
Ace Your Professional Data Engineer Certification with Practice Exams.
Google Cloud Certified – Professional Data Engineer – Practice Exam (Question 50)
Question 1
You have an Apache Kafka cluster on-prem with topics containing web application logs.
You need to replicate the data to Google Cloud for analysis in Google BigQuery and Google Cloud Storage. The preferred replication method is mirroring to avoid deployment of Kafka Connect plugins.
What should you do?
- A. Deploy a Kafka cluster on Google Compute Engine VM Instances. Configure your on-prem cluster to mirror your topics to the cluster running in Google Compute Engine. Use a Dataproc cluster or Dataflow job to read from Kafka and write to Google Cloud Storage.
- B. Deploy a Kafka cluster on Google Compute Engine VM Instances with the PubSub Kafka connector configured as a Sink connector. Use a Dataproc cluster or Dataflow job to read from Kafka and write to Google Cloud Storage.
- C. Deploy the PubSub Kafka connector to your on-prem Kafka cluster and configure PubSub as a Source connector. Use a Dataflow job to read from PubSub and write to Google Cloud Storage.
- D. Deploy the PubSub Kafka connector to your on-prem Kafka cluster and configure PubSub as a Sink connector. Use a Dataflow job to read from PubSub and write to Google Cloud Storage.
Correct Answer: A
Question 2
You have data pipelines running on Google BigQuery, Google Cloud Dataflow, and Google Cloud Dataproc.
You need to perform health checks and monitor their behavior, and then notify the team managing the pipelines if they fail. You also need to be able to work across multiple projects. Your preference is to use managed products of features of the platform.
What should you do?
- A. Export the information to Google Stackdriver, and set up an Alerting policy.
- B. Run a Virtual Machine in Google Compute Engine with Airflow, and export the information to Google Stackdriver.
- C. Export the logs to Google BigQuery, and set up Google App Engine to read that information and send emails if you find a failure in the logs.
- D. Develop an Google App Engine application to consume logs using GCP API calls, and send emails if you find a failure in the logs.
Correct Answer: B
Question 3
You have developed three data processing jobs.
One executes a Google Cloud Dataflow pipeline that transforms data uploaded to Google Cloud Storage and writes results to Google BigQuery. The second ingests data from on-premises servers and uploads it to Google Cloud Storage. The third is a Google Cloud Dataflow pipeline that gets information from third-party data providers and uploads the information to Google Cloud Storage. You need to be able to schedule and monitor the execution of these three workflows and manually execute them when needed.
What should you do?
- A. Create a Direct Acyclic Graph in Google Cloud Composer to schedule and monitor the jobs.
- B. Use Stackdriver Monitoring and set up an alert with a Webhook notification to trigger the jobs.
- C. Develop a Google App Engine application to schedule and request the status of the jobs using GCP API calls.
- D. Set up cron jobs in a Google Compute Engine instance to schedule and monitor the pipelines using GCP API calls.
Correct Answer: D
Question 4
You have enabled the free integration between Firebase Analytics and Google BigQuery.
Firebase now automatically creates a new table daily in Google BigQuery in the format app_events_YYYYMMDD. You want to query all of the tables for the past 30 days in legacy SQL.
What should you do?
- A. Use the TABLE_DATE_RANGE function
- B. Use the WHERE_PARTITIONTIME pseudo column
- C. Use WHERE date BETWEEN YYYY-MM-DD AND YYYY-MM-DD
- D. Use SELECT IF.(date >= YYYY-MM-DD AND date <= YYYY-MM-DD
Correct Answer: A
Reference contents:
– Using BigQuery and Firebase Analytics to understand your mobile app
– Legacy SQL Functions and Operators | BigQuery
Question 5
You have Google Cloud Dataflow streaming pipeline running with a Google Cloud Pub/Sub subscription as the source.
You need to make an update to the code that will make the new Google Cloud Dataflow pipeline incompatible with the current version. You do not want to lose any data when making this update.
What should you do?
- A. Update the current pipeline and use the drain flag.
- B. Update the current pipeline and provide the transform mapping JSON object.
- C. Create a new pipeline that has the same Google Cloud Pub/Sub subscription and cancel the old pipeline.
- D. Create a new pipeline that has a new Google Cloud Pub/Sub subscription and cancel the old pipeline.
Correct Answer: D
Question 6
You have Google Cloud Functions written in Node.js that pull messages from Google Cloud Pub/Sub and send the data to Google BigQuery.
You observe that the message processing rate on the Pub/Sub topic is orders of magnitude higher than anticipated, but there is no error logged in Stackdriver Log Viewer.
What are the two most likely causes of this problem? (Choose two.)
- A. Publisher throughput quota is too small.
- B. Total outstanding messages exceed the 10-MB maximum.
- C. Error handling in the subscriber code is not handling run-time errors properly.
- D. The subscriber code cannot keep up with the messages.
- E. The subscriber code does not acknowledge the messages that it pulls.
