![[GCP] Google Cloud Certified:Professional Cloud Architect](https://www.cloudsmog.net/wp-content/uploads/google-cloud-certified_professional-cloud-architect-1200x675.jpg)
Ace Your Professional Cloud Architect Certification with Practice Exams.
Google Cloud Certified – Professional Cloud Architect – Practice Exam (Question 61)
Question 1
A development manager is building a new application He asks you to review his requirements and identify what cloud technologies he can use to meet them.
The application must:
- Be based on open-source technology for cloud portability.
- Dynamically scale compute capacity based on demand.
- Support continuous software delivery.
- Run multiple segregated copies of the same application stack.
- Deploy application bundles using dynamic templates.
- Route network traffic to specific services based on URL.
Which combination of technologies will meet all of his requirements?
- A. Google Container Engine, Jenkins, and Helm
- B. Google Container Engine and Google Cloud Load Balancing
- C. Google Compute Engine and Google Cloud Deployment Manager
- D. Google Compute Engine, Jenkins, and Google Cloud Load Balancing
Correct Answer: A
Helm for managing Kubernetes
Kubernetes can base on the URL to route traffic to different location (path)
Reference contents:
– Setting up HTTP(S) Load Balancing with Ingress
Question 2
For this question, refer to the Dress4Win case study.
Dress4Win has end-to-end tests covering 100% of their endpoints. They want to ensure that the move to the cloud does not introduce any new bugs.
Which additional testing methods should the developers employ to prevent an outage?
- A. They should run the end-to-end tests in the cloud staging environment to determine if the code is working as intended.
- B. They should add additional unit tests and production scale load tests on their cloud staging environment.
- C. They should enable Google Stackdriver Debugger on the application code to show errors in the code.
- D. They should add canary tests so developers can measure how much of an impact the new release causes to latency.
Correct Answer: B
Question 3
For this question, refer to the TerramEarth case study.
TerramEarth plans to connect all 20 million vehicles in the field to the cloud.
This increases the volume to 20 million 600 byte records a second for 40 TB an hour. How should you design the data ingestion?
- A. Vehicles write data directly to Google Cloud Storage.
- B. Vehicles write data directly to Google Cloud Pub/Sub.
- C. Vehicles stream data directly to Google BigQuery.
- D. Vehicles continue to write data using the existing system (FTP).
Correct Answer: B
Reference contents:
– Data lifecycle
– Designing a Connected Vehicle Platform on Cloud IoT Core
Question 4
For this question, refer to the TerramEarth case study.
TerramEarth has decided to store data files in Google Cloud Storage. You need to configure Google Cloud Storage (GCS) lifecycle rule to store 1 year of data and minimize file storage cost.
Which two actions should you take?
- A. Create a GCS lifecycle rule with Age: “30”, Storage Class: “Standard”, and Action: “Set to Coldline”, and create a second GCS life-cycle rule with Age: “365”, Storage Class: “Coldline”, and Action: “Delete”.
- B. Create a GCS lifecycle rule with Age: “30”, Storage Class: “Coldline”, and Action: “Set to Nearline”, and create a second GCS life-cycle rule with Age: “91”, Storage Class: “Coldline”, and Action: “Set to Nearline”.
- C. Create a GCS lifecycle rule with Age: “90”, Storage Class: “Standard”, and Action: “Set to Nearline”, and create a second GCS life-cycle rule with Age: “91”, Storage Class: “Nearline”, and Action: “Set to Coldline”.
- D. Create a GCS lifecycle rule with Age: “30”, Storage Class: “Standard”, and Action: “Set to Coldline”, and create a second GCS life-cycle rule with Age: “365”, Storage Class: “Nearline”, and Action: “Delete”.
Correct Answer: A
Question 5
You write a Python script to connect to Google BigQuery from a Google Compute Engine virtual machine. The script is printing errors that it cannot connect to Google BigQuery.
What should you do to fix the script?
- A. Install the latest Google BigQuery API client library for Python.
- B. Run your script on a new virtual machine with the Google BigQuery access scope enabled.
- C. Create a new service account with Google BigQuery access and execute your script with that user.
- D. Install the bq component for gccloud with the command gcloud components install bq.
Correct Answer: B
The error is most like caused by the access scope issue. When create new instance, you have the default Google Compute Engine default service account but most serves access including Google BigQuery is not enable. Create an instance Most access are not enabled by default You have default service account but don’t have the permission (scope) you can stop the instance, edit, change scope and restart it to enable the scope access. Of course, if you Run your script on a new virtual machine with the Google BigQuery access scope enabled, it also works.
Reference contents:
– Service accounts
Question 6
For this question, refer to the Dress4Win case study.
To be legally compliant during an audit, Dress4Win must be able to give insights in all administrative actions that modify the configuration or metadata of resources on Google Cloud.
What should you do?
- A. Use Stackdriver Trace to create a trace list analysis.
- B. Use Stackdriver Monitoring to create a dashboard on the project’s activity.
- C. Enable Google Cloud Identity-Aware Proxy in all projects, and add the group of Administrators as a member.
- D. Use the Activity page in the GCP Console and Stackdriver Logging to provide the required insight.
Correct Answer: A
Reference contents:
– Cloud Audit Logs
Question 7
Your customer wants to capture multiple GBs of aggregate real-time key performance indicators (KPIs) from their game servers running on Google Cloud Platform and monitor the KPIs with low latency.
How should they capture the KPIs?
- A. Store time-series data from the game servers in Google Cloud Bigtable, and view it using Google Data Studio.
- B. Output custom metrics to Stackdriver from the game servers, and create a Dashboard in Stackdriver Monitoring Console to view them.
- C. Schedule Google BigQuery load jobs to ingest analytics files uploaded to Google Cloud Storage every ten minutes, and visualize the results in Google Data Studio.
- D. Insert the KPIs into Google Cloud Datastore entities, and run ad hoc analysis and visualizations of them in Google Cloud Datalab.
Correct Answer: A
Reference contents:
– Structure of time series
Question 8
Your applications will be writing their logs to Google BigQuery for analysis. Each application should have its own table.
Any logs older than 45 days should be removed. You want to optimize storage and follow Google recommended practices.
What should you do?
- A. Configure the expiration time for your tables at 45 days.
- B. Make the tables time-partitioned, and configure the partition expiration at 45 days.
