![[GCP ]Google Cloud Certified - Professional Machine Learning Engineer](https://www.cloudsmog.net/wp-content/uploads/Professional-Machine-Learning-Engineer.png)
※ 他の問題集は「タグ:Professional Machine Learning Engineer の模擬問題集」から一覧いただけます。
Google Cloud 認定資格 – Professional Machine Learning Engineer – 模擬問題集(全 60問)
Question 1
リアルタイムセンサーデータの異常を検出するためのMLモデルを構築しています。
Google Cloud Pub / Sub を使用して着信リクエストの処理を行い、 分析と視覚化のために結果を保存したい考えています。
パイプラインをどのように構成すればいいでしょうか?
- A. 1 = Google Cloud Dataflow、2 = Google Cloud AI Platform、3 = Google BigQuery
- B. 1 = Google Cloud Dataproc、2 = Google Cloud AutoML、3 = Google Cloud Bigtable
- C. 1 = Google BigQuery、2 = Google Cloud AutoML、3 = Google Cloud Functions
- D. 1 = Google BigQuery、2 = Google Cloud AI Platform、3 = Google Cloud Storage
Correct Answer: C
Reference:
– Dataflow、BigQuery ML、Cloud Data Loss Prevention を使用した安全な異常検出ソリューションの構築
Question 2
会社は内部シャトルサービスのルートをより効率的にしたいと考えています。
現在、シャトルは午前 7時から午前 10時まで 30分ごとに市内のすべての停留ポイントに停車します。 開発チームはすでに Google Kubernetes Engine でアプリケーションを構築しており、ユーザーは前日に自分のポイントと停留所を確認する必要があります。
どのようなアプローチを取るべきでしょうか?
- A.
- 各停留所でピックアップされる乗客の数を予測するツリーベースの回帰モデルを構築します。
- 予測に基づいて適切なサイズのシャトルを派遣し、地図上に必要な停車地を示します。
- B.
- シャトルが各停留所で乗客を迎えに行くべきかどうかを予測するツリーベースの分類モデルを構築します。
- 予測に基づいて利用可能なシャトルを派遣し、地図上に必要な停車地を示します。
- C.
- 最適なルートを容量制約の下で指定された時間に出席が確認されたすべての停留所を通過する最短ルートとして定義します。
- 適切なサイズのシャトルを派遣し、地図上に必要な停車地を示します。
- D.
- エージェントとしての停留所での乗客のポイントを予測するツリーベースの分類モデルと距離ベースのメトリックの周りの報酬関数を使用して強化学習モデルを構築します。
- 適切なサイズのシャトルを派遣し、シミュレートされた結果に基づいて地図上に必要な停車地を示します。
Correct Answer: A
Question 3
センサーの読み取り値に基づいて生産ラインでの部品の故障を調査するように依頼されました。
データセットを受け取った後、読み取り値の 1%未満が故障インシデントを表す正例であることがわかりました。いくつかの分類モデルをトレーニングしましたがどれも収束しませんでした。
クラスの不均衡問題をどのように解決するべきでしょうか?
- A. クラス分布を使用して 10%の正例を生成します。
- B. 最大プーリングとソフトマックス活性化を備えた畳み込みニューラル ネットワークを使用します。
- C. 10%の肯定的な例を含むサンプルを作成するためにアップウェイトを使用してデータをダウンサンプリングします。
- D. 正例と負例の数が等しくなるまで負例を削除します。
Correct Answer: B
Reference:
– ML Practicum: Image Classification | Machine Learning Practica
– Convolutional Neural Networks — A Beginner’s Guide | by Krut Patel
Question 4
Google Cloud で構造化データ用にML パイプラインの再構築と検討しています。
PySpark を使用して大規模なデータ変換を実行していますがパイプラインの実行に 12時間以上かかっています。 開発とパイプラインの実行時間を短縮するにはサーバーレスツールとSQL 構文を使用する必要があります。 生データはすでに Google Cloud Storage に移動しています。
速度と処理の要件を満たしながら Google Cloud でパイプラインをどのように構築するべきでしょうか?
- A. Google Cloud Data Fusion の GUI を使用して変換パイプラインを構築し、データを Google BigQuery に書き込みます。
- B. PySpark をSpark SQL クエリに変換してデータを変換してから Google Cloud Dataproc でパイプラインを実行し、データを Google BigQuery に書き込みます。
- C. データを GoogleCloud SQL に取り込み、PySpark コマンドをSQL クエリに変換してデータを変換してから Google BigQuery のフェデレーションクエリを使用して機械学習を行います。
- D. Google BigQuery Load を使用してデータを Google BigQuery に取り込み、PySpark コマンドを Google BigQuery SQL クエリに変換し、データを変換してから変換を新しいテーブルに書き込みます。
Correct Answer: B
Question 5
クラウド ベースのバックエンド システムを使用してトレーニング ジョブを送信するデータ サイエンティスト チームを管理します。
このシステムの管理は非常に困難になっているため、代わりにマネージド サービスを使用する必要があります。チームのデータ サイエンティストはKeras、PyTorch、theano、Scikit-learn、カスタムライブラリ など様々なフレームワークを使用しています。
どうしたらいいでしょうか?
- A. Google Cloud AI Platform のカスタム コンテナ機能を使用して任意のフレームワークを使用したトレーニング ジョブを受け取ることができます。
- B. Google Kubernetes Engine で動作するように Kubeflow を設定して TF Jobを通じてトレーニング ジョブを受信します。
- C. Google Compute Engine でVM イメージのライブラリを作成し、これらのイメージを中央のリポジトリ上で公開します。
- D. Slurm workload manager を設定してクラウド インフラストラクチャ上で実行するようにスケジュールできるジョブを受信します。
Correct Answer: D
Reference:
– Slurm Workload Manager – Cloud Scheduling Guide
Question 6
画像検索エンジンを作成しているオンライン小売会社で働いています。
画像に自社の製品が含まれているかどうかを分類するために Google Cloud でエンドツーエンドのML パイプラインを構築しました。近い将来、新製品がリリースされることが予想されており、パイプラインに再トレーニング機能を構成し、新しいデータをML モデルにフィードできるようにしました。 また、Google Cloud AI Platform の継続評価サービスを利用してテストデータセットでモデルが高い精度を持つことを確認したいと考えています。
どうすればいいでしょうか?
- A. 新製品が再トレーニングに組み込まれている場合でも元のテストデータ セットは変更しません。
- B. 新製品が再トレーニングに導入されたときにそれらの画像を使用してテストデータ セットを拡張します。
- C. 再トレーニングが導入されたらテストデータ セットを新製品の画像に置き換えます。
- D. 評価指標が事前に決定されたしきい値を下回ったときに新製品の画像でテストデータ セットを更新します。
Correct Answer: C
Question 7
現在 Google BigQuery に保存されているいくつかの構造化データセットに対して分類ワークフローを構築する必要があります。
分類作業は何度も行うことになるため、コードを書かずに次のステップを完了させたいと考えています。探索的データ分析 / 特徴選択 / モデル構築 / トレーニング / ハイパーパラメータの調整と提供
何をするべきでしょうか?
- A. Google Cloud AutoML Tables を設定して分類タスクを実行します。
- B. Google BigQuery ML を実行して分類のロジスティック回帰を実行します。
- C. Google Cloud AI Platform Notebooks を使用してpandas ライブラリで分類モデルを実行します。
- D. Google Cloud AI Platform を使用してハイパーパラメータ調整用に構成された分類モデル ジョブを実行します。
Correct Answer: B
Google BigQuery ML はロジスティック回帰モデルタイプの教師あり学習をサポートしています。
Reference:
– 国勢調査データに基づいた分類モデルの構築と使用 | Google BigQuery ML
Question 8
公共交通機関で働いており、複数の交通ルートの遅延時間を予測するモデルを構築する必要があります。
予測結果はアプリでユーザーにリアルタイムで直接提供されます。 季節や人口の増加がデータの関連性に影響を与えるため、毎月モデルを再トレーニングします。 Google のベストプラクティスに従います。
予測モデルのエンドツーエンド アーキテクチャをどのように構成するべきでしょうか?