Correct Answer: C, D
Question 7
You have historical data covering the last three years in Google BigQuery and a data pipeline that delivers new data to Google BigQuery daily.
You have noticed that when the Data Science team runs a query filtered on a date column and limited to 30~90 days of data, the query scans the entire table. You also noticed that your bill is increasing more quickly than you expected. You want to resolve the issue as cost-effectively as possible while maintaining the ability to conduct SQL queries.
What should you do?
- A. Re-create the tables using DDL. Partition the tables by a column containing a TIMESTAMP or DATE Type.
- B. Recommend that the Data Science team export the table to a CSV file on Google Cloud Storage and use Google Cloud Datalab to explore the data by reading the files directly.
- C. Modify your pipeline to maintain the last 30″90 days of data in one table and the longer history in a different table to minimize full table scans over the entire history.
- D. Write an Apache Beam pipeline that creates a Google BigQuery table per day. Recommend that the Data Science team use wildcards on the table name suffixes to select the data they need.
Correct Answer: C
Question 8
You have several Spark jobs that run on a Google Cloud Dataproc cluster on a schedule.
Some of the jobs run in sequence, and some of the jobs run concurrently. You need to automate this process.
What should you do?
- A. Create a Google Cloud Dataproc Workflow Template.
- B. Create an initialization action to execute the jobs.
- C. Create a Directed Acyclic Graph in Google Cloud Composer.
- D. Create a Bash script that uses the Google Cloud SDK to create a cluster, execute jobs, and then tear down the cluster.
Correct Answer: A
Reference contents:
– Using workflows | Dataproc Documentation
– Overview of Dataproc Workflow Templates | Dataproc Documentation
Question 9
You have some data, which is shown in the graphic below.
The two dimensions are X and Y, and the shade of each dot represents what class it is. You want to classify this data accurately using a linear algorithm. To do this you need to add a synthetic feature.
What should the value of that feature be?
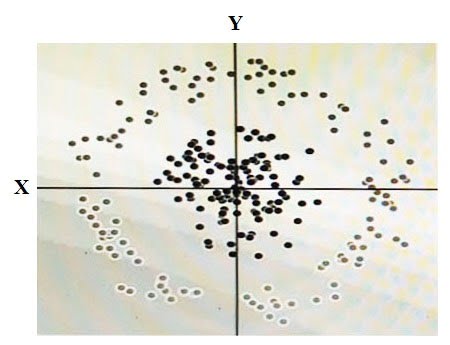
- A. X^2+Y^2
- B. X^2
- C. Y^2
- D. cos(X)
Correct Answer: D
Question 10
You have spent a few days loading data from comma-separated values (CSV) files into the Google BigQuery table CLICK_STREAM.
The column DT stores the epoch time of click events. For convenience, you chose a simple schema where every field is treated as the STRING type. Now, you want to compute web session durations of users who visit your site, and you want to change its data type to the TIMESTAMP. You want to minimize the migration effort without making future queries computationally expensive.
What should you do?
- A. Delete the table CLICK_STREAM, and then recreate it such that the column DT is of the TIMESTAMP type. Reload the data.
- B. Add a column TS of the TIMESTAMP type to the table CLICK_STREAM, and populate the numeric values from the column TS for each row. Reference the column TS instead of the column DT from now on.
- C. Create a view CLICK_STREAM_V, where strings from the column DT are cast into TIMESTAMP values. Reference the view CLICK_STREAM_V instead of the table CLICK_STREAM from now on.
- D. Add two columns to the table CLICK STREAM: TS of the TIMESTAMP type and IS_NEW of the BOOLEAN type. Reload all data in append mode. For each appended row, set the value of IS_NEW to true. For future queries, reference the column TS instead of the column DT, with the WHERE clause ensuring that the value of IS_NEW must be true.
- E. Construct a query to return every row of the table CLICK_STREAM, while using the built-in function to cast strings from the column DT into TIMESTAMP values. Run the query into a destination table NEW_CLICK_STREAM, in which the column TS is the TIMESTAMP type. Reference the table NEW_CLICK_STREAM instead of the table CLICK_STREAM from now on. In the future, new data is loaded into the table NEW_CLICK_STREAM.
Correct Answer: D
Reference contents:
– Manually changing table schemas | BigQuery
Question 11
You launched a new gaming app almost three years ago.
You have been uploading log files from the previous day to a separate Google BigQuery table with the table name format LOGS_yyyymmdd. You have been using table wildcard functions to generate daily and monthly reports for all time ranges. Recently, you discovered that some queries that cover long date ranges are exceeding the limit of 1,000 tables and failing.
How can you resolve this issue?
- A. Convert all daily log tables into date-partitioned tables.
- B. Convert the sharded tables into a single partitioned table.
- C. Enable query caching so you can cache data from previous months.
- D. Create separate views to cover each month, and query from these views.
Correct Answer: A
Question 12
You need to choose a database for a new project that has the following requirements:
– Fully managed
– Able to automatically scale up
– Transactionally consistent
– Able to scale up to 6 TB
– Able to be queried using SQL
Which database do you choose?