- C. Rely on Google BigQuery’s default behavior to prune application logs older than 45 days.
- D. Create a script that uses the Google BigQuery command line tool (bq) to remove records older than 45 days.
Correct Answer: B
Reference contents:
– Managing partitioned tables
Question 9
For this question, refer to the JencoMart case study.
The migration of JencoMart’s application to Google Cloud Platform (GCP) is progressing too slowly. The infrastructure is shown in the diagram. You want to maximize throughput.
What are three potential bottlenecks? (Choose 3 answers.)
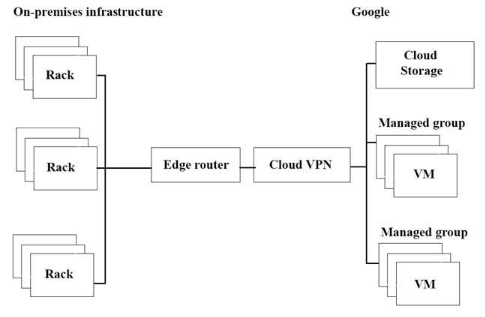
- A. Complicated internet connectivity between the on-premises infrastructure and GCP.
- B. A tier of Google Cloud Storage that is not suited for this task.
- C. A single VPN tunnel, which limits throughput.
- D. A copy command that is not suited to operate over long distances.
- E. Fewer virtual machines (VMs) in GCP than on-premises machines.
- F. A separate storage layer outside the VMs, which is not suited for this task.
Correct Answer: A, C, E
Question 10
Your company is migrating its on-premises data center into the cloud.
As part of the migration, you want to integrate Google Kubernetes Engine for workload orchestration. Parts of your architecture must also be PCI DSScompliant.
Which of the following is most accurate?
- A. Google App Engine is the only compute platform on GCP that is certified for PCI DSS hosting.
- B. Google Kubernetes Engine cannot be used under PCI DSS because it is considered shared hosting.
- C. Google Kubernetes Engine and GCP provide the tools you need to build a PCI DSS-compliant environment.
- D. All Google Cloud services are usable because GCP is certified PCI-compliant.
Correct Answer: D
Reference contents:
– PCI DSS
Question 11
Your company wants to track whether someone is present in a meeting room reserved for a scheduled meeting.
There are 1000 meeting rooms across 5 offices on 3 continents. Each room is equipped with a motion sensor that reports its status every second. The data from the motion detector includes only a sensor ID and several different discrete items of information. Analysts will use this data, together with information about account owners and office locations.
Which database type should you use?
- A. Flat file
- B. NoSQL
- C. Relational
- D. Blobstore
Correct Answer: B
Relational databases were not designed to cope with the scale and agility challenges that face modern applications, nor were they built to take advantage of the commodity storage and processing power available today.
NoSQL fits well for:
Incorrect Answers:
D: The Blobstore API allows your application to serve data objects, called blobs, that are much larger than the size allowed for objects in the Datastore service. Blobs are useful for serving large files, such as video or image files, and for allowing users to upload large data files.
Reference contents:
– What is NoSQL?
Question 12
For this question, refer to the TerramEarth case study.
To speed up data retrieval, more vehicles will be upgraded to cellular connections and be able to transmit data to the ETL process. The current FTP process is error-prone and restarts the data transfer from the start of the file when connections fail, which happens often. You want to improve the reliability of the solution and minimize data transfer time on the cellular connections.
What should you do?
- A. Use one Google Container Engine cluster of FTP servers. Save the data to a Multi-Regional bucket. Run the ETL process using data in the bucket.
- B. Use multiple Google Container Engine clusters running FTP servers located in different regions. Save the data to Multi-Regional buckets in us, eu, and asia. Run the ETL process using the data in the bucket.
- C. Directly transfer the files to different Google Cloud Multi-Regional Storage bucket locations in us, eu, and asia using Google APIs over HTTP(S). Run the ETL process using the data in the bucket.
- D. Directly transfer the files to a different Google Cloud Regional Storage bucket location in us, eu, and asia using Google APIs over HTTP(S). Run the ETL process to retrieve the data from each Regional bucket.
Correct Answer: D
Reference contents:
– Bucket locations
Question 13
You are helping the QA team to roll out a new load-testing tool to test the scalability of your primary cloud services that run on Google Compute Engine with Google Cloud Bigtable.
Which three requirements should they include? (Choose 3 answers)
- A. Create a separate Google Cloud project to use for the load-testing environment.
- B. Instrument the production services to record every transaction for replay by the load-testing tool.
- C. Schedule the load-testing tool to regularly run against the production environment.
- D. Instrument the load-testing tool and the target services with detailed logging and metrics collection.
- E. Ensure all third-party systems your services use are capable of handling high load.
- F. Ensure that the load tests validate the performance of Google Cloud Bigtable.
Correct Answer: A ,D, F
Question 14
The application reliability team at your company has added a debug feature to their backend service to send all server events to Google Cloud Storage for eventual analysis. The event records are at least 50 KB and at most 15 MB and are expected to peak at 3,000 events per second. You want to minimize data loss.
Which process should you implement?
- A. Append metadata to file body.
- Compress individual files.
- Name files with serverName-Timestamp.
- Create a new bucket if bucket is older than 1 hour and save individual files to the new bucket. Otherwise, save files to existing bucket
- B. Batch every 10,000 events with a single manifest file for metadata.
- Compress event files and manifest file into a single archive file.
- Name files using serverName-EventSequence.
- Create a new bucket if bucket is older than 1 day and save the single archive file to the new bucket. Otherwise, save the single archive file to existing bucket.
- C. Compress individual files.
- Name files with serverName-EventSequence.
- Save files to one bucket.
- Set custom metadata headers for each object after saving.
- D. Append metadata to file body.
- Compress individual files.
- Name files with a random prefix pattern.
- Save files to one bucket.
Correct Answer: D
In order to maintain a high request rate, avoid using sequential names. Using completely random object names will give you the best load distribution. Randomness after a common prefix is effective under the prefix.
Reference contents:
– Request rate and access distribution guidelines
Question 15
For this question, refer to the TerramEarth case study.
You analyzed TerramEarth’s business requirement to reduce downtime, and found that they can achieve a majority of time saving by reducing customers’ wait time for parts You decided to focus on reduction of the 3 weeks aggregate reporting time.