- A. Kubeflow Pipelines を構築してトレーニングからモデルのデプロイまでのマルチステップのワークフローをスケジュールします。
- B. Google BigQuery ML でトレーニングおよびデプロイされたモデルを使用し、Google BigQuery のスケジュールされたクエリ機能を使用して再トレーニングをトリガーします。
- C. Google Cloud Scheduler によってトリガーされる Google Cloud AI Platform でトレーニングとデプロイのジョブを起動する Google Cloud Functions スクリプトを作成します。
- D. Google Cloud Composer を使用してトレーニングからモデルのデプロイまでのワークフローを実行する Google Cloud Dataflow ジョブをプログラムでスケジュールします。
Correct Answer: A
Reference:
– Understanding Kubeflow pipelines and components | AI Hub
– TFX、Kubeflow Pipelines、Cloud Build を使用した MLOps のアーキテクチャ
Question 9
Google Cloud AI Platform を使って CT スキャンの画像セグメンテーションのためのML モデルを開発しています。
最新の研究論文に基づいてモデルのアーキテクチャを頻繁に更新し、同じデータセットでトレーニングを再実行して性能を評価する必要があります。。 コードのバージョン管理を行いながら、計算コストと手動介入を最小限に抑えたいと考えています。
どうすればいいでしょうか?
- A. Google Cloud Functions を使用して Google Cloud Storage 内のコードへの変更を識別し、再トレーニングジョブをトリガーします。
- B. gcloud コマンドラインツールを使用してコードを更新したときに Google Cloud AI Platform でトレーニング ジョブを送信します
- C. Google Cloud Source Repositories とリンクされた Google Cloud Build を使用して新しいコードがリポジトリにプッシュされたときに再トレーニングをトリガーします。
- D. Google Cloud Composer で自動ワークフローを作成し、毎日実行し、センサーを使用して Google Cloud Storage 内のコード変更を検索します。
Correct Answer: B
Reference:
– トレーニング ジョブの実行 | Google Cloud AI Platform Training
Question 10
チームは画像に運転免許証、パスポート、またはクレジットカードが含まれているかどうかを予測するモデルを構築する必要があります。
データエンジニアリング チームはすでにパイプラインを構築し、転免許証が写っている 10,000 枚の画像、パスポートが写っている 1,000 枚の画像、クレジットカードが写っている 1,000 枚の画像からなるデータセットを生成しました。
次に、次のラベルマップを使用してモデルをトレーニングする必要があります。
[‘drivers_license’, ‘passport’, ‘credit_card’]
どの損失関数を使うべきでしょうか?
- A. Categorical hinge
- B. Binary cross-entropy
- C. Categorical cross-entropy
- D. Sparse categorical cross-entropy
Correct Answer: D
Reference:
– Learning Effective Loss Functions | AI Workshop Experiments
– Cross Entropy vs. Sparse Cross Entropy: When to use one over the other – Cross Validated
Question 11
会社のeコマース Web サイトで買い物客向けのML 推奨モデルを設計しています。
システムの構築、テスト、デプロイには Recommendations AI を使用します。
ベストプラクティスに従いながら収益を増やす推奨事項をどのように作成するべきでしょうか?
- A. クリック率を上げるために「他の商品もいかがですか」というレコメンド タイプを使用します。
- B. 「よく一緒に買われている商品」レコメンド タイプを使用して各注文のショッピングカートのサイズを大きくします。
- C. ユーザーイベントをインポートしてから商品カタログをインポートし、最高品質のイベント ストリームを確保します。
- D. 製品データの収集と記録には時間がかかるため、製品カタログにはプレースホルダー値を使用してモデルの実行可能性をテストします。
Correct Answer: B
「よく一緒に買われている」レコメンデーションは商品を提供することでお客様にアップセル、クロスセルを狙うものです。
Reference:
– Recommendation model types #Frequently bought together (shopping cart expansion) | Recommendations AI
– Amazon’s Recommendation Engine: The Secret To Selling More Online
Question 12
カスタマーサポートのチケットがサポートエージェントに転送される前に情報のあるメタデータでリッチ化するためにサーバーレス ML システムを使ったアーキテクチャを設計しています。
チケットの優先度とチケットの解決時間を予測し、センチメント分析を行い、エージェントがサポート リクエストを処理する際に戦略的な意思決定を行えるようにするためのモデル群が必要です。チケットにはドメイン固有の用語や専門用語はないものとします。
提案されたアーキテクチャには次のフローになります。
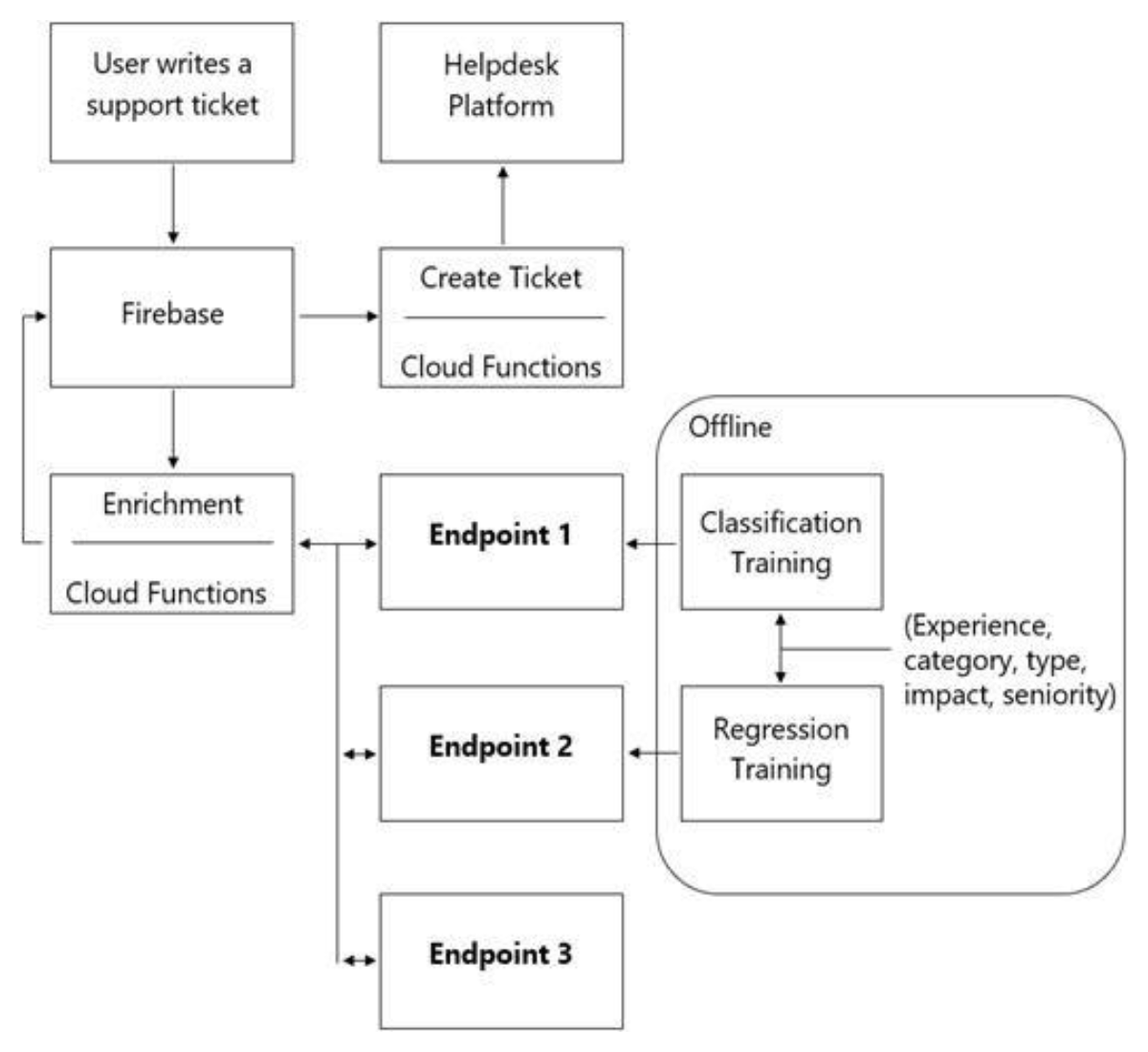
Enrichment Google Cloud Functions が呼び出すべきエンドポイントはどれでしょうか?