- A. Google Cloud SQL
- B. Google Cloud Bigtable
- C. Google Cloud Spanner
- D. Google Cloud Datastore
Correct Answer: C
Question 13
You need to choose a database to store time series CPU and memory usage for millions of computers.
You need to store this data in one-second interval samples. Analysts will be performing real-time, ad hoc analytics against the database. You want to avoid being charged for every query executed and ensure that the schema design will allow for future growth of the dataset.
Which database and data model should you choose?
- A. Create a table in Google BigQuery, and append the new samples for CPU and memory to the table.
- B. Create a wide table in Google BigQuery, create a column for the sample value at each second, and update the row with the interval for each second.
- C. Create a narrow table in Google Cloud Bigtable with a row key that combines the Google Computer Engine computer identifier with the sample time at each second.
- D. Create a wide table in Google Cloud Bigtable with a row key that combines the computer identifier with the sample time at each minute, and combine the values for each second as column data.
Correct Answer: D
Reference contents:
– Schema design for time series data | Cloud Bigtable Documentation
Question 14
You need to compose visualization for operations teams with the following requirements:
– Telemetry must include data from all 50,000 installations for the most recent 6 weeks (sampling once every minute)
– The report must not be more than 3 hours delayed from live data.
– The actionable report should only show suboptimal links.
– Most suboptimal links should be sorted to the top.
– Suboptimal links can be grouped and filtered by regional geography.
– User response time to load the report must be <5 seconds.
You create a data source to store the last 6 weeks of data, and create visualizations that allow viewers to see multiple date ranges, distinct geographic regions, and unique installation types. You always show the latest data without any changes to your visualizations. You want to avoid creating and updating new visualizations each month.
What should you do?
- A. Look through the current data and compose a series of charts and tables, one for each possible combination of criteria.
- B. Look through the current data and compose a small set of generalized charts and tables bound to criteria filters that allow value selection.
- C. Export the data to a spreadsheet, compose a series of charts and tables, one for each possible combination of criteria, and spread them across multiple tabs.
- D. Load the data into relational database tables, write a Google App Engine application that queries all rows, summarizes the data across each criteria, and then renders results using the Google Charts and visualization API.
Correct Answer: B
Question 15
You need to compose visualizations for operations teams with the following requirements:
– The report must include telemetry data from all 50,000 installations for the most recent 6 weeks (sampling once every minute).
– The report must not be more than 3 hours delayed from live data.
– The actionable report should only show suboptimal links.
– Most suboptimal links should be sorted to the top.
– Suboptimal links can be grouped and filtered by regional geography.
– User response time to load the report must be <5 seconds.
Which approach meets the requirements?
- A. Load the data into Google Sheets, use formulas to calculate a metric, and use filters/sorting to show only suboptimal links in a table.
- B. Load the data into Google BigQuery tables, write Google Apps Script that queries the data, calculates the metric, and shows only suboptimal rows in a table in Google Sheets.
- C. Load the data into Google Cloud Datastore tables, write a Google App Engine Application that queries all rows, applies a function to derive the metric, and then renders results in a table using the Google charts and visualization API.
- D. Load the data into Google BigQuery tables, write a Google Data Studio 360 report that connects to your data, calculates a metric, and then uses a filter expression to show only suboptimal rows in a table.
Correct Answer: C
Question 16
You need to copy millions of sensitive patient records from a relational database to Google BigQuery.
The total size of the database is 10 TB. You need to design a solution that is secure and time-efficient.
What should you do?
- A. Export the records from the database as an Avro file. Upload the file to Google Cloud Storage using gsutil, and then load the Avro file into Google BigQuery using the Google BigQuery web UI in the GCP Console.
- B. Export the records from the database as an Avro file. Copy the file onto a Transfer Appliance and send it to Google, and then load the Avro file into Google BigQuery using the Google BigQuery web UI in the GCP Console.
- C. Export the records from the database into a CSV file. Create a public URL for the CSV file, and then use Storage Transfer Service to move the file to Google Cloud Storage. Load the CSV file into Google BigQuery using the Google BigQuery web UI in the GCP Console.
- D. Export the records from the database as an Avro file. Create a public URL for the Avro file, and then use Storage Transfer Service to move the file to Google Cloud Storage. Load the Avro file into Google BigQuery using the Google BigQuery web UI in the GCP Console.
Correct Answer: A
Question 17
You need to create a data pipeline that copies time-series transaction data so that it can be queried from within Google BigQuery by your data science team for analysis.
Every hour, thousands of transactions are updated with a new status. The size of the initial dataset is 1.5 PB, and it will grow by 3 TB per day. The data is heavily structured, and your data science team will build machine learning models based on this data. You want to maximize performance and usability for your data science team.
Which two strategies should you adopt? (Choose two.)
- A. Denormalize the data as much as possible.
- B. Preserve the structure of the data as much as possible.
- C. Use Google BigQuery UPDATE to further reduce the size of the dataset.