Which modifications to the company’s processes should you recommend?
- A. Migrate from CSV to binary format, migrate from FTP to SFTP transport, and develop machine learning analysis of metrics.
- B. Migrate from FTP to streaming transport, migrate from CSV to binary format, and develop machine learning analysis of metrics.
- C. Increase fleet cellular connectivity to 80%, migrate from FTP to streaming transport, and develop machine learning analysis of metrics.
- D. Migrate from FTP to SFTP transport, develop machine learning analysis of metrics, and increase dealer local inventory by a fixed factor.
Correct Answer: C
The Avro binary format is the preferred format for loading compressed data. Avro data is faster to load because the data can be read in parallel, even when the data blocks are compressed.
Google Cloud Storage supports streaming transfers with the gsutil tool or boto library, based on HTTP chunked transfer encoding. Streaming data lets you stream data to and from your Google Cloud Storage account as soon as it becomes available without requiring that the data be first saved to a separate file. Streaming transfers are useful if you have a process that generates data and you do not want to buffer it locally before uploading it, or if you want to send the result from a computational pipeline directly into Google Cloud Storage.
Reference contents:
– Streaming transfers
– Introduction to loading data
Question 16
For this question, refer to the Mountkirk Games case study.
You need to analyze and define the technical architecture for the database workloads for your company, Mountkirk Games. Considering the business and technical requirements, what should you do?
- A. Use Google Cloud SQL for time series data, and use Google Cloud Bigtable for historical data queries.
- B. Use Google Cloud SQL to replace MySQL, and use Google Cloud Spanner for historical data queries.
- C. Use Google Cloud Bigtable to replace MySQL, and use Google BigQuery for historical data queries.
- D. Use Google Cloud Bigtable for time series data, use Google Cloud Spanner for transactional data, and use Google BigQuery for historical data queries.
Correct Answer: D
Reference contents:
– Schema design for time series data
Question 17
For this question, refer to the Mountkirk Games case study.
Mountkirk Games wants you to design a way to test the analytics platform’s resilience to changes in mobile network latency.
What should you do?
- A. Deploy failure injection software to the game analytics platform that can inject additional latency to mobile client analytics traffic.
- B. Create an opt-in beta of the game that runs on players’ mobile devices and collects response times from analytics endpoints running in Google Cloud Platform regions all over the world.
- C. Build a test client that can be run from a mobile phone emulator on a Google Compute Engine virtual machine, and run multiple copies in Google Cloud Platform regions all over the world to generate realistic traffic.
- D. Add the ability to introduce a random amount of delay before beginning to process analytics files uploaded from mobile devices.
Correct Answer: B
Question 18
For this question, refer to the Dress4Win case study.
As part of their new application experience, Dress4Wm allows customers to upload images of themselves. The customer has exclusive control over who may view these images. Customers should be able to upload images with minimal latency and also be shown their images quickly on the main application page when they log in.
Which configuration should Dress4Win use?
- A. Use a distributed file system to store customers’ images. As storage needs increase, add more persistent disks and/or nodes. Assign each customer a unique ID, which sets each file’s owner attribute, ensuring privacy of images.
- B. Store image files in a Google Cloud Storage bucket. Add custom metadata to the uploaded images in Google Cloud Storage that contains the customer’s unique ID.
- C. Store image files in a Google Cloud Storage bucket. Use Google Cloud Datastore to maintain metadata that maps each customer’s ID and their image files.
- D. Use a distributed file system to store customers’ images. As storage needs increase, add more persistent disks and/or nodes. Use a Google Cloud SQL database to maintain metadata that maps each customer’s ID to their image files.
Correct Answer: C
Question 19
You want to optimize the performance of an accurate, real-time, weather-charting application. The data comes from 50,000 sensors sending 10 readings a second, in the format of a timestamp and sensor reading.
Where should you store the data?
- A. Google BigQuery
- B. Google Cloud SQL
- C. Google Cloud Bigtable
- D. Google Cloud Storage
Correct Answer: C
It is time-series data, So Big Table.
Google Cloud Bigtable is a scalable, fully-managed NoSQL wide-column database that is suitable for both real-time access and analytics workloads.
Good for:
– Low-latency read/write access
– High-throughput analytics
– Native time series support
– Common workloads:
– IoT, finance, adtech
– Personalization, recommendations
– Monitoring
– Geospatial datasets
– Graphs
Reference contents:
– Schema design for time series data
– Cloud storage products
Question 20
For this question, refer to the TerramEarth case study.
Your development team has created a structured API to retrieve vehicle data. They want to allow third parties to develop tools for dealerships that use this vehicle event data. You want to support delegated authorization against this data.
What should you do?
- A. Build or leverage an OAuth-compatible access control system.
- B. Build SAML 2.0 SSO compatibility into your authentication system.
- C. Restrict data access based on the source IP address of the partner systems.
- D. Create secondary credentials for each dealer that can be given to the trusted third party.
Correct Answer: A
Delegate application authorization with OAuth2 Google Cloud Platform APIs support OAuth 2.0, and scopes provide granular authorization over the methods that are supported. Google Cloud Platform supports both service-account and user-account OAuth, also called three-legged OAuth.
Reference contents:
– Best practices for enterprise organizations
Question 21
Your architecture calls for the centralized collection of all admin activity and VM system logs within your project.
How should you collect these logs from both VMs and services?
- A. All admin and VM system logs are automatically collected by Stackdriver.
- B. Stackdriver automatically collects admin activity logs for most services. The Stackdriver Logging agent must be installed on each instance to collect system logs.
- C. Launch a custom syslogd compute instance and configure your GCP project and VMs to forward all logs to it.
- D. Install the Stackdriver Logging agent on a single compute instance and let it collect all audit and access logs for your environment.
Correct Answer: B
Reference contents:
– Default Logging agent logs
Question 22
Your customer wants to do resilience testing of their authentication layer. This consists of a regional managed instance group serving a public REST API that reads from and writes to a Google Cloud SQL instance.
What should you do?
- A. Schedule a disaster simulation exercise during which you can shut off all VMs in a zone to see how your application behaves.
- B. Deploy intrusion detection software to your virtual machines to detect and log unauthorized access.