- A. 1 = Google Cloud AI Platform, 2 = Google Cloud AI Platform, 3 = Google Cloud AutoML Vision
- B. 1 = Google Cloud AI Platform, 2 = Google Cloud AI Platform, 3 = Google Cloud AutoML Natural Language
- C. 1 = Google Cloud AI Platform, 2 = Google Cloud AI Platform, 3 = Google Cloud Natural Language API
- D. 1 = Cloud Natural Language API, 2 = Google Cloud AI Platform, 3 = Google Cloud Vision API
Correct Answer: B
Question 13
Google Cloud でディープ ニューラル ネットワークモデルをトレーニングしました。
このモデルはトレーニングデータでは損失が少ないのですが検証データではパフォーマンスが低下しています。このモデルを過学習に強いものにしたいと考えています。
モデルを再トレーニングする際にはどの戦略を使うべきでしょうか?
- A. ドロップアウト パラメータを 0.2 に設定して学習率を 1/10 に下げます。
- B. L2 正則化パラメータを 0.4 に設定して学習率を 1/10 に下げます。
- C. Google Cloud AI Platform でハイパーパラメータ調整ジョブを実行し、L2 正則化とドロップアウトのパラメータを最適化します。
- D. Google Cloud AI Platform でハイパーパラメータ調整ジョブを実行し、学習率を最適化してニューロン数を 2倍にします。
Correct Answer: D
Reference:
– 過学習の防止 | BigQuery ML
– ハイパーパラメータ調整の概要 | AI Platform Training
– ハイパーパラメータ調整の使用 | AI Platform Training
– Generalization: Peril of Overfitting | Machine Learning Crash Course
– Training Neural Networks: Best Practices bookmark_border
Question 14
販売数を予測する役割を担う生産システムを構築と管理しています。
生産モデルは市場の変化に対応する必要があるため、モデルの精度は非常に重要です。本番環境に導入されて以来、モデルは変更されておらず、モデルの精度は着実に低下しています。
モデルの精度が着実に低下する原因としてどのような問題が考えられますか?
- A. データ品質が悪質です。
- B. モデルの再トレーニングの欠如しています。
- C. モデル内の情報をキャプチャするためのレイヤーが少ないです。
- D. モデルのトレーニング、評価、検証、テスト中のデータ分割率が正しくありません。
Correct Answer: D
Question 15
異なるソースからの画像を低レイテンシーで処理する ML トレーニングモデルの入力パイプラインの開発を依頼されました。
しかし、入力データがメモリに収まらないことがわかりました。
Google のベストプラクティスに従ってどのようにデータセットを作成すればよいでしょうか?
- A. tf.data.Dataset.prefetch transformation を作成します。
- B. 画像を tf.Tensor オブジェクトに変換して Dataset.from_tensor_slices() を実行します。
- C. 画像を tf.Tensor オブジェクトに変換して tf.data.Dataset.from_tensors() を実行します。
- D. 画像を TFRecords に変換して Google Cloud Storage に保存し、tf.data APIを使って学習用の画像を読み込みます。
Correct Answer: B
Reference:
– tf.data.Dataset
– tf.data:TensorFlow入力パイプラインを構築する
Question 16
複数の地域に店舗を持つ大手食料品小売業の ML エンジニアで在庫予測モデルの作成を依頼されました。
モデルの特徴は地域、場所、過去の需要、季節の人気などでアルゴリズムを毎日の新しい在庫データから学習させたいと考えています。
モデルを構築するためにどのアルゴリズムを使用すべきでしょうか?
- A. 分類
- B. 強化学習
- C. リカレント ニューラル ネットワーク(RNN)
- D. 畳み込みニューラル ネットワーク (CNN)
Correct Answer: B
Reference:
– GCP による深層強化学習 : ハイパーパラメータ調整と Cloud ML Engineで OpenAI Gym ゲームを攻略
– Learning Machine Learning | Cloud AI
– 5 Things You Need to Know about Reinforcement Learning
Question 17
個人を特定できる情報(PII)を含む可能性のあるファイルを Google Cloud にストリーミングするリアルタイム予測エンジンを構築しています。
Google Cloud Data Loss Prevention(DLP)API を使用してファイルをスキャンするとします。
許可されていない個人が PII にアクセスできないようにするにはどうすればよいでしょうか?
- A. すべてのファイルを Google Cloud にストリーミングし、そのデータを Google BigQuery に書き込みます。定期的に Google Cloud DLP API を使用してテーブルの一括スキャンを行います。
- B. すべてのファイルを Google Cloud にストリーミングし、データのバッチを Google BigQuery に書き込みます。Google BigQuery にデータを書き込んでいる間に Google Cloud DLP API を使用してデータの一括スキャンを行います。
- C. 機密データと非機密データの 2つのバケットを作成して すべてのデータを非機密 バケットに書き込みます。すべてのデータを非機密のバケットに書き込みます。定期的にそのバケットを Google Cloud DLP API で一括スキャンして機密データを機密 バケットに移動させます。
- D. 検疫、機密、非機密の 3つのデータバケットを作成してすべてのデータを検疫 バケットに書き込みます。定期的に Google Cloud DLP API を使用してそのバケットの一括スキャンを行い、データを機密または非機密 バケットに移動します。
Correct Answer: A
Reference:
– 機密データの匿名化 | Data Loss Prevention Documentation
– Cloud DLP を使用した大規模なデータセットにおける PII の匿名化と再識別
– 機密データ保護に有用な DLP API の新機能
– BigQuery, PII, and Cloud Data Loss Prevention (DLP): Take it to the next level with Data Catalog
Question 18
大手ホテルチェーンに勤務しており、ターゲットマーケティング戦略のための予測を収集するためにマーケティング チームを支援するよう依頼されました。
今後 20日間の顧客の生涯価値(LTV)を予測し、それに応じてマーケティングを調整できるようにする必要があります。顧客データセットは Google BigQuery にあり、Google Cloud AutoML Tables でトレーニング用の表形式データを準備しています。このデータには複数の列にまたがるタイムシグナルがあります。
Google Cloud AutoML がデータに最適なモデルをフィットさせるにはどうすればよいでしょうか?
- A. タイムシグナルを含むすべての列を手動で配列に結合します。この配列を適切に解釈するように Google Cloud AutoML に指示し、トレーニングセット、検証セット、テストセットの自動データ分割を選択します。
- B. 手動分割を行わずにトレーニング用のデータを送信します。Google Cloud AutoML を使用して適切な変換を行い、トレーニングセット、検証セット、テストセットのの自動データ分割を選択します。
- C. 手動分割を行わずにトレーニング用のデータを送信し、適切な列を時間 列として指定します。Google Cloud AutoML に指示し、提供されたタイムシグナルに基づいてデータを分割し、より最近のデータを検証セットとテストセットに確保します。
- D. 手動分割を行わずにトレーニング用のデータを送信します。タイムシグナルのある列を使用して手動データ分割をします。検証セットのデータはトレーニングセットのデータの 30日後、テストセットのデータは検証セットの 30日後のデータであることを確認します。
Correct Answer: D
Reference:
– トレーニング データの準備 | AutoML Tables
– トレーニング データを作成するためのベスト プラクティス | AutoML Tables
– AI Platform を使用した顧客の生涯価値の予測: モデルのトレーニング
Question 19
カスタムライブラリを必要とする Kubeflow Pipelines 単体テストを作成しています。
Google Cloud Source Repositories の開発ブランチに新しくプッシュするたびに単体テストの実行を自動化したいと考えています。
どうすればいいのでしょうか?
- A. 開発ブランチへのプッシュを順次実行し、Google Cloud Run で単体テストを実行するスクリプトを作成します。
- B. Google Cloud Build を使用し、開発ブランチに変更がプッシュされたときに単体テストを実行する自動トリガーを設定します。
- C. Google Cloud Source Repositories とのやりとりをキャプチャする Google Cloud Pub/Subトピックに Google Cloud Logging の sink を設定します。Google Cloud Run 用の Google Cloud Pub/Subトリガーを設定し、Google Cloud Run で単体テストを実行します。
- D. Google Cloud Source Repositories とのやりとりをキャプチャする Google Cloud Pub/Subトピックに Google Cloud Logging の sink を設定します。Google Cloud Pub/Subトピックにメッセージが送信されたときにトリガーされる Google Cloud Functions を使用して単体テストを実行します。
Correct Answer: B
Reference:
– TFX、Kubeflow Pipelines、Cloud Build を使用した MLOps のアーキテクチャ
Question 20
Google Cloud AI Platform で LSTM ベースのモデルを学習し、次のジョブ送信スクリプトを使ってテキストを要約しています。
gcloud ai-platform jobs submit training $JOB_NAME \
--package-path $TRAINER_PACKAGE_PATH \
--module-name $MAIN_TRAINER_MODULE \
--job-dir $JOB_DIR \
--region $REGION \
--scale-tier basic \
-- \
--epochs 20 \
--batch_size=32 \
--learning_rate=0.001 \モデルの精度を大幅に低下させることなく、トレーニング時間を最小限に抑えたいと考えています。
どうすればいいのでしょうか?