- D. Develop a data pipeline where status updates are appended to Google BigQuery instead of updated.
- E. Copy a daily snapshot of transaction data to Google Cloud Storage and store it as an Avro file. Use Google BigQuery’s support for external data sources to query.
Correct Answer: D, E
Question 18
You need to create a near real-time inventory dashboard that reads the main inventory tables in your Google BigQuery data warehouse.
Historical inventory data is stored as inventory balances by item and location. You have several thousand updates to inventory every hour. You want to maximize performance of the dashboard and ensure that the data is accurate.
What should you do?
- A. Leverage Google BigQuery UPDATE statements to update the inventory balances as they are changing.
- B. Partition the inventory balance table by item to reduce the amount of data scanned with each inventory update.
- C. Use the Google BigQuery streaming the stream changes into a daily inventory movement table. Calculate balances in a view that joins it to the historical inventory balance table. Update the inventory balance table nightly.
- D. Use the Google BigQuery bulk loader to batch load inventory changes into a daily inventory movement table. Calculate balances in a view that joins it to the historical inventory balance table. Update the inventory balance table nightly.
Correct Answer: A
Question 19
You need to create a new transaction table in Google Cloud Spanner that stores product sales data.
You are deciding what to use as a primary key.
From a performance perspective, which strategy should you choose?
- A. The current epoch time.
- B. A random universally unique identifier number (version 4 UUID).
- C. A concatenation of the product name and the current epoch time.
- D. The original order identification number from the sales system, which is a monotonically increasing integer.
Correct Answer: B
Reference contents:
– Online UUID Generator Tool
– Schema and data model | Cloud Spanner
Question 20
You need to deploy additional dependencies to all of a Google Cloud Dataproc cluster at startup using an existing initialization action.
Company security policies require that Google Cloud Dataproc nodes do not have access to the Internet so public initialization actions cannot fetch resources.
What should you do?
- A. Deploy the Google Cloud SQL Proxy on the Google Cloud Dataproc master.
- B. Use an SSH tunnel to give the Google Cloud Dataproc cluster access to the Internet.
- C. Copy all dependencies to a Google Cloud Storage bucket within your VPC security perimeter.
- D. Use Google Cloud Resource Manager to add the service account used by the Google Cloud Dataproc cluster to the Network User role.
Correct Answer: D
Reference contents:
– Initialization actions | Dataproc Documentation
– Dataproc Cluster Network Configuration | Dataproc Documentation
Question 21
You need to migrate a 2TB relational database to Google Cloud Platform.
You do not have the resources to significantly refactor the application that uses this database and cost to operate is of primary concern.
Which service do you select for storing and serving your data?
- A. Google Cloud Spanner
- B. Google Cloud Bigtable
- C. Firestore
- D. Google Cloud SQL
Correct Answer: D
Question 22
You need to move 2 PB of historical data from an on-premises storage appliance to Google Cloud Storage within six months, and your outbound network capacity is constrained to 20 Mb/sec.
How should you migrate this data to Google Cloud Storage?
- A. Use Google Transfer Appliance to copy the data to Google Cloud Storage.
- B. Use gsutil cp to compress the content being uploaded to Google Cloud Storage.
- C. Create a private URL for the historical data, and then use Storage Transfer Service to copy the data to Google Cloud Storage.
- D. Use trickle or ionice along with gsutil cp to limit the amount of bandwidth gsutil utilizes to less than 20 Mb/sec so it does not interfere with the production traffic.
Correct Answer: A
Question 23
You need to set access to Google BigQuery for different departments within your company.
Your solution should comply with the following requirements:
– Each department should have access only to their data.
– Each department will have one or more leads who need to be able to create and update tables and provide them to their team.
– Each department has data analysts who need to be able to query but not modify data.
How should you set access to the data in Google BigQuery?
- A. Create a dataset for each department. Assign the department leads the role of OWNER, and assign the data analysts the role of WRITER on their dataset.
- B. Create a dataset for each department. Assign the department leads the role of WRITER, and assign the data analysts the role of READER on their dataset.
- C. Create a table for each department. Assign the department leads the role of Owner, and assign the data analysts the role of Editor on the project the table is in.
- D. Create a table for each department. Assign the department leads the role of Editor, and assign the data analysts the role of Viewer on the project the table is in.
Correct Answer: D
Question 24
You need to store and analyze social media postings in Google BigQuery at a rate of 10,000 messages per minute in near real-time. Initially, design the application to use streaming inserts for individual postings.
Your application also performs data aggregations right after the streaming inserts. You discover that the queries after streaming inserts do not exhibit strong consistency, and reports from the queries might miss in-flight data.
How can you adjust your application design?
- A. Re-write the application to load accumulated data every 2 minutes.
- B. Convert the streaming insert code to batch load for individual messages.
- C. Load the original message to Google Cloud SQL, and export the table every hour to Google BigQuery via streaming inserts.
- D. Estimate the average latency for data availability after streaming inserts, and always run queries after waiting twice as long.