- C. Configure a red replica for your Google Cloud SQL instance in a different zone than the master, and then manually trigger a failover while monitoring KPIs for our REST API.
- D. Engage with a security company to run web scrapes that look your users’ authentication data om malicious websites and notify you if any if found.
Correct Answer: A
Question 23
A news teed web service has the following code running on Google App Engine. During peak load, users report that they can see news articles they already viewed.
What is the most likely cause of this problem?
import news
from flask import Flask, redirect, request
from flask.ext.api import status
from google.appengine.api import users
app = Flask (_name_)
sessions = { }
@app.route ("/")
def homepage():
user = users.get_current_user()
if not user:
return "Invalid login",
status.HTTP_401_UNAUTHORIZED
if user not in sessions :
sessions (user] = { "viewed": []}
news_articles = news.get_new_news (user, sessions [user] ["viewed"])
sessions [user] ["viewed"] + [n["id"] for n in news_articles]
return news.render (news_articles)
if _name_ == "_main_":
app.run()- A. The session variable is local to just a single instance.
- B. The session variable is being overwritten in Google Cloud Datastore.
- C. The URL of the API needs to be modified to prevent caching.
- D. The HTTP Expires header needs to be set to -1 to stop caching.
Correct Answer: A
Reference contents:
– Google App Engine Cache List in Session Variable
Question 24
For this question, refer to the Dress4Win case study.
As part of Dress4Win’s plans to migrate to the cloud, they want to be able to set up a managed logging and monitoring system so they can handle spikes in their traffic load. They want to ensure that:
– The infrastructure can be notified when it needs to scale up and down to handle the ebb and flow of usage throughout the day.
– Their administrators are notified automatically when their application reports errors.
– They can filter their aggregated logs down in order to debug one piece of the application across many hosts.
Which Google StackDriver features should they use?
- A. Logging, Alerts, Insights, Debug
- B. Monitoring, Logging, Debug, Error Report
- C. Monitoring, Logging, Alerts, Error Reporting
- D. Monitoring, Trace, Debug, Logging
Correct Answer: B
Question 25
Your company has successfully migrated to the cloud and wants to analyze their data stream to optimize operations.
They do not have any existing code for this analysis, so they are exploring all their options. These options include a mix of batch and stream processing, as they are running some hourly jobs and live-processing some data as it comes in.
Which technology should they use for this?
- A. Google Cloud Dataproc
- B. Google Cloud Dataflow
- C. Google Container Engine with Google Cloud Bigtable
- D. Google Compute Engine with Google BigQuery
Correct Answer: B
Dataflow is for processing both the Batch and Stream.
Google Cloud Dataflow is a fully-managed service for transforming and enriching data in stream (real time) and batch (historical) modes with equal reliability and expressiveness — no more complex workarounds or compromises needed.
Reference contents:
– Dataflow
Question 26
For this question, refer to the Mountkirk Games case study.
Mountkirk Games wants to set up a real-time analytics platform for their new game. The new platform must meet their technical requirements. Which combination of Google technologies will meet all of their requirements?
- A. Google Container Engine, Google Cloud Pub/Sub, and Google Cloud SQL
- B. Google Cloud Dataflow, Google Cloud Storage, Google Cloud Pub/Sub, and Google BigQuery
- C. Google Cloud SQL, Google Cloud Storage, Google Cloud Pub/Sub, and Google Cloud Dataflow
- D. Google Cloud Dataproc, Google Cloud Pub/Sub, Google Cloud SQL, and Google Cloud Dataflow
- E. Google Cloud Pub/Sub, Google Compute Engine, Google Cloud Storage, and Google Cloud Dataproc
Correct Answer: B
A real time requires Stream / Messaging so Pub/Sub, Analytics by Google BigQuery.
Ingest millions of streaming events per second from anywhere in the world with Google Cloud Pub/Sub, powered by Google’s unique, high-speed private network. Process the streams with Google Cloud Dataflow to ensure reliable, exactly-once, low-latency data transformation. Stream the transformed data into Google BigQuery, the cloud-native data warehousing service, for immediate analysis via SQL or popular visualization tools.
From scenario: They plan to deploy the game’s backend on Google Compute Engine so they can capture streaming metrics, run intensive analytics.
Requirements for Game Analytics Platform:
– Dynamically scale up or down based on game activity.
– Process incoming data on the fly directly from the game servers.
– Process data that arrives late because of slow mobile networks.
– Allow SQL queries to access at least 10 TB of historical data.
– Process files that are regularly uploaded by users’ mobile devices.
– Use only fully managed services.
Reference contents:
– Stream analytics
Question 27
Your company acquired a healthcare startup and must retain its customers’ medical information for up to 4 more years, depending on when it was created. Your corporate policy is to securely retain this data, and then delete it as soon as regulations allow.
Which approach should you take?
- A. Store the data in Google Drive and manually delete records as they expire.
- B. Anonymize the data using the Google Cloud Data Loss Prevention API and store it indefinitely.
- C. Store the data using the Google Cloud Storage and use lifecycle management to delete files when they expire.
- D. Store the data in Google Cloud Storage and run a nightly batch script that deletes all expired datA.
Correct Answer: C
Reference contents:
– Object Lifecycle Management
Question 28
For this question, refer to the Dress4Win case study.
At Dress4Win, an operations engineer wants to create a tow-cost solution to remotely archive copies of database backup files. The database files are compressed tar files stored in their current data center.
How should he proceed?
- A. Create a cron script using gsutil to copy the files to a Coldline Storage bucket.
- B. Create a cron script using gsutil to copy the files to a Regional Storage bucket.
- C. Create a Google Cloud Storage Transfer Service Job to copy the files to a Coldline Storage bucket.
- D. Create a Google Cloud Storage Transfer Service job to copy the files to a Regional Storage bucket.
Correct Answer: A
Follow these rules of thumb when deciding whether to use gsutil or Storage Transfer Service:
– When transferring data from an on-premises location, use gsutil.
– When transferring data from another cloud storage provider, use Storage Transfer Service.
– Otherwise, evaluate both tools with respect to your specific scenario.
Use this guidance as a starting point. The specific details of your transfer scenario will also help you determine which tool is more appropriate.
Reference contents:
– Google Cloud Storage Transfer Service Overview
Question 29
For this question, refer to the Dress4Win case study.
