネット内の単一の Virtual Private Cloud (VPC) ネットワークで実行されます。
VPC ネットワークで使用できるプライベート IP アドレスはありません。最小限の手順でクラスタと通信するための新しい VM を追加したいと考えています。
何をするべきでしょうか?
- A. 既存のサブネット範囲を 172.16.20.0/24 に変更します。
- B. VPC に新しいセカンダリ IP 範囲を作成し、その範囲を使用するように VM を構成します。
- C. VM 用の新しい VPC ネットワークを作成します。VM の VPC ネットワークと Dataproc クラスタ VPC ネットワークの間で VPC ピアリングを有効にします。
- D. 172.32.0.0/16 のサブネットを持つ VM 用の新しい VPC ネットワークを作成します。Dataproc VPC ネットワークと VM VPC ネットワークの間で VPC ネットワーク ピアリングを有効にします。カスタム ルート交換を構成します。
Answer: C
Question 130
BigQuery からのデータを集約して可視化する App Engine サービスを管理します。
アプリケーションはデフォルトの App Engine サービス アカウントでデプロイされます。
視覚化する必要があるデータは、別のチームが管理する別のプロジェクトに存在します。このプロジェクトへのアクセス権はありませんが、アプリケーションで BigQuery データセットからデータを読み取れるようにしたいと考えています。
何をするべきでしょうか?
- A. 他のチームに依頼してデフォルトの App Engine サービス アカウントに BigQuery ジョブ ユーザーの役割を付与してもらいます。
- B. 他のチームにデフォルトの App Engine サービス アカウントに BigQuery データ閲覧者の役割を付与するよう依頼します。
- C. プロジェクトの Cloud IAM でデフォルトの App Engine サービス アカウントに BigQuery データ閲覧者の役割があることを確認します。
- D. プロジェクトの Cloud IAM で他のチームから新しく作成されたサービス アカウントにプロジェクトでの BigQuery ジョブ ユーザーのロールを付与します。
Answer: B
所有者、編集者、閲覧者の基本役割にはそれぞれ BigQuery 管理者 (roles/bigquery.dataOwner)、BigQuery データ編集者 (roles/bigquery.dataEditor)、BigQuery データ閲覧者 (roles/bigquery.dataViewer) 役割が含まれます。これは所有者、編集者、閲覧者の基本的な役割が、それぞれの BigQuery の役割に対して定義されているように BigQuery にアクセスできることを意味します。
Reference:
–IAM の概要 | BigQuery | Google Cloud
Question 131
企業買収によるアプリケーション トラフィックの増加が予想されるため、カスタムの Compute Engine 仮想マシン (VM) のコピーを作成する必要があります。
何をするべきでしょうか?
- A. ベース VM の Compute Engine スナップショットを作成します。そのスナップショットからイメージを作成します。
- B. ベース VM の Compute Engine スナップショットを作成します。そのスナップショットからインスタンスを作成します。
- C. スナップショットからカスタム Compute Engine イメージを作成します。その画像から画像を作成します。
- D. スナップショットからカスタム Compute Engine イメージを作成します。そのイメージからインスタンスを作成します。
Answer: B
カスタム イメージはプロジェクトにのみ属します。カスタム イメージでインスタンスを作成するには、まずカスタム イメージが必要です。
Reference:
–VM インスタンスの作成と開始 | Compute Engine ドキュメント | Google Cloud
Question 132
単一の Compute Engine インスタンスにアプリケーションをデプロイしました。
アプリケーションはログをディスクに書き込みます。ユーザーはアプリケーションのエラーを報告し始めます。問題を診断したいと考えています。
何をするべきでしょうか?
- A. Cloud Logging に移動し、アプリケーション ログを表示します。
- B. インスタンスのシリアル コンソールに接続し、アプリケーション ログを読み取ります。
- C. インスタンスでヘルスチェックを構成し、Low Healthy Threshold 値を設定します。
- D. Cloud Logging エージェントをインストールして構成し、Cloud Logging からログを表示します。
Answer: D
Question 133
アプリケーションは Compute Engine 仮想マシン (VM) で日次レポートを生成します。
VM はプロジェクト corp-iot-insights にあります。あなたのチームはプロジェクト corp-aggregate-reports でのみ動作し、バケット corp-aggregate-reports-storage に毎日のエクスポートのコピーが必要です。VM からの日次レポートがバケット corp-aggregate-reports-storage で利用できるようにアクセスを構成し、Google が推奨するプラクティスに従ってできるだけ少ない手順を使用する必要があります。
何をするべきでしょうか?
- A. 両方のプロジェクトを同じフォルダーに移動します。
- B. VM サービス アカウントに corp-aggregate-reports-storage の Storage Object Creator ロールを付与します。
- C. 両方のプロジェクト間に共有 VPC ネットワークを作成します。VM サービス アカウントに、corp-iot-insights でストレージ オブジェクト作成者の役割を付与します。
- D. corp-aggregate-reports-storage を公開し、疑似ランダム化されたサフィックス名を持つフォルダーを作成します。フォルダーを IoT チームと共有します。
Answer: B
Reference:
–Cloud Billing リソースの組織化とアクセス管理 | Google Cloud
Question 134
Google Cloud サービスを使用する開発用ノートパソコンでアプリケーションを構築しました。
アプリケーションは認証にアプリケーションの既定の資格情報を使用し、開発用ラップトップで正常に動作します。このアプリケーションを Compute Engine 仮想マシン (VM) に移行し、Google が推奨する方法と最小限の変更を使用して認証を設定したいと考えています。
何をするべきでしょうか?
- A. Compute Engine VM が使用するサービス アカウントに Google サービスへの適切なアクセスを割り当てます。
- B. Google サービスへの適切なアクセス権を持つサービス アカウントを作成し、このアカウントを使用するようにアプリケーションを構成します。
- C. Google サービスへの適切なアクセス権を持つサービス アカウントの資格情報を構成ファイルに保存し、この構成ファイルをアプリケーションにデプロイします。
- D. Google サービスへの適切なアクセス権を持つユーザー アカウントの資格情報を構成ファイルに保存し、この構成ファイルをアプリケーションと共にデプロイします。
Answer: A
Reference:
–サービス アカウントを使用したワークロードを認証 | Compute Engine ドキュメント | Google Cloud
Question 135
まだ存在しない新しいプロジェクトに Compute Engine インスタンスを作成する必要があります。
何をするべきでしょうか?
- A. Cloud SDK を使用して新しいプロジェクトを作成し、そのプロジェクトで Compute Engine API を有効にしてから新しいプロジェクトを指定するインスタンスを作成します。
- B. Cloud Console で Compute Engine API を有効にし、Cloud SDK を使用してインスタンスを作成し、–project フラグを使用して新しいプロジェクトを指定します。
- C. Cloud SDK を使用して新しいインスタンスを作成し、–project フラグを使用して新しいプロジェクトを指定します。Cloud SDK から Compute Engine API を有効にするよう求められたら、「はい」と答えます。
- D. Cloud Console で Compute Engine API を有効にします。コンソールの Compute Engine セクションに移動して新しいインスタンスを作成し、作成フォームで [Create In A New Project] オプションを探します。
Answer: A
Question 136
あなたの会社ではオンプレミス サーバで 1 つのバッチ プロセスを実行しており、完了するまでに約 30 時間かかります。
タスクは毎月実行され、オフラインで実行でき、中断された場合は再起動する必要があります。コストを最小限に抑えながら、このワークロードをクラウドに移行したいと考えています。
何をするべきでしょうか?