Correct Answer: D
Question 25
You operate a database that stores stock trades and an application that retrieves average stock price for a given company over an adjustable window of time.
The data is stored in Google Cloud Bigtable where the datetime of the stock trade is the beginning of the row key. Your application has thousands of concurrent users, and you notice that performance is starting to degrade as more stocks are added.
What should you do to improve the performance of your application?
- A. Change the row key syntax in your Google Cloud Bigtable table to begin with the stock symbol.
- B. Change the row key syntax in your Google Cloud Bigtable table to begin with a random number per second.
- C. Change the data pipeline to use Google BigQuery for storing stock trades, and update your application.
- D. Use Google Cloud Dataflow to write a summary of each day’s stock trades to an Avro file on Google Cloud Storage. Update your application to read from Google Cloud Storage and Google Cloud Bigtable to compute the responses.
Correct Answer: A
Question 26
You operate a logistics company, and you want to improve event delivery reliability for vehicle-based sensors.
You operate small data centers around the world to capture these events, but leased lines that provide connectivity from your event collection infrastructure to your event processing infrastructure are unreliable, with unpredictable latency. You want to address this issue in the most cost-effective way.
What should you do?
- A. Deploy small Kafka clusters in your data centers to buffer events.
- B. Have the data acquisition devices publish data to Google Cloud Pub/Sub.
- C. Establish a Cloud Interconnect between all remote data centers and Google.
- D. Write a Google Cloud Dataflow pipeline that aggregates all data in session windows.
Correct Answer: A
Question 27
You operate an IoT pipeline built around Apache Kafka that normally receives around 5000 messages per second.
You want to use Google Cloud Platform to create an alert as soon as the moving average over 1 hour drops below 4000 messages per second.
What should you do?
- A. Consume the stream of data in Google Cloud Dataflow using Kafka IO. Set a sliding time window of 1 hour every 5 minutes. Compute the average when the window closes, and send an alert if the average is less than 4,000 messages.
- B. Consume the stream of data in Google Cloud Dataflow using Kafka IO. Set a fixed time window of 1 hour. Compute the average when the window closes, and send an alert if the average is less than 4,000 messages.
- C. Use Kafka Connect to link your Kafka message queue to Google Cloud Pub/Sub. Use a Google Cloud Dataflow template to write your messages from Google Cloud Pub/Sub to Google Cloud Bigtable. Use Google Cloud Scheduler to run a script every hour that counts the number of rows created in Google Cloud Bigtable in the last hour. If that number falls below 4,000, send an alert.
- D. Use Kafka Connect to link your Kafka message queue to Google Cloud Pub/Sub. Use a Google Cloud Dataflow template to write your messages from Google Cloud Pub/Sub to Google BigQuery. Use Google Cloud Scheduler to run a script every five minutes that counts the number of rows created in Google BigQuery in the last hour. If that number falls below 4,000, send an alert.
Correct Answer: C
Question 28
You plan to deploy Google Cloud SQL using MySQL.
You need to ensure high availability in the event of a zone failure.
What should you do?
- A. Create a Google Cloud SQL instance in one zone, and create a failover replica in another zone within the same region.
- B. Create a Google Cloud SQL instance in one zone, and create a read replica in another zone within the same region.
- C. Create a Google Cloud SQL instance in one zone, and configure an external read replica in a zone in a different region.
- D. Create a Google Cloud SQL instance in a region, and configure automatic backup to a Google Cloud Storage bucket in the same region.
Correct Answer: C
Question 29
You receive data files in CSV format monthly from a third party.
You need to cleanse this data, but every third month the schema of the files changes. Your requirements for implementing these transformations include:
– Executing the transformations on a schedule.
– Enabling non-developer analysts to modify transformations.
– Providing a graphical tool for designing transformations.
What should you do?
- A. Use Google Cloud Dataprep to build and maintain the transformation recipes, and execute them on a scheduled basis.
- B. Load each month’s CSV data into Google BigQuery, and write a SQL query to transform the data to a standard schema. Merge the transformed tables together with a SQL query.
- C. Help the analysts write a Google Cloud Dataflow pipeline in Python to perform the transformation. The Python code should be stored in a revision control system and modified as the incoming data’s schema changes.
- D. Use Apache Spark on Google Cloud Dataproc to infer the schema of the CSV file before creating a Dataframe. Then implement the transformations in Spark SQL before writing the data out to Google Cloud Storage and loading into Google BigQuery.
Correct Answer: D
Question 30
You set up a streaming data insert into a Redis cluster via a Kafka cluster.
Both clusters are running on Google Compute Engine instances.
You need to encrypt data at rest with encryption keys that you can create, rotate, and destroy as needed. What should you do?
- A. Create a dedicated service account, and use encryption at rest to reference your data stored in your Google Compute Engine cluster instances as part of your API service calls.
- B. Create encryption keys in Google Cloud Key Management Service. Use those keys to encrypt your data in all of the Google Compute Engine cluster instances.