The Dress4Win security team has disabled external SSH access into production virtual machines (VMs) on Google Cloud Platform (GCP). The operations team needs to remotely manage the VMs, build and push Docker containers, and manage Google Cloud Storage objects.
What can they do?
- A. Grant the operations engineers access to use Google Cloud Shell.
- B. Have the development team build an API service that allows the operations team to execute specific remote procedure calls to accomplish their tasks.
- C. Develop a new access request process that grants temporary SSH access to cloud VMs when an operations engineer needs to perform a task.
- D. Configure a VPN connection to GCP to allow SSH access to the cloud VMs.
Correct Answer: A
Question 30
For this question, refer to the Dress4Win case study.
Dress4Win is expected to grow to 10 times its size in 1 year with a corresponding growth in data and traffic that mirrors the existing patterns of usage. The CIO has set the target of migrating production infrastructure to the cloud within the next 6 months.
How will you configure the solution to scale for this growth without making major application changes and still maximize the ROI?
- A. Implement managed instance groups for the Tomcat and Nginx. Migrate MySQL to Google Cloud SQL, RabbitMQ to Google Cloud Pub/Sub, Hadoop to Google Cloud Dataproc, and NAS to Google Cloud Storage.
- B. Implement managed instance groups for Tomcat and Nginx. Migrate MySQL to Google Cloud SQL, RabbitMQ to Google Cloud Pub/Sub, Hadoop to Google Cloud Dataproc, and NAS to Google Compute Engine with Persistent Disk storage.
- C. Migrate RabbitMQ to Google Cloud Pub/Sub, Hadoop to Google BigQuery, and NAS to Google Compute Engine with Persistent Disk storage. Deploy Tomcat, and deploy Nginx using Google Cloud Deployment Manager.
- D. Migrate the web application layer to Google App Engine, and MySQL to Google Cloud Datastore, and NAS to Google Cloud Storage. Deploy RabbitMQ, and deploy Hadoop servers using Google Cloud Deployment Manager.
Correct Answer: A
Question 31
For this question, refer to the JencoMart case study.
A few days after JencoMart migrates the user credentials database to Google Cloud Platform and shuts down the old server, the new database server stops responding to SSH connections. It is still serving database requests to the application servers correctly.
What three steps should you take to diagnose the problem? (Choose 3 answers)
- A. Delete the virtual machine (VM) and disks and create a new one.
- B. Delete the instance, attach the disk to a new VM, and investigate.
- C. Take a snapshot of the disk and connect to a new machine to investigate.
- D. Check inbound firewall rules for the network the machine is connected to.
- E. Connect the machine to another network with very simple firewall rules and investigate.
- F. Print the Serial Console output for the instance for troubleshooting, activate the interactive console, and investigate.
Correct Answer: C, D, F
D: Handling “Unable to connect on port 22” error message Possible causes include:
There is no firewall rule allowing SSH access on the port. SSH access on port 22 is enabled on all Google Compute Engine instances by default. If you have disabled access, SSH from the Browser will not work. If you run sshd on a port other than 22, you need to enable the access to that port with a custom firewall rule.
The firewall rule allowing SSH access is enabled, but is not configured to allow connections from GCP Console services. Source IP addresses for browser-based SSH sessions are dynamically allocated by GCP Console and can vary from session to session.
Reference contents:
– Troubleshooting SSH
– SSH from the browser
Question 32
Your company’s test suite is a custom C++ application that runs tests throughout each day on Linux virtual machines. The full test suite takes several hours to complete, running on a limited number of on premises servers reserved for testing. Your company wants to move the testing infrastructure to the cloud, to reduce the amount of time it takes to fully test a change to the system, while changing the tests as little as possible. Which cloud infrastructure should you recommend?
- A. Google Compute Engine unmanaged instance groups and Network Load Balancer.
- B. Google Compute Engine managed instance groups with auto-scaling.
- C. Google Cloud Dataproc to run Apache Hadoop jobs to process each test.
- D. Google App Engine with Google Stackdriver for logging.
Correct Answer: B
Google Compute Engine enables users to launch virtual machines (VMs) on demand. VMs can be launched from the standard images or custom images created by users.
Managed instance groups offer auto-scaling capabilities that allow you to automatically add or remove instances from a managed instance group based on increases or decreases in load. Autoscaling helps your applications gracefully handle increases in traffic and reduces cost when the need for resources is lower.
Reference contents:
– Instance groups
Question 33
Your customer is moving an existing corporate application to Google Cloud Platform from an on-premises data center. The business owners require minimal user disruption. There are strict security team requirements for storing passwords.
What authentication strategy should they use?
- A. Use G Suite Password Sync to replicate passwords into Google.
- B. Federate authentication via SAML 2.0 to the existing Identity Provider.
- C. Provision users in Google using the Google Cloud Directory Sync tool.
- D. Ask users to set their Google password to match their corporate password.
Correct Answer: B
Reference contents:
– Authenticating corporate users in a hybrid environment
Question 34
One of the developers on your team deployed their application in Google Container Engine with the Dockerfile below. They report that their application deployments are taking too long.
FROM ./src
RUN apt-get update && apt-get install -y python python-pip
RUN pip install -r requirements.txtYou want to optimize this Dockerfile for faster deployment times without adversely affecting the app’s functionality.
Which two actions should you take? (Choose 2 answers)
- A. Remove Python after running pip.
- B. Remove dependencies from requirements.txt.
- C. Use a slimmed-down base image like Alpine linux.
- D. Use larger machine types for your Google Container Engine node pools.
- E. Copy the source after the package dependencies (Python and pip) are installed.
Correct Answer: C, E
The speed of deployment can be changed by limiting the size of the uploaded app, limiting the complexity of the build necessary in the Dockerfile, if present, and by ensuring a fast and reliable internet connection.
Note: Alpine Linux is built around musl libc and busybox. This makes it smaller and more resource efficient than traditional GNU/Linux distributions. A container requires no more than 8 MB and a minimal installation to disk requires around 130 MB of storage. Not only do you get a fully-fledged Linux environment but a large selection of packages from the repository.
Reference contents:
– Google App Engine is slow to deploy, hangs on “Updating service [someproject]…”
– Small. Simple. Secure.
Question 35
For this question, refer to the Dress4Win case study.