- A. ワークロードを Compute Engine プリエンプティブル VM に移行します。
- B. プリエンプティブル ノードを使用してワークロードを Google Kubernetes Engine クラスタに移行します。
- C. ワークロードを Compute Engine VM に移行します。必要に応じてインスタンスを開始、停止します。
- D. プリエンプティブル VM をオンにしてインスタンス テンプレートを作成します。テンプレートからマネージド インスタンス グループを作成し、ターゲット CPU 使用率を調整します。ワークロードを移行します。
Answer: C
Reference:
–ワークロードを他のマシンタイプに移行する | Kubernetes Engine | Google Cloud
Question 137
あなたは新しいアプリケーションを開発しており、ソース コードをビルドしてデプロイするための Jenkins インストールを探しています。
インストールをできるだけ迅速かつ簡単に自動化したいと考えています。
何をするべきでしょうか?
- A. Google Cloud Marketplace を通じて Jenkins をデプロイします。
- B. 新しい Compute Engine インスタンスを作成します。Jenkins 実行可能ファイルを実行します。
- C. 新しい Kubernetes Engine クラスタを作成します。Jenkins イメージのデプロイメントを作成します。
- D. Jenkins 実行可能ファイルを使用してインスタンス テンプレートを作成します。このテンプレートを使用してマネージド インスタンス グループを作成します。
Answer: A
Reference:
–About Jenkins on GKE | Google Kubernetes Engine (GKE) | Google Cloud
Question 138
gcloud コマンドライン インターフェース (CLI) をダウンロードしてインストールし、Google アカウントで認証しました。
プロジェクト内の Compute Engine インスタンスのほとんどは、europe-west1-d ゾーンで実行されます。これらのインスタンスを管理するときに、各 CLI コマンドでこのゾーンを指定する必要はありません。
何をするべきでしょうか?
- A. gcloud config サブコマンドを使用して europe-west1-d ゾーンをデフォルト ゾーンとして設定します。
- B. Compute Engine の [設定] ページの [デフォルトの場所] でゾーンを europe-west1-d に設定します。
- C. CLI インストール ディレクトリで zone=europe-west1-d を含む default.conf というファイルを作成します。
- D. Compute Engine ページでキー compute/zone と値 europe-west1-d を使用してメタデータ エントリを作成します。
Answer: A
Reference:
–gcloud compute | Compute Engine ドキュメント | Google Cloud
Question 139
会社のコアビジネスは大規模な建設機械のレンタルです。
レンタルされているすべての機器には数秒ごとにイベント情報を送信する複数のセンサーが装備されています。これらの信号はエンジンの状態、走行距離、燃料レベルなどによって異なります。顧客はこれらのセンサーによって監視された使用量に基づいて請求されます。高スループット「デバイスごとに 1 時間あたり最大数千のイベント」が期待され、イベントの時間に基づいて一貫したデータを取得する必要があります。個々のシグナルの保存と取得はアトミックである必要があります。
何をするべきでしょうか?
- A. デバイスごとに Cloud Storage にファイルを作成し、そのファイルに新しいデータを追加します。
- B. デバイスごとに Cloud Filestore にファイルを作成し、そのファイルに新しいデータを追加します。
- C. データを Datastore に取り込みます。デバイスに基づいてエンティティ グループにデータを格納します。
- D. データを Cloud Bigtable に取り込みます。イベントのタイムスタンプに基づいて行キーを作成します。
Answer: D
Question 140
Google Cloud プロジェクト A、B、C でアプリケーション パフォーマンス モニタリングを 1 つの画面として設定するよう求められます。
CPU、メモリ、ディスクを監視したいと考えています。
何をするべきでしょうか?
- A. API を有効にしてからプロジェクト A、B、C からチャートを共有します。
- B. API を有効にしてから metrics.reader ロールをプロジェクト A、B、C に付与します。
- C. API を有効にしてからデフォルトのダッシュボードを使用し、すべてのプロジェクトを順番に表示します。
- D. API を有効にし、プロジェクト A の下にワークスペースを作成してからプロジェクト B と C を追加します。
Answer: D
Question 141
複数の Google Cloud プロジェクトで複数のリソースを作成しました。
すべてのプロジェクトは異なる請求先アカウントにリンクされています。将来の料金をより正確に見積もるには発生したすべてのコストを 視覚的に表現する必要があります。できるだけ早く新しい費用データを含めたいと考えています。
何をするべきでしょうか?
- A. BigQuery への請求データのエクスポートを構成し、データポータルでデータを可視化します。
- B. コスト テーブル ページにアクセスして CSV エクスポートを取得し、データポータルを使用して視覚化します。
- C. Google Cloud 料金計算ツールにすべてのリソースを入力し、毎月のコストの見積もりを取得します。
- D. Cloud Billing Console のレポート ビューを使用し、目的の費用情報を表示します。
Answer: A
Reference:
–Google データポータルで費用を可視化する | Cloud Billing | Google Cloud
Question 142
会社には Compute Engine とオンプレミスで実行されているワークロードがあります。
Google Cloud Virtual Private Cloud (VPC) は、Virtual Private Network (VPN) 経由で WAN に接続されています。新しい Compute Engine インスタンスをデプロイし、パブリック インターネット トラフィックがルーティングされないようにする必要があります。
何をするべきでしょうか?
- A. パブリック IP アドレスなしでインスタンスを作成します。
- B. 限定公開の Google アクセスを有効にしてインスタンスを作成します。
- C. VPC ネットワークですべての下り (外向き) ファイアウォール ルールを拒否するルールを作成します。
- D. VPC にルートを作成し、すべてのトラフィックを VPN トンネル経由でインスタンスにルーティングします。
Answer: B
サービスにパブリック IP アドレスを付与することなく、ストレージ、ビッグデータ、分析、機械学習などの Google サービスへのプライベート アクセスを取得します。
Reference:
–Virtual Private Cloud(VPC) | Google Cloud
Question 143
チームは、組織のインフラストラクチャを維持します。
現在のインフラストラクチャには変更が必要です。提案された変更をチームの他のメンバーと共有する必要があります。Google が推奨するベスト プラクティスに従う必要があります。
何をするべきでしょうか?
- A. Deployment Manager テンプレートを使用して提案された変更を記述し、Cloud Storage バケットに保存します。
- B. Deployment Manager テンプレートを使用して提案された変更を記述し、Cloud Source Repositories に保存します。
- C. 開発環境で変更を適用し、gcloud compute instances list を実行してから共有ストレージ バケットに出力を保存します。
- D. 開発環境で変更を適用し、gcloud compute instances list を実行してから出力を Cloud Source Repositories に保存します。
Answer: B
Question 144
平日の午前 9 時から午後 6 時まで使用されるアプリケーションをホストする Compute Engine インスタンスがあります。
災害復旧の目的で、このインスタンスを毎日バックアップしたいと考えています。バックアップを 30 日間保持したいと考えています。管理オーバーヘッドが最小でサービスの数が最小である、Google が推奨するソリューションが必要です。
何をするべきでしょうか?
- A.
- 1. インスタンスのメタデータを更新して次の値を追加します。
snapshot schedule: 0 1 * * * - 2. インスタンスのメタデータを更新して次の値を追加します。
snapshot retention: 30
- 1. インスタンスのメタデータを更新して次の値を追加します。
- B.
- 1. Cloud Console で [Compute Engine ディスク] ページに移動し、インスタンスのディスクを選択します。
- 2. [スナップショット スケジュール] セクションで [スケジュールの作成] を選択し、次のパラメーターを構成します。
- C.
- 1. インスタンスのディスクのスナップショットを作成する Cloud Function を作成します。
- 2. 30 日以上経過したスナップショットを削除する Cloud Function を作成します。
- 3. Cloud Scheduler を使用して両方の Cloud Functions を毎日午前 1 時にトリガーします。
- D.
- 1. ディスクのコンテンツを Cloud Storage にコピーするインスタンスで bash スクリプトを作成します。
- 2. バックアップ Cloud Storage バケットで 30 日より古いデータを削除するインスタンスで bash スクリプトを作成します。
- 3. インスタンスの crontab を構成してこれらのスクリプトを毎日午前 1:00 に実行します。
Answer: B
Question 145
Google Kubernetes Engine (GKE) で実行されている既存のアプリケーションは、4 つの GKE n1-standard-2 ノードで実行されている複数のポッドで構成されています。
ダウンタイムなしで n2-highmem-16 ノードを必要とする追加のポッドをデプロイする必要があります。
何をするべきでしょうか?