- A. 「epochs」を修正します。
- B. 「scale-tier」を修正します。
- C. 「batch_size」を修正します。
- D. 「learning_rate」を修正します。
Correct Answer: C
Question 21
Google Cloud AI Platform で複数のバージョンの画像分類モデルをデプロイしました。
モデルのバージョンのパフォーマンスを長期的に監視したいと考えています。
この比較はどのように行うべきでしょうか?
- A. 差し出されたデータセットの各モデルの損失パフォーマンスを比較します。
- B. 検証データの各モデルの損失パフォーマンスを比較します。
- C. What-If ツールを使用して各モデルの受信者動作特性(ROC)曲線を比較します。
- D. 継続的評価 機能を使用してモデル全体の平均平均精度を比較します。
Correct Answer: B
Reference:
– 評価指標の表示 | AI Platform Prediction
– モデル バージョンのモニタリング | AI Platform Prediction
Question 22
テキスト分類モデルを学習しました。次の SignatureDef があります。
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input (s):
inputs['text'] tensor_info:
dtype: DT_STRING shape: (-1, 2)
name: serving_default_text: 0
The given SavedModel SignatureDef contains the following output (s):
outputs ['softmax'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 2)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predictTensorFlow Servingコンポーネント サーバーを起動し、HTTP リクエストを送信して予測値を取得しようとしました。
headers = {"content -type": "application/json"}
json_response = requests.post('http://localhost:8501/v1/models/text_model:predict', data=data, headers=headers)予測されたリクエストを書く正しい方法はどれでしょうか?
- A. data = json.dumps({“signature_name”: “seving_default”, “instances” [[‘ab’, ‘bc’, ‘cd’]]})
- B. data = json.dumps({“signature_name”: “serving_default”, “instances” [[‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’]]})
- C. data = json.dumps({“signature_name”: “serving_default”, “instances” [[‘a’, ‘b’, ‘c’], [‘d’, ‘e’, ‘f’]]})
- D. data = json.dumps({“signature_name”: “serving_default”, “instances” [[‘a’, ‘b’], [‘c’, ‘d’], [‘e’, ‘f’]]})
Correct Answer: C
Reference:
– TensorFlowServingを使用してTensorFlowモデルをトレーニングして提供する | TFX
Question 23
組織のコールセンターから各通話のお客様の感情を分析するモデルの開発を依頼されました。
コールセンターには毎日 100万件以上の電話がかかってきており、データは Google Cloud Storage に保存されています。収集されたデータは通話が発生した地域を離れてはならず、個人を特定できる情報(PII)を保存や分析したりすることはできません。データサイエンス チームは可視化とアクセスするためのサードパーティ ツールを使用していますが SQL ANSI-2011に準拠したインターフェースが必要でデータ処理用と分析用のコンポーネントを選択する必要があります。
データパイプラインはどのように設計すべきでしょうか?
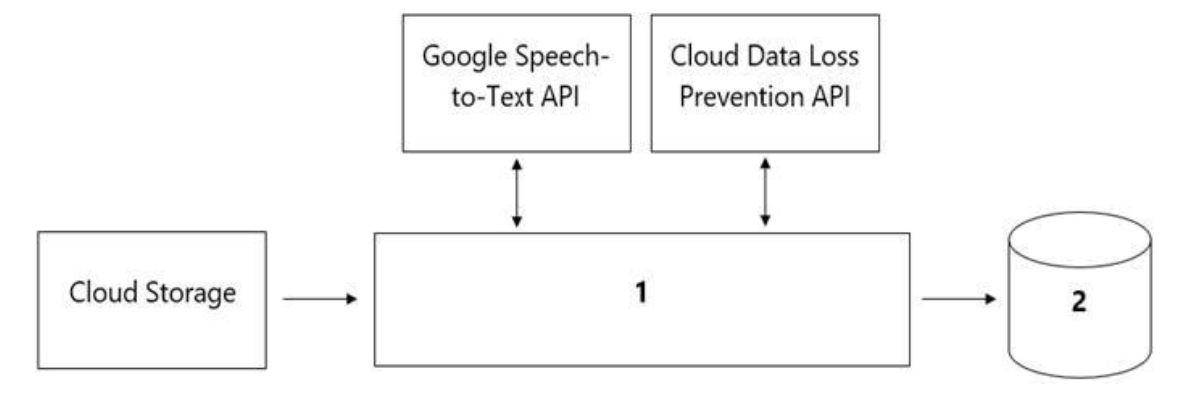
- A. 1 = Google Cloud Dataflow, 2= Google BigQuery
- B. 1 = Google Cloud Pub/Sub, 2= Google Cloud Datastore
- C. 1 = Google Cloud Dataflow, 2 = Google Cloud SQL
- D. 1 = Google Cloud Functions, 2= Google Cloud SQL
Correct Answer: B
Question 24
世界的なシューズショップのML エンジニアをしています。
会社のWeb サイトのML モデルを管理しています。ユーザーの購買行動や他のユーザーとの類似性に基づいて、ユーザーに新商品を推奨するモデルを構築するように求められています。
何をすべきでしょうか?
- A. 分類モデルを構築します。
- B. 知識ベースのフィルタリング モデルを構築します。
- C. コラボレーションベースのフィルタリング モデルの構築します。
- D. 特徴量を予測変数とした回帰モデルを構築します。
Correct Answer: C
Reference:
– Compute Engine で機械学習を使用して商品のおすすめを生成する
Question 25
ソーシャルメディアの会社で働いています。
投稿された画像に車が写っているかどうかを検出する必要があります。各トレーニング例は正確に 1つのクラスのメンバーです。オブジェクト検出 ニューラル ネットワークをトレーニングし、評価のためにモデル バージョンを Google Cloud AI Platform Prediction にデプロイしました。デプロイする前に評価ジョブを作成し、Google Cloud AI Platform Prediction モデルバージョンに添付しましたが精度がビジネス要件の許容範囲よりも低いことに気づきました。
精度を上げるためにはモデルの最終レイヤーソフトマックスしきい値をどのように調整すればよいでしょうか?
- A. リコールを増やします。
- B. リコールを減らします。
- C. 誤検知の数を増やします。
- D. 偽陰性の数を減らします。
Correct Answer: D
Reference:
– Multi-Class Neural Networks: Softmax | Machine Learning Crash Course
– 夏休みの自由工作:TensorFlowでじゃんけんマシンを作る
Question 26
様々なオンプレミスのデータマートを統合された分析環境を構築することになりました。
会社はサーバー間でデータを統合する際に様々なツールや一時的なソリューションを使用しているため、データ品質やセキュリティの問題が発生しています。完全に管理されたクラウド型のデータ統合サービスが必要である。 チームの一部のメンバーは抽出、変換、読み込み(ETL)プロセスを構築するためにコードレスなインターフェイスを求めています。
どのサービスを使うべきですでしょうか?
- A. Google Cloud Dataflow
- B. Google Cloud Dataprep
- C. Apache Flink
- D. Google Cloud Data Fusion
Correct Answer: D
Question 27
規制が厳しい保険会社のML エンジニアです。
潜在的な顧客からの保険申請を受け入れるか否かを決定する保険承認モデルを開発するように求められています。
モデルを構築する前にどのような要素を考慮する必要があるでしょうか?
- A. 編集、再現性、説明可能性
- B. トレーサビリティ、再現性、説明可能性
- C. 連合学習、再現性、説明可能性
- D. 差分プライバシー、連合学習、説明可能性
Correct Answer: A
Reference:
– Using explainable AI on tabular data
Question 28
Google Cloud AI Platform で TPU を使って Resnet モデルを学習し、自動車エンジンの欠陥の種類を視覚的に分類しています。
Google Cloud TPU Profiler プラグインを使用してトレーニング プロファイルをキャプチャしたところ、入力の制約が大きいことがわかりました。このボトルネックを解消し、モデルの学習プロセスを高速化したいと考えています。
tf.data データセットにどのような変更を加えるべきでしょうか?(回答を 2つ選択しなさい)
- A. データの読み込みにインターリーブ オプションを使用します。
- B. repeat パラメータの値を小さくする。
- C. shuttle オプションのバッファサイズを大きくする。
- D. プリフェッチ オプションをトレーニングのバッチサイズと同じに設定します。
- E. 変換時のバッチサイズ引数を小さくします。
Correct Answer: A、E
Reference:
– Cloud TPU ツールの使用
– パフォーマンス ガイド | Cloud TPU
– TensorFlow プロファイラによる tf.data パフォーマンスの分析
Question 29
計算コストの高い前処理操作を必要とするデータセットでモデルをトレーニングしました。
予測時にも同じ前処理を行う必要があり、ハイスループットのオンライン予測のために、Google Cloud AI Platform にモデルをデプロイしました。
どのアーキテクチャーを使うべきでしょうか?