- C. Create encryption keys locally. Upload your encryption keys to Google Cloud Key Management Service. Use those keys to encrypt your data in all of the Google Compute Engine cluster instances.
- D. Create encryption keys in Google Cloud Key Management Service. Reference those keys in your API service calls when accessing the data in your Google Compute Engine cluster instances.
Correct Answer: C
Question 31
You store historic data in Google Cloud Storage. You need to perform analytics on the historic data.
You want to use a solution to detect invalid data entries and perform data transformations that will not require programming or knowledge of SQL.
What should you do?
- A. Use Google Cloud Dataflow with Beam to detect errors and perform transformations.
- B. Use Google Cloud Dataprep with recipes to detect errors and perform transformations.
- C. Use Google Cloud Dataproc with a Hadoop job to detect errors and perform transformations.
- D. Use federated tables in Google BigQuery with queries to detect errors and perform transformations.
Correct Answer: A
Question 32
You use a dataset in Google BigQuery for analysis.
You want to provide third-party companies with access to the same dataset. You need to keep the costs of data sharing low and ensure that the data is current.
Which solution should you choose?
- A. Create an authorized view on the Google BigQuery table to control data access, and provide third-party companies with access to that view.
- B. Use Google Cloud Scheduler to export the data on a regular basis to Google Cloud Storage, and provide third-party companies with access to the bucket.
- C. Create a separate dataset in Google BigQuery that contains the relevant data to share, and provide third-party companies with access to the new dataset.
- D. Create a Google Cloud Dataflow job that reads the data in frequent time intervals, and writes it to the relevant Google BigQuery dataset or Google Cloud Storage bucket for third-party companies to use.
Correct Answer: B
Question 33
You use Google BigQuery as your centralized analytics platform.
New data is loaded every day, and an ETL pipeline modifies the original data and prepares it for the final users. This ETL pipeline is regularly modified and can generate errors, but sometimes the errors are detected only after 2 weeks. You need to provide a method to recover from these errors, and your backups should be optimized for storage costs.
How should you organize your data in Google BigQuery and store your backups?
- A. Organize your data in a single table, export, and compress and store the Google BigQuery data in Google Cloud Storage.
- B. Organize your data in separate tables for each month, and export, compress, and store the data in Google Cloud Storage.
- C. Organize your data in separate tables for each month, and duplicate your data on a separate dataset in Google BigQuery.
- D. Organize your data in separate tables for each month, and use snapshot decorators to restore the table to a time prior to the corruption.
Correct Answer: D
Question 34
You used Google Cloud Dataprep to create a recipe on a sample of data in a Google BigQuery table.
You want to reuse this recipe on a daily upload of data with the same schema, after the load job with variable execution time completes.
What should you do?
- A. Create a cron schedule in Google Cloud Dataprep.
- B. Create an Google App Engine cron job to schedule the execution of the Google Cloud Dataprep job.
- C. Export the recipe as a Google Cloud Dataprep template, and create a job in Google Cloud Scheduler.
- D. Export the Google Cloud Dataprep job as a Google Cloud Dataflow template, and incorporate it into a Google Cloud Composer job.
Correct Answer: C
Question 35
You want to analyze hundreds of thousands of social media posts daily at the lowest cost and with the fewest steps.
You have the following requirements:
– You will batch-load the posts once per day and run them through the Google Cloud Natural Language API.
– You will extract topics and sentiment from the posts.
– You must store the raw posts for archiving and reprocessing.
– You will create dashboards to be shared with people both inside and outside your organization.
You need to store both the data extracted from the API to perform analysis as well as the raw social media posts for historical archiving.
What should you do?
- A. Store the social media posts and the data extracted from the API in Google BigQuery.
- B. Store the social media posts and the data extracted from the API in Google Cloud SQL.
- C. Store the raw social media posts in Google Cloud Storage, and write the data extracted from the API into Google BigQuery.
- D. Feed social media posts into the API directly from the source, and write the extracted data from the API into Google BigQuery.
Correct Answer: D
Question 36
You want to archive data in Google Cloud Storage.
Because some data is very sensitive, you want to use the “Trust No One” (TNO) approach to encrypt your data to prevent the cloud provider staff from decrypting your data.
What should you do?
- A. Use gcloud kms keys to create a symmetric key. Then use gcloud kms encrypt to encrypt each archival file with the key and unique additional authenticated data (AAD). Use gsutil cp to upload each encrypted file to the Google Cloud Storage bucket, and keep the AAD outside of Google Cloud.
- B. Use gcloud kms keys to create a symmetric key. Then use gcloud kms encrypt to encrypt each archival file with the key. Use gsutil cp to upload each encrypted file to the Google Cloud Storage bucket. Manually destroy the key previously used for encryption, and rotate the key once.
- C. Specify customer-supplied encryption key (CSEK) in the .boto configuration file. Use gsutil cp to upload each archival file to the Google Cloud Storage bucket. Save the CSEK in Cloud Memorystore as permanent storage of the secret.