- A. gcloud container clusters upgrade を使用します。新しいサービスをデプロイします。
- B. 新しいノード プールを作成し、マシン タイプ n2-highmem-16 を指定して新しいポッドをデプロイします。
- C. n2-highmem-16 ノードで新しいクラスタを作成します。ポッドを再デプロイし、古いクラスタを削除します。
- D. n1-standard-2 と n2-highmem-16 ノードの両方で新しいクラスタを作成します。ポッドを再デプロイし、古いクラスタを削除します。
Answer: B
Question 146
Cloud Spanner をデータベース バックエンドとして使用して、ユーザーに関する現在の状態情報を保持するアプリケーションがあります。
Cloud Bigtable はユーザーによってトリガーされたすべてのイベントをログに記録します。毎日のバックアップ中に Cloud Spanner データを Cloud Storage にエクスポートします。アナリストの 1 人が特定のユーザーのために Cloud Spanner と Cloud Bigtable からのデータを結合するように依頼しました。このアドホックなリクエストをできるだけ効率的に完了したいと考えています。
何をするべきでしょうか?
- A. 特定のユーザーのために Cloud Bigtable と Cloud Storage からデータをコピーするデータフロー ジョブを作成します。
- B. 特定のユーザーのために Cloud Bigtable と Cloud Spanner からデータをコピーするデータフロー ジョブを作成します。
- C. 特定のユーザーのために Cloud Bigtable と Cloud Storage からデータを抽出する Spark ジョブを実行する Cloud Dataproc クラスタを作成します。
- D. Cloud Storage と Cloud Bigtable に 2 つの個別の BigQuery 外部テーブルを作成します。BigQuery コンソールを使用してユーザー フィールドを介してこれらのテーブルを結合し、適切なフィルタを適用します。
Answer: D
Question 147
us-central1-a の Compute Engine 仮想マシン(VM)からアプリケーションをホストしています。
単一の Compute Engine ゾーンの障害をサポートしてダウンタイムを排除し、コストを最小限に抑えるためにデザインを調整したいと思います。
何をするべきでしょうか?
- A. us-central1-b に Compute Engine リソースを作成します。us-central-a と us-central1-b の両方で負荷を分散します。
- B. マネージド インスタンス グループを作成し、us-central1-a をゾーンとして指定します。短いヘルス間隔でヘルス チェックを構成します。
- C. HTTP (S) ロード バランサーを作成します。1 つ以上のグローバル転送ルールを作成してトラフィックを VM に転送します。
- D. アプリケーションの定期的なバックアップを実行します。Cloud Monitoring アラートを作成し、アプリケーションが利用できなくなった場合に通知を受けます。通知されたらバックアップから復元します。
Answer: A
Question 148
同僚が Google Cloud Platform プロジェクトを引き渡し、あなたが維持できるようにしました。
セキュリティ診断の一環として、誰がプロジェクト オーナーの役割を付与されているかを確認したいと考えています。
何をするべきでしょうか?
- A. コンソールでどの SSH キーがプロジェクト全体のキーとして保存されているかを確認します。
- B. Identity-Aware Proxy に移動し、これらのリソースの権限を確認します。
- C. すべてのリソースの IAM & 管理ページで監査ログを有効にし、結果を検証します。
- D. コマンド gcloud projects get-iam-policy を使用し、現在の役割の割り当てを表示します。
Answer: D
Reference:
–アクセス方法を選択する | Compute Engine ドキュメント | Google Cloud
Question 149
同じサブネットで複数の VPC ネイティブ Google Kubernetes Engine クラスタを実行しています。
ノードで使用できる IP が使い果たされているため、必要に応じてノードでクラスタを拡張できるようにする必要があります。
何をするべきでしょうか?
- A. 使用中のサブネットと同じリージョンに新しいサブネットを作成します。
- B. GKE クラスタが使用するサブネットにエイリアス IP 範囲を追加します。
- C. 新しい VPC を作成し、既存の VPC との VPC ピアリングをセットアップします。
- D. クラスタに関連するサブネットの CIDR 範囲を拡張します。
Answer: D
Question 150
毎晩実行され、多数の仮想マシン (VM) を使用するバッチ ワークロードがあります。
これは耐障害性があり、一部の VM が終了しても許容できます。VM の現在のコストが高すぎます。
何をするべきでしょうか?
- A. シミュレートされたメンテナンス イベントを使用してテストを実行します。テストが成功した場合は将来のジョブを実行するときにプリエンプティブル n1-standard VM を使用します。
- B. シミュレートされたメンテナンス イベントを使用してテストを実行します。テストが成功した場合は今後のジョブを実行するときに n1-standard VM を使用します。
- C. マネージド インスタンス グループを使用してテストを実行します。テストが成功した場合は今後のジョブを実行するときにマネージド インスタンス グループの n1-standard VM を使用します。
- D. n2 の代わりに n1-standard VM を使用してテストを実行します。テストが成功した場合は今後のジョブを実行するときに n1-standard VM を使用します。
Answer: A
Reference:
–VM インスタンスの料金 | Compute Engine ドキュメント | Google Cloud
Question 151
あなたはユーザーと協力してファイアウォールの背後にある新しい VPC でアプリケーションをセットアップしています。
ユーザーはデータの送信について懸念しています。開いている出力ポートを最小限に設定する必要があります。
何をするべきでしょうか?
- A. すべての送信をブロックする優先度の低い (65534) ルールと、適切なポートのみを許可する優先度の高いルール (1000) を設定します。
- B. 入力ポートと出力ポートの両方をペアにする優先度の高い (1000) ルールを設定します。
- C. すべての送信をブロックする優先度の高い (1000) ルールと、適切なポートのみを許可する優先度の低い (65534) ルールを設定します。
- D. 適切なポートを許可する優先度の高い (1000) ルールを設定します。
Answer: A
Question 152
会社は Compute Engine インスタンスで Linux ワークロードを実行しています。
会社は Google アカウントを使用しない新しい運用パートナーと協力します。運用パートナーがインストール済みのツールを維持できるように、インスタンスへのアクセス権を運用パートナーに付与する必要があります。
何をするべきでしょうか?
- A. Compute Engine インスタンスに対して Cloud IAP を有効にし、運用パートナーを Cloud IAP トンネル ユーザーとして追加します。
- B. すべてのインスタンスに同じネットワーク タグを付けます。VPC でファイアウォール ルールを作成し、運用パートナーからネットワーク タグを持つインスタンスへのトラフィックに対してポート 22 での TCP アクセスを許可します。
- C. Google Cloud VPC と運用パートナーの内部ネットワークの間に Cloud VPN を設定します。
- D. 運用パートナーに SSH キー ペアの生成を依頼し、公開キーを VM インスタンスに追加します。
Answer: A
Reference:
–VPC ファイアウォール ルール | Google Cloud
Question 153
新しいファイルが Cloud Storage バケットにアップロードされるたびにトリガーされるコード スニペットを作成しました。
このコード スニペットをデプロイします。
何をするべきでしょうか?
- A. App Engine を使用し、Cloud Pub/Sub を使用してアプリケーションをトリガーするように Cloud Scheduler を構成します。
- B. Cloud Functions を使用し、バケットをトリガー リソースとして構成します。
- C. Google Kubernetes Engine を使用し、Cloud Pub/Sub を使用してアプリケーションをトリガーするように CronJob を構成します。
- D. Dataflow をバッチ ジョブとして使用し、バケットをデータ ソースとして設定します。
Answer: B
Question 154
ストレージ バケットに格納されているオブジェクトのオブジェクト ライフサイクル管理をセットアップするよう求められました。
オブジェクトは 1 回書き込まれ、30 日間頻繁にアクセスされます。30 日後、特別な必要がない限り、オブジェクトは再度読み取られません。オブジェクトは 3 年間保管する必要があり、コストを最小限に抑える必要があります。
何をするべきでしょうか?