Dress4Win has configured a new uptime check with Google Stackdriver for several of their legacy services. The Stackdriver dashboard is not reporting the services as healthy.
What should they do?
- A. Configure their legacy web servers to allow requests that contain user-Agent HTTP header when the value matches GoogleStackdriverMonitoring- UptimeChecks.
- B. In the Google Cloud Platform Console download the list of the uptime servers’ IP addresses and create an inbound firewall rule
- C. Install the Stackdriver agent on all of the legacy web servers.
- D. Configure their load balancer to pass through the User-Agent HTTP header when the value matches GoogleStackdriverMonitoring-UptimeChecks.
Correct Answer: B
Question 36
Your company has decided to make a major revision of their API in order to create better experiences for their developers. They need to keep the old version of the API available and deployable, while allowing new customers and testers to try out the new API. They want to keep the same SSL and DNS records in place to serve both APIs.
What should they do?
- A. Configure a new load balancer for the new version of the API.
- B. Reconfigure old clients to use a new endpoint for the new API.
- C. Have the old API forward traffic to the new API based on the path.
- D. Use separate backend pools for each API path behind the load balancer.
Correct Answer: D
Reference contents:
– API lifecycle management
Question 37
The development team has provided you with a Kubernetes Deployment file. You have no infrastructure yet and need to deploy the application.
What should you do?
- A. Use gcloud to create a Kubernetes cluster. Use Deployment Manager to create the deployment.
- B. Use gcloud to create a Kubernetes cluster. Use kubect1 to create the deployment.
- C. Use kubect1 to create a Kubernetes cluster. Use Deployment Manager to create the deployment.
- D. Use kubect1 to create a Kubernetes cluster. Use kubect1 to create the deployment.
Correct Answer: B
Reference contents:
– Creating a zonal cluster
Question 38
During a high traffic portion of the day, one of your relational databases crashes, but the replica is never promoted to a master. You want to avoid this in the future.
What should you do?
- A. Use a different database.
- B. Choose larger instances for your database.
- C. Create snapshots of your database more regularly.
- D. Implement routinely scheduled failovers of your databases.
Correct Answer: D
Reference contents:
– Disaster recovery planning guide
Question 39
You have developed an application using Google Cloud ML Engine that recognizes famous paintings from uploaded images. You want to test the application and allow specific people to upload images for the next 24 hours. Not all users have a Google Account.
How should you have users upload images?
- A. Have users upload the images to Google Cloud Storage. Protect the bucket with a password that expires after 24 hours.
- B. Have users upload the images to Google Cloud Storage using a signed URL that expires after 24 hours.
- C. Create an Google App Engine web application where users can upload images. Configure Google App Engine to disable the application after 24 hours. Authenticate users via Google Cloud Identity.
- D. Create an Google App Engine web application where users can upload images for the next 24 hours. Authenticate users via Google Cloud Identity.
Correct Answer: A
Reference contents:
– Uploading images directly to Cloud Storage using Signed URL
Question 40
Your customer is receiving reports that their recently updated Google App Engine application is taking approximately 30 seconds to load for some of their users. This behavior was not reported before the update.
What strategy should you take?
- A. Work with your ISP to diagnose the problem.
- B. Open a support ticket to ask for network capture and flow data to diagnose the problem, then roll back your application.
- C. Roll back to an earlier known good release initially, then use Stackdriver Trace and logging to diagnose the problem in a development/test/staging environment.
- D. Roll back to an earlier known good release, then push the release again at a quieter period to investigate. Then use Stackdriver Trace and logging to diagnose the problem.
Correct Answer: C
Stackdriver Logging allows you to store, search, analyze, monitor, and alert on log data and events from Google Cloud Platform and Amazon Web Services (AWS). Our API also allows ingestion of any custom log data from any source. Stackdriver Logging is a fully managed service that performs at scale and can ingest application and system log data from thousands of VMs. Even better, you can analyze all that log data in real time.
Reference contents:
– Cloud Logging
Question 41
An application development team believes their current logging tool will not meet their needs for their new cloud-based product. They want a bettor tool to capture errors and help them analyze their historical log data. You want to help them find a solution that meets their needs, what should you do?
- A. Direct them to download and install the Google StackDriver logging agent.
- B. Send them a list of online resources about logging best practices.
- C. Help them define their requirements and assess viable logging tools.
- D. Help them upgrade their current tool to take advantage of any new features.
Correct Answer: C
Help them define their requirements and assess viable logging tools. They know the requirements and the existing tools’ problems. While it’s true StackDriver Logging and Error Reporting possibly meet all their requirements, there might be other tools also meet their need. They need you to provide expertise to make assessment for new tools, specifically, logging tools that can “capture errors and help them analyze their historical log data”.
Reference contents:
– Installing the Cloud Logging agent on a single VM
Question 42
Your company’s user-feedback portal comprises a standard LAMP stack replicated across two zones.
It is deployed in the us-central1 region and uses autoscaled managed instance groups on all layers, except the database. Currently, only a small group of select customers have access to the portal. The portal meets a 99.99% availability SLA under these conditions However next quarter, your company will be making the portal available to all users, including unauthenticated users. You need to develop a resiliency testing strategy to ensure the system maintains the SLA once they introduce additional user load.
What should you do?
- A. Capture existing users input, and replay captured user load until autoscale is triggered on all layers. At the same time, terminate all resources in one of the zones.
- B. Expose the new system to a larger group of users, and increase group size each day until autoscale logic is tnggered on all layers. At the same time, terminate random resources on both zones.
- C. Create synthetic random user input, replay synthetic load until autoscale logic is triggered on at least one layer, and introduce “chaos” to the system by terminating random resources on both zones.
- D. Capture existing users input, and replay captured user load until resource utilization crosses 80%. Also, derive estimated number of users based on existing users usage of the app, and deploy enough resources to handle 200% of expected load.
Correct Answer: A
Question 43
As part of implementing their disaster recovery plan, your company is trying to replicate their production MySQL database from their private data center to their GCP project using a Google Cloud VPN connection.
They are experiencing latency issues and a small amount of packet loss that is disrupting the replication.
What should they do?
- A. Add additional VPN connections and load balance them.
- B. Configure a Google Cloud Dedicated Interconnect.
- C. Send the replicated transaction to Google Cloud Pub/Sub.
- D. Configure their replication to use UDP.