- A.
- 前処理されたデータでトレーニングしたモデルの精度を検証します。
- 生データを使用してリアルタイムで利用可能な新しいモデルを作成します。
- オンライン予測のために新しいモデルを Google Cloud AI Platform にデプロイします。
- B.
- 受信した予測リクエストを Google Cloud Pub/Sub トピックに送信します。
- Google Cloud Dataflow ジョブを使用して受信データを変換します。
- 変換されたデータを使用して予測リクエストを Google Cloud AI Platform に送信します。予測をアウトバウンドの Google Cloud Pub/Sub キューに書き込みます。
- C.
- 受信した予測リクエスト データを Google Cloud Spanner にストリーミングします。
- 前処理ロジックを抽象化するビューを作成します。
- 1秒ごとにビューに新しいレコードを問い合わせます。
- 変換されたデータを使用して予測リクエストを Google Cloud AI Platform に送信します。予測をアウトバウンドの Google Cloud Pub/Sub キューに書き込みます。
- D.
- 受信した予測リクエストを Google Cloud Pub/Sub トピックに送信します。
- メッセージが Google Cloud Pub/Sub トピックにパブリッシュされたときにトリガーされる Google Cloud Functions を設定します。
- Google Cloud Functions に前処理ロジックを実装します。
- 変換されたデータを使用して予測リクエストを Google Cloud AI Platform に送信します。予測をアウトバウンドの Google Cloud Pub/Sub キューに書き込みます。
Correct Answer: D
Reference:
– トピックへのメッセージのパブリッシュ | Cloud Pub/Sub
Question 30
チームは DNN 回帰モデルのトレーニングとテストを行い、良好な結果を得ました。
導入から 6ヶ月後、入力データの分布が変化したため、モデルのパフォーマンスが低下しています。
本番では入力の違いにどのように対処すべきでしょうか?
- A. スキューを監視するアラートを作成し、モデルを再トレーニングします。
- B. モデルの特徴選択を実行し、より少ない特徴でモデルを再トレーニングします。
- C. モデルを再トレーニングし、ハイパーパラメータ調整サービスで L2 正則化 パラメータを選択します。
- D. モデルの特徴選択を実行し、月ごとにより少ない特徴でモデルの再トレーニングします。
Correct Answer: C
Question 31
Google Compute Engine で GPU を搭載した仮想マシンを使用し、指定された画像に存在する政府機関 ID のタイプを予測するコンピュータ ビジョンモデルをトレーニングする必要があります。
次のパラメータを使用します。
– Optimizer: SGD
– Image shape = 224×224
– Batch size = 64
– Epochs = 10
– Verbose =2
トレーニング中に次のようなエラーが発生します。
ResourceExhaustedError: Out Of Memory (OOM) when allocating tensor.
どうすればいいでしょうか?
- A. オプティマイザーを変更します。
- B. バッチサイズを減らします。
- C. 学習率を変更します。
- D. 画像の形状を縮小します。
Correct Answer: B
Reference:
– ResourceExhaustedError in CNN/MNIST example (with GPU) · Issue #136 · tensorflow/tensorflow
Question 32
Google Cloud AI Platform で ML モデルを開発し、本番環境に移行したいと考えています。
毎秒 数千件のクエリを処理していますが遅延問題が発生しています。受信したリクエストは Google Kubernetes Engine(GKE)で動作する複数の Kubeflow CPU 専用ポッドに分散するロードバランサーによって処理されています。基本的なインフラストラクチャを変更することなく、サービスの遅延を改善することが目標です。
何をすべきでしょうか?
- A. TensorFlow Serving の max_batch_size パラメータを大幅に増やします。
- B. TensorFlow Serving の tensorflow-model-server-universal バージョンに切り替えます。
- C. TensorFlow Serving の max_enqueued_batches パラメータを大幅に増やします。
- D. ソースを使用して TensorFlow Serving を再コンパイルし、CPU 固有の最適化をサポートします。ノードにサービスを提供するための適切なベースライン最小 CPU プラットフォームを選択するように GKE に指示します。
Correct Answer: D
Question 33
Google Cloud Dataflow を使用してモデルのトレーニングと予測の前に生データの前処理する本番環境の需要予測パイプラインがあります。
前処理では Google BigQuery に保存されているデータに z スコア正規化(数値特徴の標準スケーリング)を行い、Google BigQuery に書き戻します。毎週、新しいトレーニング データが追加されます。計算時間と手動による介入を最小限にすることでプロセスを効率化したいと考えています。
どうすればいいのでしょうか?
- A. Google Kubernetes Engine を使ってデータを正規化します。
- B. Google BigQuery で使用するために正規化アルゴリズムを SQL に変換する。
- C. TensorFlow の Feature Column API で normalizer_fn 引数を使用する。
- D. Google BigQuery 用の Google Cloud Dataproc コネクタを使用して、Apache Spark でデータを正規化します。
Correct Answer: B
Reference:
– データ ウェアハウス使用者のための BigQuery | Cloud Architecture Center
– 機械学習のためのデータ前処理: オプションと推奨事項
– BigQuery 特集: 結合データ、繰り返しおよびネストされたデータの処理
Question 34
顧客の購入履歴に基づいて顧客の購入を予測する、カスタマイズされたディープ ニューラル ネットワークを Keras で設計する必要があります。
複数のモデルアーキテクチャーを使用してモデルのパフォーマンスを調査し、トレーニングデータを保存して同じダッシュボードで評価指標を比較できるようにしたいと考えています。
どうすればいいのでしょうか?
- A. Google Cloud AutoML Tables を使用して複数のモデルを作成します。
- B. Google Cloud Composer を使用して複数のトレーニングの実行を自動化します。
- C. 同様のジョブ名で Google Cloud AI Platform で複数のトレーニング ジョブを実行します。
- D. Kubeflow Pipelines で実験を作成して複数の実行を整理します。
Correct Answer: C
Question 35
Google Kubernetes Engine でKubeflow Pipelines を開発しています。
パイプラインの最初のステップは Google BigQuery に対してクエリを発行することです。そのクエリの結果をパイプラインの次のステップへの入力として使用することを計画しており、 可能な限り最も簡単な方法で達成したいと考えています。
何をするべきかでしょうか?
- A. Google BigQuery コンソールを使用してクエリを実行し、クエリ結果を新しいGoogle BigQuery テーブルに保存します。
- B. Google BigQuery APIを使用して Google BigQuery に対してクエリを実行する Python スクリプトを記述し、Kubeflow Pipelines の最初のステップとして実行します。
- C. Kubeflow Pipelines ドメイン固有言語を使用して Python で Google BigQuery クライアント ライブラリでクエリを実行するカスタム コンポーネントを作成します。
- D. GitHubで Kubeflow Pipelines リポジトリを見つけます。Google BigQuery クエリ コンポーネントを見つけ、そのコンポーネントのURLをコピーし、コンポーネントをパイプラインにロードします。コンポーネントを使用し、Google BigQuery に対してクエリを実行します。
Correct Answer: A
Question 36
毎日の気温を予測するモデルを構築しています。
データをランダムに分割してトレーニング データセットとテスト データセットを変換しました。 モデルトレーニングの温度データは 1時間ごとにアップロードされます。テスト中、モデルは 97%の精度で実行されましたが、本番環境に導入した後、モデルの精度は 66%に低下しました。
どうすれば生産モデルをより正確にすることができるでしょうか?