- A. Nearline ストレージを 30 日間使用し、その後 3 年間 Archive ストレージに移行するポリシーを設定します。
- B. Standard ストレージを 30 日間使用し、その後 3 年間 Archive ストレージに移動するポリシーを設定します。
- C. Nearline ストレージを 30 日間使用し、Coldline を 1 年間移動し、その後 Archive ストレージに 2 年間移動するポリシーを設定します。
- D. Standard ストレージを 30 日間使用し、Coldline に 1 年間移行し、その後 Archive ストレージに 2 年間移行するポリシーを設定します。
Answer: B
Reference:
–Official Google Cloud Certified Professional Data Engineer Study Guide – Dan Sullivan – Google Books
Question 155
機密情報を Cloud Storage バケットに保存しています。
法的な理由により、保存されたデータを読み取るすべてのリクエストを記録できる必要があります。これらの要件に準拠していることを確認する必要があります。
何をするべきでしょうか?
- A. プロジェクトで Identity Aware Proxy API を有効にします。
- B. Data Loss Prevention API を使用してバケットをスキャンします。
- C. データを読み取るために、単一のサービス アカウント アクセスのみを許可します。
- D. Cloud Storage API のデータアクセス監査ログを有効にします。
Answer: D
Reference:
–Cloud Storage での Cloud Audit Logs | Google Cloud
Question 156
あなたは 10 人の開発者グループのチーム リーダーです。
各デベロッパーに、さまざまな Google Cloud ソリューションを試すための個人用サンドボックスとして使用できる個別の Google Cloud プロジェクトを提供しました。開発者がサンドボックス環境で月額 500 ドルを超えている場合に通知を受け取る必要があります。
何をするべきでしょうか?
- A. すべてのプロジェクトに対して単一の予算を作成し、この予算で予算アラートを構成します。
- B. サンドボックス プロジェクトごとに個別の請求先アカウントを作成し、BigQuery 課金エクスポートを有効にします。データポータル ダッシュボードを作成して請求先アカウントごとの支出をプロットします。
- C. プロジェクトごとに予算を作成し、これらすべての予算に対して予算アラートを設定します。
- D. すべてのサンドボックス プロジェクトに対して 1 つの請求先アカウントを作成し、BigQuery 請求書のエクスポートを有効にします。プロジェクトごとの支出をプロットする Data Studio ダッシュボードを作成します。
Answer: C
Reference:
–予算と予算アラートを作成、編集、削除する | Cloud Billing | Google Cloud
Question 157
Compute Engine に本番環境のアプリケーションをデプロイしています。
間違ったボタンをクリックしてインスタンスを誤って破棄することを防止したいと考えています。
何をするべきでしょうか?
- A. インスタンスの削除時にブートディスクを削除するフラグを無効にします。
- B. インスタンスで削除保護を有効にします。
- C. インスタンスで自動再起動を無効にします。
- D. インスタンスでプリエンプティビリティを有効にします。
Answer: B
Question 158
会社では 1 つのプロジェクトで一元化された多数の Google Cloud サービスを使用しています。
すべてのチームには、テストと開発のための特定のプロジェクトがあります。DevOps チームは、仕事を遂行するためにすべての本番サービスにアクセスする必要があります。今後、Google Cloud プロダクトの変更によって権限が拡大されないようにしたいと考えています。Google のベストプラクティスに従います。
何をするべきでしょうか?
- A. DevOps チームのすべてのメンバーに組織レベルでのプロジェクト編集者の役割を付与します。
- B. DevOps チームのすべてのメンバーに本番プロジェクトのプロジェクト編集者の役割を付与します。
- C. 必要な権限を組み合わせたカスタムロールを作成します。DevOps チームに本番プロジェクトのカスタムロールを付与します。
- D. 必要な権限を組み合わせたカスタムロールを作成します。組織レベルで DevOps チームにカスタムロールを付与します。
Answer: C
Question 159
何千ものサプライヤーからアップロードされたデータ ファイルを処理するアプリケーションを構築しています。
アプリケーションの主な目標はデータ セキュリティと古いデータの期限切れです。
次の目的でアプリケーションを設計する必要があります。
– サプライヤーが自社のデータのみにアクセスできるようにアクセスを制限します。
– サプライヤーにデータへの書き込みアクセス権を 30 分間だけ付与します。
– 45 日以上経過したデータを削除します。
開発サイクルが非常に短いため、アプリケーションのメンテナンスが最小限で済むようにする必要があります。
どの 2 つの戦略を使用する必要がありますか? (2つ選んでください)
- A. 45 日後に Cloud Storage オブジェクトを削除するライフサイクル ポリシーを作成します。
- B. 署名付き URL を使用してサプライヤがオブジェクトを保存するための限られた時間のアクセスを許可します。
- C. アプリケーション用に SFTP サーバをセットアップし、サプライヤーごとに個別のユーザーを作成します。
- D. 有効期限が切れたオブジェクトを削除するために 45 日のタイマーをトリガーするクラウド機能を構築します。
- E. すべての Cloud Storage バケットをループ処理し、45 日以上経過したバケットを削除するスクリプトを作成します。
Answer: A、B
Question 160
会社は Infrastructure as Code を使用し、複数の Google Cloud リソースの作成と管理を標準化したいと考えています。
環境の管理に必要な反復コードの量を最小限に抑えたいと考えています。
何をするべきでしょうか?
- A. Cloud Deployment Manager を使用して環境のテンプレートを開発します。
- B. 端末で curl を使用して個々のリソースごとに関連する Google API に REST リクエストを送信します。
- C. Cloud Console インターフェースを使用して関連するすべてのリソースをプロビジョニング、管理します。
- D. すべての要件ステップを gcloud コマンドとして含む bash スクリプトを作成します。
Answer: A
Reference:
–Deployment Manager の基礎知識 | Cloud Deployment Manager のドキュメント | Google Cloud
Question 161
Google Cloud 環境の毎月のセキュリティ チェックを行っており、Google Cloud プロジェクトに保存されているデータを表示するためのアクセス権を持つユーザーを知りたいと考えています。
何をするべきでしょうか?
- A. データ ストレージに関連するすべての API の監査ログを有効にします。
- B. データ アクセスを許可するロールの IAM 権限を確認します。
- C. 各リソースの Identity-Aware Proxy 設定を確認します。
- D. データ損失防止ジョブを作成します。
Answer: B
Reference:
–アクセス制御の概要 | Compute Engine ドキュメント | Google Cloud
Question 162
会社は一部のアプリケーションを Google Cloud にデプロイするハイブリッド クラウド戦略を採用しています。
Virtual Private Network (VPN) トンネルは GCP の Virtual Private Cloud (VPC) を会社のオンプレミス ネットワークに接続します。Google Cloud の複数のアプリケーションがオンプレミス データベース サーバに接続する必要があり、データベースの IP が変更されたときにすべてのアプリケーションで IP 構成を変更する必要がないようにしたいと考えています。
何をするべきでしょうか?
- A. VM インスタンスからの送信時に使用される VPC のすべてのサブネットに対して Cloud NAT を構成します。
- B. Cloud DNS に限定公開ゾーンを作成し、DNS 名を使用してアプリケーションを構成します。
- C. データベースの IP を各インスタンスのカスタム メタデータとして構成し、メタデータ サーバにクエリを実行します。
- D. アプリケーションから Compute Engine の内部 DNS にクエリを実行し、データベースの IP を取得します。
Answer: B
Question 163
営業時間中に社内の同僚にサービスを提供するコンテナ化された Web アプリケーションを開発しました。
アプリケーションの使用時間外にコストが発生しないようにする必要があります。新しい Google Cloud プロジェクトを作成したばかりでアプリケーションをデプロイしたいと考えています。
何をするべきでしょうか?