- E. Restore their database daily using Google Cloud SQL.
Correct Answer: B
Question 44
You are deploying a PHP Google App Engine Standard service with SQL as the backend. You want to minimize the number of queries to the database.
What should you do?
- A. Set the memcache service level to dedicated. Create a key from the hash of the query, and return database values from memcache before issuing a query to Google Cloud SQL.
- B. Set the memcache service level to dedicated. Create a cron task that runs every minute to populate the cache with keys containing query results.
- C. Set the memcache service level to shared. Create a cron task that runs every minute to save all expected queries to a key called “cached-queries”.
- D. Set the memcache service level to shared. Create a key called “cached-queries”, and return database values from the key before using a query to Google Cloud SQL.
Correct Answer: A
Reference contents:
– Using Memcache
Question 45
Your company is using Google BigQuery as its enterprise data warehouse. Data is distributed over several Google Cloud projects.
All queries on Google BigQuery need to be billed on a single project. You want to make sure that no query costs are incurred on the projects that contain the data. Users should be able to query the datasets, but not edit them.
How should you configure users’ access roles?
- A. Add all users to a group. Grant the group the role of Google BigQuery user on the billing project and Google BigQuery dataViewer on the projects that contain the data.
- B. Add all users to a group. Grant the group the roles of Google BigQuery dataViewer on the billing project and Google BigQuery user on the projects that contain the data.
- C. Add all users to a group. Grant the group the roles of Google BigQuery jobUser on the billing project and Google BigQuery dataViewer on the projects that contain the data.
- D. Add all users to a group. Grant the group the roles of Google BigQuery dataViewer on the billing project and Google BigQuery jobUser on the projects that contain the data.
Correct Answer: A
Reference contents:
– Running interactive and batch query jobs
Question 46
For this question, refer to the JencoMart case study.
The JencoMart security team requires that all Google Cloud Platform infrastructure is deployed using a least privilege model with separation of duties for administration between production and development resources. What Google domain and project structure should you recommend?
- A. Create two G Suite accounts to manage users: one for development/test/staging and one for production. Each account should contain one project for every application.
- B. Create two G Suite accounts to manage users: one with a single project for all development applications and one with a single project for all production applications.
- C. Create a single G Suite account to manage users with each stage of each application in its own project.
- D. Create a single G Suite account to manage users with one project for the development/test/staging environment and one project for the production environment.
Correct Answer: D
Note: The principle of least privilege and separation of duties are concepts that, although semantically different, are intrinsically related from the standpoint of security. The intent behind both is to prevent people from having higher privilege levels than they actually need.
– Principle of Least Privilege: Users should only have the least amount of privileges required to perform their job and no more. This reduces authorization exploitation by limiting access to resources such as targets, jobs, or monitoring templates for which they are not authorized.
– Separation of Duties: Beyond limiting user privilege level, you also limit user duties, or the specific jobs they can perform. No user should be given responsibility for more than one related function. This limits the ability of a user to perform a malicious action and then cover up that action.
Reference contents:
– Separation of duties
Question 47
For this question, refer to the Dress4Win case study.
You want to ensure that your on-premises architecture meets business requirements before you migrate your solution.
What change in the on-premises architecture should you make?
- A. Replace RabbitMQ with Google Cloud Pub/Sub.
- B. Downgrade MySQL to v5.7, which is supported by Google Cloud SQL for MySQL.
- C. Resize compute resources to match predefined Google Compute Engine machine types.
- D. Containerize the micro services and host them in Google Kubernetes Engine.
Correct Answer: C
Question 48
Your solution is producing performance bugs in production that you did not see in staging and test environments. You want to adjust your test and deployment procedures to avoid this problem in the future.
What should you do?
- A. Deploy smaller changes to production.
- B. Increase the load on your test and staging environments.
- C. Deploy changes to a small subset of users before rolling out to production.
- D. Deploy fewer changes to production.
Correct Answer: B
Question 49
Your company creates rendering software which users can download from the company website. Your company has customers all over the world. You want to minimize latency for all your customers. You want to follow Google-recommended practices.
How should you store the files?
- A. Save the files in a Multi-Regional Google Cloud Storage bucket.
- B. Save the files in a Regional Google Cloud Storage bucket, one bucket per zone of the region.
- C. Save the files in multiple Regional Google Cloud Storage buckets, one bucket per zone per region.
- D. Save the files in multiple Multi-Regional Google Cloud Storage buckets, one bucket per multi-region.
Correct Answer: A
Reference contents:
– Bucket locations > Multi-regions
Question 50
Your organization requires that metrics from all applications be retained for 5 years for future analysis in possible legal proceedings.
Which approach should you use?
- A. Grant the security team access to the logs in each Project.
- B. Configure Stackdriver Monitoring for all Projects, and export to Google BigQuery.
- C. Configure Stackdriver Monitoring for all Projects with the default retention policies.
- D. Configure Stackdriver Monitoring for all Projects, and export to Google Cloud Storage.
Correct Answer: D
Reference contents:
– Storage classes
– Overview of logs exports
– Quotas and limits
– Pricing
Question 51
You are designing a mobile chat application.
You want to ensure people cannot spoof chat messages, by providing a message were sent by a specific user.
What should you do?
- A. Tag messages client side with the originating user identifier and the destination user.
- B. Use public key infrastructure (PKI) to encrypt the message client side using the originating user’s private key.
- C. Encrypt the message client side using block-based encryption with a shared key.
- D. Use a trusted certificate authority to enable SSL connectivity between the client application and the server.
Correct Answer: B
Question 52
Your organization has a 3-tier web application deployed in the same network on Google Cloud Platform.
Each tier (web, API, and database) scales independently of the others Network traffic should flow through the web to the API tier and then on to the database tier. Traffic should not flow between the web and the database tier.
How should you configure the network?
- A. Add each tier to a different subnetwork.
- B. Set up software based firewalls on individual VMs.
- C. Add tags to each tier and set up routes to allow the desired traffic flow.
- D. Add tags to each tier and set up firewall rules to allow the desired traffic flow.
Correct Answer: D
Google Cloud Platform(GCP) enforces firewall rules through rules and tags. GCP rules and tags can be defined once and used across all regions.