- D. Specify customer-supplied encryption key (CSEK) in the .boto configuration file. Use gsutil cp to upload each archival file to the Google Cloud Storage bucket. Save the CSEK in a different project that only the security team can access.
Correct Answer: B
Question 37
You want to automate execution of a multi-step data pipeline running on Google Cloud.
The pipeline includes Google Cloud Dataproc and Google Cloud Dataflow jobs that have multiple dependencies on each other. You want to use managed services where possible, and the pipeline will run every day.
Which tool should you use?
- A. cron
- B. Google Cloud Composer
- C. Google Cloud Scheduler
- D. Workflow Templates on Google Cloud Dataproc
Correct Answer: D
Question 38
You want to build a managed Hadoop system as your data lake.
The data transformation process is composed of a series of Hadoop jobs executed in sequence. To accomplish the design of separating storage from compute, you decided to use the Google Cloud Storage connector to store all input data, output data, and intermediary data. However, you noticed that one Hadoop job runs very slowly with Google Cloud Dataproc, when compared with the on-premises bare-metal Hadoop environment (8-core nodes with 100-GB RAM). Analysis shows that this particular Hadoop job is disk I/O intensive. You want to resolve the issue.
What should you do?
- A. Allocate sufficient memory to the Hadoop cluster, so that the intermediary data of that particular Hadoop job can be held in memory.
- B. Allocate sufficient persistent disk space to the Hadoop cluster, and store the intermediate data of that particular Hadoop job on native HDFS.
- C. Allocate more CPU cores of the virtual machine instances of the Hadoop cluster so that the networking bandwidth for each instance can scale up.
- D. Allocate additional network interface card (NIC), and configure link aggregation in the operating system to use the combined throughput when working with Google Cloud Storage.
Correct Answer: A
Question 39
You want to migrate an on-premises Hadoop system to Google Cloud Dataproc.
Hive is the primary tool in use, and the data format is Optimized Row Columnar (ORC). All ORC files have been successfully copied to a Google Cloud Storage bucket. You need to replicate some data to the cluster’s local Hadoop Distributed File System (HDFS) to maximize performance.
What are two ways to start using Hive in Google Cloud Dataproc? (Choose two.)
- A. Run the gsutil utility to transfer all ORC files from the Google Cloud Storage bucket to HDFS. Mount the Hive tables locally.
- B. Run the gsutil utility to transfer all ORC files from the Google Cloud Storage bucket to any node of the Dataproc cluster. Mount the Hive tables locally.
- C. Run the gsutil utility to transfer all ORC files from the Google Cloud Storage bucket to the master node of the Dataproc cluster. Then run the Hadoop utility to copy them to HDFS. Mount the Hive tables from HDFS.
- D. Leverage Google Cloud Storage connector for Hadoop to mount the ORC files as external Hive tables. Replicate external Hive tables to the native ones.
- E. Load the ORC files into Google BigQuery. Leverage Google BigQuery connector for Hadoop to mount the Google BigQuery tables as external Hive tables. Replicate external Hive tables to the native ones.
Correct Answer: B, C
Question 40
You want to process payment transactions in a point-of-sale application that will run on Google Cloud Platform.
Your user base could grow exponentially, but you do not want to manage infrastructure scaling.
Which Google database service should you use?
- A. Google Cloud SQL
- B. Google BigQuery
- C. Google Cloud Bigtable
- D. Google Cloud Datastore
Correct Answer: A
Question 41
You want to use a database of information about tissue samples to classify future tissue samples as either normal or mutated.
You are evaluating an unsupervised anomaly detection method for classifying the tissue samples.
Which two characteristics support this method? (Choose two.)
- A. There are very few occurrences of mutations relative to normal samples.
- B. There are roughly equal occurrences of both normal and mutated samples in the database.
- C. You expect future mutations to have different features from the mutated samples in the database.
- D. You expect future mutations to have similar features to the mutated samples in the database.
- E. You already have labels for which samples are mutated and which are normal in the database.
Correct Answer: B, C
Question 42
You want to use a Google BigQuery table as a data sink. In which writing mode(s) can you use Google BigQuery as a sink?
- A. Both batch and streaming.
- B. Google BigQuery cannot be used as a sink.
- C. Only batch.
- D. Only streaming.
- Correct Answer: A
When you apply a Google BigQueryIO.Write transform in batch mode to write to a single table, Dataflow invokes a Google BigQuery load job. When you apply a Google BigQueryIO.Write transform in streaming mode or in batch mode using a function to specify the destination table, Dataflow uses Google BigQuery’s streaming inserts.
Reference contents:
– BigQuery I/O
Question 43
You want to use Google Stackdriver Logging to monitor Google BigQuery usage.
You need an instant notification to be sent to your monitoring tool when new data is appended to a certain table using an insert job, but you do not want to receive notifications for other tables.
What should you do?
- A. Make a call to the Stackdriver API to list all logs, and apply an advanced filter.