- A. Cloud Run for Anthos にコンテナをデプロイし、インスタンスの最小数をゼロに設定します。
- B. Cloud Run (フルマネージド) にコンテナをデプロイし、インスタンスの最小数をゼロに設定します。
- C. 自動スケーリングを使用してコンテナを App Engine フレキシブル環境にデプロイし、app.yaml で値 min_instances をゼロに設定します。
- D. 手動スケーリングで App Engine フレキシブル環境にコンテナをデプロイし、app.yaml で値インスタンスをゼロに設定します。
Answer: B
Question 164
あなたは自分のクレジット カードを使用して Google Cloud を試し、費用を会社に請求しました。
会社は請求プロセスを合理化し、プロジェクトの費用を毎月の請求書に請求したいと考えています。
何をするべきでしょうか?
- A. 財務チームにクレジット カードにリンクされた請求先アカウントに対する請求先アカウント ユーザーの IAM ロールを付与します。
- B. BigQuery 請求エクスポートを設定し、財務部門に IAM アクセス権を付与してデータをクエリします。
- C. Google Billing Support でチケットを作成し、会社に請求書を送るよう依頼します。
- D. プロジェクトの請求先アカウントを会社の請求先アカウントに変更します。
Answer: D
Question 165
BigQuery でデータ ウェアハウスを実行しています。
パートナー企業はデータ ウェアハウス内のデータに基づくレコメンデーション エンジンを提供しています。パートナー企業も Google Cloud でアプリケーションを実行しています。彼らは自分のプロジェクトでリソースを管理しますがプロジェクトの BigQuery データセットにアクセスする必要があります。パートナー企業にデータセットへのアクセスを提供したいと考えています。
何をするべきでしょうか?
- A. 独自のプロジェクトでサービス アカウントを作成し、このサービス アカウントにプロジェクト内の BigQuery へのアクセスを許可します。
- B. 独自のプロジェクトでサービス アカウントを作成し、このサービス アカウントにプロジェクト内の BigQuery へのアクセス権を付与するようパートナーに依頼します。
- C. プロジェクトでサービス アカウントを作成するようパートナーに依頼し、そのサービス アカウントにプロジェクトで BigQuery へのアクセス権を付与してもらいます。
- D. パートナーにプロジェクトでサービス アカウントを作成するよう依頼し、サービス アカウントにプロジェクトの BigQuery データセットへのアクセス権を付与します。
Answer: D
Question 166
ウェブ アプリケーションは Cloud Run for Anthos で正常に実行されています。
特定のパーセンテージの実稼働ユーザー (カナリア デプロイ) を使用して、アプリケーションの更新バージョンを評価する必要があります。
何をするべきでしょうか?
- A. 新しいバージョンのアプリケーションで新しいサービスを作成します。このバージョンと現在実行中のバージョンの間でトラフィックを分割します。
- B. アプリケーションの新しいバージョンで新しいリビジョンを作成します。このバージョンと現在実行中のバージョンの間でトラフィックを分割します。
- C. 新しいバージョンのアプリケーションで新しいサービスを作成します。両方のサービスの前に HTTP ロード バランサーを追加します。
- D. アプリケーションの新しいバージョンで新しいリビジョンを作成します。両方のリビジョンの前に HTTP ロード バランサーを追加します。
Answer: B
Question 167
会社は Google Cloud にデプロイされるモバイル ゲームを開発しました。
ゲーマーはインターネットを介して自分の携帯電話でゲームに接続しています。ゲームは UDP パケットを送信して、マルチプレイヤー モードでのプレイ中のゲーマーのアクションについてサーバを更新します。ゲーム バックエンドは複数の仮想マシン (VM) にスケーリングでき、単一の IP アドレスで VM を公開したいと考えています。
何をするべきでしょうか?
- A. アプリケーション サーバの前に SSL プロキシ ロード バランサーを構成します。
- B. アプリケーション サーバの前に内部 UDP ロード バランサーを構成します。
- C. アプリケーション サーバの前に外部 HTTP (S) ロード バランサーを構成します。
- D. アプリケーション サーバの前に外部ネットワーク ロード バランサーを構成します。
Answer: D
Reference:
–VM インスタンスへの安全な接続 | Compute Engine ドキュメント | Google Cloud
Question 168
あなたはオンプレミスのデータ ルームに医用画像を保存する病院で働いています。
病院はこれらの画像のアーカイブ ストレージに Cloud Storage を使用したいと考えています。病院は新しい医療画像を Cloud Storage にアップロードするプロセスを自動化したいと考えています。ソリューションを設計して実装する必要があります。
何をするべきでしょうか?
- A. Cloud Pub/Sub トピックを作成し、Cloud Pub/Sub トピックの Cloud Storage トリガーを有効にします。すべての医用画像を Cloud Pub/Sub トピックに送信するアプリケーションを作成します。
- B. バッチ テンプレート Datastore から Cloud Storage に Dataflow ジョブをデプロイします。目的の間隔でバッチ ジョブをスケジュールします。
- C. gsutil コマンドライン インターフェースを使用してオンプレミス ストレージを Cloud Storage と同期するスクリプトを作成します。スクリプトを cron ジョブとしてスケジュールします。
- D. Google Cloud Console で Cloud Storage に移動し、関連する画像を適切なバケットにアップロードします。
Answer: C
Question 169
監査人は組織による Google Cloud でのデータの使用状況を確認したいと考えています。
監査人は誰が Cloud Storage バケット内のデータにアクセスしたかを監査することに最も関心があります。監査人が必要なデータにアクセスできるようにする必要があります。
何をするべきでしょうか?
- A. 監査するバケットのデータ アクセス ログを有効にし、Cloud Storage でフィルタリングするログ ビューアでクエリを作成します。
- B. 適切なアクセス許可を割り当て、管理アクティビティ監査ログに関する Data Studio レポートを作成します。
- C. 適切な権限を割り当て、Cloud Monitoring を使用して指標を確認します。
- D. エクスポート ログ API を使用し、必要な形式で管理アクティビティ監査ログを提供します。
Answer: A
Reference:
–Cloud Storage での Cloud Audit Logs | Google Cloud
Question 170
Google Cloud プロジェクトの複数のリソースにアクセスするためにサービス アカウントの秘密鍵を含む JSON ファイルを受け取りました。
Cloud SDK をダウンロードしてインストールし、gcloud コマンドを実行する際の認証と認可にこの秘密鍵を使用したいと考えています。
何をするべきでしょうか?
- A. gcloud auth login コマンドを使用し、秘密鍵を指定します。
- B. gcloud auth activate-service-account コマンドを使用し、秘密鍵を指定します。
- C. Cloud SDK のインストール ディレクトリに秘密鍵ファイルを配置し、名前を credentials.json に変更します。
- D. 秘密鍵ファイルをホーム ディレクトリに置き、名前を GOOGLE_APPLICATION_CREDENTIAL に変更します。
Answer: B
Reference:
–gcloud CLI を承認する | Google Cloud CLI のドキュメント
Question 171
あなたは会社で Cloud SQL MySQL データベースを使用しています。
監査目的でデータベースの月末のコピーを 3 年間保持する必要があります。
何をするべきでしょうか?
- A. 月初にエクスポート ジョブを設定します。エクスポート ファイルを Archive クラスの Cloud Storage バケットに書き込みます。
- B. 月初の自動バックアップを 3 年間保存します。バックアップ ファイルを Archive クラスの Cloud Storage バケットに保存します。
- C. 月初にオンデマンド バックアップを設定します。アーカイブ クラスの Cloud Storage バケットにバックアップを書き込みます。
- D. 月初の自動バックアップをエクスポート ファイルに変換します。エクスポート ファイルを Coldline クラスの Cloud Storage バケットに書き込みます。
Answer: A
Question 172
アプリケーションを監視していて特定のエラーが急増しているというユーザー フィードバックを受け取りました。
このエラーはサービス アカウントの権限が不十分であることが原因であることに気付きました。問題を解決することはできますが、問題が再発した場合に通知を受け取りたいと考えています。
何をするべきでしょうか?