Reference contents:
– Google Cloud for OpenStack Users
– Building three-tier architectures with security groups
Question 53
For this question, refer to the Mountkirk Games case study.
Mountkirk Games needs to create a repeatable and configurable mechanism for deploying isolated application environments. Developers and testers can access each other’s environments and resources, but they cannot access staging or production resources. The staging environment needs access to some services from production.
What should you do to isolate development environments from staging and production?
- A. Create a project for development and test and another for staging and production.
- B. Create one subnetwork for development and another for staging and production.
- C. Create one project for development, a second for staging and a third for production.
- D. Create a network for development and test and another for staging and production.
Correct Answer: C
Question 54
For this question, refer to the TerramEarth case study.
Considering the technical requirements, how should you reduce the unplanned vehicle downtime in GCP?
- A. Use Google Cloud Dataproc Hive as the data warehouse. Directly stream data into prtitioned Hive tables. Use Pig scripts to analyze data.
- B. Use Google BigQuery as the data warehouse. Connect all vehicles to the network and upload gzip files to a Multi-Regional Google Cloud Storage bucket using gcloud. Use Google Data Studio for analysis and reporting.
- C. Use Google BigQuery as the data warehouse. Connect all vehicles to the network and stream data into Google BigQuery using Google Cloud Pub/Sub and Google Cloud Dataflow. Use Google Data Studio for analysis and reporting.
- D. Use Google Cloud Dataproc Hive as the data warehouse. Upload gzip files to a MultiRegional Google Cloud Storage bucket. Upload this data into Google BigQuery using gcloud. Use Google data Studio for analysis and reporting.
Correct Answer: C
Question 55
For this question, refer to the Mountkirk Games case study.
Mountkirk Games wants to design their solution for the future in order to take advantage of cloud and technology improvements as they become available.
Which two steps should they take? (Choose two.)
- A. Store as much analytics and game activity data as financially feasible today so it can be used to train machine learning models to predict user behavior in the future.
- B. Begin packaging their game backend artifacts in container images and running them on Google Kubernetes Engine to improve the availability to scale up or down based on game activity.
- C. Set up a CI/CD pipeline using Jenkins and Spinnaker to automate canary deployments and improve development velocity.
- D. Adopt a schema versioning tool to reduce downtime when adding new game features that require storing additional player data in the database.
- E. Implement a weekly rolling maintenance process for the Linux virtual machines so they can apply critical kernel patches and package updates and reduce the risk of 0-day vulnerabilities.
Correct Answer: B, C
Question 56
Your application needs to process credit card transactions.
You want the smallest scope of Payment Card Industry (PCI) compliance without compromising the ability to analyze transactional data and trends relating to which payment methods are used.
How should you design your architecture?
- A. Create a tokenizer service and store only tokenized data.
- B. Create separate projects that only process credit card data.
- C. Create separate subnetworks and isolate the components that process credit card data.
- D. Streamline the audit discovery phase by labeling all of the virtual machines (VMs) that process PCI data.
- E. Enable Logging export to Google BigQuery and use ACLs and views to scope the data shared with the auditor.
Correct Answer: A
Reference contents:
– PCI Data Security Standard compliance
Question 57
You need to evaluate your team readiness for a new GCP project.
You must perform the evaluation and create a skills gap plan incorporates the business goal of cost optimization. Your team has deployed two GCP projects successfully to date.
What should you do?
- A. Allocate budget for team training. Set a deadline for the new GCP project.
- B. Allocate budget for team training. Create a roadmap for your team to achieve Google Cloud certification based on job role.
- C. Allocate budget to hire skilled external consultants. Set a deadline for the new GCP project.
- D. Allocate budget to hire skilled external consultants. Create a roadmap for your team to achieve Google Cloud certification based on job role.
Correct Answer: B
Reference contents:
– Building a Cloud Center of Excellence (PDF)
Question 58
You are developing a globally scaled frontend for a legacy streaming backend data API.
This API expects events in strict chronological order with no repeat data for proper processing.
Which products should you deploy to ensure guaranteed-once FIFO (first-in, first-out) delivery of data?
- A. Google Cloud Pub/Sub alone
- B. Google Cloud Pub/Sub to Google Cloud DataFlow
- C. Google Cloud Pub/Sub to Stackdriver
- D. Google Cloud Pub/Sub to Google Cloud SQL
Correct Answer: B
Reference contents:
– Ordering messages
Question 59
For this question, refer to the Mountkirk Games case study.
Mountkirk Games’ gaming servers are not automatically scaling properly. Last month, they rolled out a new feature, which suddenly became very popular. A record number of users are trying to use the service, but many of them are getting 503 errors and very slow response times.
What should they investigate first?
- A. Verify that the database is online.
- B. Verify that the project quota hasn’t been exceeded.
- C. Verify that the new feature code did not introduce any performance bugs.
- D. Verify that the load-testing team is not running their tool against production.
Correct Answer: B
503 is service unavailable error. If the database was online everyone would get the 503 error.
Reference contents:
– Working with Quotas > Capping usage
Question 60
You are using Google Cloud CDN to deliver static HTTP(S) website content hosted on a Google Compute Engine instance group. You want to improve the cache hit ratio.
What should you do?
- A. Customize the cache keys to omit the protocol from the key.
- B. Shorten the expiration time of the cached objects.
- C. Make sure the HTTP(S) header “Cache-Region” points to the closest region of your users.
- D. Replicate the static content in a Google Cloud Storage bucket. Point Google Cloud CDN toward a load balancer on that bucket.
Correct Answer: A
Question 61
A lead engineer wrote a custom tool that deploys virtual machines in the legacy data center.
He wants to migrate the custom tool to the new cloud environment You want to advocate for the adoption of Google Cloud Deployment Manager.
What are two business risks of migrating to Google Cloud Deployment Manager? (Choose 2 answers)
- A. Google Cloud Deployment Manager uses Python.
- B. Google Cloud Deployment Manager APIs could be deprecated in the future.
- C. Google Cloud Deployment Manager is unfamiliar to the company’s engineers.
- D. Google Cloud Deployment Manager requires a Google APIs service account to run.
- E. Google Cloud Deployment Manager can be used to permanently delete cloud resources.
- F. Google Cloud Deployment Manager only supports automation of Google Cloud resources.
Correct Answer: C, F
Reference contents:
– Deleting deployments
Comments are closed