- B. In the Stackdriver logging admin interface, and enable a log sink export to Google BigQuery.
- C. In the Stackdriver logging admin interface, enable a log sink export to Google Cloud Pub/Sub, and subscribe to the topic from your monitoring tool.
- D. Using the Stackdriver API, create a project sink with advanced log filter to export to Pub/Sub, and subscribe to the topic from your monitoring tool.
Correct Answer: B
Question 44
You work for a bank.
You have a labelled dataset that contains information on already granted loan applications and whether these applications have been defaulted. You have been asked to train a model to predict default rates for credit applicants.
What should you do?
- A. Increase the size of the dataset by collecting additional data.
- B. Train a linear regression to predict a credit default risk score.
- C. Remove the bias from the data and collect applications that have been declined loans.
- D. Match loan applicants with their social profiles to enable feature engineering.
Correct Answer: B
Question 45
You work for a car manufacturer and have set up a data pipeline using Google Cloud Pub/Sub to capture anomalous sensor events.
You are using a push subscription in Google Cloud Pub/Sub that calls a custom HTTPS endpoint that you have created to take action of these anomalous events as they occur. Your custom HTTPS endpoint keeps getting an inordinate amount of duplicate messages.
What is the most likely cause of these duplicate messages?
- A. The message body for the sensor event is too large.
- B. Your custom endpoint has an out-of-date SSL certificate.
- C. The Google Cloud Pub/Sub topic has too many messages published to it.
- D. Your custom endpoint is not acknowledging messages within the acknowledgement deadline.
Correct Answer: B
Question 46
You work for a global shipping company.
You want to train a model on 40 TB of data to predict which ships in each geographic region are likely to cause delivery delays on any given day. The model will be based on multiple attributes collected from multiple sources. Telemetry data, including location in GeoJSON format, will be pulled from each ship and loaded every hour. You want to have a dashboard that shows how many and which ships are likely to cause delays within a region. You want to use a storage solution that has native functionality for prediction and geospatial processing.
Which storage solution should you use?
- A. Google BigQuery
- B. Google Cloud Bigtable
- C. Google Cloud Datastore
- D. Google Cloud SQL for PostgreSQL
Correct Answer: A
Question 47
You work for a large fast food restaurant chain with over 400,000 employees.
You store employee information in Google BigQuery in a Users table consisting of a FirstName field and a LastName field. A member of IT is building an application and asks you to modify the schema and data in Google BigQuery so the application can query a FullName field consisting of the value of the FirstName field concatenated with a space, followed by the value of the LastName field for each employee.
How can you make that data available while minimizing cost?
- A. Create a view in Google BigQuery that concatenates the FirstName and LastName field values to produce the FullName.
- B. Add a new column called FullName to the Users table. Run an UPDATE statement that updates the FullName column for each user with the concatenation of the FirstName and LastName values.
- C. Create a Google Cloud Dataflow job that queries Google BigQuery for the entire Users table, concatenates the FirstName value and LastName value for each user, and loads the proper values for FirstName, LastName, and FullName into a new table in Google BigQuery.
- D. Use Google BigQuery to export the data for the table to a CSV file. Create a Google Cloud Dataproc job to process the CSV file and output a new CSV file containing the proper values for FirstName, LastName and FullName. Run a Google BigQuery load job to load the new CSV file into Google BigQuery.
Correct Answer: C
Question 48
You work for a manufacturing company that sources up to 750 different components, each from a different supplier.
You’ve collected a labeled dataset that has on average 1000 examples for each unique component. Your team wants to implement an app to help warehouse workers recognize incoming components based on a photo of the component. You want to implement the first working version of this app (as Proof-Of-Concept) within a few working days.
What should you do?
- A. Use Google Cloud Vision AutoML with the existing dataset.
- B. Use Google Cloud Vision AutoML, but reduce your dataset twice.
- C. Use Google Cloud Vision API by providing custom labels as recognition hints.
- D. Train your own image recognition model leveraging transfer learning techniques.
Correct Answer: A
Question 49
You work for a manufacturing plant that batches application log files together into a single log file once a day at 2:00 AM.
You have written a Google Cloud Dataflow job to process that log file. You need to make sure the log file is processed once per day as inexpensively as possible.
What should you do?
- A. Change the processing job to use Google Cloud Dataproc instead.
- B. Manually start the Google Cloud Dataflow job each morning when you get into the office.
- C. Create a cron job with Google App Engine Cron Service to run the Google Cloud Dataflow job.
- D. Configure the Google Cloud Dataflow job as a streaming job so that it processes the log data immediately.
Correct Answer: C
Reference contents:
– Scheduling Jobs with cron.yaml
Question 50
You work for a mid-sized enterprise that needs to move its operational system transaction data from an on-premises database to GCP.
The database is about 20 TB in size.
Which database should you choose?
- A. Google Cloud SQL
- B. Google Cloud Bigtable
- C. Google Cloud Spanner
- D. Google Cloud Datastore
Correct Answer: A
Comments are closed