- A. ログ ビューアで重大度「エラー」とサービス アカウントの名前でログをフィルタリングします。
- B. BigQuery へのシンクを作成し、すべてのログをエクスポートします。エクスポートされたログで Data Studio ダッシュボードを作成します。
- C.アラートポリシーで使用される特定のエラーのカスタムログベースのメトリックを作成します。
- D. プロジェクト オーナーにサービス アカウントへのアクセス権を付与します。
Answer: C
Reference:
–Logging のクエリ言語を使用したクエリの作成 | Google Cloud
Question 173
あなたはグローバルに使用される金融取引アプリケーションを開発しています。
データはリレーショナル構造を使用して保存、クエリされ、世界中のクライアントがまったく同じ状態のデータを取得する必要があります。アプリケーションは複数のリージョンにデプロイされ、エンド ユーザーに最小限のレイテンシーを提供します。待ち時間を最小限に抑えながら、アプリケーション データのストレージ オプションを選択する必要があります。
何をするべきでしょうか?
- A. データ ストレージに Cloud Bigtable を使用します。
- B. データ ストレージに Cloud SQL を使用します。
- C. データ ストレージに Cloud Spanner を使用します。
- D. データ ストレージに Firestore を使用します。
Answer: C
Reference:
–Compute Engine のリージョン選択に関するベスト プラクティス | ソリューション | Google Cloud
Question 174
Google Cloud に新しいエンタープライズ リソース プランニング (ERP) システムをデプロイしようとしています。
アプリケーションは高速データ アクセスのために完全なデータベースをメモリ内に保持します。このアプリケーション用に GCP で最も適切なリソースを構成する必要があります。
何をするべきでしょうか?
- A. プリエンプティブルな Compute Engine インスタンスをプロビジョニングします。
- B. GPU が接続された Compute Engine インスタンスをプロビジョニングします。
- C. ローカル SSD が接続された Compute Engine インスタンスをプロビジョニングします。
- D. M1 マシンタイプで Compute Engine インスタンスをプロビジョニングします。
Answer: D
Reference:
–ローカル SSD について | Compute Engine ドキュメント | Google Cloud
Question 175
複数のマイクロサービスで構成されるアプリケーションを開発し、各マイクロサービスを独自の Docker コンテナ イメージにパッケージ化しました。
各マイクロサービスを個別にスケーリングできるようにアプリケーション全体を Google Kubernetes Engine にデプロイしたいと考えています。
何をするべきでしょうか?
- A. マイクロサービスごとにカスタム リソース定義を作成し、デプロイします。
- B. Docker Compose ファイルを作成し、デプロイします。
- C. マイクロサービスごとに Job を作成し、デプロイします。
- D. マイクロサービスごとに Deployment を作成し、デプロイします。
Answer: D
Question 176
同じプロジェクト内の異なる Compute Engine インスタンスで複数のアプリケーションを実行します。
各インスタンスが Google Cloud API を呼び出すときに使用するサービス アカウントをより詳細なレベルで指定したいと考えています。
何をするべきでしょうか?
- A. インスタンスを作成するときにインスタンスごとにサービス アカウントを指定します。
- B. インスタンスを作成するときに各サービス アカウントの名前をインスタンス メタデータとして割り当てます。
- C. インスタンスを起動し、gcloud compute instances update を使用して各インスタンスのサービス アカウントを指定します。
- D. インスタンスを起動し、gcloud compute instances update を使用して関連するサービス アカウントの名前をインスタンス メタデータとして割り当てます。
Answer: A
Question 177
Google Kubernetes Engine で実行されるアプリケーションを作成しています。
アプリケーションに最適なデータベース システムとして MongoDB を特定し、サポート SLA を提供するマネージド MongoDB 環境をデプロイしたいと考えています。
何をするべきでしょうか?
- A. Cloud Bigtable クラスタを作成し、HBase API を使用します。
- B. Google Cloud Marketplace から MongoDB Atlas をデプロイします。
- C. MongoDB インストール パッケージをダウンロードし、Compute Engine インスタンスで実行します。
- D. MongoDB インストール パッケージをダウンロードし、マネージド インスタンス グループで実行します。
Answer: B
Question 178
あなたは会社のビジネス インテリジェンス (BI) 部門のプロジェクトを管理しています。
データ パイプラインはストリーミングを介して BigQuery にデータを取り込みます。BI 部門のユーザーが BigQuery の最新データに対してカスタム SQL クエリを実行できるようにしたいと考えています。
何をするべきでしょうか?
- A. 関連する BigQuery テーブルをソースとして使用する Data Studio ダッシュボードを作成し、BI チームに Data Studio ダッシュボードへのビュー アクセス権を付与します。
- B. BI チームのサービス アカウントを作成し、BI チームの各メンバーに新しい秘密鍵を配布します。
- C. Cloud Scheduler を使用してバッチ Dataflow ジョブをスケジュールし、BigQuery から BI チームの内部データ ウェアハウスにデータをコピーします。
- D. BigQuery ユーザーの IAM ロールを BI チームのメンバーを含む Google グループに割り当てます。
Answer: D
Question 179
会社はワークロード全体を Compute Engine に移行しています。
インターネット経由でアクセスできるサーバもあれば、内部ネットワーク経由でのみアクセスできるサーバもあります。すべてのサーバは特定のポートとプロトコルを介して相互に通信できる必要があります。現在のオンプレミス ネットワークは、パブリック サーバ用の非武装地帯 (DMZ) とプライベート サーバ用のローカル エリア ネットワーク (LAN) に依存しています。これらの要件を満たすように、Google Cloud のネットワーク インフラストラクチャを設計する必要があります。
何をするべきでしょうか?
- A.
- 1. DMZ 用のサブネットと LAN 用のサブネットを持つ単一の VPC を作成します。
- 2. DMZ と LAN サブネット間の関連トラフィックを開くファイアウォール ルールを設定し、DMZ へのパブリック トラフィック (内向き)を許可する別のファイアウォール ルールを設定します。
- B.
- 1. DMZ 用のサブネットと LAN 用のサブネットを持つ単一の VPC を作成します。
- 2. DMZ と LAN サブネット間の関連するトラフィックを開くファイアウォール ルールを設定し、DMZ のパブリック トラフィック (外向き) を許可する別のファイアウォール ルールを設定します。
- C.
- 1. DMZ のサブネットを持つ VPC と LAN のサブネットを持つ別の VPC を作成します。
- 2. DMZ と LAN サブネット間の関連トラフィックを開くファイアウォール ルールを設定し、DMZ へのパブリック トラフィック (内向き) を許可する別のファイアウォール ルールを設定します。
- D.
- 1. DMZ のサブネットを持つ VPC と LAN のサブネットを持つ別の VPC を作成します。
- 2. DMZ と LAN サブネット間の関連するトラフィックを開くファイアウォール ルールを設定し、DMZ のパブリック トラフィック (外向き) を許可する別のファイアウォール ルールを設定します。
Answer: A
Question 180
グローバルに分散されたアプリケーションをデプロイするために使用される新しいプロジェクトが作成されました。
データ ストレージには Cloud Spanner を使用し、Cloud Spanner インスタンスを作成したいと考えています。インスタンスを作成する準備として最初のステップを実行します。
何をするべきでしょうか?
- A. Cloud Spanner API を有効にします。
- B. Cloud Spanner インスタンスをマルチリージョンになるように構成します。
- C. 必要なすべてのリージョンにサブネットワークを持つ新しい VPC ネットワークを作成します。
- D. Cloud Spanner 管理者の IAM ロールを自分自身に付与します。
Answer: A
Reference:
–インスタンスについて | Cloud Spanner | Google Cloud
Question 181
gcloud コマンドライン インターフェース (CLI) を使用して Google Cloud に新しいプロジェクトを作成し、請求先アカウントをリンクしました。
CLI を使用して新しい Compute Engine インスタンスを作成する必要があります。前提条件の手順を実行する必要があります。
何をするべきでしょうか?