- A. トレーニングのデータを正規化し、データセットを 2つの別々のステップとしてテストします。
- B. トレーニング データとテスト データをランダムに分割するのではなく、時間に基づいて分割することで漏れを防ぎます。
- C. テストセットにデータを追加し、テスト用の公平な分布とサンプルがあることを確認します。
- D. 分割する前にデータ変換を適用し、相互検証して変換がトレーニング セットとテスト セットの両方に適用されていることを確認します。
Correct Answer: D
Question 37
カスタマーサポートのメールを分類するためのモデルを開発しています。
オンプレミス システムで小さなデータセットを使用して TensorFlow の Estimators でモデルを作成しましたが高いパフォーマンスを確保するには大きなデータセットを使用してモデルをトレーニングする必要があります。 モデルを GoogleCloud に移行してコードのリファクタリングとインフラストラクチャのオーバーヘッドを最小限に抑えてオンプレミスからクラウドへの移行を容易にします。
何をするべきでしょうか?
- A. Google Cloud AI Platform を使って分散学習をします。
- B. Google Cloud Dataproc でトレーニング用のクラスタを作成します。
- C. オートスケーリング機能付きのマネージド インスタンス グループを作成します。
- D. Kubeflow Pipelines を使用して Google Kubernetes Engine クラスタでトレーニングします。
Correct Answer: C
Question 38
Google Cloud AI Platform を使用して TensorFlow でテキスト分類モデルをトレーニングしました。
トレーニングされたモデルを使用して計算のオーバーヘッドを最小限に抑えながら Google BigQuery に保存されているテキストデータのバッチ予測を行います。
何をするべきでしょうか?
- A. モデルを Google BigQuery ML にエクスポートします。
- B. Google Cloud AI Platform にモデルをデプロイしてバージョン管理する。
- C. SavedModel で Google Cloud Dataflow を使用して Google BigQuery からデータを読み込みます。
- D. Google Cloud AI Platform で Google Cloud Storage のモデルの場所を指すバッチ予測ジョブを送信します。
Correct Answer: A
Question 39
データセットをクリーンアップして Google Cloud Storage バケットに保存するパイプラインを開発したデータエンジニアリングチームと協力します。
ML モデルを作成し、新しいデータが利用可能になり次第、データを使用してモデルを更新したいと考えています。 CI/CD ワークフローの一部として Google Kubernetes Engine(GKE)で Kubeflow Pipelines のトレーニング ジョブを自動的に実行する必要があります。
このワークフローをどのように設計するべきでしょうか?
- A. パイプラインを Google Cloud Dataflow で構成し、Google Cloud Storage にファイルを保存します。ファイルが保存されたら GKE クラスタでトレーニング ジョブを開始します。
- B. Google App Engine を使用して Google Cloud Storage に継続的に新しいファイルをポーリングする軽量の Python クライアントを作成します。ファイルが到着したらすぐにトレーニング ジョブを開始します。
- C. 新しいファイルがストレージ バケットで利用可能になったときに GoogleCloud Pub/Sub トピックにメッセージを送信するように Google Cloud Storage のトリガーを設定します。Google Cloud Pub/Sub をトリガーとした Google Cloud Functions を使用して GKE クラスターでトレーニング ジョブを開始します。
- D. Google Cloud Scheduler を使用して定期的な間隔でジョブをスケジュールします。ジョブの最初のステップで Google Cloud Storage バケット内のオブジェクトのタイムスタンプを確認します。前回の実行後に新しいファイルがない場合はジョブを中止します。
Correct Answer: C
Reference:
– TFX、Kubeflow Pipelines、Cloud Build を使用した MLOps のアーキテクチャ
– AI Platform Pipelines 用の Google Kubernetes Engine クラスタを構成する
Question 40
Google Cloud AI Platform を使用してML モデルのハイパーパラメータをチューニングし、最適にチューニングされたパラメータをトレーニングに使用するというエンドツーエンドのML パイプラインがあります。
ハイパーチューニングに予想以上の時間がかかり、下流のプロセスが遅れています。チューニングの効果を大幅に損なうことなく、チューニング作業を高速化したいと考えています。
どのような行動を取るべきでしょうか?(回答を 2つ選択しなさい)
- A. 並行試行の回数を減らします。
- B. 浮動小数点値の範囲を小さくします。
- C. 早期停止パラメータをTRUE に設定します。
- D. 検索アルゴリズムをベイズ検索からランダム検索に変更します。
- E. 後続のトレーニング フェーズでの試行の最大数を減らします。
Correct Answer: B、D
Reference:
– ハイパーパラメータ調整の概要 | Google Cloud AI Platform Training
– Hyperparameter tuning in Cloud Machine Learning Engine using Bayesian Optimization|
– ~ベイズ最適化~ Optuna with SageMaker チューニングと評価を時短して効率化
– 機械学習モデルのハイパパラメータ最適化
Question 41
チームは何百万もの顧客が使用するグローバル銀行向けのアプリケーションを構築しています。
3日後の顧客の口座残高を予測する予測モデルを構築しました。 チームは口座残高が 25ドルを下回る可能性がある場合にユーザーに通知する新機能に使用します。
予測結果をどのように提供すべきでしょうか?
- A.
- ユーザーごとに Google Cloud Pub/Sub トピックを作成します。
- ユーザーの口座残高が 25ドルのしきい値を下回るとモデルが予測した場合に通知を送信する Google Cloud Functions をデプロイします。
- B.
- ユーザーごとに Google Cloud Pub/Sub トピックを作成します。
- ユーザーの口座残高が 25ドルのしきい値を下回るとモデルが予測した場合に通知を送信する Google App Engine スタンダード環境をデプロイします。
- C.
- Firebase で通知システムを構築します。
- 各ユーザーを Firebase Cloud Messaging サーバーにユーザーIDで登録し、すべての口座残高 予測の平均値が 25ドルのしきい値を下回ったときに通知を送信します。
- D.
- Firebase で通知システムを構築します。
- 各ユーザーを Firebase Cloud Messaging サーバーのユーザーIDに登録し、モデルがユーザーの口座残高が 25ドルのしきい値を下回ると予測した場合に通知を送信します。
Correct Answer: A
Question 42
広告会社に勤務しており、自社の最新広告キャンペーンの効果を把握したいと考えています。
テーブルにクエリを実行してから、Google Cloud AI Platform Notebooks の pandas データフレームを使用してそのクエリの結果を操作します。
どうすればいいのでしょうか?
- A. Google Cloud AI Platform Notebooks の Google BigQuery セルマジックを使用してデータをクエリし、結果を pandas データフレームとして取り込みます。
- B.テーブルを CSV ファイルとしてGoogle BigQuery から Google ドライブにエクスポートし、Google ドライブ API を使用してファイルを Notebooks インスタンスに取り込みます。
- C. テーブルを Google BigQuery からローカル CSV ファイルとしてダウンロードし、Google Cloud AI Platform Notebooks インスタンスにアップロードします。 pandas.read_csv を使用してファイルを pandas データフレームとして取り込みます。
- D. Google Cloud AI Platform Notebooks のbash セルから bqextract コマンドを使用してテーブルを CSV ファイルとして Google Cloud Storage にエクスポートし、gsutilcp を使用してデータを Notebooks にコピーします。 pandas.read_csv を使用してファイルを pandas データフレームとして取り込みます。
Correct Answer: C
Reference:
– BigQuery Storage API を使用して BigQuery データを pandas にダウンロードする
Question 43
世界的な自動車メーカーのML エンジニアです。
世界中の様々な都市での自動車販売台数を予測するML モデルを構築する必要があります。
車両と販売台数の関係を都市別にトレーニングするためには、どのような特徴や特徴の組み合わせを使うべきでしょうか?
- A. 3つの特徴:緯度、経度、ワンホット エンコードされた車種。
- B. 緯度、経度、ワンホット エンコードされた車種の間の要素ごとの積として取得された 1つの特徴。
- C. 緯度、経度、ワンホット エンコードされた車種の間の要素ごとの積として取得された 1つの特徴量。
- D. 要素ごとの積として取得された 2つの特徴。:1つは緯度とワンホット エンコードされた車種、2つは経緯とワンホット エンコードされた車種。
Correct Answer: C
Question 44
コンタクトセンターの近代化を目指している大手テクノロジー企業に勤務しています。
製品別に着信通話を分類し、リクエストをより迅速に適切なサポート チームに振り分けるソリューションの開発するように依頼されました。すでに Google Cloud Speech-to-Text API を使って通話内容を文字変換しました。データの前処理と開発時間を最小限にしたいと考えています。
どのようにモデルを構築すればよいでしょうか?