- A. クラウド監視ワークスペースを作成します。
- B. プロジェクトで VPC ネットワークを作成します。
- C. コンピューティング googleapis.com API を有効にします。
- D. コンピュータ管理者の IAM ロールを自分自身に付与します。
Answer: C
Reference:
–Launching a Google Cloud Virtual Machine (VM) — ISB Cancer Gateway in the Cloud 2.0.0 documentation
Question 182
会社は複数のマイクロサービスで構成される新しいアプリケーションを開発しました。
あなたはアプリケーションを Google Kubernetes Engine (GKE) にデプロイしたいと考えており、将来さらに多くのアプリケーションがデプロイされたときにクラスタがスケーリングできるようにしたいと考えています。新しいアプリケーションをデプロイするたびに手動で介入することは避けたいと考えています。
何をするべきでしょうか?
- A. アプリケーションを GKE にデプロイし、そのデプロイに HorizontalPodAutoscaler を追加します。
- B. アプリケーションを GKE にデプロイし、VerticalPodAutoscaler をデプロイに追加します。
- C. ノードプールで自動スケーリングを有効にして GKE クラスタを作成します。ノード プールのサイズの最小値と最大値を設定します。
- D. アプリケーションごとに個別のノード プールを作成し、各アプリケーションを専用のノード プールにデプロイします。
Answer: C
Question 183
Compute Engine インスタンスで実行されるサードパーティ アプリケーションを管理する必要があります。
他の Compute Engine インスタンスはデフォルト構成ですでに実行されています。アプリケーションのインストール ファイルは Cloud Storage でホストされます。他の仮想マシン (VM) がこれらのファイルにアクセスすることを許可せずに新しいインスタンスからこれらのファイルにアクセスする必要があります。
何をするべきでしょうか?
- A. デフォルトの Compute Engine サービス アカウントでインスタンスを作成します。サービス アカウントに Cloud Storage の権限を付与します。
- B. デフォルトの Compute Engine サービス アカウントでインスタンスを作成します。新しいインスタンスのメタデータと一致する Cloud Storage のオブジェクトにメタデータを追加します。
- C. 新しいサービス アカウントを作成し、このサービス アカウントを新しいインスタンスに割り当てます。サービス アカウントに Cloud Storage の権限を付与します。
- D. 新しいサービス アカウントを作成し、このサービス アカウントを新しいインスタンスに割り当てます。新しいインスタンスのメタデータと一致する Cloud Storage のオブジェクトにメタデータを追加します。
Answer: C
Reference:
–サービス アカウント | Compute Engine ドキュメント | Google Cloud
Question 184
最小限のコストで Cloud Storage に保存されたファイルに最適なデータ ストレージを構成する必要があります。
ファイルは、継続的に使用されるミッション クリティカルな分析パイプラインで使用されます。ユーザーは米国マサチューセッツ州ボストンにいます。
何をするべきでしょうか?
- A. ユーザーに最も近いリージョンのリージョン ストレージを構成します。Nearline ストレージ クラスを構成します。
- B. ユーザーに最も近いリージョンのリージョン ストレージを構成します。Standard ストレージ クラスを構成します。
- C. ユーザーに最も近いデュアル リージョンにデュアルリージョン ストレージを構成します。Nearline ストレージ クラスを構成します。
- D. ユーザーに最も近いデュアル リージョンにデュアルリージョン ストレージを構成します。Standard ストレージ クラスを構成します。
Answer: D
Question 185
Google Cloud Platform にデプロイされる新しいウェブ アプリケーションを開発しています。
リリース サイクルの一環として、実際のユーザー トラフィックのごく一部でアプリケーションの更新をテストしたいと考えています。大多数のユーザーは引き続きアプリケーションの安定したバージョンに向けられるべきです。
何をするべきでしょうか?
- A. アプリケーションを App Engine にデプロイします。更新ごとに同じサービスの新しいバージョンを作成します。トラフィックのごく一部を新しいバージョンに送信するようにトラフィック分割を構成します。
- B. アプリケーションを App Engine にデプロイします。更新ごとに新しいサービスを作成します。トラフィックのごく一部を新しいサービスに送信するようにトラフィック分割を構成します。
- C. アプリケーションを Kubernetes Engine にデプロイします。新しいリリースの場合は、デプロイメントを更新して新しいバージョンを使用します。
- D. アプリケーションを Kubernetes Engine にデプロイします。新しいリリースの場合は、新しいバージョンの新しい展開を作成します。新しい展開を利用できるようにサービスを更新します。
Answer: A
Reference:
–Admin API でトラフィックの移行と分割を行う | App Engine Admin API | Google Cloud
Question 186
新しいユーザーのグループを Cloud Identity に追加する必要があります。
一部のユーザーは既存の Google アカウントを既に持っています。Google のベストプラクティスの 1 つに従い、競合するアカウントを避けたいと考えています。
何をするべきでしょうか?
- A. 既存のアカウントを移行するようユーザーに依頼します。
- B. メール エイリアスを使用して競合を解決するようにユーザーを招待します。
- C. 既存のアカウントを削除する必要があることをユーザーに伝えます。
- D. ユーザーに既存のアカウントからすべての個人メールを削除するように伝えます。
Answer: A
Reference:
–Cloud Identity のユーザー アカウントを作成する – Cloud Identity ヘルプ
Question 187
最高のクエリ パフォーマンスを得るには Cloud Spanner インスタンスを管理する必要があります。
本番環境のインスタンスは単一の Google Cloud リージョンで実行されます。最短時間でパフォーマンスを向上させる必要があります。サービス構成について Google のベスト プラクティスに従う必要があります。
何をするべきでしょうか?
- A. Cloud Monitoring でアラートを作成して優先度の高い CPU 使用率の割合が 45% に達したときにアラートを出します。このしきい値を超えた場合はインスタンスにノードを追加してください。
- B. Cloud Monitoring でアラートを作成して優先度の高い CPU 使用率が 45% に達したときにアラートを出します。データベース クエリ統計を使用して CPU 使用率が高いクエリを特定し、それらのクエリを書き直して、リソースの使用を最適化します。
- C. Cloud Monitoring でアラートを作成して優先度の高い CPU 使用率が 65% に達したときにアラートを出します。このしきい値を超えた場合はインスタンスにノードを追加してください。
- D. Cloud Monitoring でアラートを作成して優先度の高い CPU 使用率の割合が 65% に達したときにアラートを出す。データベース クエリ統計を使用して CPU 使用率が高いクエリを特定し、それらのクエリを書き直してリソースの使用を最適化します。
Answer: C
Reference:
–インスタンスについて | Cloud Spanner | Google Cloud
Question 188
会社には取引注文を管理するための社内アプリケーションがあります。
アプリケーションは単一の物理的な場所にいる従業員のみが使用します。アプリケーションには、複数テーブルのトランザクション更新のための強力な一貫性、高速クエリ、ACID 保証が必要です。アプリケーションの最初のバージョンは PostgreSQL に実装されており、最小限のコード変更でクラウドにデプロイしたいと考えています。
このアプリケーションに最も適したデータベースはどれですか?
- A. BigQuery
- B. Cloud SQL
- C. Cloud Spanner
- D. Datastore
Answer: B
Reference:
–トランザクションについて | Cloud Spanner | Google Cloud
Question 189
あなたは Google Cloud にデプロイされた「dev」という名前の Google Kubernetes Engine (GKE) クラスタを維持するように割り当てられています。
コマンドライン インターフェース (CLI) を使用して GKE 構成を管理したいと考えています。Cloud SDK をダウンロードしてインストールしました。今後の CLI コマンドがデフォルトでこの特定のクラスタに対応するようにする必要があります。
何をするべきでしょうか?