- A. Google Cloud AI Platform Training の組み込みアルゴリズムを使用してカスタム モデルを作成する。
- B. Google Cloud AutoMLL Natural Language を使用して分類用のカスタム エンティティを抽出します。
- C. Google Cloud Natural Language API を使用して分類用のカスタム エンティティを抽出します。
- D. カスタム モデルを構築して変換クリプトされた通話から製品キーワードを特定し、分類アルゴリズムでキーワードを実行します。
Correct Answer: A
Reference:
– 組み込みアルゴリズムの概要 | AI Platform Training
– 機械学習を使用した音声コンテンツの分類
Question 45
複数のCSVファイルに格納された 1,000億レコードの構造化データセットで TensorFlow モデルをトレーニングしています。
入力/出力の実行性能を改善する必要があります。
何をすべきでしょうか?
- A. Google BigQuery にデータを読み込んで Google BigQuery からデータを読み込みます。
- B. Google Cloud Bigtable にデータを読み込んで Google Cloud Bigtable からデータを読み込みます。
- C. CSV ファイルを TFRecords でシャーディングし、Google Cloud Storage に保存します。
- D. CSV ファイルを TFRecords でシャーディングし、Hadoop 分散ファイル システム(HDFS)に保存します。
Correct Answer: B
Reference:
– Google 提供のバッチ テンプレート | Google Cloud Dataflow
Question 46
会社のリード ML エンジニアとしてスキャンした顧客フォームをデジタル化するためのML モデルの構築を担当しています。
スキャンされた画像をテキストに変換し、Google Cloud Storage に保存する TensorFlow モデルを開発しました。毎日の終わりに収集された集約されたデータに最小限の手動介入でMLモデルを使用する必要があります。
何をすべきでしょうか?
- A. Google Cloud AI Platform のバッチ予測機能を利用します。
- B. Google Compute Engine に予測用のサービス パイプラインを作成します。
- C. 新しいデータポイントが取り込まれるたびに Google Cloud Functions を使用して予測を行います。
- D. Google Cloud AI Platform にモデルをデプロイしてオンライン推論用のバージョンを作成します。
Correct Answer: D
Question 47
最近、数千のデータセットを持つ企業規模の会社に入社しました。
Google BigQuery の各テーブルには正確な説明があることを知っており、Google Cloud AI Platform で構築しているモデルに使用する適切な Google BigQuery テーブルを探しています。
どのようにして必要なデータを見つけるべきでしょうか?
- A. Google Cloud Data Catalogを使ってテーブルの説明にあるキーワードを使ってGoogle BigQuery データセットを検索します。
- B. トレーニングに使用された Google BigQuery テーブルの名前で Google Cloud AI Platform の各モデルとバージョンのリソースにタグを付けます。
- C. テーブルの説明とテーブル ID をマッピングするルックアップテーブルを Google BigQuery で管理します。ルックアップテーブルを照会して必要なデータの正しいテーブル ID を見つけます。
- D. Google BigQuery でクエリを実行して Google BigQuery に備わっている INFORMATION_SCHEMA メタデータ テーブルを使用し、プロジェクト内のすべての既存のテーブル名を取得します。その結果を使用して必要なテーブルを見つけます。
Correct Answer: B
Question 48
時系列データの分類問題に取り組み始め、わずか数回の実験でトレーニングデータの受信者操作特性 曲線(AUC ROC)の下の面積値が 99%に達成しました。
洗練されたアルゴリズムの使用は検討しておらず、ハイパーパラメータ調整にも時間を費やしたこともありません。
問題を特定して解決するために次のステップは何をすべきでしょうか?
- A. より複雑でないアルゴリズムを使用することでモデルの過剰適合に対処します。
- B. モデルのトレーニング中にネストされた相互検証を適用することにより、データ漏洩に対処します。
- C. 目標値との相関性が高い特徴を削除することでデータ漏洩に対処します。
- D. AUC ROC 値を下げるようにハイパーパラメータ調整することでモデルの過剰適合に対処します。
Correct Answer: B
Reference:
– モデルの評価 | AutoML Tables
– 表形式の AutoML モデルの最適化目標 | Vertex AI
Question 49
Webサイトで掲載する広告枠を他社にも販売しているオンライン旅行代理店で働いています。
ユーザーが次に見るべき最も関連性の高いWeb バナーを予測するよう依頼されましたが会社ではセキュリティが重要視されています。モデルのレイテンシー要件は 300ms@p99、インベントリは数千のWeb バナーで探索的な分析ではナビゲーション コンテキストが良い予測因子であることがわかっています。最もシンプルなソリューションを導入したいと考えています。
予測パイプラインはどのように構成すべきでしょうか?
- A. Web サイトにクライアントを埋め込み、Google Cloud AI Platform Prediction にモデルにデプロイします。
- B. Web サイトにクライアントを埋め込み、Google App Engine にゲートウェイをデプロイし、Google Cloud AI Platform Prediction にモデルをデプロイします。
- C. Web サイトにクライアントを埋め込み、Google App Engine にゲートウェイをデプロイし、ユーザーのナビゲーション コンテキストの書き込み用と読み込み用のデータベースを Google Cloud Bigtable にデプロイしてモデルを Google Cloud AI Platform Prediction にデプロイします。
- D. Web サイトにクライアントを埋め込み、Google App Engine にゲートウェイをデプロイし、データベースを Google Cloud Memorystore にデプロイしてユーザーのナビゲーション コンテキストの書き込みと読み取りを行い、モデルを Google Kubernetes Engine にデプロイします。
Correct Answer: B
Question 50
チームは畳み込みニューラル ネットワーク(CNN)ベースのアーキテクチャをゼロから構築しています。
オンプレミスのCPU のみのインフラで実行した予備実験では有望な結果が得られましたが収束には時間がかかっています。市場投入までの時間を短縮するためにモデルのトレーニングを高速化するよう求められています。より強力なハードウェアを活用するために Google Cloud で仮想マシン(VM)を試してみたいと考えています。コードには手動でのデバイス配置は含まれておらず、Estimator モデルレベルの抽象化も施されていません。
どの環境でモデルをトレーニングするべきでしょうか?
- A. すべての依存関係が手動でインストールされた Google Compute Engine のAVMと 1つのTPU。
- B. すべての依存関係が手動でインストールされた Google Compute Engine と 8 GPUのAVM。
- C. すべてのライブラリがプリインストールされた n1-standard-2 マシンと 1 GPUを備えたディープラーニングVM。
- D. すべてのライブラリがプリインストールされたより強力な CPU e2-highcpu-16 マシンを備えたディープラーニングVM。
Correct Answer: A
Question 51
Google Cloud AI Platform を使用する 50人以上のデータサイエンティストからなる成長中のチームで働いています。
ジョブ、モデル、バージョンをクリーンでスケーラブルな方法で整理するための戦略を設計しています。
どの戦略を選ぶべきでしょうか?
- A. Google Cloud AI Platform の Notebooks に制限的な IAM 権限を設定し、単一のユーザーまたはグループのみが所定のインスタンスにアクセスできるようにします。
- B. 各データサイエンティストの作業を別のプロジェクトに分離し、各データサイエンティストが作成したジョブ、モデル、バージョンにはそのユーザーのみがアクセスできるようにします。
- C. ラベルを使用してリソースを説明的なカテゴリに整理します。作成された各リソースにラベルを適用し、ユーザーがリソースを表示または監視する際にラベルによって結果をフィルタリングできるようにする。
- D. Google Cloud AI Platform のリソース使用状況に関する情報を取得するために適切にフィルタリングされた Google Cloud Logging ログ用の Google BigQuery の sink を設定します。Google BigQuery でユーザーを使用しているリソースにマッピングする SQL ビューを作成します。
Correct Answer: A
Question 52
トレーニング時間を短縮して画像セマンティック セグメンテーションの深層学習モデルをトレーニングしています。
ディープラーニング VM イメージを使用しているときに、次のエラーが発生します。
リソース'projects/deeplearning-platforn/zones/europe-west4-c/acceleratorTypes/nvidia-tesla-k80' が見つかりませんでした。
何をするべきでしょうか
- A. 選択したリージョンに GPU クォータがあることを確認します。
- B. 必要な GPU が選択したリージョンで使用可能であることを確認します。
- C. 選択したリージョンにプリエンプティブ GPU クォータがあることを確認します。
- D. 選択した GPU にワークロードに十分な GPU メモリがあることを確認します。
Correct Answer: A
Reference:
– トラブルシューティング | Deep Learning VM Images
– Troubleshooting | Deep Learning VM Images
Question 53
チームは著者が執筆した記事に基づいて著者の所属政党を予測するNLP 研究プロジェクトに取り組んでいます。
次のような構造の大規模な学習データセットがあります。
AuthorA:Political Party A
TextA1: [SentenceA11, SentenceA12, SentenceA13, ...]