- A. コマンド gcloud config set container/cluster dev を使用します。
- B. コマンド gcloud container clusters update dev を使用します。
- C. ~/.gcloud フォルダーにクラスタ名を含む gke.default というファイルを作成します。
- D. ~/.gcloud フォルダーにクラスタ名を含む defaults.json という名前のファイルを作成します。
Answer: A
Reference:
–kubectl をインストールしてクラスタ アクセスを構成する | Google Kubernetes Engine (GKE) | Google Cloud
Question 190
営業チームには ID acme-data-digest を持つ Sales Data Digest という名前のプロジェクトがあります。
マーケティング チーム用に同様の Google Cloud リソースを設定する必要がありますが、そのリソースはセールス チームとは別に編成する必要があります。
何をするべきでしょうか?
- A. プロジェクト編集者の役割を acme-data-digest のマーケティング チームに付与します。
- B. acme-data-digest でプロジェクト リーエンを作成し、プロジェクト編集者の役割をマーケティング チームに付与します。
- C. マーケティング チーム用に acme-marketing-data-digest という ID で別のプロジェクトを作成し、そこにリソースをデプロイします。
- D. Marketing Data Digest という名前の新しいプロジェクトを作成し、ID acme-data-digest を使用します。プロジェクト編集者の役割をマーケティング チームに付与します。
Answer: C
Question 191
Compute Engine に複数の Linux インスタンスをデプロイしました。
今後数週間でさらにインスタンスを追加する予定です。既存のインスタンスと新しいインスタンスで特定のアクセスを構成することなく、インターネット経由で SSH クライアントを介してこれらすべてのインスタンスにアクセスできるようにしたいと考えています。Compute Engine インスタンスにパブリック IP を持たせたくありません。
何をするべきでしょうか?
- A. HTTPS リソース用に Cloud Identity-Aware Proxy を構成します。
- B. SSH 、TCP リソース用に Cloud Identity-Aware Proxy を構成する
- C. SSH キーペアを作成し、公開キーをプロジェクト全体の SSH キーとして保存します。
- D. SSH キーペアを作成し、秘密キーをプロジェクト全体の SSH キーとして保存します。
Answer: B
Question 192
Docker イメージにパッケージ化されたアプリケーションを作成しました。
Docker イメージをワークロードとして Google Kubernetes Engine にデプロイしたいと考えています。
何をするべきでしょうか?
- A. イメージを Cloud Storage にアップロードし、イメージを参照する Kubernetes Service を作成します。
- B. イメージを Cloud Storage にアップロードし、イメージを参照する Kubernetes Deployment を作成します。
- C. イメージを Container Registry にアップロードし、イメージを参照する Kubernetes Service を作成します。
- D. イメージを Container Registry にアップロードし、イメージを参照する Kubernetes Deployment を作成します。
Answer: D
Reference:
–コンテナ化されたウェブ アプリケーションのデプロイ | Kubernetes Engine | Google Cloud
Question 193
データスタジオを使用して BigQuery の上に構築されたデータ ウェアハウスのテーブルを視覚化しています。
データは日中にデータ ウェアハウスに追加されます。夜になると、テーブルを上書きして日次集計が再計算されます。データポータルのグラフが壊れていることに気付き、問題を分析したいと考えています。
何をするべきでしょうか?
- A. Cloud Console の [Error Reporting] ページを確認し、エラーを見つけます。
- B. BigQuery インターフェースを使用し、夜間ジョブを確認し、エラーを探します。
- C. Cloud Debugger を使用し、データが正しく更新されなかった理由を調べます。
- D. Cloud Logging でデータポータル レポートのフィルタを作成します。
Answer: D
Question 194
新しい Google Cloud のお客様の請求構成をセットアップするよう依頼されました。
顧客は共通の IAM ポリシーを共有するリソースをグループ化することを望んでいます。
何をするべきでしょうか?
- A. ラベルを使用し、共通の IAM ポリシーを共有するリソースをグループ化します。
- B. フォルダーを使用し、共通の IAM ポリシーを共有するリソースをグループ化します。
- C. IAM ポリシーをグループ化するための適切な請求先アカウント構造を設定します。
- D. IAM ポリシーをグループ化するための適切なプロジェクト命名構造を設定します。
Answer: B
Question 195
新しい Virtual Private Cloud (VPC) とリモート サイトの間に堅牢な Virtual Private Network (VPN) 接続を作成するよう依頼されました。
主な要件には動的ルーティング、10.19.0.1/22 の共有アドレス空間、フェイルオーバーイベント中のトンネルのオーバープロビジョニングがないことが含まれます。Google が推奨する方法に従って高可用性の Cloud VPN を設定する必要があります。
何をするべきでしょうか?
- A. カスタム モードの VPC ネットワークを使用して静的ルートを構成し、アクティブ/パッシブ ルーティングを使用します。
- B. 自動モードの VPC ネットワークを使用して静的ルートを構成し、アクティブ/アクティブ ルーティングを使用します。
- C. カスタム モードの VPC ネットワークを使用して Cloud Router ボーダー ゲートウェイ プロトコル (BGP) ルートを使用し、アクティブ / パッシブ ルーティングを使用します。
- D. 自動モードの VPC ネットワークを使用し、Cloud Router Border Gateway Protocol (BGP) ルートを使用してポリシーベースのルーティングを構成します。
Answer: C
Question 196
Kubernetes Engine クラスタで複数のマイクロサービスを実行しています。
1 つのマイクロサービスが画像をレンダリングしています。画像のレンダリングを担当するマイクロサービスは、必要なメモリに比べて大量の CPU 時間を必要とします。その他のマイクロサービスは n1-standard マシンタイプ向けに最適化されたワークロードです。すべてのワークロードができるだけ効率的にリソースを使用するようにクラスタを最適化する必要があります。
何をするべきでしょうか?
- A. 画像レンダリング マイクロサービスのポッドに他のマイクロサービスよりも高いポッド優先度を割り当てます。
- B. 画像レンダリング マイクロサービス用のコンピューティング最適化マシンタイプ ノードを含むノード プールを作成します。他のマイクロサービス用の汎用マシンタイプ ノードでノード プールを使用します。
- C. イメージ レンダリング マイクロサービス用の汎用マシン タイプ ノードでノード プールを使用します。他のマイクロサービス用のコンピューティング最適化マシンタイプ ノードを含むノード プールを作成します。
- D. 画像レンダリング マイクロサービス展開のリソース要求仕様で必要な CPU とメモリの量を構成します。他のマイクロサービスのリソース リクエストはデフォルトのままにします。
Answer: B
Question 197
組織には 3 つの既存の Google Cloud プロジェクトがあります。
グループ内の新しいイニシアチブについて Google Cloud サービスのみについてマーケティング部門に請求する必要があります。
何をするべきでしょうか?
- A.
- 1. 組織のマーケティング部門の Google Cloud プロジェクトの課金管理者 IAM ロールが割り当てられていることを確認します。
- 2. 新しいプロジェクトをマーケティング請求先アカウントにリンクします。
- B.
- 1. 組織の Google Cloud アカウントの課金管理者 IAM ロールが割り当てられていることを確認します。
- 2. マーケティング部門用に新しい Google Cloud プロジェクトを作成します。
- 3. このプロジェクトのすべてのサービスについて デフォルトのキー値プロジェクト ラベルを department:marketing に設定します。
- C.
- 1. 組織の Google Cloud アカウントの組織管理者 IAM ロールが割り当てられていることを確認します。
- 2. マーケティング部門用に新しい Google Cloud プロジェクトを作成します。
- 3. 新しいプロジェクトをマーケティング請求先アカウントにリンクします。
- D.
- 1. 組織の Google Cloud アカウントの組織管理者 IAM ロールが割り当てられていることを確認します。
- 2. マーケティング部門用に新しい Google Cloud プロジェクトを作成します。
- 3. このプロジェクトのすべてのサービスについて、デフォルトのキー値プロジェクト ラベルを department:marketing に設定します。
Answer: A
Comments are closed