TextA2: [SentenceA21, SentenceA22, SentenceA23, ...]
…
AuthorB:Political Party B
TextB1: [SentenceB11, SentenceB12, SentenceB13, ...]
TextB2: [SentenceB21, SentenceB22, SentenceB23, ...]
…
AuthorC:Political Party B
TextC1: [SentenceC11, SentenceC12, SentenceC13, ...]
TextC2: [SentenceC21, SentenceC22, SentenceC23, ...]
…
AuthorD:Political Party A
TextD1: [SentenceD11, SentenceD12, SentenceD13, ...]
TextD2: [SentenceD21, SentenceD22, SentenceD23, ...]
…
...トレーニング、テスト、評価の各サブセットに 80% 〜 10% 〜 10%の標準的なデータ配分を行いました。
80 / 10 / 10 の割合を維持しつつ、トレーニング / テスト / 評価のサブセット間でトレーニング例をどのように分配すればよいでしょうか?
- A. テキストをトレーニング / テスト / 評価の各サブセットにランダムに配置します。
- Train set: [TextA1, TextB2, …]
- Test set: [TextA2, TextC1, TextD2, …]
- Eval set: [TextB1, TextC2, TextD1, …]
- B. 著者をトレーニング / テスト / 評価のサブセットにランダムに分散させます。(*)
- Train set: [TextA1, TextA2, TextD1, TextD2, …]
- Test set: [TextB1, TextB2, …]
- Eval set: [TexC1,TextC2 …]
- C. トレーニング / テスト / 評価のサブセットにランダムに文を配置します。
- Train set: [SentenceA11, SentenceA21, SentenceB11, SentenceB21, SentenceC11, SentenceD21 …]
- Test set: [SentenceA12, SentenceA22, SentenceB12, SentenceC22, SentenceC12, SentenceD22 …]
- Eval set: [SentenceA13, SentenceA23, SentenceB13, SentenceC23, SentenceC13, SentenceD31 …]
- D. テキストの段落(連続する文のチャンク)をトレーニング / テスト / 評価のサブセット全体に分散します。
- Train set: [SentenceA11, SentenceA12, SentenceD11, SentenceD12 …]
- Test set: [SentenceA13, SentenceB13, SentenceB21, SentenceD23, SentenceC12, SentenceD13 …]
- Eval set: [SentenceA11, SentenceA22, SentenceB13, SentenceD22, SentenceC23, SentenceD11 …]
Correct Answer: C
Question 54
チームはプラットフォームの 1つに対するサポートリクエストを分類するために Google Cloud でML ソリューションを作成することを任されました。
要件を分析し、モデルのコード、サービング、デプロイメントを完全に制御できるように TensorFlow を使用して分類器を構築することを決定しました。ML プラットフォームには Kubeflow Pipelines を使用します。 時間を節約するにはまったく新しいモデルを構築するのではなく、既存のリソースに基づいて構築してマネージド サービスを使用する必要があります。
分類器をどのように構築するべきでしょうか?
- A. Google Cloud Natural Language APIを使用してサポートリクエストを分類します。
- B. Google Cloud AutoML Natural Languageを使用してサポートリクエスト分類子を作成します。
- C. Google Cloud AI Platform で確立されたテキスト分類モデルを使用して転移学習を実行します。
- D. Google Cloud AI Platformで確立されたテキスト分類モデルをそのまま使用してサポートリクエストを分類します。
Correct Answer: D
Question 55
新しいプロジェクトを間もなくリリースする機械学習チームに参加しました。
プロジェクトのリーダーとしてML コンポーネントの生産準備状況を判断するように求められます。 チームはすでに機能とデータ、モデル開発、インフラストラクチャをテストしています。
チームにどの追加準備チェックを勧めるべきでしょうか?
- A. トレーニングが再現可能であることを確認します。
- B. すべてのハイパーパラメータが調整されていることを確認します。
- C. モデルのパフォーマンスが監視されていることを確認します。
- D. 機能の期待値がスキーマに取り込まれていることを確認します。
Correct Answer: A
Question 56
クレジットカード会社で働いており、Google Cloud AutoMLTables を使用して履歴データに基づいてカスタムの不正検出モデルを作成するように依頼されました。
誤検知を最小限に抑えながら不正なトランザクションの検出を優先する必要があります。
モデルをトレーニングするときにどの最適化の目標を使用する必要がありますか?
- A. ログの損失を最小限に抑える最適化の目標。
- B. 0.50 のリコール値で精度を最大化する最適化の目標。
- C. 適合率 / 再現率 曲線(AUC PR)の下の面積値を最大化する最適化の目標。
- D. 受信者操作特性 曲線(AUC ROC)の下の面積値を最大化する最適化の目標。
Correct Answer: C
Question 57
会社はユーザーが動画を見たりアップロードしたりできる動画共有サイトを運営しています。
MLモデルを作成して新しくアップロードされたどの動画が最も人気があるかを予測し、それらの動画を会社のWeb サイトで優先できるようにする必要があります。
このモデルが成功したかどうかを判断するためにどの結果を使うべきでしょうか?
- A. 動画をアップロードしたユーザーの「いいね!」が1万件を超える場合、人気があると予測します。
- B. クリック数で測定した最も人気のあるクリックベイト動画の 97.5%を予測しています。
- C. アップロードされてから 30日以内の総再生時間で測定された最も人気のある動画の95%を予測します。
- D. 公開後 7日後と 30日後の対数変換された再生回数の間のピアソン相関係数は 0 に等しいです。
Correct Answer: C
Question 58
ニューラル ネットワークベースのプロジェクトに取り組んでいます。
用意されたデータセットには異なる範囲の列があり、モデル トレーニング用のデータを準備しているときに勾配最適化で重みを良い解に移動させるのが難しいことに気づきました。
どうしたらいいでしょうか?
- A. 特徴構築を使用して最も強力な特徴を組み合わせます。
- B. 表現変換(正規化)手法を使用します。
- C. 値が欠落している特徴を削除してデータ クリーニング手順を改善します。
- D. パーティショニング ステップを変更してテストセットの次元を減らし、トレーニングセットを大きくします。
Correct Answer: C
Reference:
– 機械学習のためのデータ前処理: オプションと推奨事項
– YouTube: Advanced Data Cleanup Techniques using Cloud Dataprep (Cloud Next ’19)
Question 59
データサイエンス チームは様々な機能、モデルアーキテクチャー、ハイパーパラメータをすばやく実験する必要があります。
また、様々な実験の精度指標を追跡し、APIを使用してその指標を時系列でクエリします。
手動での作業を最小限に抑えながら実験を追跡し、報告するには何を使用すべきでしょうか?
- A. Kubeflow Pipelines を使用して実験を実行します。 メトリックファイルをエクスポートし、Kubeflow Pipelines API を使用して結果をクエリします。
- B. Google Cloud AI Platform のトレーニングを使用して実験を実行します。 精度メトリックを Google BigQuery に書き込み、Google BigQuery API を使用して結果をクエリします。
- C. Google Cloud AI Platform のトレーニングを使用して実験を実行します。 精度指標を GoogleCloud Monitoring に書き込み、Monitoring APIを使用して結果をクエリします。
- D. Google Cloud AI Platform の Notebooks を使用して実験を実行します。 共有のGoogle スプレッドシート ファイルに結果を収集し、Google スプレッドシート APIを使用して結果をクエリします。
Correct Answer: B
Question 60
銀行に勤務しており、不正行為を検出するためのランダム フォレスト モデルを構築しています。
データセットにはトランザクションが含まれており、そのうちの 1%が不正行為として識別されています。
どのデータ変換戦略が分類器のパフォーマンスを向上させるでしょうか?
- A. TFRecords にデータを書き込みます。
- B. すべての数値特徴を z スコア正規化します。
- C. 不正なトランザクションを10倍のオーバー サンプリングにします。
- D. すべてのカテゴリ機能でワンホット エンコーディングを使用します。
Correct Answer: C
Reference:
– How to Build a Machine Learning Model to Identify Credit Card Fraud in 5 Steps
Comments are closed